当前位置:网站首页>10W word segmentation searches per second, the product manager raised another demand!!! (Collection)
10W word segmentation searches per second, the product manager raised another demand!!! (Collection)
2022-07-07 05:57:00 【58 Shen Jian】
Unreasonable demands , How can it be done easily ?
The article is longer , It is recommended to collect... In advance .
Probably 99% My classmates don't do search engine , but 99% Students must have realized the retrieval function . Search for , retrieval , What technologies are included in this , I hope this article can give you some inspiration .
Need one : I want to be a whole network search engine , Not complicated , Just like Baidu , Can it be online in two months ?
Cut in How about the structure and process of search engine ?
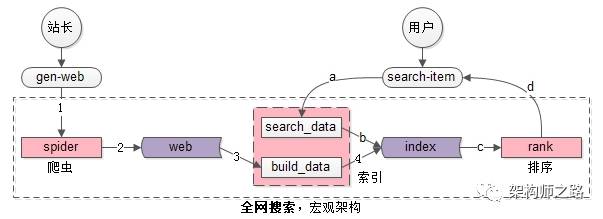
The macro structure of the whole network search engine is shown in the figure above , The core subsystem is mainly divided into three parts ( The pink part ):
(1)spider Reptile system ;
(2)search&index Build index and query index system , The system is divided into two parts :
- Part of it is used to generate index data build_index
- Part of it is used to query index data search_index
(3)rank Scoring and sorting system ;
The core data is mainly divided into two parts ( Purple part ):
(1)web Web Library ;
(2)index Index data ;
The business characteristics of the whole network search engine determine , This is a “ write in ” and “ retrieval ” Separate systems .
How writing is implemented ?
System composition : from spider And search&index Two systems are completed .
Input : Web pages generated by webmasters .
Output : Forward inverted index data .
technological process : As in the frame composition 1,2,3,4:
(1)spider Grab the Internet pages ;
(2)spider Store Internet pages in the Web Library ( This requires a lot of storage , To store almost the entire “ web ” Mirror image );
(3)build_index Read data from the Web Library , Complete the participle ;
(4)build_index Generate inverted index ;
How is retrieval implemented ?
System composition : from search&index And rank Two systems are completed .
Input : User's search terms .
Output : The first page of the search results in order .
technological process : As in the frame composition a,b,c,d:
(a)search_index Get users' search terms , Complete the participle ;
(b)search_index Query inverted index , get “ Character matching ” Webpage , This is the result of preliminary screening ;
(c)rank Score and sort the results of the preliminary screening ;
(d)rank Return the result of the first page after sorting ;
Station How about the structure and process of search engine ?
After all, there are only a few companies that do whole web search , What most companies want to achieve is just a website search , In the same city 100 Take the search of 100 million posts as an example , Its overall structure is as follows :
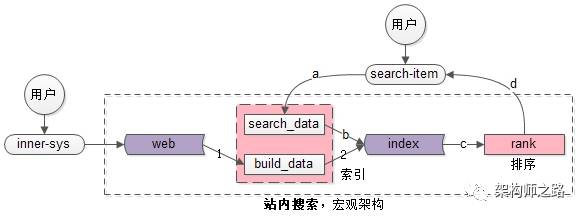
The macro structure of the search engine is shown in the figure above , Compared with the macro structure of the whole network search engine , The difference is only written in :
(1) The need of whole network search spider To capture data passively ;
(2) Site search is data generated by internal system , for example “ Publishing system ” Will actively push the generated posts to build_data System ;
Voice over : It looks like “ Very small ” The difference of , The architecture is much less difficult to implement , How to search the whole web “ real time ” Find out “ Total quantity ” It's very difficult to find the right web page , And the station search is easy to get all the data in real time .
about spider、search&index、rank Three systems :
(1)spider and search&index It's an engineering system ;
(2)rank It's business and business 、 Close strategy 、 Algorithm related systems , The main difference in search experience is , And business 、 It takes time to optimize the strategy , The inspiration here is :
- Google Experience ratio Baidu good , It's the former rank frigging awesome
- Domestic Internet companies ( for example 360) In a short time, we need to experience and surpass Baidu Search engine , It's hard , It really takes time to accumulate
The previous content is too macro , In order to take care of most of the students who have not done search engine , Data structure and algorithm part is from forward index 、 The inverted index starts a little bit .
What is a forward index? (forward index)?
in short , from key The process of querying entities , Using forward index .
for example , User table :
t_user(uid, name, passwd, age, sex)
from uid The process of querying the whole line , Is the forward index query .
For example , Web Library :
t_web_page(url, page_content)
from url The process of querying the whole web page , Is also a forward index query. .
After web content segmentation ,page_content Will correspond to a set of participles list<item>.
Simple , Forward index can be understood as :
Map<url, list<item>>
Can be created by the web url Quickly find a data structure for content .
Voice over : Time complexity can be thought of as O(1).
What is inverted index (inverted index)?
Contrary to forward index , from item Inquire about key The process of , Use inverted index .
For web search , Inverted index can be understood as :
Map<item, list<url>>
It can quickly find the data structure of the web page containing the query word by the query word .
Voice over : Time complexity is also O(1).
for instance , Suppose there is 3 Pages :
url1 -> “ I love Beijing ”
url2 -> “ I love going home ”
url3 -> “ Home is beautiful ”
This is a Forward index :
Map<url, page_content>.
After the participle :
url1 -> { I , Love , Beijing }
url2 -> { I , Love , home }
url3 -> { home , happy }
This is a Forward index after segmentation :
Map<url, list<item>>.
Inverted index after word segmentation :
I -> {url1, url2}
Love -> {url1, url2}
Beijing -> {url1}
home -> {url2, url3}
happy -> {url3}
By key words item Quickly find the web page containing the query word Map<item, list<url>> Namely Inverted index .
Voice over : I see! , Word to url The process of , It's inverted index .
Forward index and inverted index are spider and build_index The system establishes a good data structure in advance , Why use these two data structures , Because it can be implemented quickly “ User web search ” demand .
Voice over , Business requirements determine architecture implementation , It's quick to find out .
What is the retrieval process like ?
Suppose the search term is “ I love ”:
(1) participle ,“ I love ” Participle { I , Love }, The time complexity is O(1);
(2) After each participle item, Query from inverted index contains this item The web page of list<url>, Time complexity is also O(1):
I -> {url1, url2}
Love -> {url1, url2}
(3) seek list<url> Intersection , It's the result page that matches all the query words , For this example ,{url1, url2} This is the final query result ;
Voice over : The retrieval process is also very simple : participle , Check the inverted index , Finding the intersection of result sets .
Is it over ? It's not , The time complexity of word segmentation and inverted query is O(1), The time complexity of the whole search depends on “ seek list<url> Intersection ”, The problem is to find the intersection of two sets .
Character type url Not conducive to storage and Computing , Generally speaking, each url There will be a numerical type url_id To mark , For convenience of description ,list<url> Unified use list<url_id> replace .
list1 and list2, How to find intersection ?
Scheme 1 :for * for, Earth way , Time complexity O(n*n)
Every search term hits a lot of pages ,O(n*n) The complexity of is obviously unacceptable . Inverted index can be used for sorting and preprocessing at the beginning of creation , The problem translates into two orderly list Find the intersection , It's much more convenient .
Voice over : Stupid way .
Option two : Orderly list Find the intersection , Zipper method
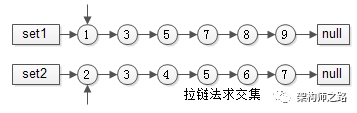
Ordered set 1{1,3,5,7,8,9}
Ordered set 2{2,3,4,5,6,7}
Two pointers point to the first element , Compare the size of the elements :
(1) If the same , Put the result set , Move a pointer at will ;
(2) otherwise , Move a pointer with a smaller value , Until the end of the team ;
The advantage of this method is :
(1) The elements in the collection are compared at most once , The time complexity is O(n);
(2) Multiple ordered sets can be made at the same time , This applies to more than one participle item seek url_id intersection ;
This method is like the gears on both sides of a zipper , One by one comparison is like a zipper , So it's called zipper method ;
Voice over : Inverted index is initialized ahead of time , You can use “ Orderly ” This feature .
Option three : Parallel optimization by buckets
When the amount of data is large ,url_id To cut horizontally + Parallel operation is a common optimization method , If you can list1<url_id> and list2<url_id> Divide into bucket intervals , Each interval uses multithreading to find intersection in parallel , The union of the result sets of each thread , As the final result set , Can greatly reduce the execution time .
give an example :
Ordered set 1{1,3,5,7,8,9, 10,30,50,70,80,90}
Ordered set 2{2,3,4,5,6,7, 20,30,40,50,60,70}
Find the intersection , Split the buckets first :
bucket 1 For the range of [1, 9]
bucket 2 For the range of [10, 100]
bucket 3 For the range of [101, max_int]
therefore :
aggregate 1 Split it into
aggregate a{1,3,5,7,8,9}
aggregate b{10,30,50,70,80,90}
aggregate c{}
aggregate 2 Split it into
aggregate d{2,3,4,5,6,7}
aggregate e{20,30,40,50,60,70}
aggregate e{}
The amount of data in each bucket is greatly reduced , And there is no repeating element in each bucket , You can use multithreaded parallel computing :
bucket 1 A collection within a And collection d The intersection of x{3,5,7}
bucket 2 A collection within b And collection e The intersection of y{30, 50, 70}
bucket 3 A collection within c And collection d The intersection of z{}
Final , aggregate 1 And collection 2 Intersection , yes x And y And z Union , I.e. set {3,5,7,30,50,70}.
Voice over : Multithreading 、 Horizontal segmentation is a common optimization method .
Option four :bitmap Optimize again
After the data is split horizontally , The data in each bucket must be in a range , If the set matches this characteristic , You can use bitmap To represent a set :
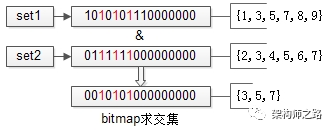
Pictured above , hypothesis set1{1,3,5,7,8,9} and set2{2,3,4,5,6,7} All of the elements in the bucket value [1, 16] Within the scope of , It can be used 16 individual bit To describe these two sets , The elements of the original collection x, In this 16bitmap No x individual bit by 1, Now two bitmap Find the intersection , Just put two bitmap Conduct “ And ” operation , Result set bitmap Of 3,5,7 Is it 1, Indicates that the intersection of the original set is {3,5,7}.
Divide the barrels horizontally ,bitmap After the optimization , Can greatly improve the efficiency of intersection , But time complexity is still O(n).bitmap It takes a lot of continuous space , Large memory footprint .
Voice over :bitmap Can represent a set , It's very fast to find the intersection of sets .
Option five : Jump watch skiplist
The intersection of the ordered list set , Jump table is the most commonly used data structure , It can get the complexity of intersection from O(n) It's close to O(log(n)).

aggregate 1{1,2,3,4,20,21,22,23,50,60,70}
aggregate 2{50,70}
Ask for intersection , If you use zipper method , Will find 1,2,3,4,20,21,22,23 All have to be traversed invalid once , Every element has to be compared , The time complexity is O(n), Can you compare each time “ Skip some elements ” Well ?
The jump watch appears :
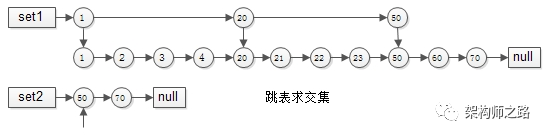
aggregate 1{1,2,3,4,20,21,22,23,50,60,70} When creating a jump table , There is only one level {1,20,50} Three elements , The second level is the same as the common list .
aggregate 2{50,70} Because there are fewer elements , Only one level of common linked list has been established .
such , In implementation “ zipper ” In the process of finding intersection ,set1 The pointer of can be controlled by 1 Jump to the 20 Jump to 50, Can skip many elements in the middle , There is no need to compare one by one , The time complexity of finding intersection is approximate O(log(n)), This is a common algorithm in search engines .
A brief summary :
(1) Whole network search engine system from spider, search&index, rank Three subsystems ;
(2) On site search engine The difference with the whole web search engine is , One less. spider Subsystem ;
(3)spider and search&index The system is two engineering system ,rank The optimization of the system needs a long time of tuning and accumulation ;
(4) Forward index (forward index) It's made up of web pages url_id Quickly find the content of the web page after word segmentation list<item> The process of ;
(5) Inverted index (inverted index) It's made up of participles item Quickly find the web page containing this participle list<url_id> The process of ;
(6) The process of user retrieval , It's participle first , Find each one again item Corresponding list<url_id>, Finally, the process of intersection of sets is carried out ;
(7) Intersection of ordered sets The way to do this is :
- double for Circulation , Time complexity O(n*n)
- Zipper method , Time complexity O(n)
- Divide the barrels horizontally , Multithreading parallel
- bitmap, Greatly improve the parallelism of operation , Time complexity O(n)
- Jump watch , The time complexity is O(log(n))
Demand two : I want to do a content retrieval function , Not complicated ,100 100 million data , Per second 10 Ten thousand inquiries , Can it be online in two weeks ?
Most engineers may not have been exposed to “ Search kernel ”, But the Internet business , It will basically involve “ retrieval ” function . Take the post business scenario in the same city as an example , The title of the post , The content of the post has a strong user search demand , In the business 、 Traffic 、 The phases of increasing concurrency , How to realize the retrieval requirements ?
Original stage -LIKE
The start-up phase , This method is often used to achieve .
The data may be stored in the database in this way :
t_tiezi(tid, title, content)
Meet the title 、 Content retrieval requirements can be achieved through LIKE Realization :
select tid from t_tiezi where content like ‘% Tiantongyuan %’
This approach can really meet business needs quickly , The problems are also obvious :
(1) Low efficiency , A full table scan is required each time , Large amount of computation , Concurrent high time cpu Easy to 100%;
(2) Participle... Is not supported ;
Primary stage - Full-text index
How to improve efficiency quickly , Support participle , And the impact on the original system architecture is as small as possible , The first thing I thought of was building a full-text index :
alter table t_tiezi add fulltext(title,content)
Use match and against Realize the query requirements on the index field .
Full text indexing can quickly meet the needs of business word segmentation , And quickly improve performance ( Inverted after participle , At least don't scan the whole table ), But there are also some problems :
(1) Only applicable to MyISAM;
(2) Because the full-text index uses the characteristics of the database , Search needs and common CURD Requirement coupling in database : When retrieval requirements are concurrent , Possible impact CURD Request ;CURD Concurrent large time , Retrieval will be very slow ;
(3) Millions of data , Performance will still be significantly reduced , Query return time is very long , The business is hard to accept ;
(4) It is difficult to expand horizontally ;
Intermediate stage - Open source external index
In order to solve the limitation of full text search , When the amount of data increases to millions , Ten million level , We need to consider the external index . The design of external index The core idea yes : The index data is separated from the original data , The former meets the needs of search , The latter is satisfied with CURD demand , Through a certain mechanism ( Double write , notice , Rebuild regularly ) To ensure data consistency .
Raw data can continue to be used Mysql To store , How to implement external index ?Solr,Lucene,ES Are common open source solutions . among ,ES(ElasticSearch) It's the most popular .
Lucene Is good , What are the potential disadvantages :
(1)Lucene It's just a library , You need to do your own service , High availability on your own / Scalable / Load balancing and other complex characteristics ;
(2)Lucene Only support Java, If you want to support other languages , You have to serve yourself ;
(3)Lucene unfriendly , It can be deadly , Very complicated , Users often need to know more about search to understand how it works , In order to shield its complexity , We still have to do our own service ;
To improve Lucene The shortcomings of , The solutions are “ Encapsulating an interface friendly service , Mask underlying complexity ”, Hence the ES:
(1)ES It's an example. Lucene Search for the kernel , Provide REStful Service of interface ;
(2)ES It can support a large amount of information storage , Supports highly concurrent search requests ;
(3)ES Support clusters , Shield users from high availability / Scalable / Load balancing and other complex characteristics ;
at present , Fast Dog Taxi use ES As a core search service , Realize all kinds of search requirements in the business , among :
(1) The largest amount of data “ Interface time consuming data collection ” demand , The amount of data is about 10 Million or so ;
(2) The most concurrent “ Longitude and latitude , Location search ” demand , The average online concurrency is about 2000 about , Pressure measurement data concurrency in 8000 about ;
therefore ,ES It's totally satisfying 10 Billion data volume ,5k Common search business requirements for throughput .
Advanced stage - Self developed search engine
When the amount of data increases further , achieve 10 Billion 、100 Billion data volume ; The concurrency also increased , Up to... Per second 10 10000 throughput ; Business personality is also gradually increasing , We need to develop our own search engine , Customized implementation of the search kernel .
To the stage of customized self-developed search engine , Huge amount of data 、 High concurrency is the focus of design , In order to achieve “ Unlimited capacity 、 Infinite concurrency ” The needs of , Architecture design needs to focus on “ Extensibility ”, Strive to achieve : More machines can expand capacity ( Data volume + Concurrency ).
Self developed search engine in the same city E-search The preliminary structure is as follows :
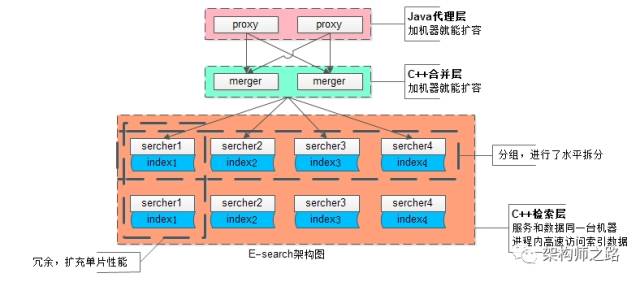
(1) The upper proxy( Pink ) yes Access cluster , For the external portal , Accept search request , Its statelessness can ensure that the increase of machines can expand proxy Cluster performance ;
(2) Middle level merger( The light blue ) yes Logical cluster , It is mainly used to realize search merge , And ranking , Business related rank It's implemented at this level , Its statelessness can also guarantee the expansion of the machine merger Cluster performance ;
(3) Bottom searcher( Large dark red frame ) It's a search cluster , Services and index data are deployed on the same machine , The index data can be loaded into memory when the service is started , Request access from memory load data , The access speed is very fast :
- In order to satisfy the Scalability of data capacity , The index data is sliced horizontally , Increase the number of shards , You can scale performance infinitely , Pictured above searcher Divided into 4 Group
- In order to satisfy the Performance scalability of a piece of data , The same data is redundant , In theory, if you add machines, you can expand performance infinitely , As shown in the figure above searcher It's redundant again 2 Share
So designed , More machines can carry more data , Respond to higher concurrency .
A brief summary :
To meet the needs of the search business , With the growth of data and concurrency , Search architecture generally goes through these stages :
(1) Original stage -LIKE;
(2) Primary stage - Full-text index ;
(3) Intermediate stage - Open source external index ;
(4) Advanced stage - Self developed search engine ;
Demand 3 : Timeliness of retrieval , It's important for the user experience , Must retrieve 5 News minutes ago ,1 Post posted seconds ago , It's not complicated ?
Last high-level topic , About Real time search :
Why baidu can retrieve in real time 5 New news that came out minutes ago ? Why can the same city retrieve in real time 1 Posts posted two seconds ago ?
What are the key points of real-time search engine system architecture ?
Large amount of data 、 In order to ensure the real-time performance of the search engine in the case of high concurrency , Two key points in architecture design :
(1) Index rating ;
(2)dump&merge;
First , In the case of a very large amount of data , In order to ensure the efficient retrieval efficiency of inverted index , Any update to the data , The index is not modified in real time .
Voice over : because , Once there's debris , It will greatly reduce the retrieval efficiency .
Since index data cannot be modified in real time , How to ensure that the latest web pages can be indexed ?
Index rating , It is divided into full database 、 Daily increment Library 、 Hourly increment Library .
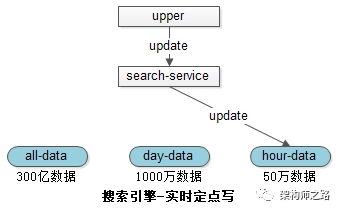
As shown above :
(1)300 100 million data in the full index library ;
(2)1000 ten thousand 1 The data modified in the day is in the day database ;
(3)50 ten thousand 1 The data modified within the hour is in the hour library ;
When When a modification request occurs , Only the lowest level index is manipulated , For example, hour bank .
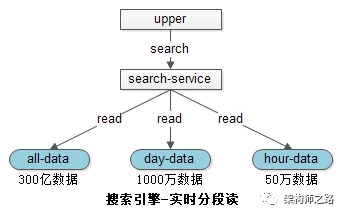
When When a query request occurs , Will query all levels of index at the same time , Combine the results , Get the latest data :
(1) A full library is a tightly stored index , No debris , Fast ;
(2) Tianku is compact storage , Fast ;
(3) Small amount of data in hour bank , Too fast ;
Hierarchical index can guarantee real-time performance , that , New questions are coming , When will the data of hour database be reflected in the day database , When will the data in the sky database be reflected in the full database ?
dump&merge, Export and merge of index , It's done by these two asynchronous tools :
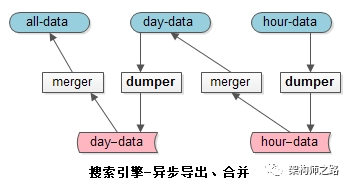
dumper: Export online data .
merger: Merge offline data into a higher level index .
Hour bank , Once an hour , Merge into tianku ;
Tianku , Once a day , Merge it into the full database ;
In this way, the amount of data in the hour database and the day database will not be particularly large ;
If the amount of data and concurrency is greater , It can also increase the weekly library , Buffer from the monthly bank .
A brief summary :
Huge amount of data , High concurrency , Two key points of real-time search engine architecture :
(1) Index rating ;
(2)dump&merge;
About “ Search for ” And “ retrieval ” The needs of , Are you satisfied ?
Architect's way - Share technical ideas
Related to recommend :
《 You have to know RPC Kernel details ( Collection )》
《 Whose encryption key , Write dead in code ?》
research :
Have you received any abnormal needs ?
边栏推荐
- Introduction to distributed transactions
- 原生小程序 之 input切換 text與password類型
- JVM the truth you need to know
- 老板总问我进展,是不信任我吗?(你觉得呢)
- Three level menu data implementation, nested three-level menu data
- 软件测试面试技巧
- Win configuration PM2 boot auto start node project
- Why does the data center need a set of infrastructure visual management system
- Things about data storage 2
- Question 102: sequence traversal of binary tree
猜你喜欢
Reading notes of Clickhouse principle analysis and Application Practice (6)

Red hat install kernel header file
一名普通学生的大一总结【不知我等是愚是狂,唯知一路向前奔驰】
驱动开发中platform设备驱动架构详解
Three level menu data implementation, nested three-level menu data
Realize GDB remote debugging function between different network segments
深度聚类:将深度表示学习和聚类联合优化

目标检测中的BBox 回归损失函数-L2,smooth L1,IoU,GIoU,DIoU,CIoU,Focal-EIoU,Alpha-IoU,SIoU
mac版php装xdebug环境(m1版)
Industrial Finance 3.0: financial technology of "dredging blood vessels"
随机推荐
Web authentication API compatible version information
Wechat applet Bluetooth connects hardware devices and communicates. Applet Bluetooth automatically reconnects due to abnormal distance. JS realizes CRC check bit
Loss function and positive and negative sample allocation in target detection: retinanet and focal loss
Check Point:企业部署零信任网络(ZTNA)的核心要素
Go language learning notes - Gorm use - Gorm processing errors | web framework gin (10)
【已解决】记一次EasyExcel的报错【读取xls文件时全表读不报错,指定sheet名读取报错】
随机生成session_id
成为资深IC设计工程师的十个阶段,现在的你在哪个阶段 ?
Classic questions about data storage
bat 批示处理详解
微信小程序蓝牙连接硬件设备并进行通讯,小程序蓝牙因距离异常断开自动重连,js实现crc校验位
数字IC面试总结(大厂面试经验分享)
Reptile exercises (III)
职场经历反馈给初入职场的程序员
Polynomial locus of order 5
SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
cf:C. Column Swapping【排序 + 模擬】
上海字节面试问题及薪资福利
Determine whether the file is a DICOM file
Five core elements of architecture design