当前位置:网站首页>03-存储系统
03-存储系统
2022-07-04 13:28:00 【柒姑娘哦】
存储系统基本概念
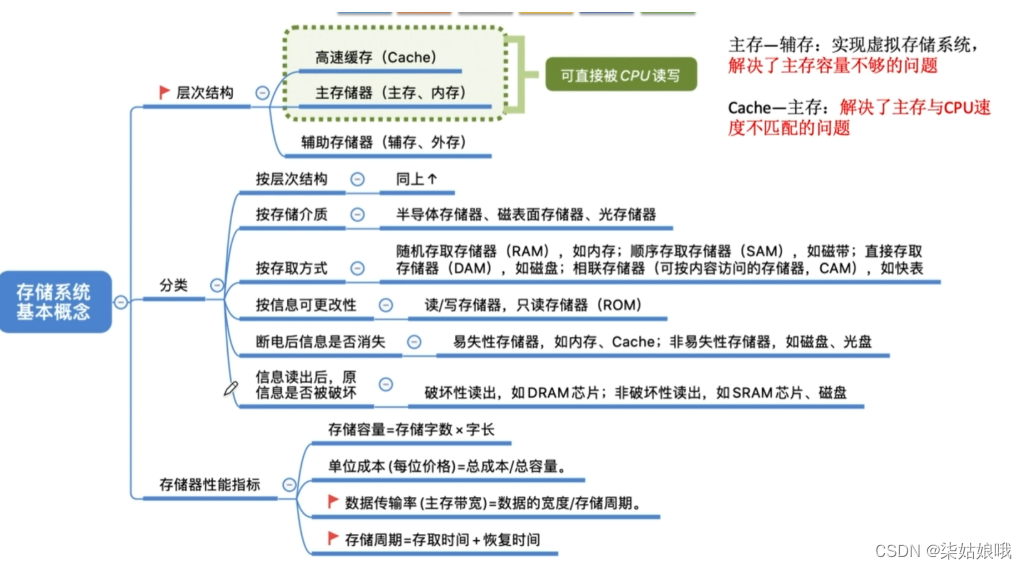
现代计算机的结构
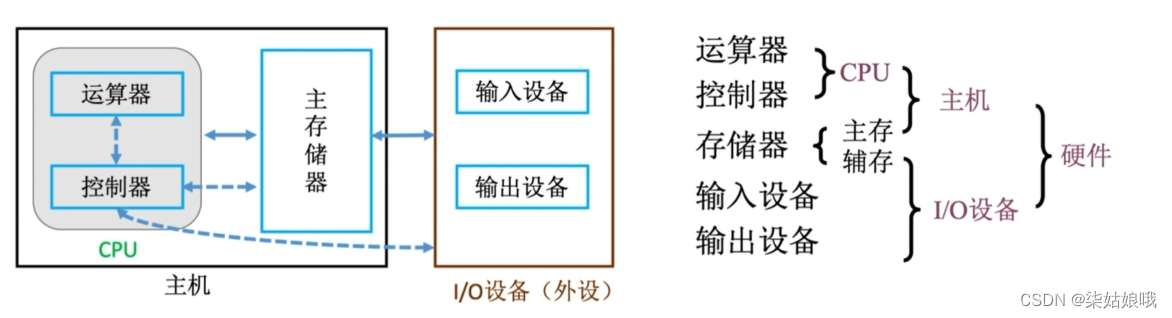
存储器的层次化结构
注:有的教材把安装在电脑内部的磁盘称为“辅存”,把U盘、光盘等称为“外存”。
也有的教材把磁盘、U盘、光盘等统称为“辅存”或“外存”
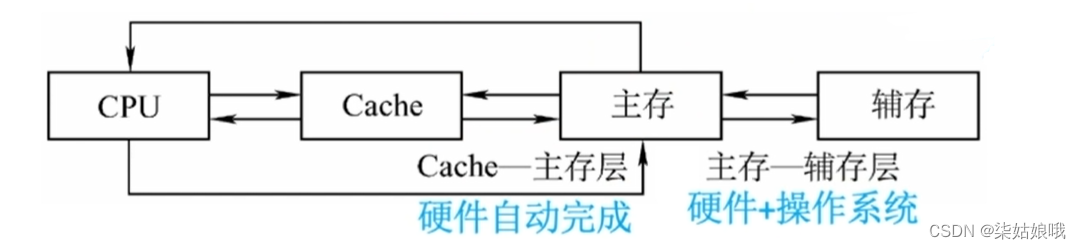
辅存中的数据要调入主存后才能被CPU访问,Cache主要是为了缓解CPU和主存之间的矛盾
主存―辅存:实现虚拟存储系统解决了主存容量不够的问题
Cache一主存:解决了主存与CPU速度不匹配的问题
存储器的分类
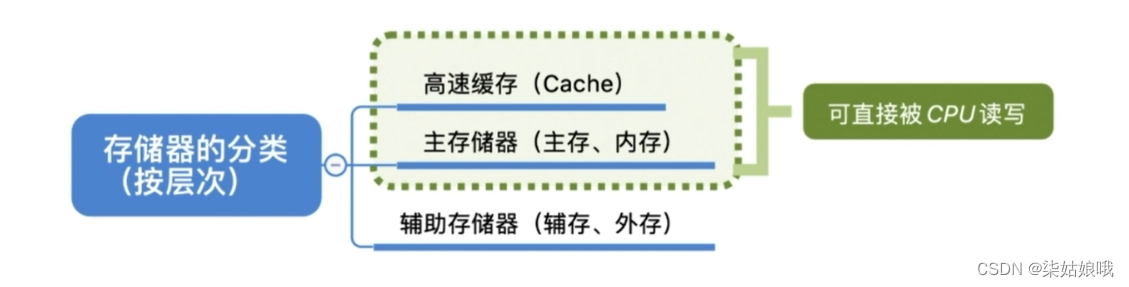


存储器的性能指标
MDR位数反映存储字长
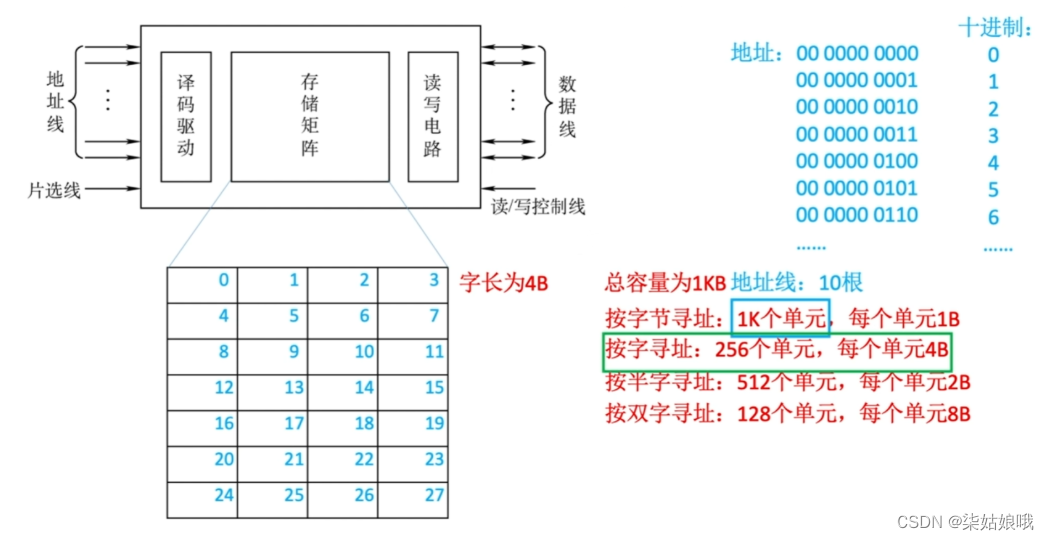
1.存储容量:存储字数×字长(如1M×8位)。
2.单位成本:每位价格=总成本/总容量。
3.存储速度:数据传输率=数据的宽度/存储周期。
数据的宽度即存储字长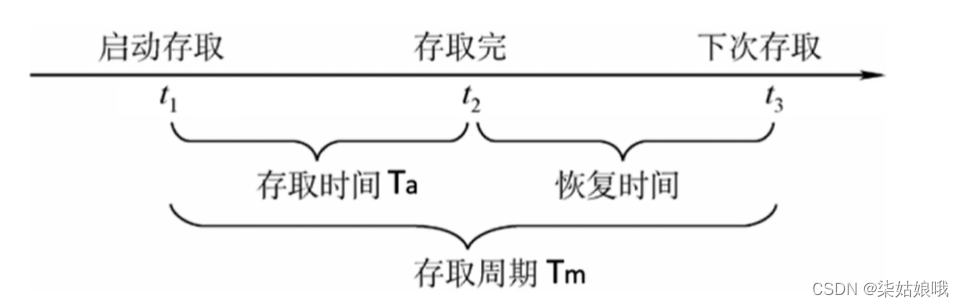
①存取时间(Ta):存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。
②存取周期:存取周期又称为读写周期或访问周期。它是指存储器进行一次完整的读写操作所需的全部时间,即连续两次独立地访问存储器操作(读或写操作)之间所需的最小时间间隔。
主存带宽(Bm):主存带宽又称数据传输率,表示每秒从主存进出信息的最大数量,单位为字/秒、字节/秒(B/s)或位/秒(b/s) 。
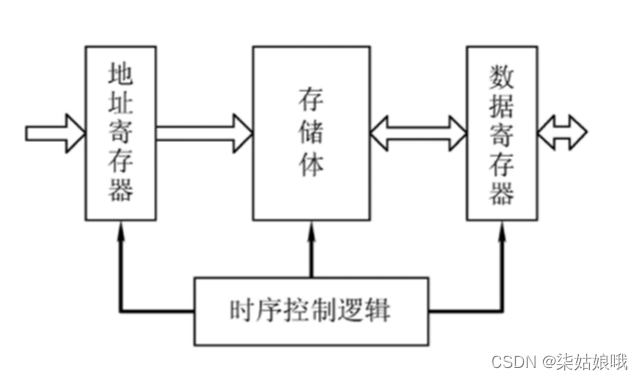
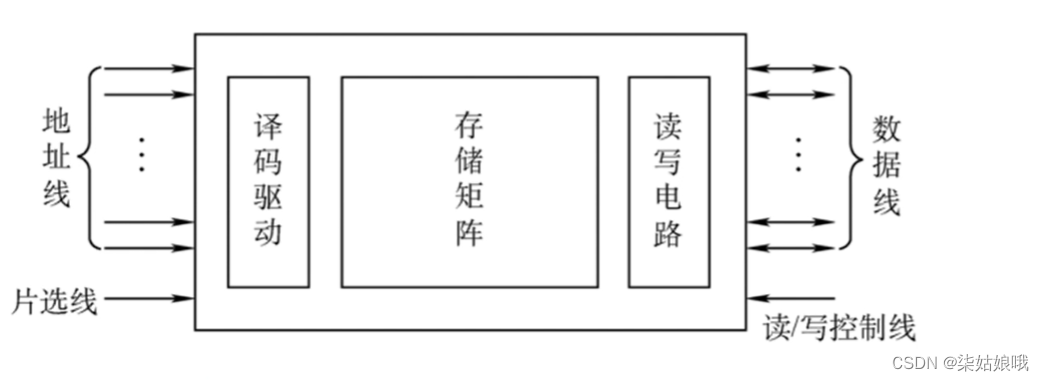
主存储器的基本组成
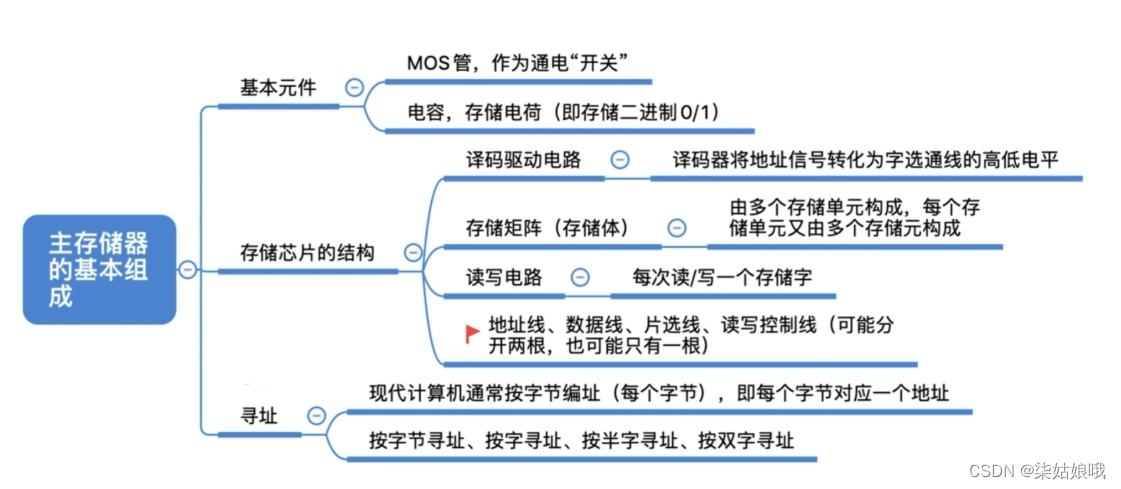
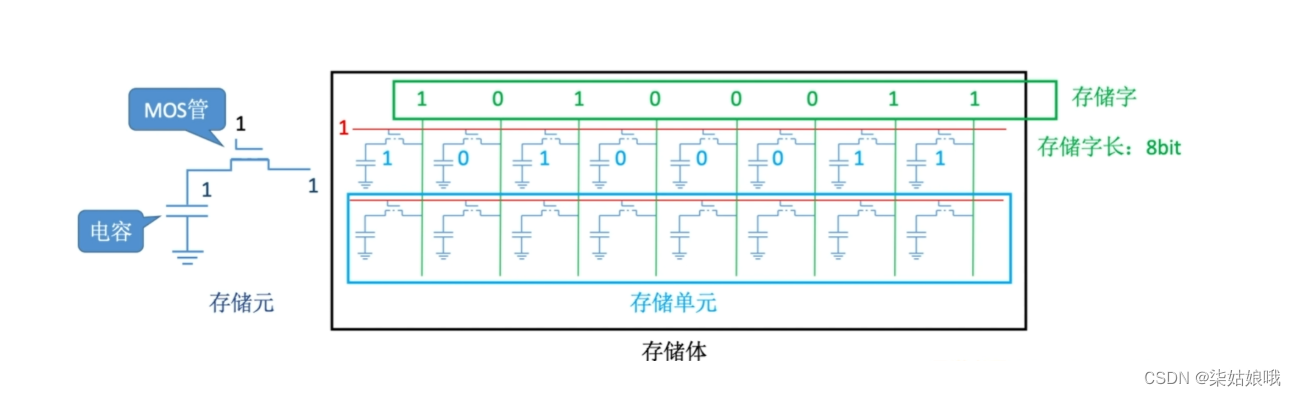
基本的半导体元件及原理
注: MOS管可理解为一种电控开关,输入电压达到某个阈值时,MOS管就可以接通
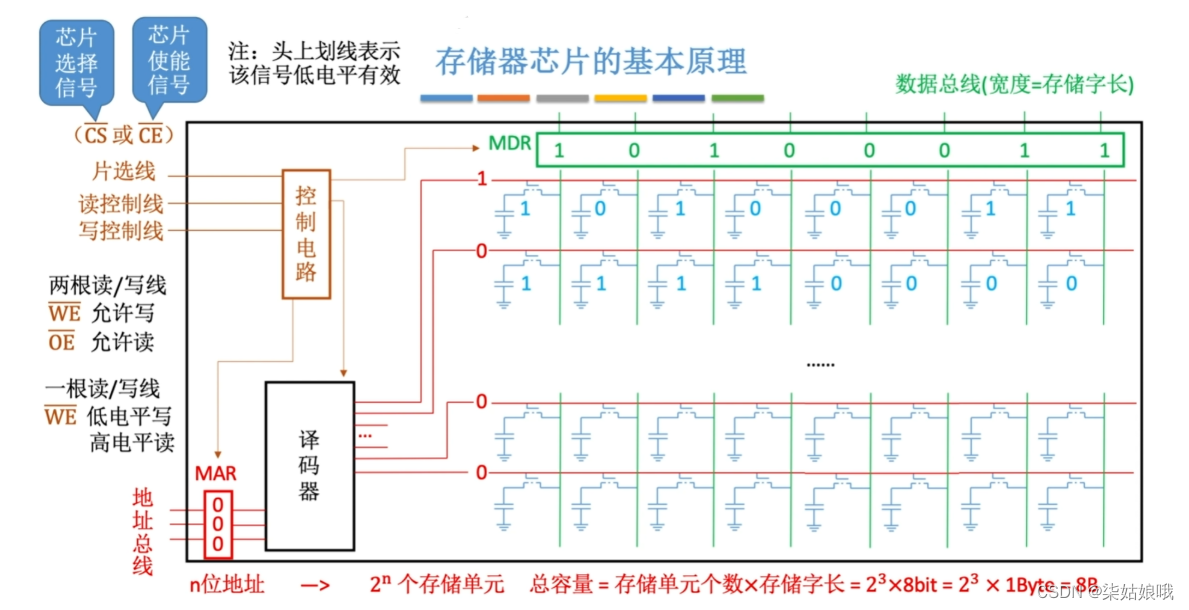
存储器芯片的基本原理
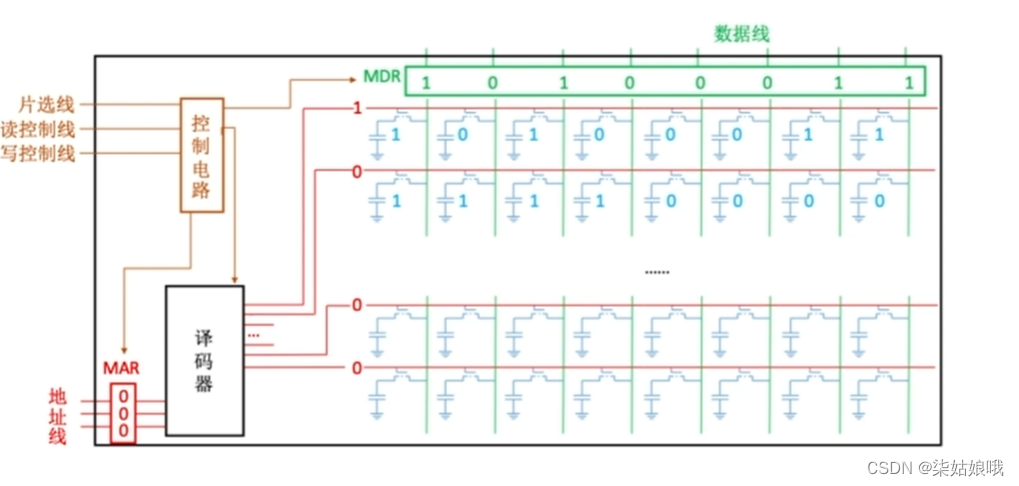

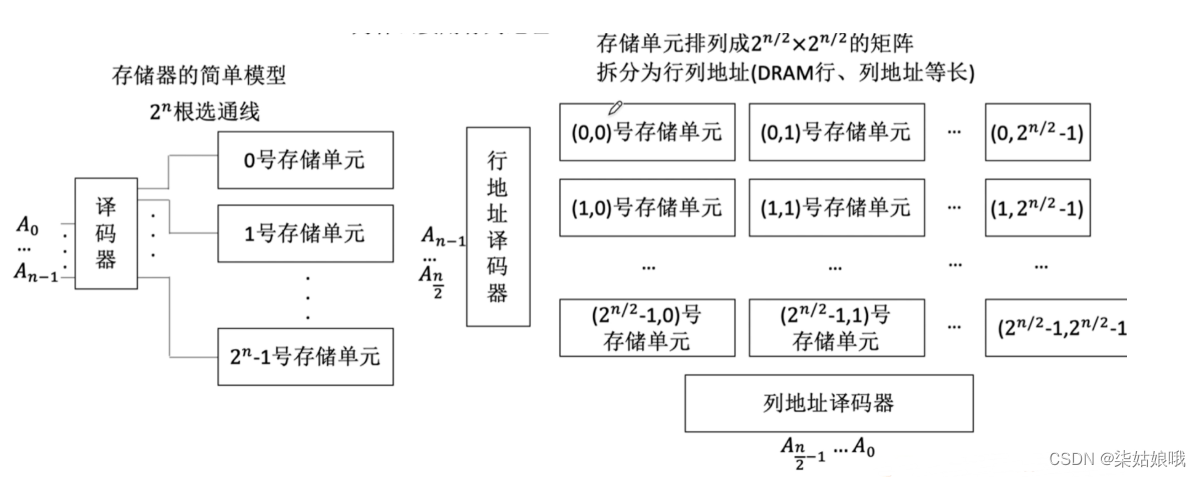
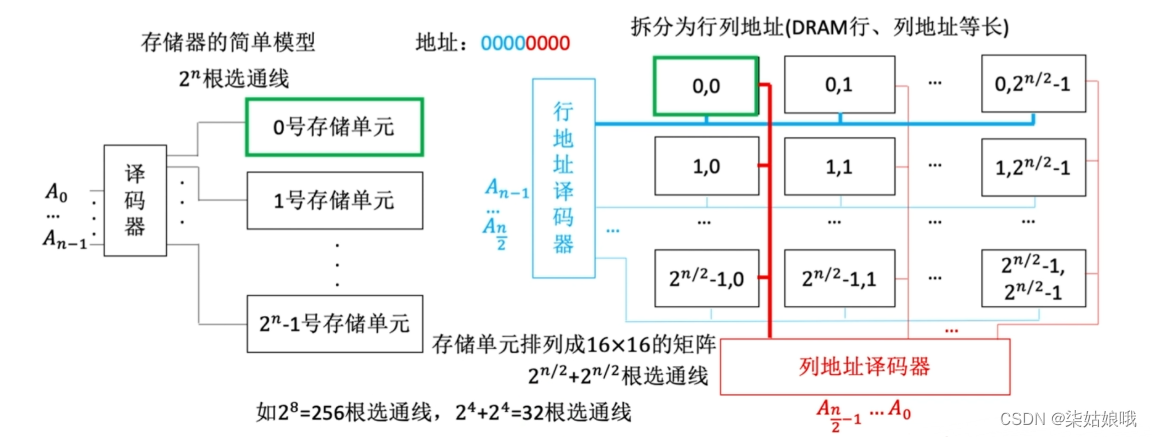
寻址
SRAM和DRAM
Dynamic Random Access Memory,即动态RAM
Static Random Access Memory,即静态RAM
DRAM用于主存、SRAM用于Cache
高频考点:DRAM和SRAM的对比
很多ROM芯片虽然名字是“Read-Only”,但很多ROM也可以“写”
闪存的写速度一般比读速度更慢,因为写入前要先擦除
RAM芯片是易失性的,ROM芯片是非易失性的。很多ROM也具有“随机存取”的特性
DRAM芯片
DRAM芯片:使用栅极电容存储信息
SRAM芯片:使用双稳态触发器存储信息
核心区别:存储元不一样
栅极电容&双稳态触发器
DRAM
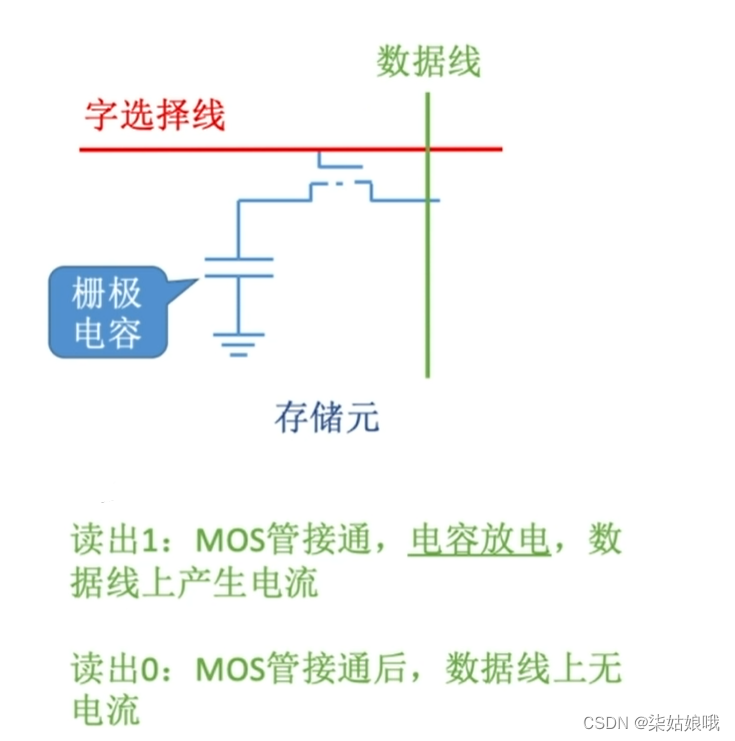
电容放电信息被破坏,是破坏性读出。读出后应有重写操作,也称“再生”。读写速度慢( •̀ ω •́ )*
每个存储元制造成本更低,集成度高,功耗低
电容内的电荷只能维持2ms。即便不断电,2ms后信息也会消失。2ms之内必须“刷新”一次(给电容充电)
SRAM
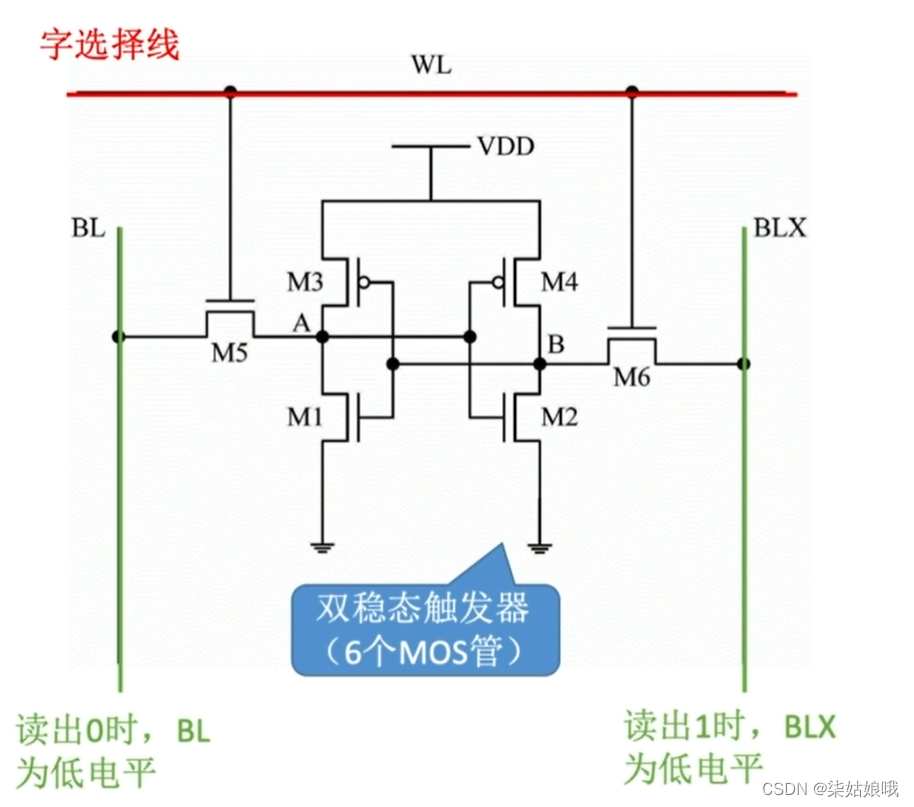
双稳态
1:A高B低
0:A低B高
读出数据,触发器状态保持稳定,是非破坏性读出,无需重写,读写速度快
只要不断电,触发器的状态就不会改变
每个存储元制造成本更高,集成度低,功耗大

DRAM的刷新
1.多久需要刷新一次? 刷新周期:一般为2ms
2.每次刷新多少存储单元? 以行为单位,每次刷新一行存储单元——为什么要用行列地址?减少选通线的数量
3.如何刷新?
有硬件支持,读出一行的信息后重新写入,占用1个读/写周期
4.在什么时刻刷新?
假设DRAM内部结构排列成128×128的形式,(读/写周期)存取周期0.5us
2ms共2ms/0.5us = 4000个周期

DRAM的地址线复用技术
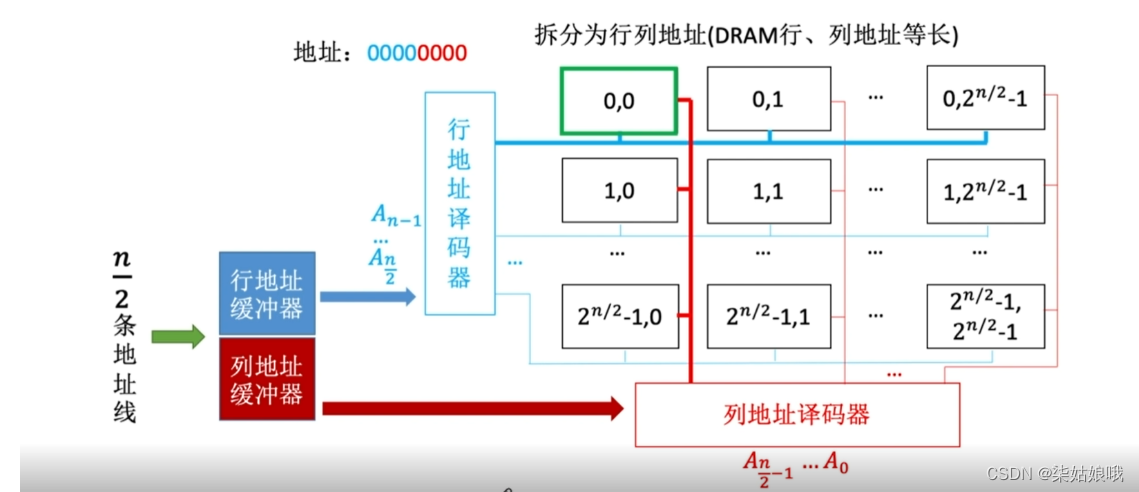
行、列地址分两次送,可使地址线更少,芯片引脚更少
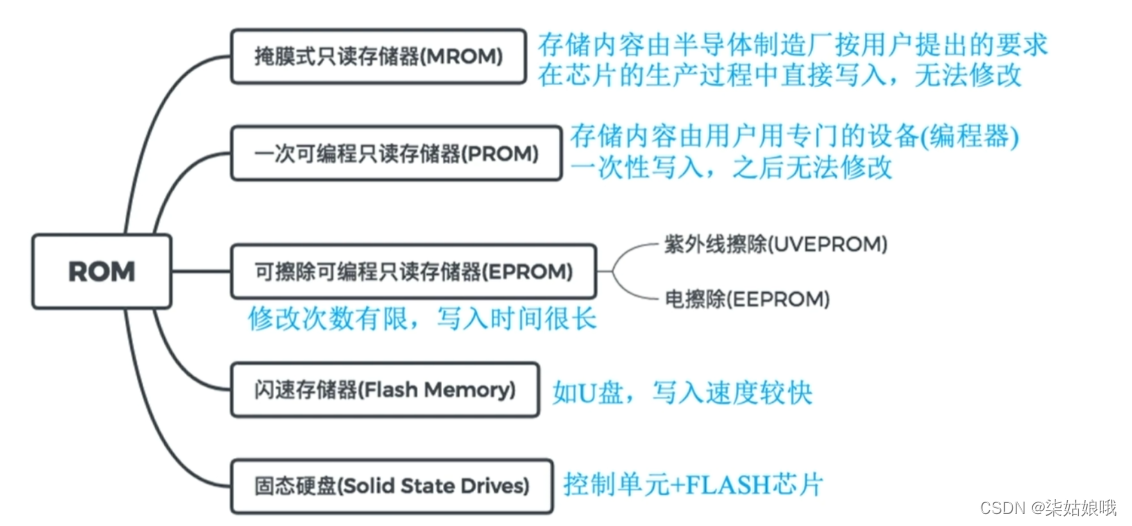
只读存储器ROM
RAM芯片一一易失性,断电后数据消失
ROM芯片――非易失性,断电后数据不会丢失
各种ROM
MROM(Mask Read-Only Memory) —―掩模式只读存储器,厂家按照客户需求,在芯片生产过程中直接写入信息,之后任何人不可重写(只能读出)可靠性高、灵活性差、生产周期长、只适合批量定制
PROM (Programmable Read-Only Memory) -一可编程只读存储器用户可用专门的PROM写入器写入信息,写一次之后就不可更改
EPROM (Erasable Programmable Read-Only Memory)—―可擦除可编程只读存储器允许用户写入信息,之后用某种方法擦除数据,可进行多次重写
UVEPROM (ultraviolet rays)一一用紫外线照射8~20分钟,擦除所有信息
EEPROM(也常记为E²PROM,第一个E是Electrically)-一可用“电擦除”的方式,擦除特定的字
Flash Memory —一闪速存储器(注:U盘、SD卡就是闪存)在EEPROM基础上发展而来,断电后也能保存信息,且可进行多次快速擦除重写注意:由于闪存需要先擦除在写入,因此闪存的“写”速度要比“读”速度更慢。每个存储元只需单个MOS管,位密度比RAM高
SSD ( Solid State Drives) -一固态硬盘,由控制单元+存储单元(Flash芯片)构成,与闪速存储器的核心区别在于控制单元不一样,但存储介质都类似,可进行多次快速擦除重写。SSD速度快、功耗低、价格高。目前个人电脑上常用sSD取代传统的机械硬盘
拓:手机辅存也使用Flash芯片,但相比SSD使用的芯片集成度高、功耗低、价格贵
计算机内的各种重要ROM
CPU的任务:
到主存中取指令并执行指令
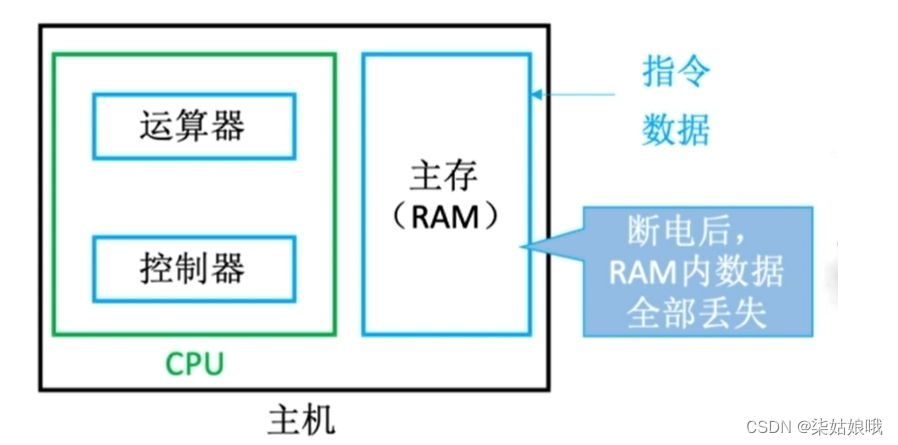
操作系统安装在辅存
主板上的BIOS芯片(ROM) ,存储了“自举装入程序”,负责引导装入操作系统(开机)
注:我们常说“内存条”就是“主存”,但事实上,主板上的ROM芯片也是“主存”的一部分
逻辑上,主存由RAM+ROM组成,且二者常统一编址
多模块存储器(双端口已删)
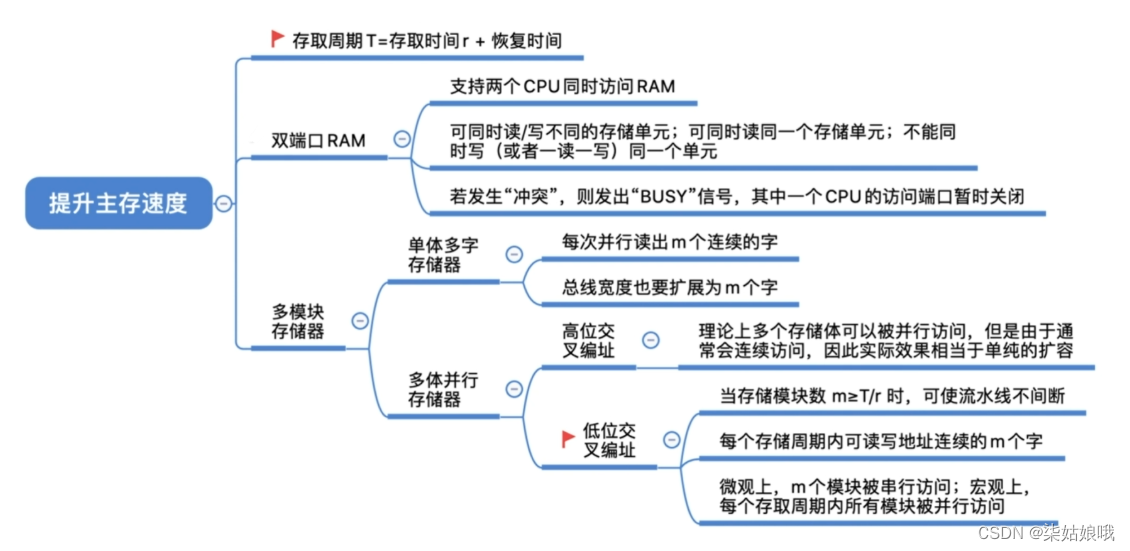
存取周期
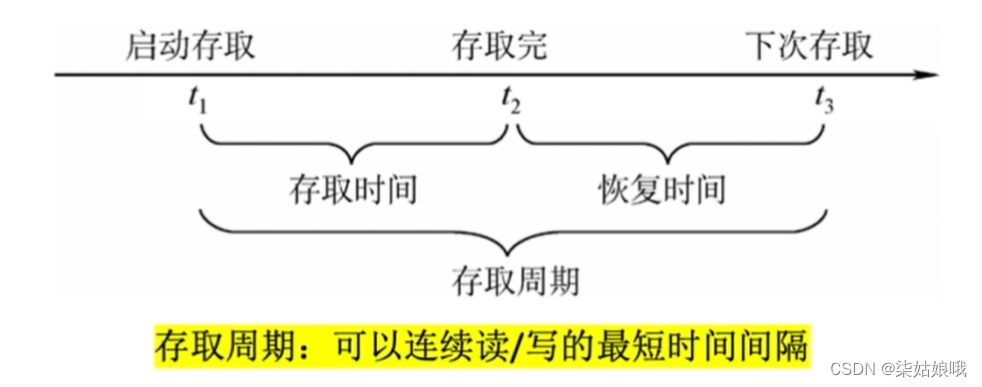
如:存取时间为r,存取周期为T,T=4r
双口RAM
作用:优化多核CPU访问一根内存条的速度
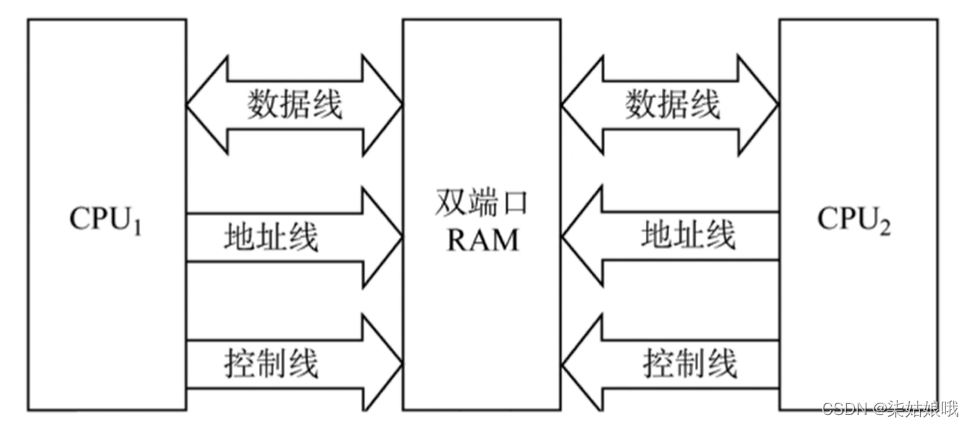
需要有两组完全独立的数据线、地址线、控制线。CPU、RAM中也要有更复杂的控制电路
两个端口对同一主存操作有以下4种情况:
1.两个端口同时对不同的地址单元存取数据。
2.两个端口同时对同一地址单元读出数据。
3.两个端口同时对同一地址单元写入数病。——写入错误
4.两个端口同时对同一地址单元,一个写入数据,另一个读出数据。——读出错误(对比操作系统“读者写者问题”)
解决方法:置“忙”信号为0,由判断逻辑决定暂时关闭一个端口(即被延时),未被关闭的端口正常访问,被关闭的端口延长一个很短的时间段后再访问。
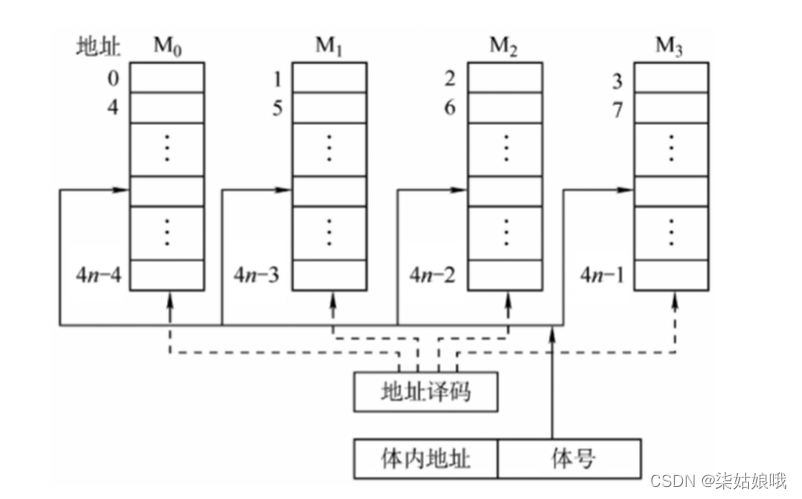
多体并行存储器
可理解为“四根内存条”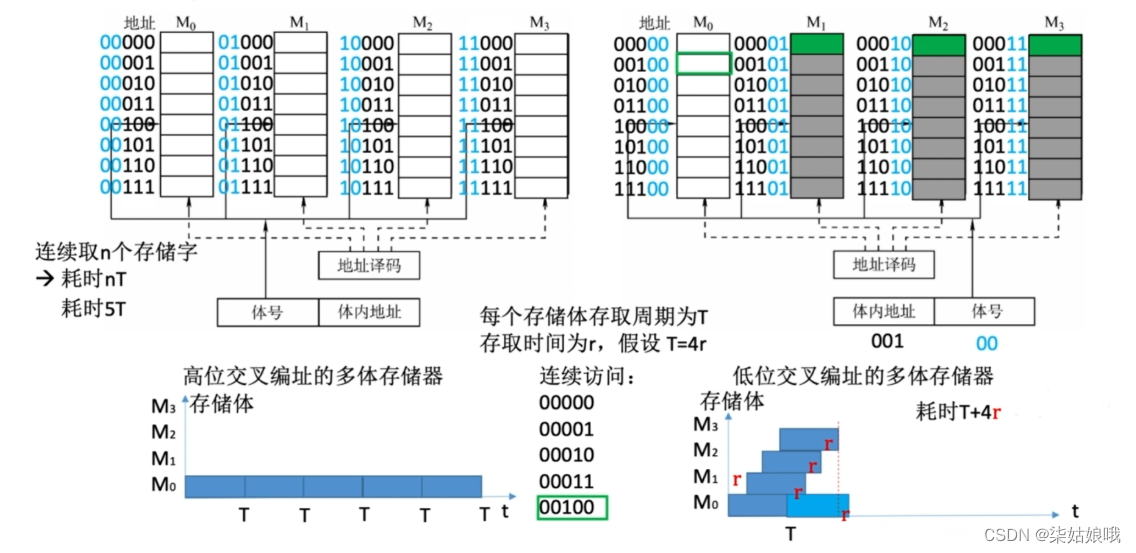
高位交叉编制连续存取n个存储字耗时nT
低位交叉编制连续存取n个存储字耗时T+(n-1)r,宏观上读写一个字的时间接近r
应该取几个“体”
采用“流水线”的方式并行存取(宏观上并行,微观上串行)
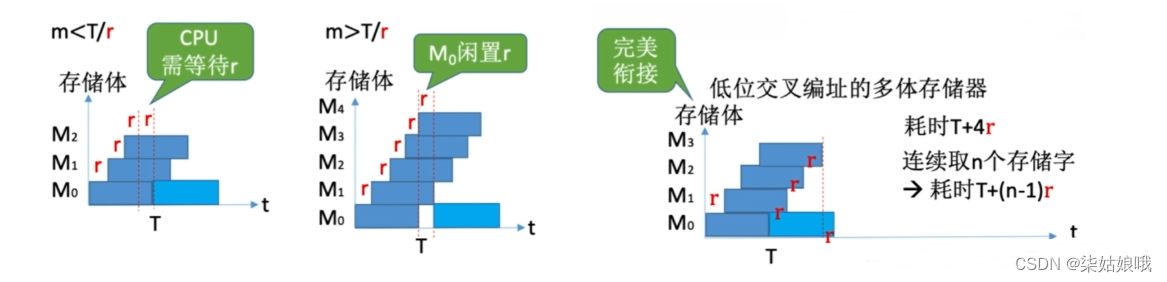
宏观上,一个存储周期内,m体交叉存储器可以提供的数据量为单个模块的m倍。
存取周期为T,存取时间为r,为了使流水线不间断,应保证模块数m≥T/r
即:存取周期为T,总线传输周期为r,为了使流水线不间断,应保证模块数m≥T/r
多模块存储器
多体并行存储器
每个模块都有相同的容量和存取速度。
各模块都有独立的读写控制鬼路、(地址寄存器和数据寄存器)它们既能并行工作,又能交叉工作。
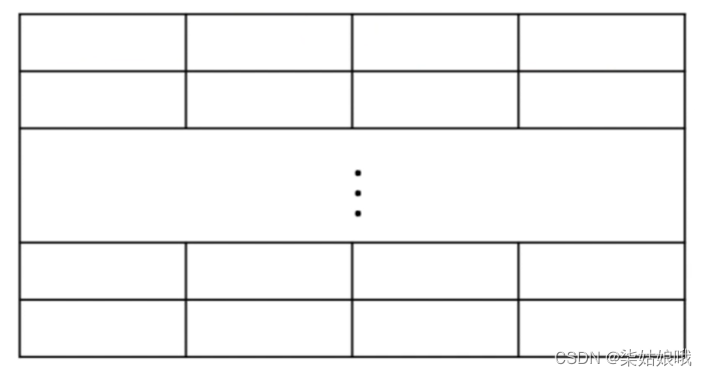
单体多字存储器
每个存储单元存储m个字
总线宽度也为m个字
一次并行读出m个字
每次只能同时取m个字,不能单独取其中某个字
指令和数据在主存内必须是连续存放的
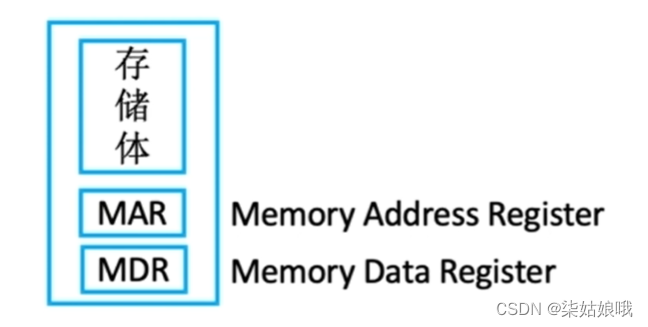
主存储器和CPU的连接
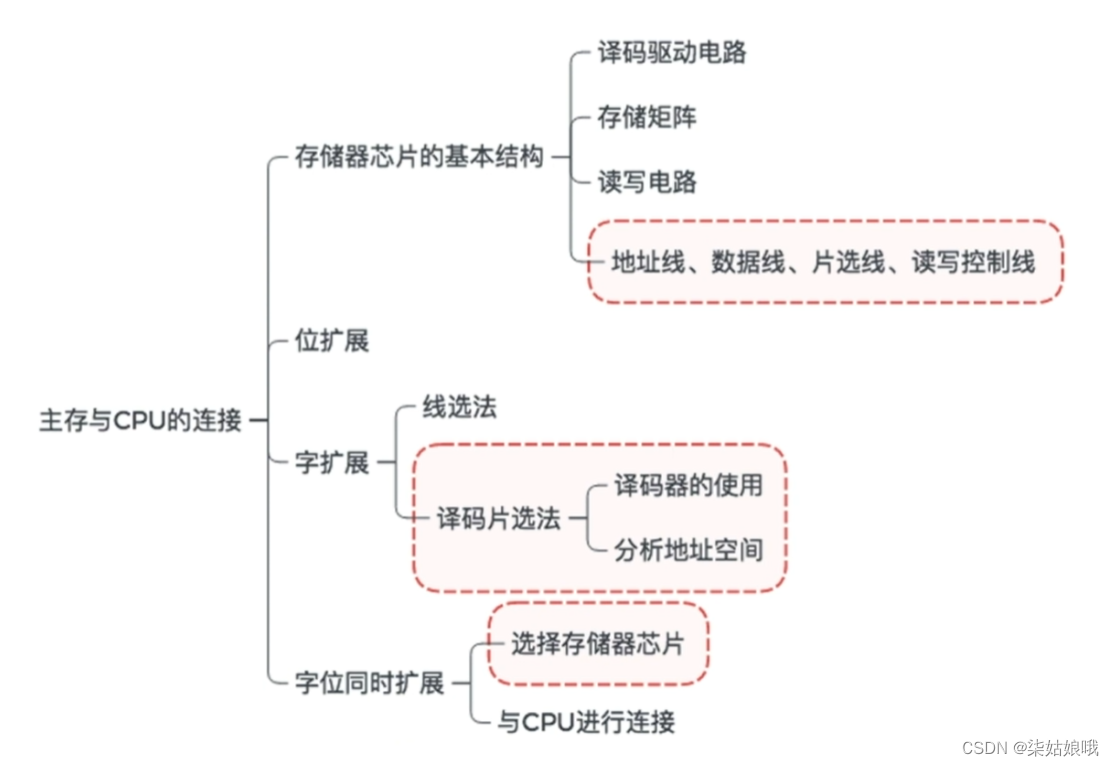
存储器芯片的输入输出信号
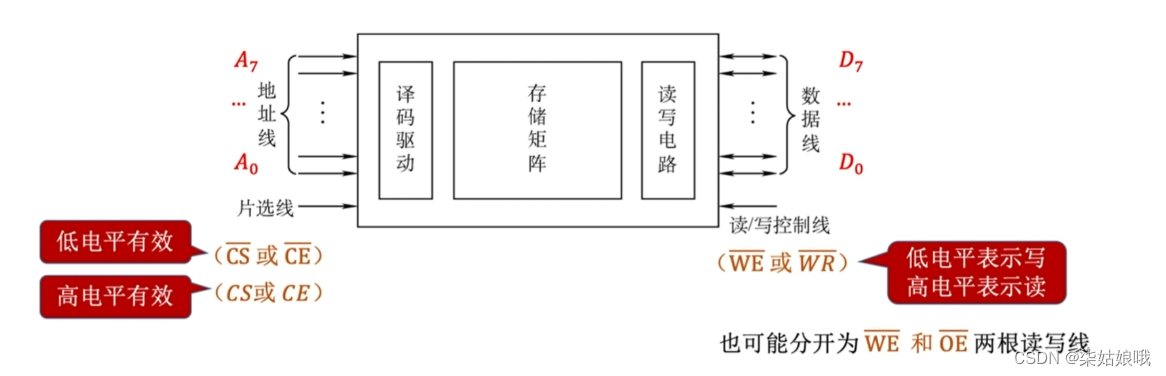
增加主存的存储字长-位扩展
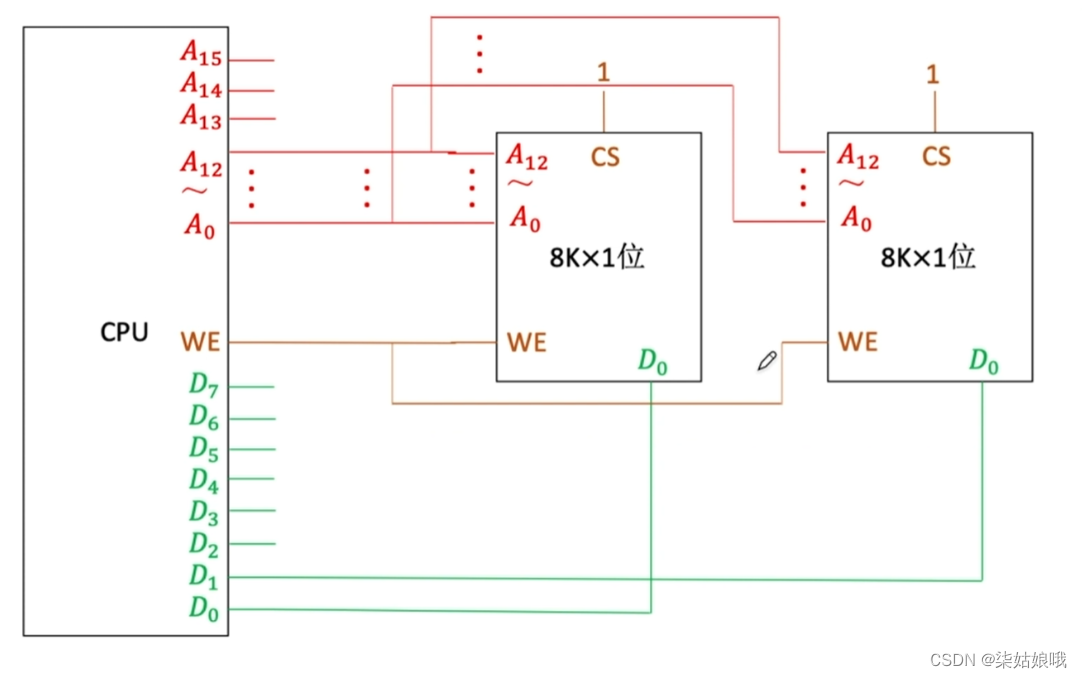
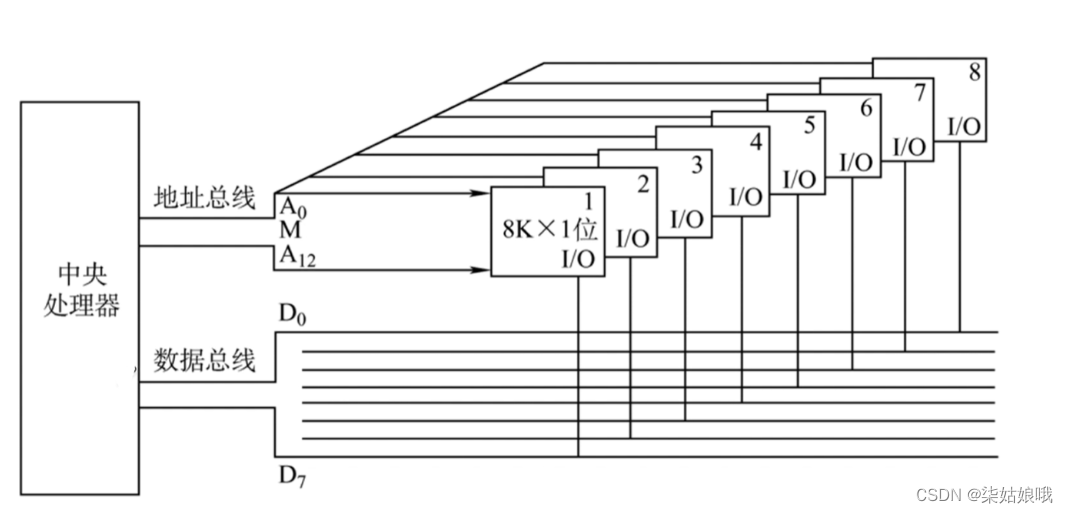
增加主存的存储字数-字扩展
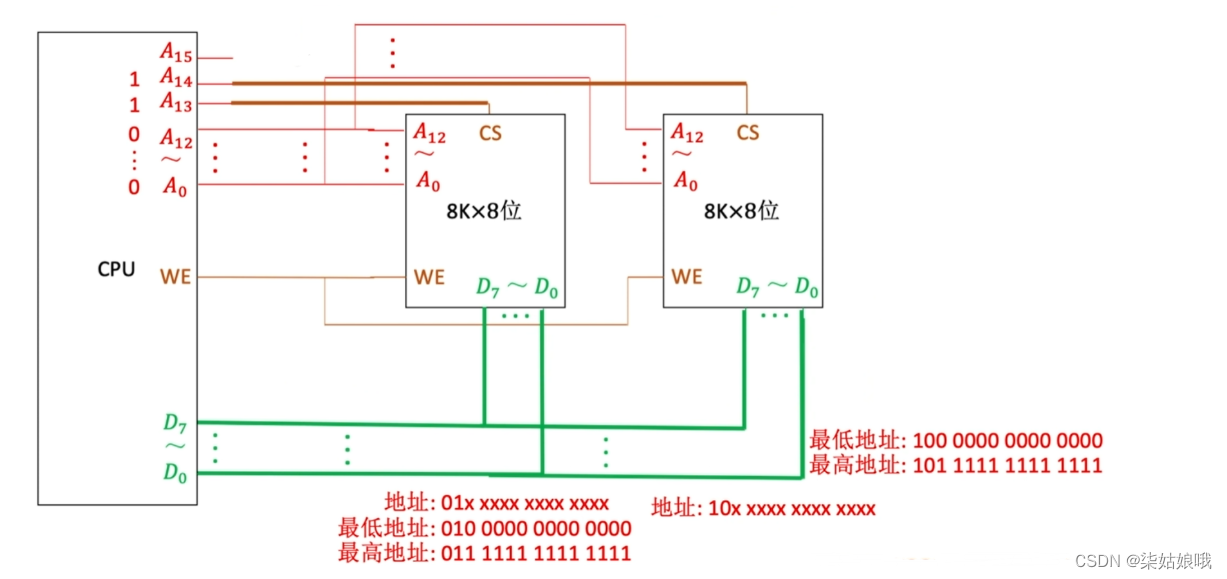
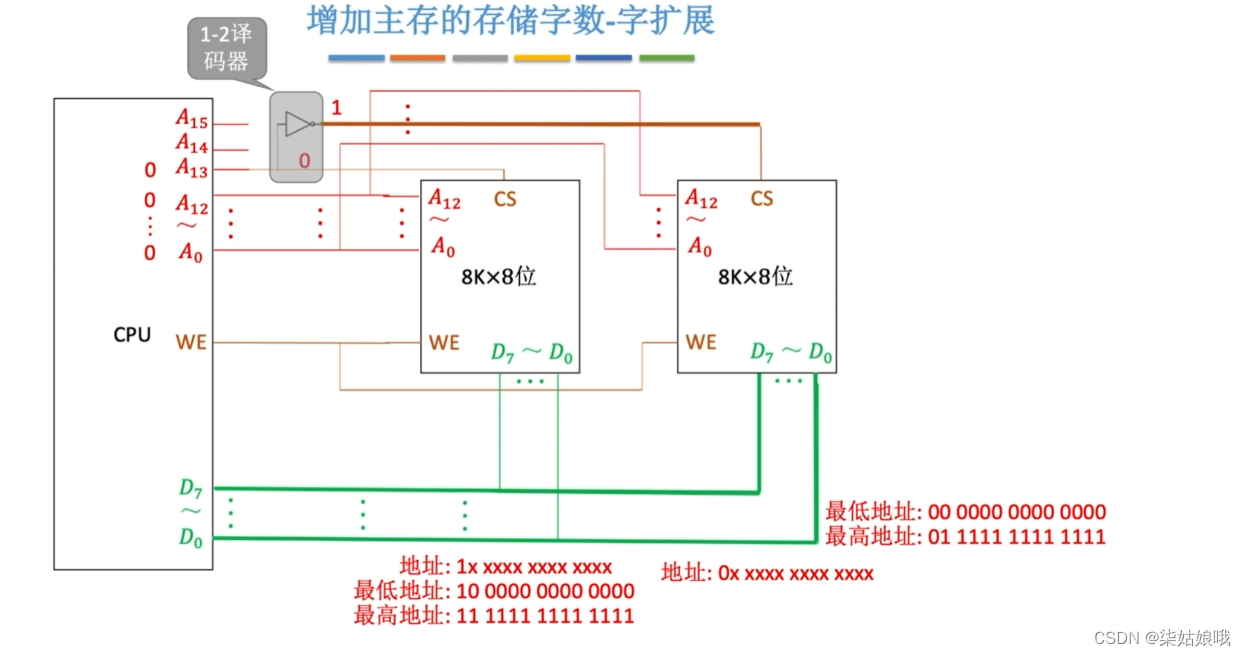
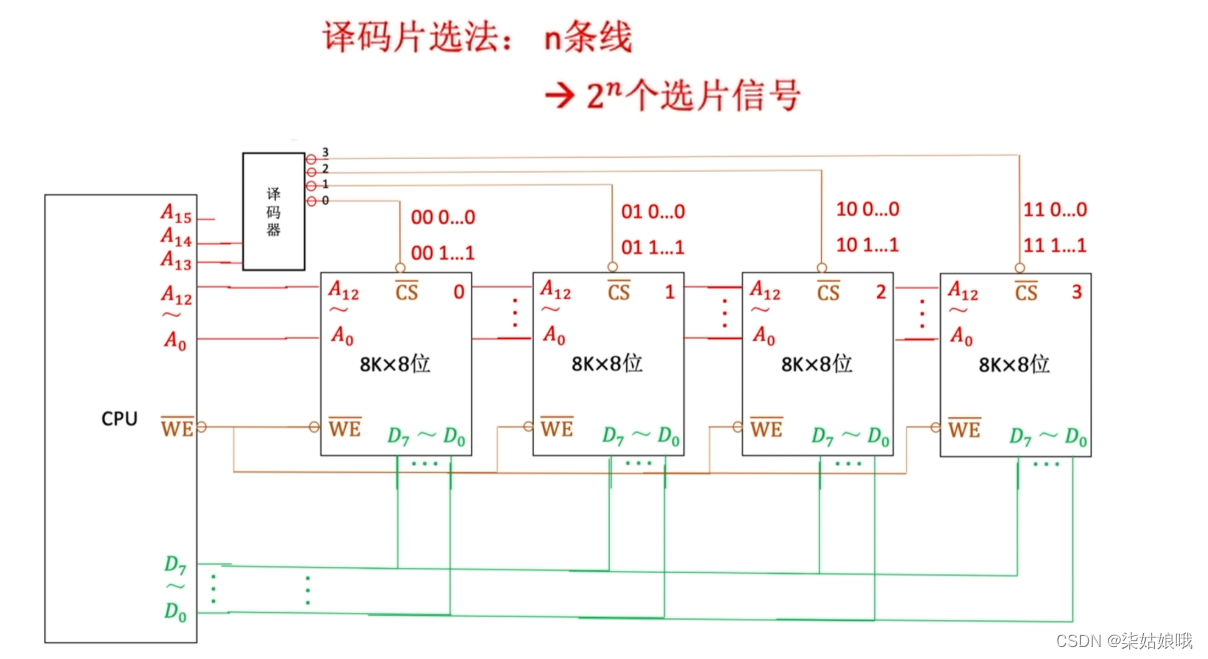
主存容量扩展-字扩展

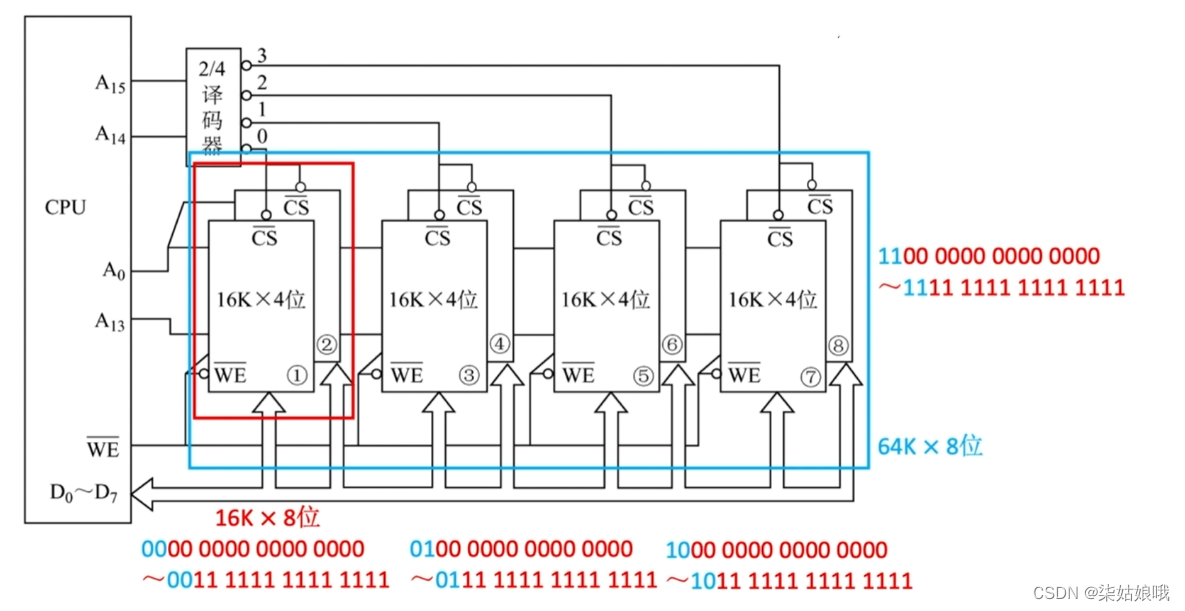
主存容量扩展-字位同时扩展
译码器
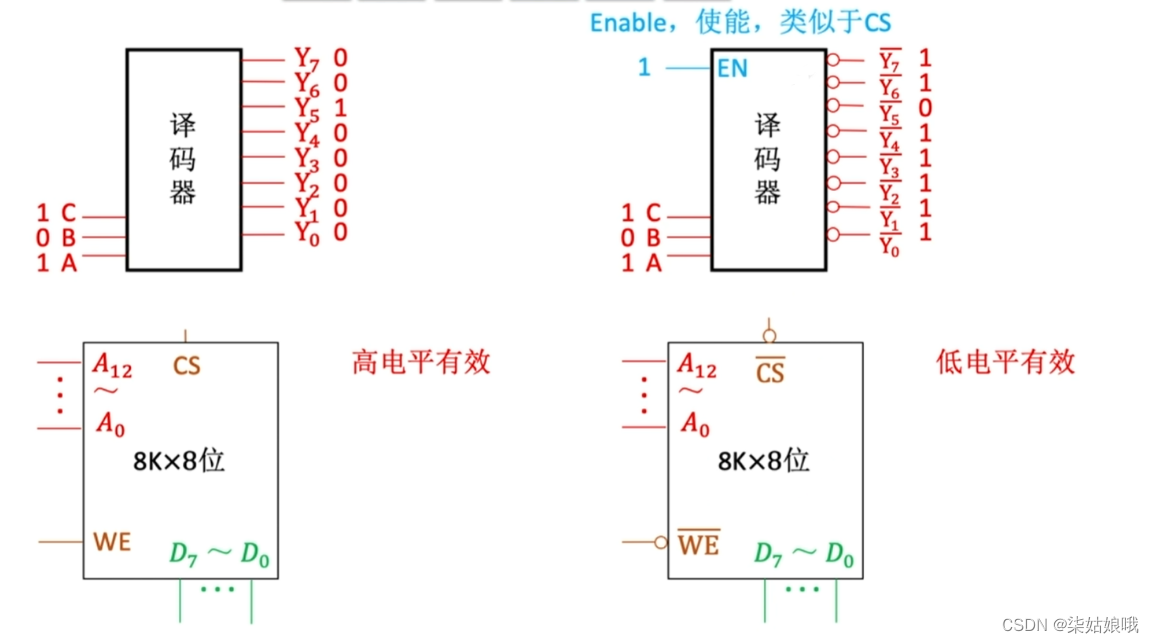
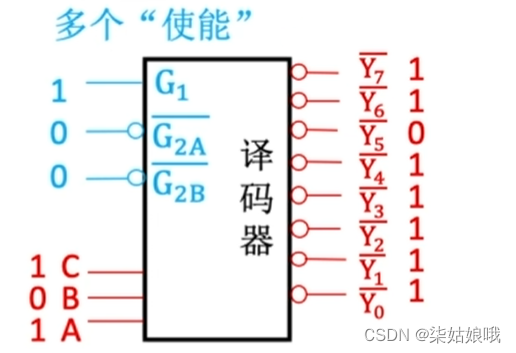
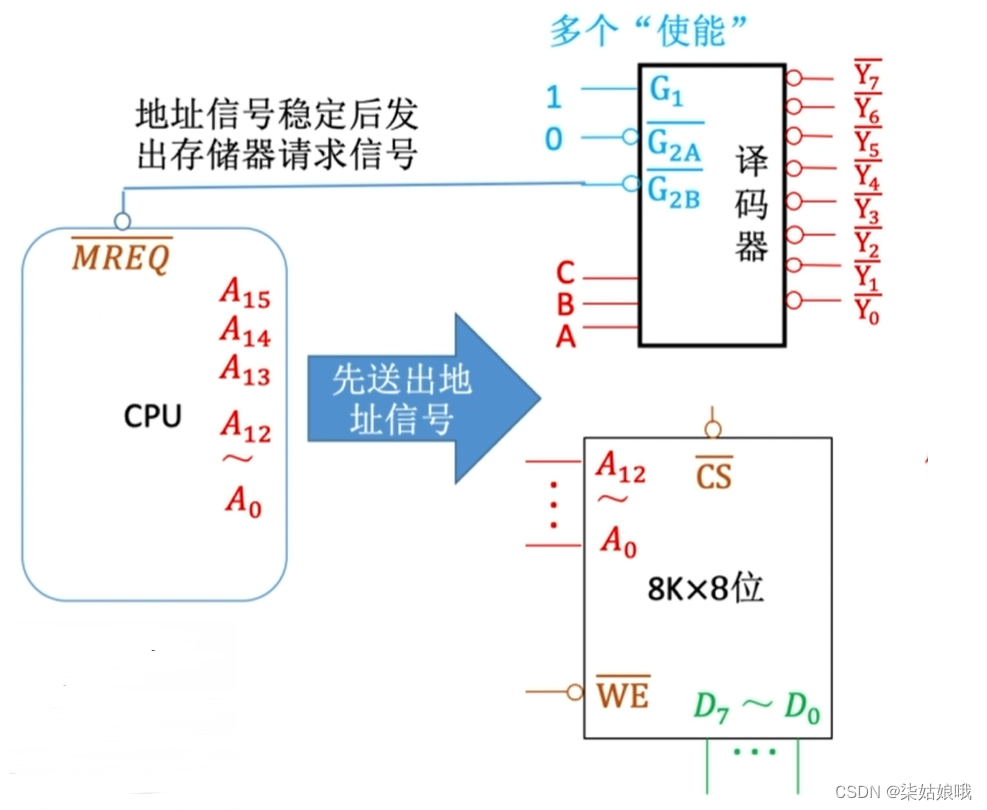
注:CPU可使用译码器的使能端控制片选信号的生效时间
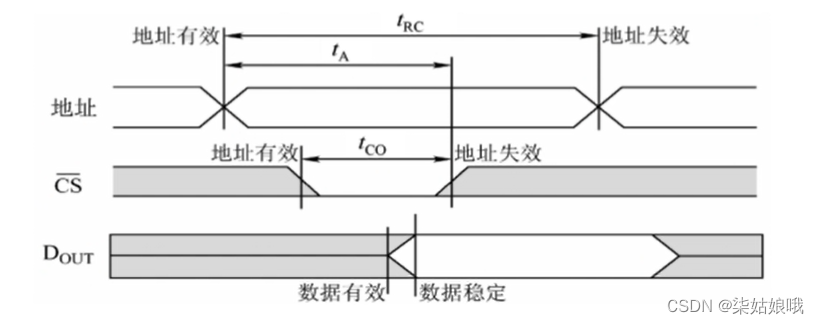
RAM的读周期
外存储器
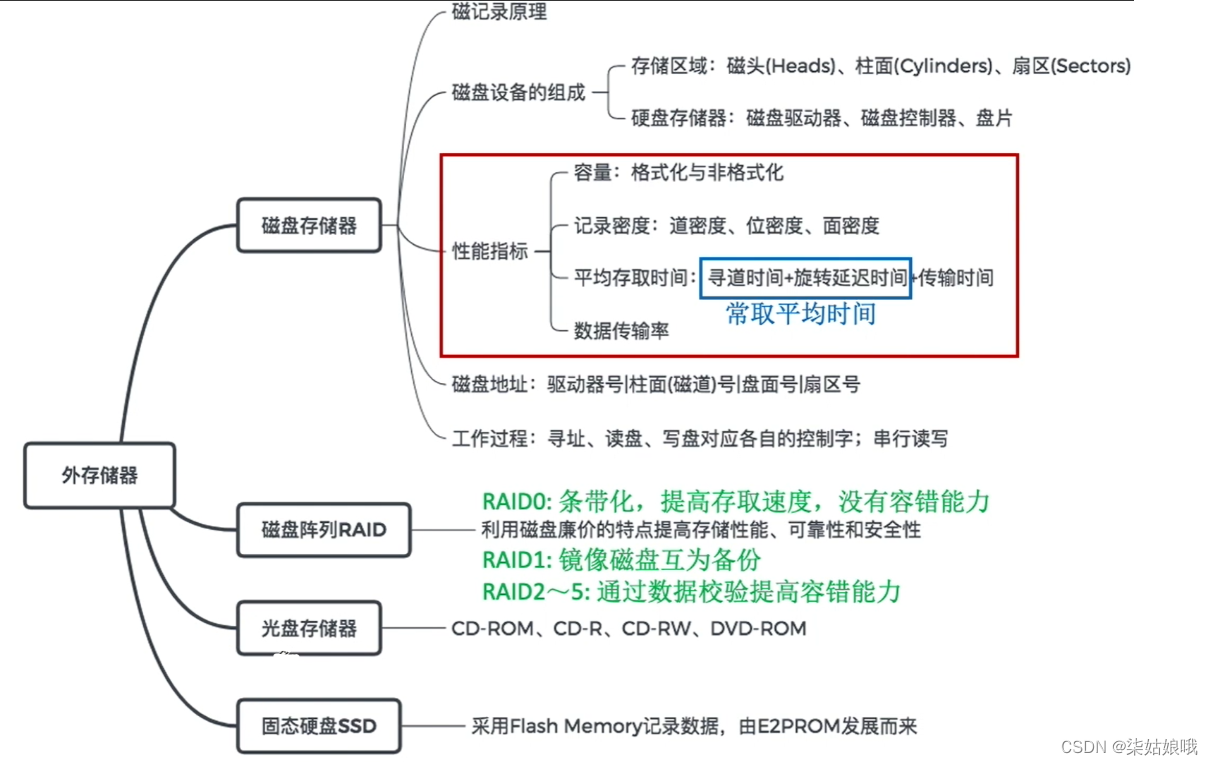
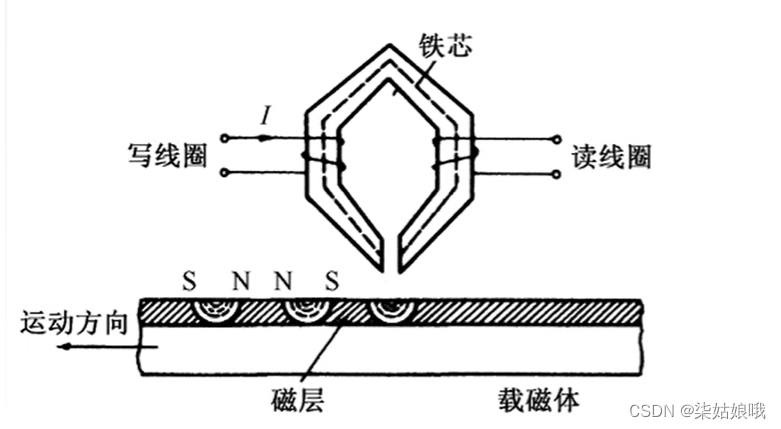
计算机的外存储器又称为辅助存储器,目前主要使用磁表面存储器。
所谓“磁表面存储”,是指把某些磁性材料薄薄地涂在金属铝或塑料表面上作为载磁体来存储信息。磁盘存储器、磁带存储器和磁鼓存储器均属于磁表面存储器。
磁表面存储器的优点:
①存储容量大,位价格低;
②记录介质可以重复使用;
③记录信息可以长期保存而不丢失,甚至可以脱机存档;
④非破坏性读出,读出时不需要再生。
磁表面存储器的缺点:
①存取速度慢;
②机械结构复杂;
③对工作环境要求较高。
磁盘存储器
磁盘驱动器:核心部件是磁头组件和盘片组件,温彻斯特盘是一种可移动头固定盘片的硬盘存储器。
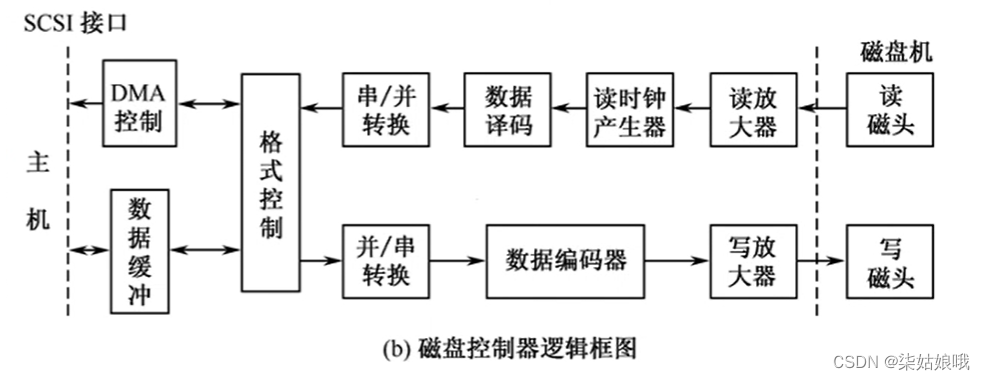
磁盘控制器:是硬盘存储器和主机的接口,主流的标准有IDE、SCSI、SATA等。
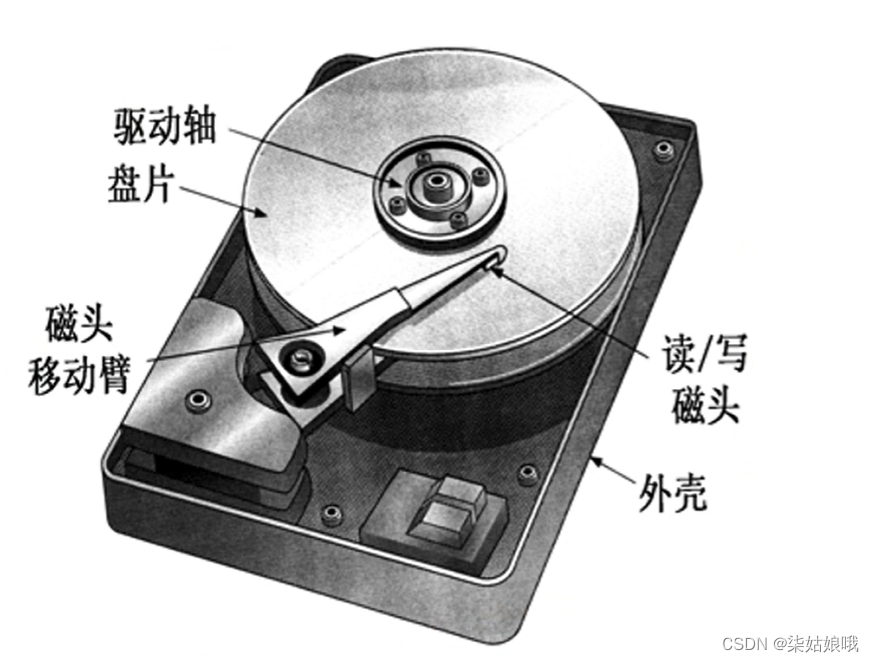

磁盘设备的组成
存储区域
一块硬盘含有若干个记录面,每个记录面划分为若干条磁道,而每条磁道又划分为若干个扇区,扇区(也称块)是磁盘读写的最小单位,也就是说磁盘按块存取。

硬盘存储器
硬盘存储器由磁盘驱动器、磁盘控制器和盘片组成。
磁盘驱动器:核心部件是磁头组件和盘片组件,温彻斯特盘是一种可 移动头固定盘片的硬盘存储器。
磁盘控制器:是硬盘存储器和主机的接凹,主流的标准有IDE、SCSI、 SATA等。
磁盘的性能指标
磁盘的容量
一个磁盘所能存储的字节总数称为磁盘容量。磁盘容量有非格式化容量和格式化容量之分。
非格式化容量是指磁记录表面可以利用的磁化单元总数。
格式化容量是指按照某种特定的记录格式所能存储信息的总量。
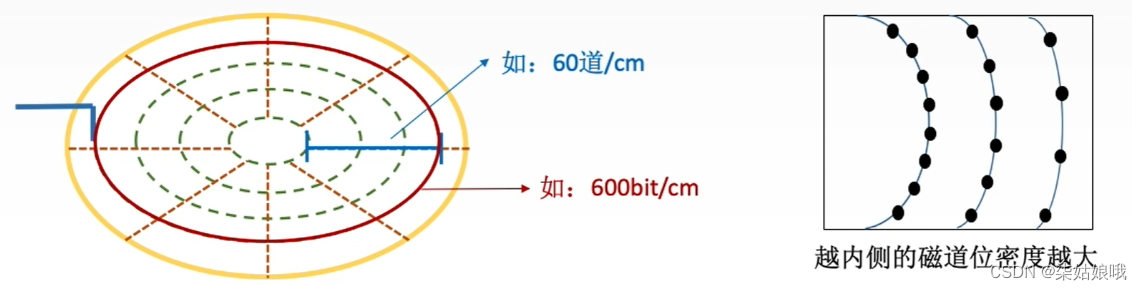
记录密度
记录密度是指盘片单位面积上记录的二进制的信息量,通常以道密度、位密度和面密度表示。
道密度是沿磁盘半径方向单位长度上的磁道数;
位密度是磁道单位长度上能记录的二进制代码位数;
面密度是位密度和道密度的乘积。
注意:磁盘所有磁道记录的信息量一定是相等的,并不是圆越大信息越多,故每个磁道的位密度都不同。
平均存取时间
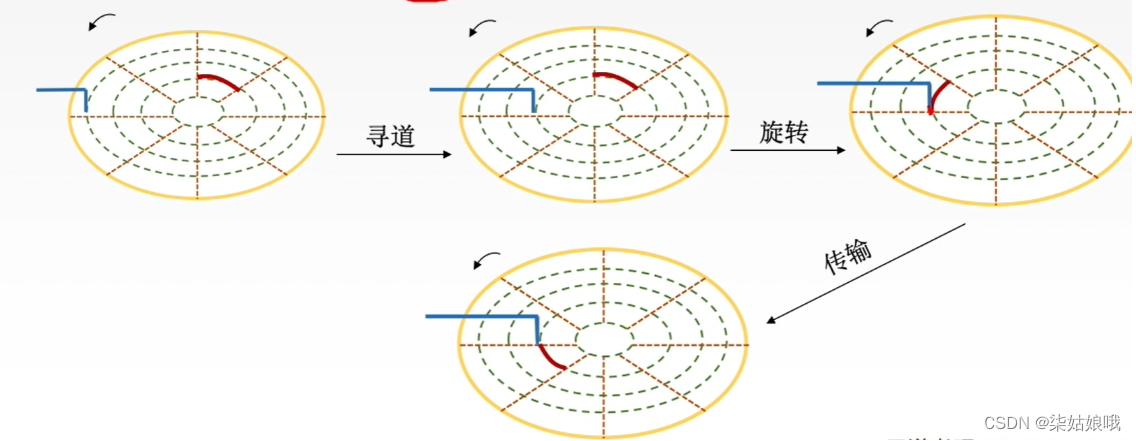
平均存取时间=寻道时间(磁头移动到目的磁道)+旋转延迟时间(磁头定位到所在扇区)+传输时间(传输数据所花费的时间)
数据传输率
磁盘存储器在单位时间内向主机传送数据的字节数,称为数据传输率。

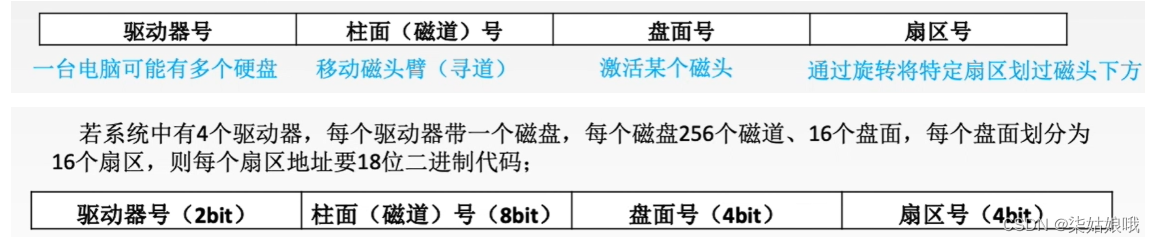
磁盘地址
主机向磁盘控制器发送寻址信息,磁盘的地址一般如图所示:
磁盘的工作过程
硬盘的主要操作是寻址,读盘、写盘。每个操作都对应一个控制字,硬盘工作时,第一步是取控制字,第二步是执行控制字。
硬盘属于机械式部件,其读写操作是串行的,不可能在同一时刻既读又写,也不可能在同一时刻读两组数据或写两组数据。
磁盘阵列
RAID ( Redundant Array of Inexpensive Disks,廉价冗余磁盘阵列)是将多个独立的物理磁盘组成一个独立的逻辑盘,数据在多个物理盘上分割交叉存储、并行访问,具有更好的存储性能、可靠性和安全性。
RAID的分级如下所示。在RAID1~RAID5的几种方案中,无论何时有磁盘损坏,都可以随时拔出受损的磁盘再插入好的磁盘,而数据不会损坏。
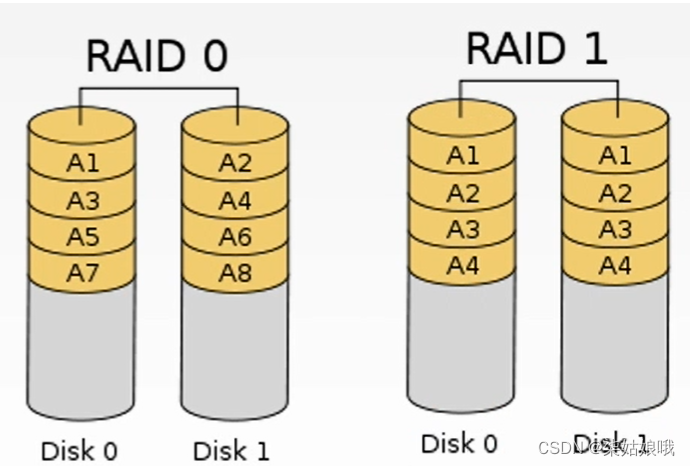
- RAID0:无冗余和无校验的磁盘阵列。
- RAID1:镜像磁盘阵列。
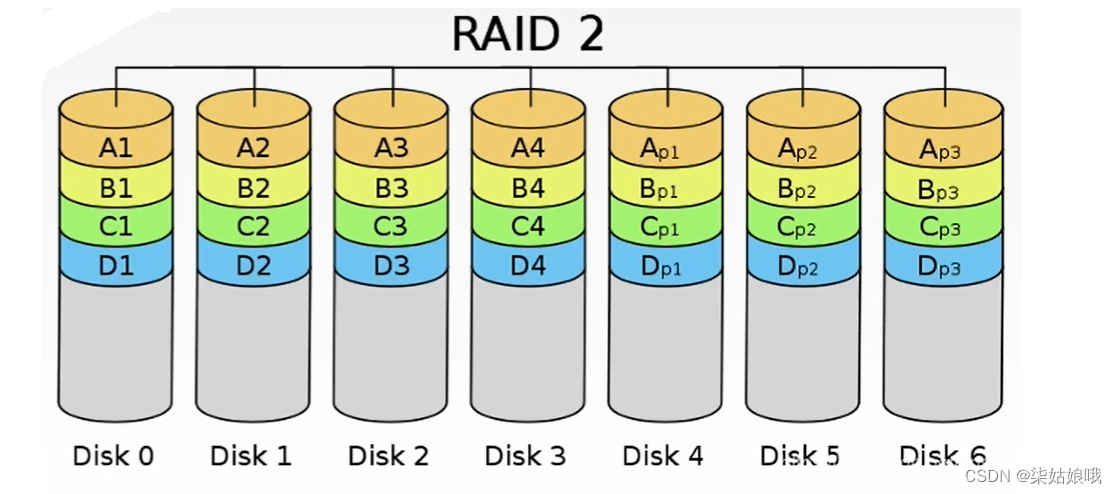
- RAID2:采用纠错的海明码的磁盘阵列。
- RAID3:位交叉奇偶校验的磁盘阵列。
- RAID4:块交叉奇偶校验的磁盘阵列。
- RAID5:无独立校验的奇偶校验磁盘阵列。
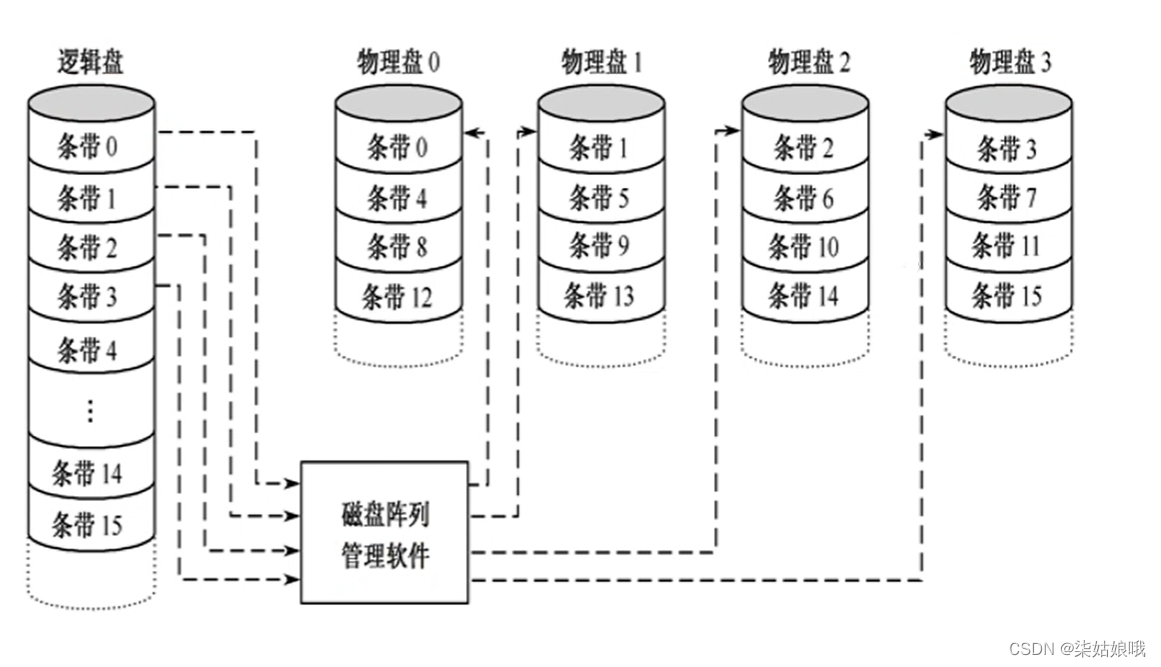
RAID0:逻辑上相邻的两个扇区在物理上存到两个磁盘,类比第三章“低位交叉编址的多体存储器”。RAID0把连续多个数据块交替地存放在不同物理磁盘的扇区中,几个磁盘交叉并行读写,不仅扩大了存储容量,而且提高了磁盘数据存取速度,但RAID0没有容错能力。
RAID1:很粗暴,存两份数据。RAID1是为了提高可靠性,使两个磁盘同时进行读写,互为备份,如果一个磁盘出现故障,可从另一磁盘中读出数据。两个磁盘当一个磁盘使用,意味着容量减少一半。
RAID2:逻辑上连续的几个bit物理上分散存储在各个盘中4bit信息位+3bit海明校验位一―可纠正一位错
RAID通过同时使用多个磁盘,提高了传输率;通过在多个磁盘上并行存取来大幅提高存储系统的数据吞吐量;通过镜像功能,可以提高安全可靠性;通过数据校验,可以提供容错能力。
光盘存储器
光盘存储器是利用光学原理读/写信息的存储装置,它采用聚焦激光束对盘式介质以非接触的方式记录信息。
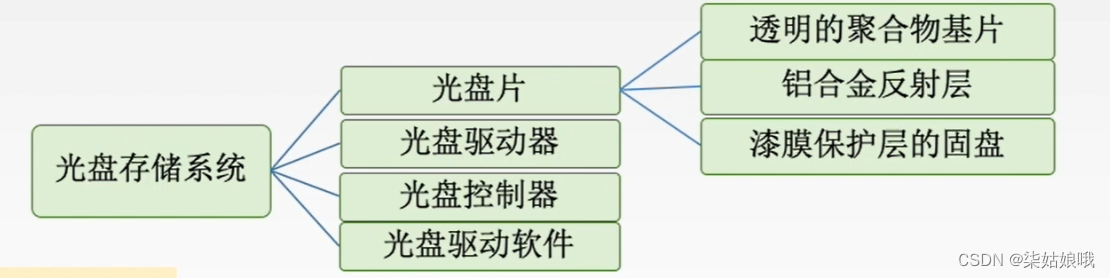
特点:
- 存储密度高
- 携带方便
- 成本低
- 容量大
- 存储期限长
- 容易保存等
光盘类型如下:
CD-ROM:只读型光盘,只能读出其中内容,不能写入或修改。
CD-R:只可写入一次信息,之后不可修改。
CD-RW:可读可写光盘,可以重复读写。
DVD-ROM:高容量的CD-ROM,DVD表示通用数字化多功能光盘。
固态硬盘
在微小型高档笔记本电脑中,采用高性能Flash Memory作为硬盘来记录数据,这种“硬盘”称固态硬盘。
固态硬盘除了需要Flash Memory外,还需要其他硬件和软件的支持。
注:闪存(Flash Memory)是在E2PROM的基础上发展起来的,本质上是只读存储器。
Cache的基本概念和原理
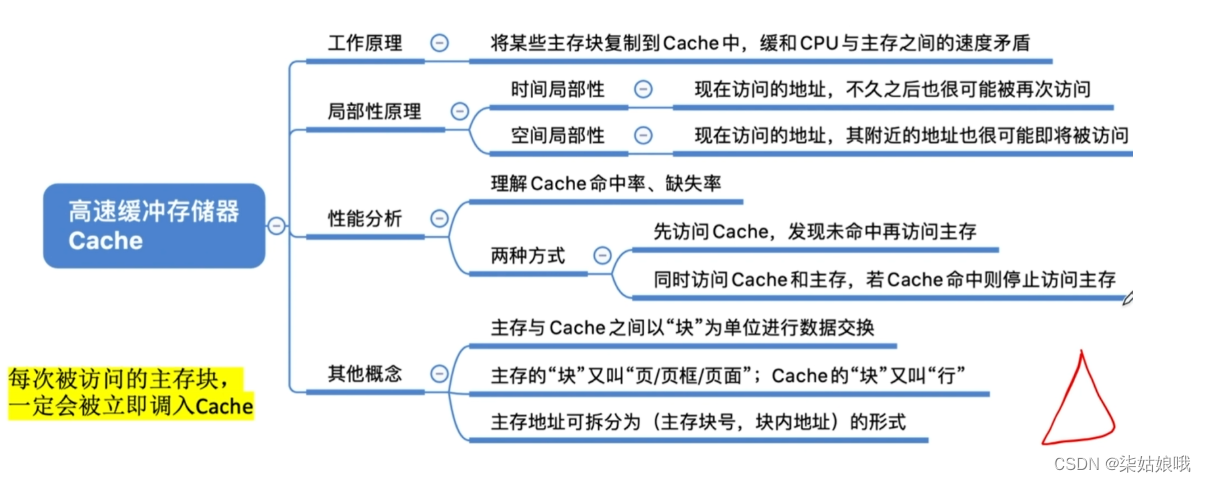
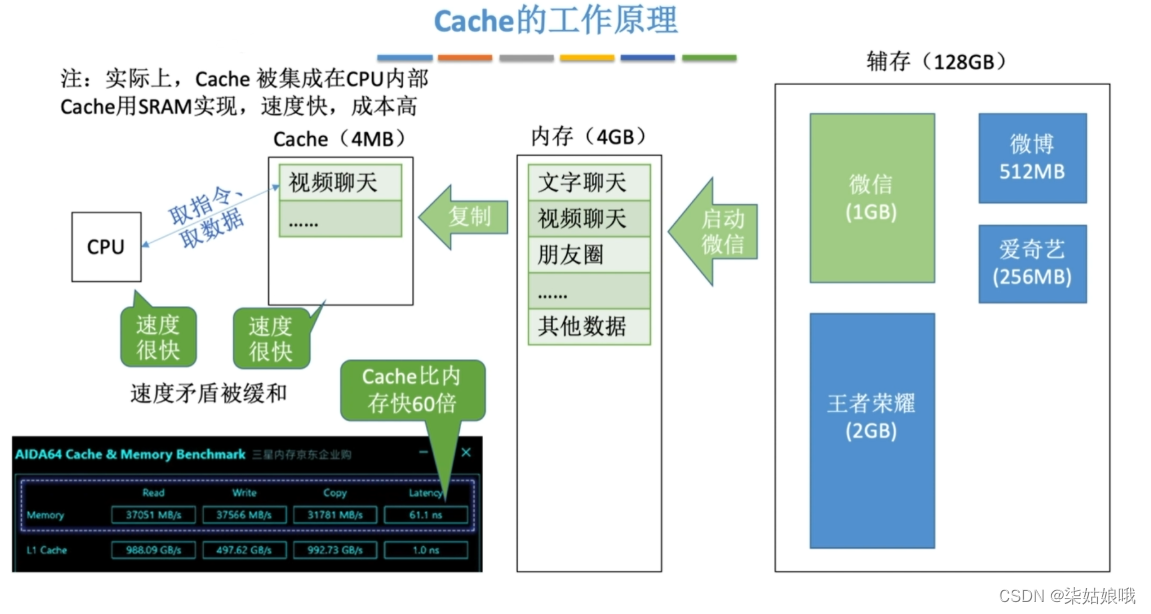
Cache的工作原理
注:实际上,Cache被集成在CPU内部Cache用SRAM实现,速度快,成本高
局部性原理
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息

性能分析
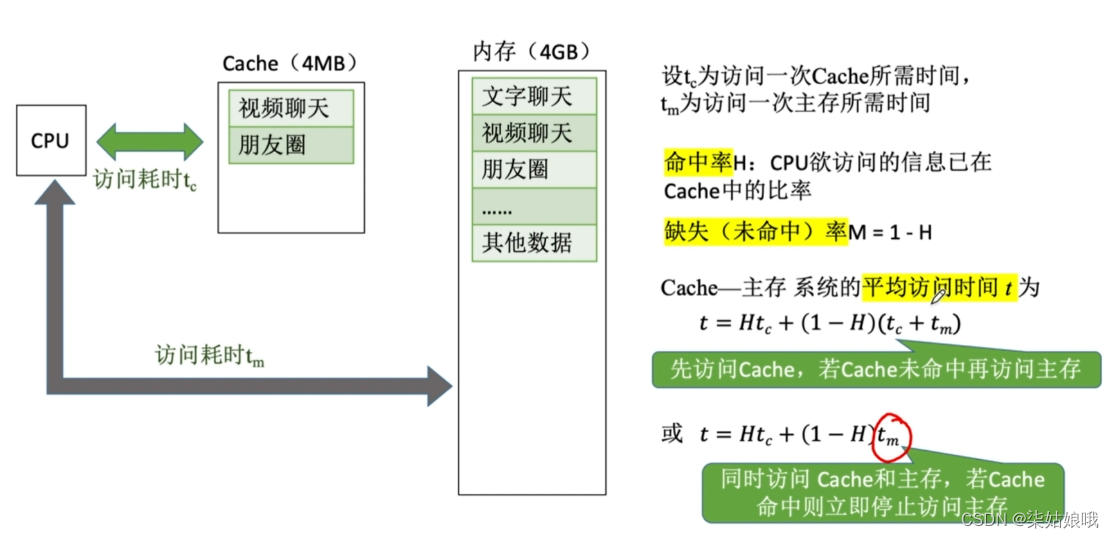
【例3-2】假设Cache的速度是主存的5倍,且Cache的命中率为95%,则采用Cache后,存储器性能提高多少(设Cache和主存同时被访问,若Cache命中则中断访问主存)?
设Cache的存取周期为t,则主存的存取周期为5t
若Cache和主存同时访问,命中时访问时间为t,未命中时访问时间为5t
平均访问时间为0.95×t+0.05×5t= 1.2t
故性能为原来的5t/1.2t≈4.17倍
若先访问Cache再访问主存,命中时访问时间为t,未命中时访问时间为t+5t
平均访问时间为Ta=0.95×t+0.05×6t=1.25t
故性能为原来的5t/1.25t≈4倍
有待解决的问题
基于局部性原理,不难想到,可以把CPU目前访问的地址“周围”的部分数据放到Cache中。如何界定“周围”?
将主存的存储空间“分块”,如:每1KB为一块。主存与Cache之间以“块”为单位进行数据交换
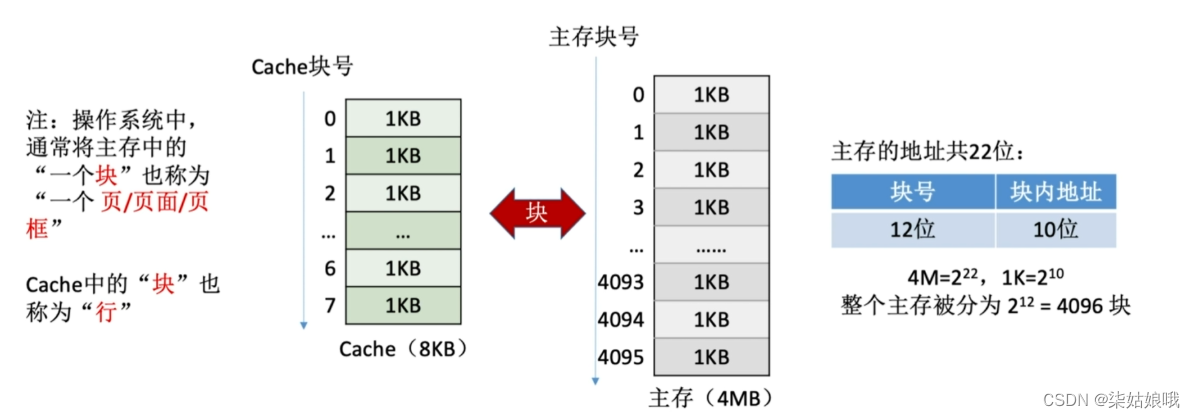
注意:每次被访问的主存块,一定会被立即调入Cache
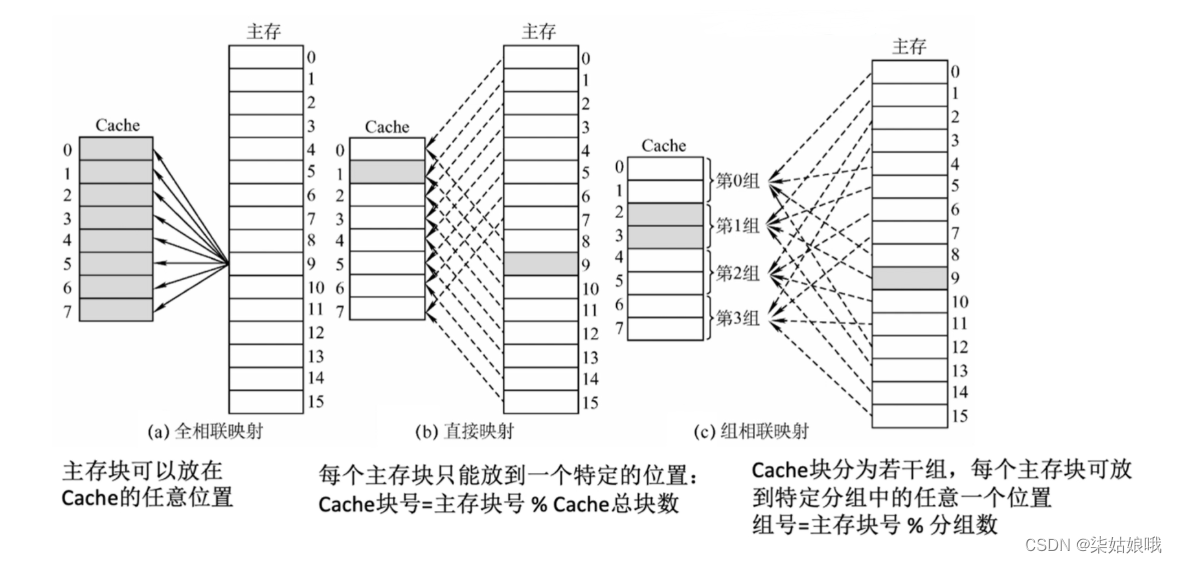
结合每种地址映射方式的地址结构思考:给定一个主存地址,如何拆分地址,并查找Cache、访存?

Cache和主存的映射方式
全相联映射(随意放)
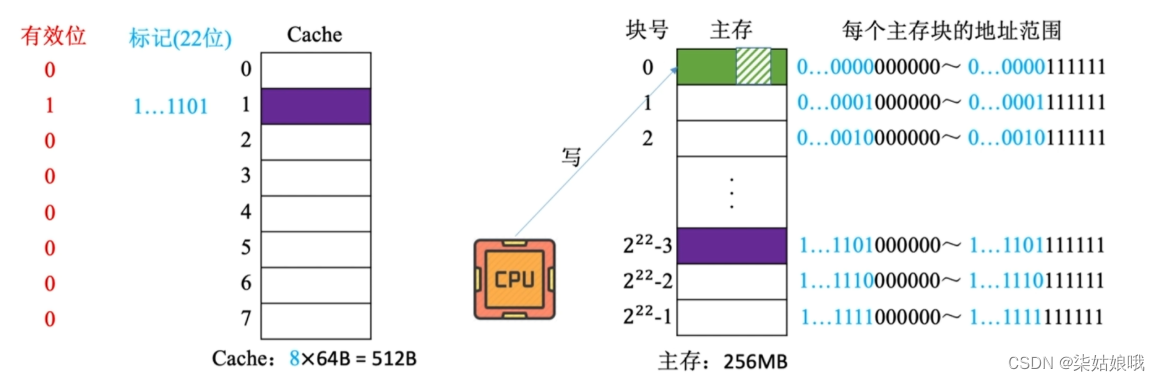
假设某个计算机的主存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行,行长为64B。
即Cache块,与主存块的大小相等
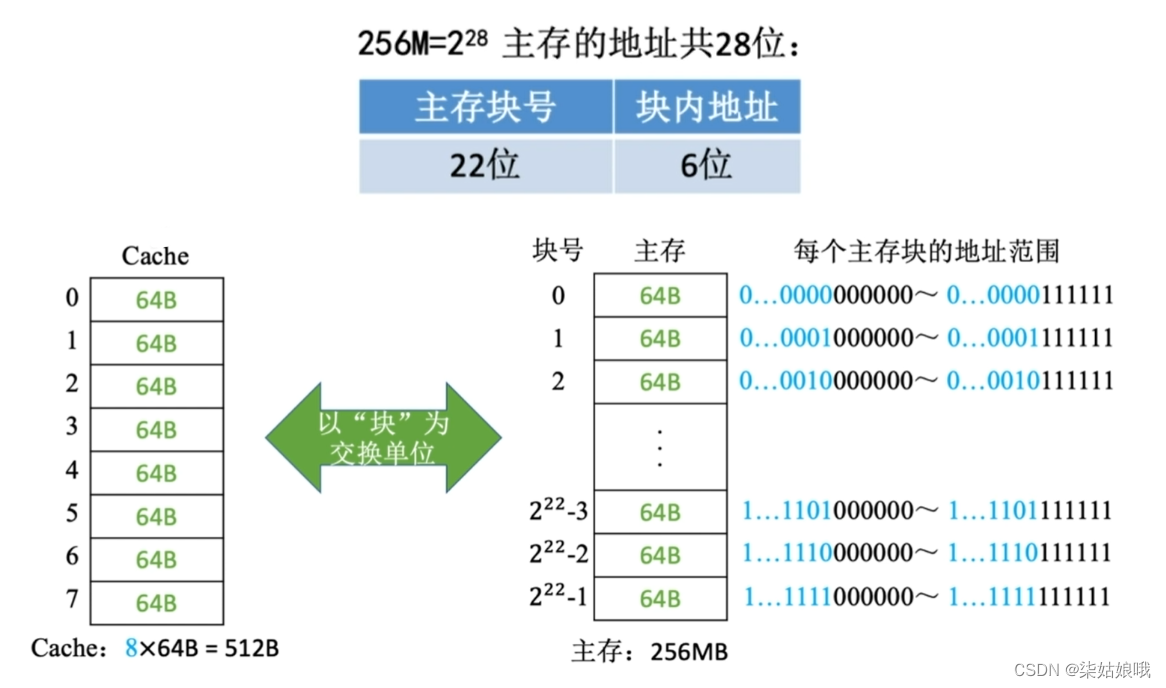
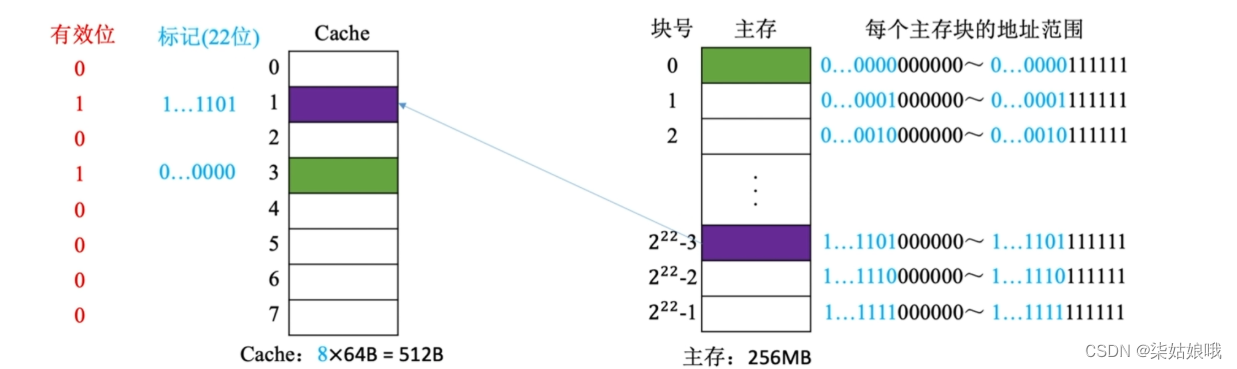
CPU 访问主存地址1…1101001110:
①主存地址的前22位,对比Cache中所有块的标记;
②若标记匹配且有效位=1,则cache命中,访问块内地址为001110的单元。
③若未命中或有效位=0,则正常访问主存
直接映射(只能放固定位置)
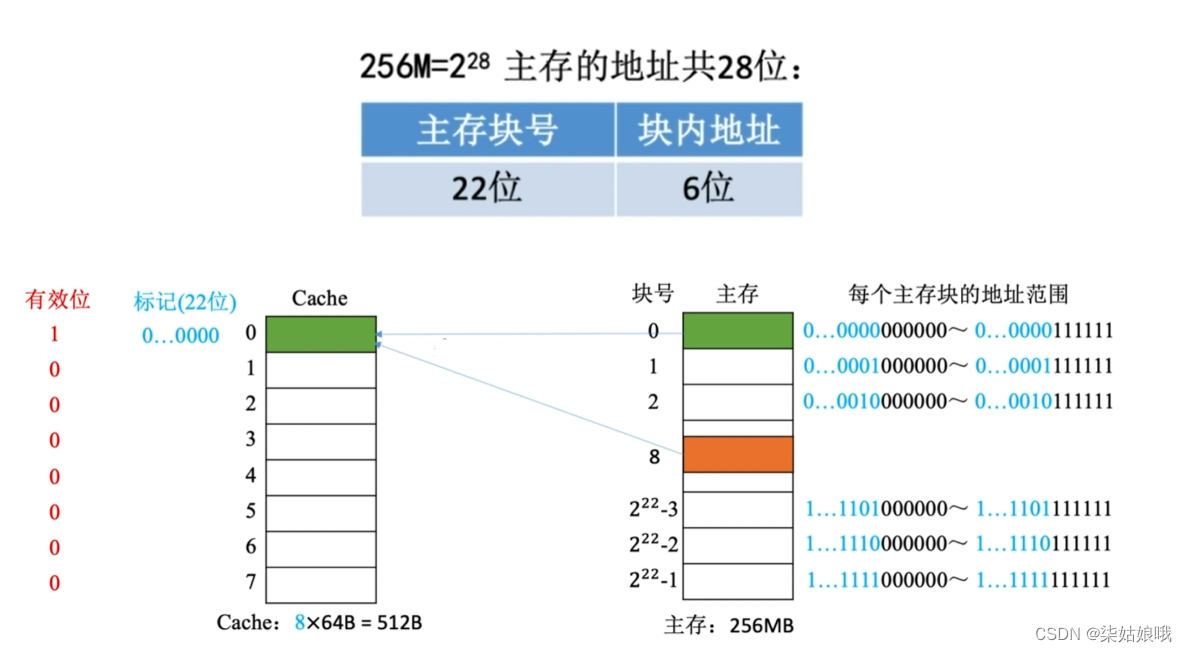
假设某个计算机的主存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行,行长为64B。
直接映射,主存块在cache中的位置=主存块号%cache总块数
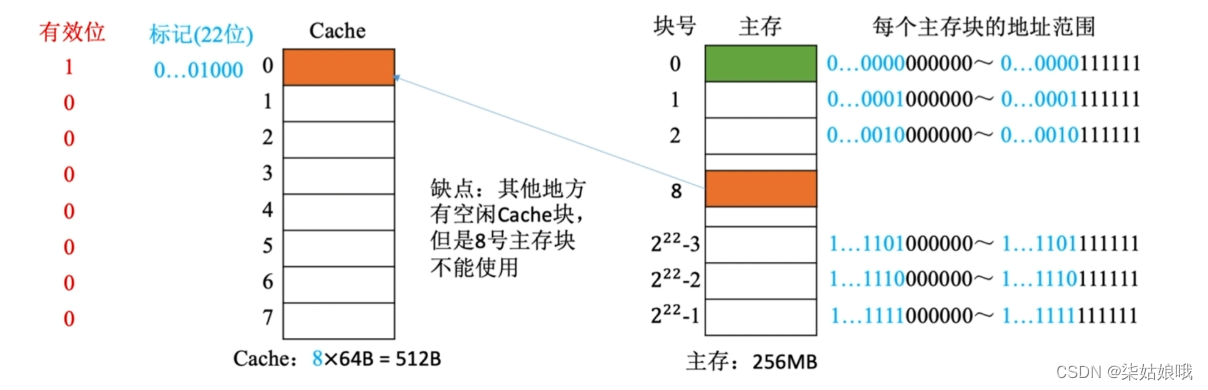
灵活性差,空间利用率低

CPU 访问主存地址0…01000 001110 :
①根据主存块号的后3位确定Cache行
②若主存块号的前19位与Cache标记匹配且有效位=1,则Cache命中,访问块内地址为001110的单元。
③若未命中或有效位=0,则正常访问主存
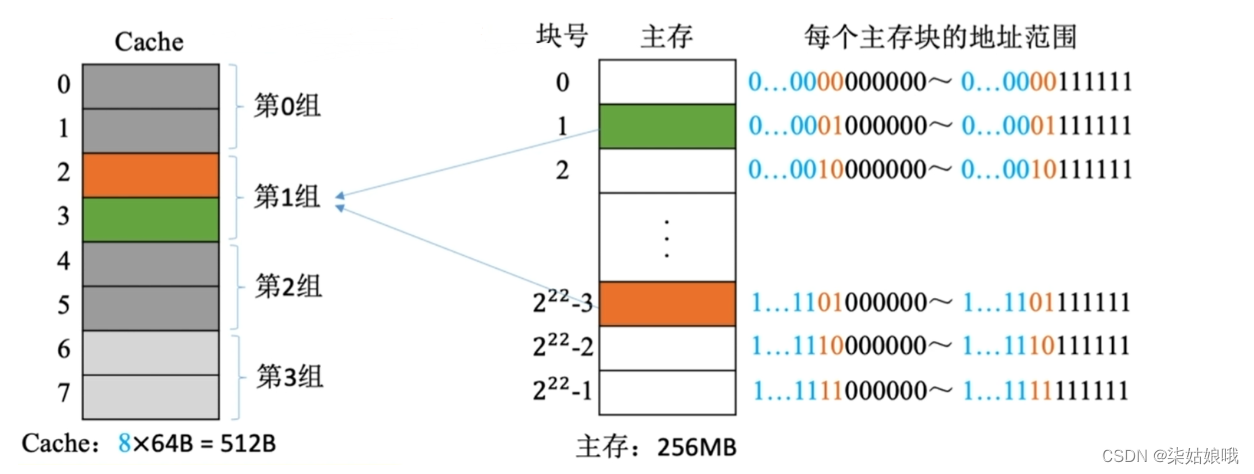
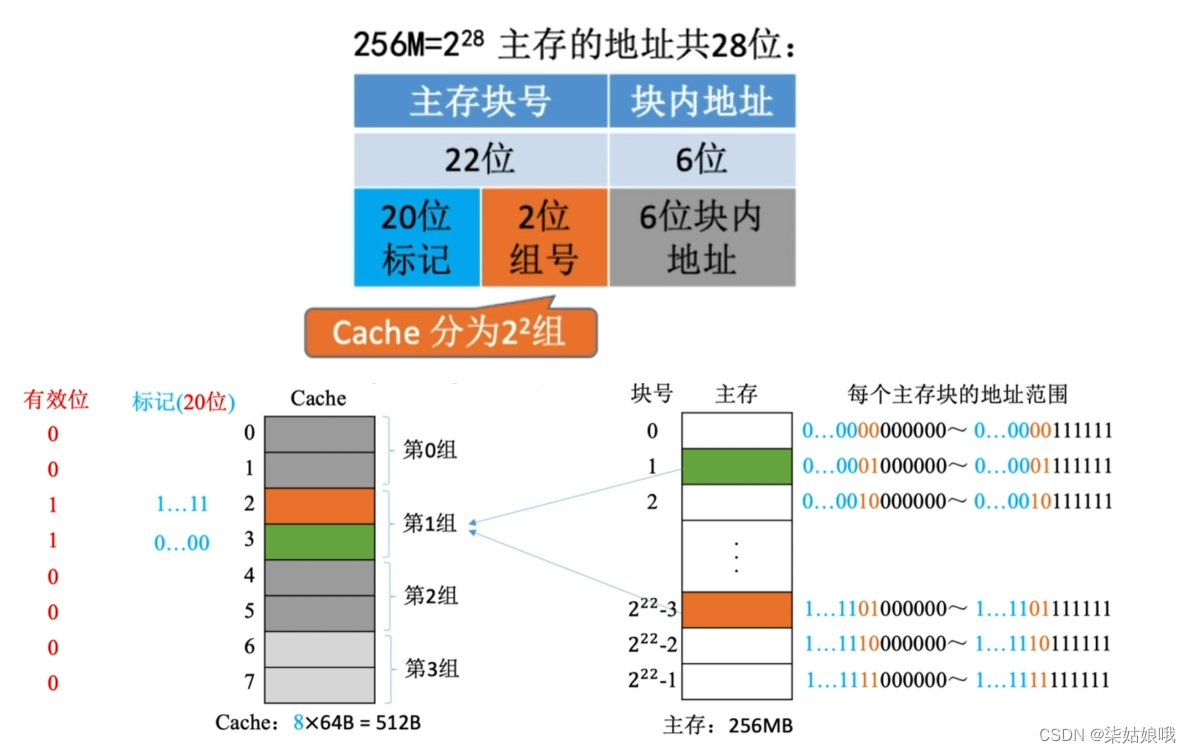
组相联映射(可放到特定分组)
假设某个计算机的主存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行,行长为64B。
组相联映射,所属分组=主存块号%分组数
2路组相联映射――2块为一组,分四组
Cache替换算法
全相联映射Cache完全满了才需要替换需要在全局选择替换哪一块
直接映射如果对应位置为空,则毫无选择地选择直接替换
组相联映射分组内满了才需要替换,需要在分组内选择替换哪一块
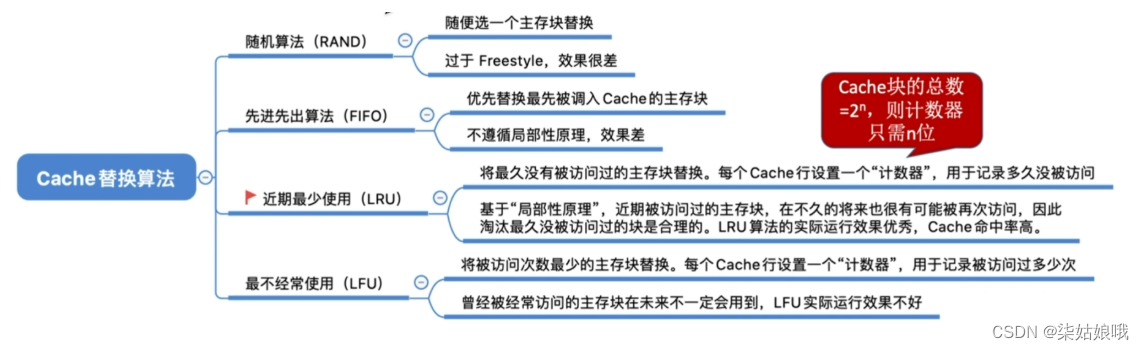
随机算法(RAND)
随机算法(RAND, Random)一一若Cache已满,则随机选择一块替换。
设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
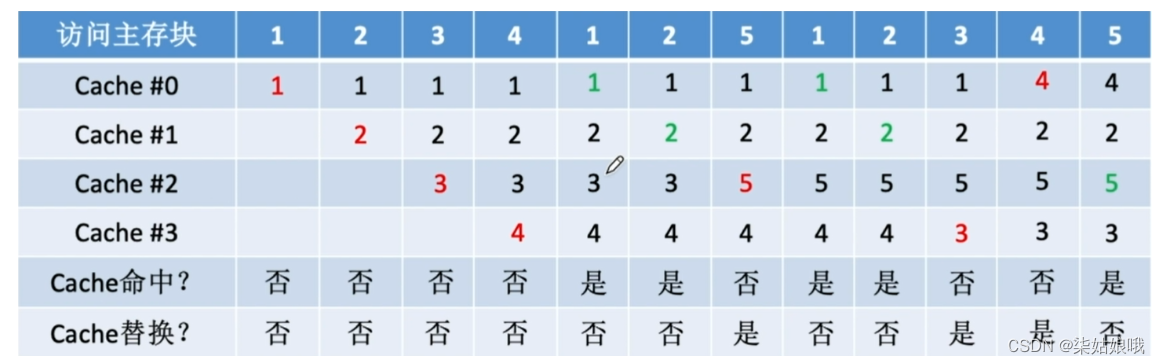
随机算法――实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定
先进先出算法(FIFO)
先进先出算法( FIFO, First In First Out)—―若Cache已满,则替换最先被调入Cache的块
设总共有4个Cache块,初始整个Cache为空。
采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
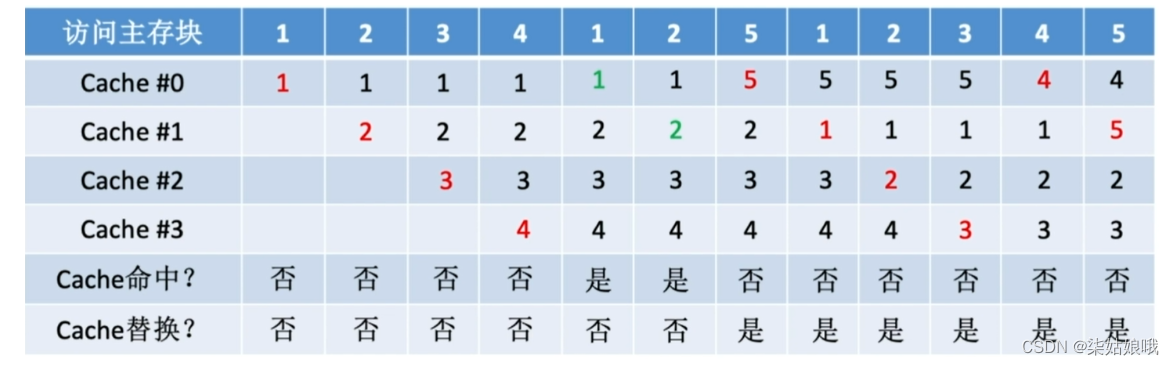
先进先出算法―一实现简单,最开始按#0#1#2#3放入Cache,之后轮流替换#0#1#2#3
FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的
抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入)
近期最少使用算法(LRU)
近期最少使用算法(LRU, Least Recently Used )-—为每一个Cache块设置一个“计数器”,用于记录每个Cache块已经有多久没被访问了。当Cache满后替换“计数器”最大的
设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}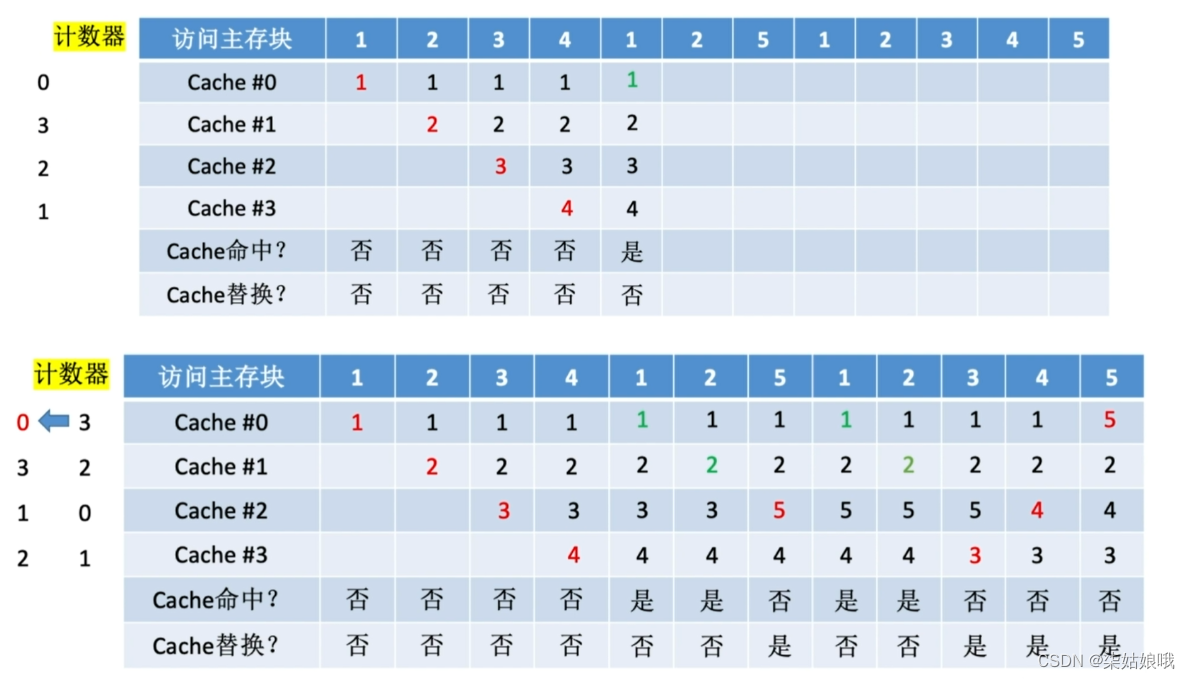
Cache块的总数=2^n,则计数器只需n位且Cache装满后所有计数器的值一定不重复
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
LRU算法―-基于“局部性原理”,近期被访问过的主存块,在不久的将来也很有可能被再次访问,因此淘汰最久没被访间过的块是合理的。LRU算法的实际运行效果优秀,Cache命中率高。
若被频繁访问的主存块数量>Cache行的数量,则有可能发生抖动
最不经常使用算法(LFU)
最不经常使用算法(LFU, Least Frequently Used )一—为每一个Cache块设置一个“计数器”,用于记录每个Cache块被访问过几次。当Cache满后替换“计数器”最小的
设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行。若有多个计数器最小的行,可按行号递增、或FIFO策略进
行选择
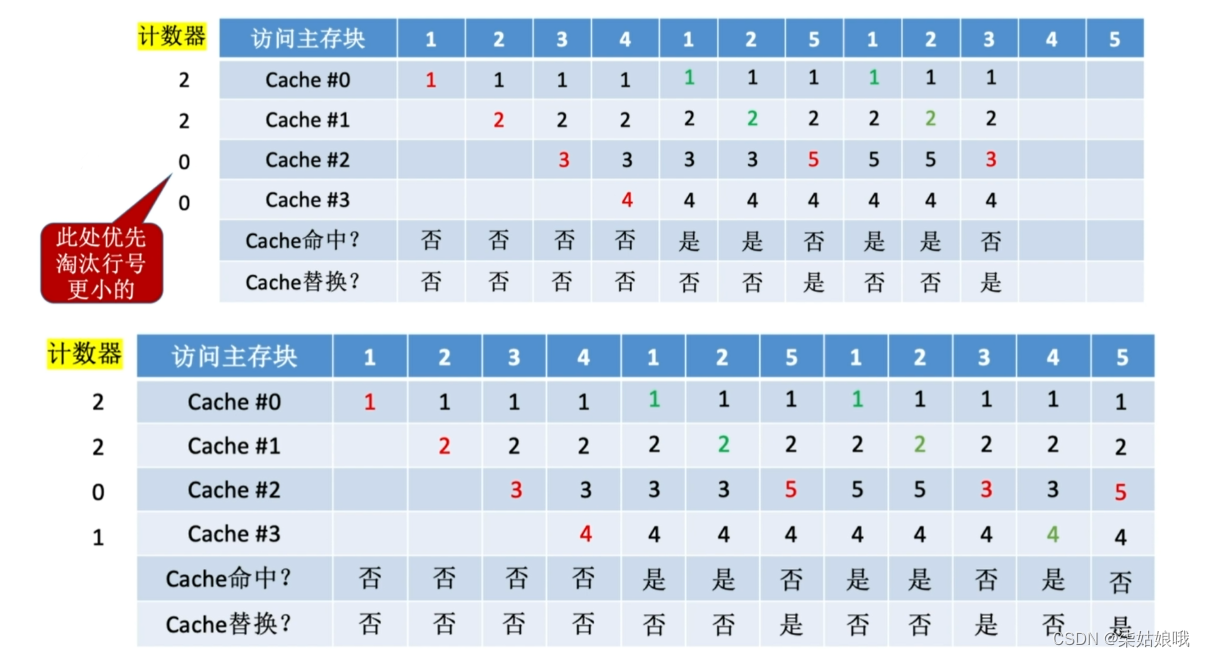
LFU算法――曾经被经常访问的主存块在未来不一定会用到(如:微信视频聊天相关的块),并没有很好地遵循局部性原理,因此实际运行效果不如LRU
Cache写策略
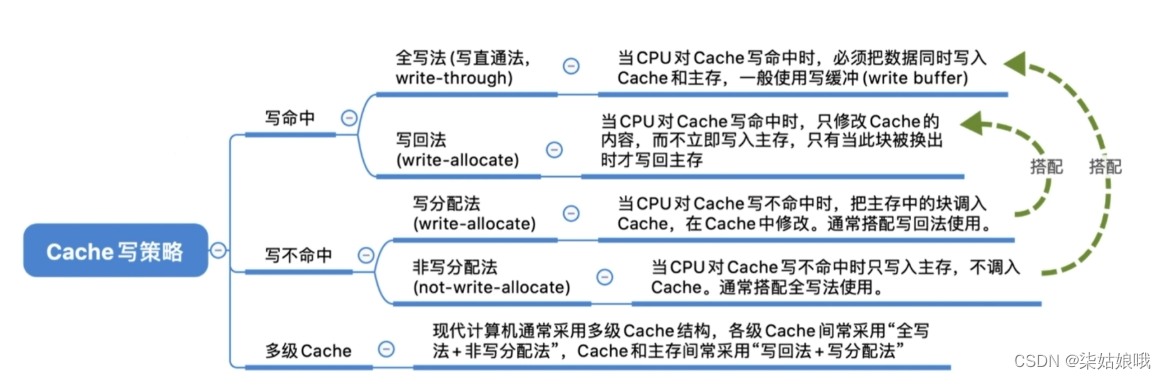
写命中
写回法
写回法(write-back)——当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存
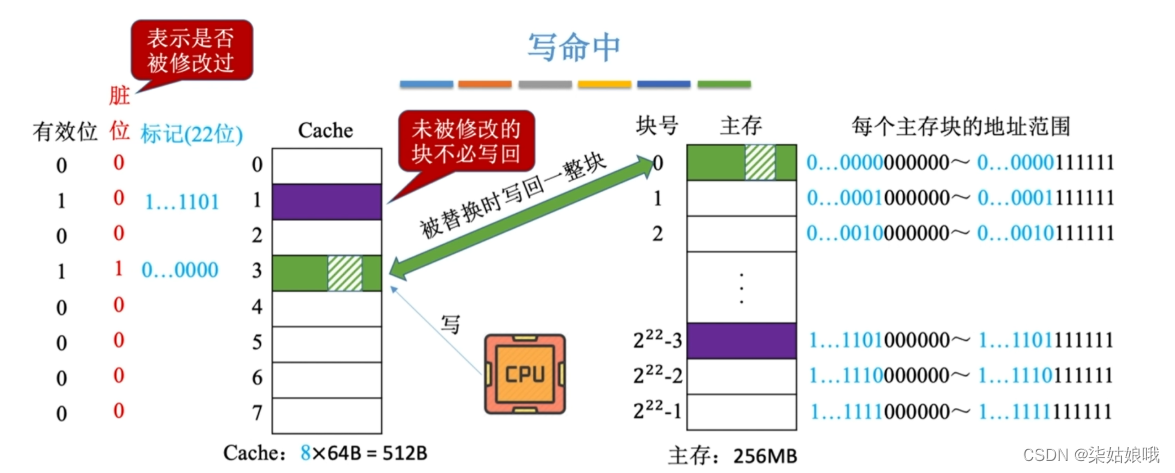
减少了访存次数,但存在数据不一致的隐患。
全写法
全写法(写直通法,write-through)——当CPU对Cache写命中时,必须把数据同时写入Cache和主存
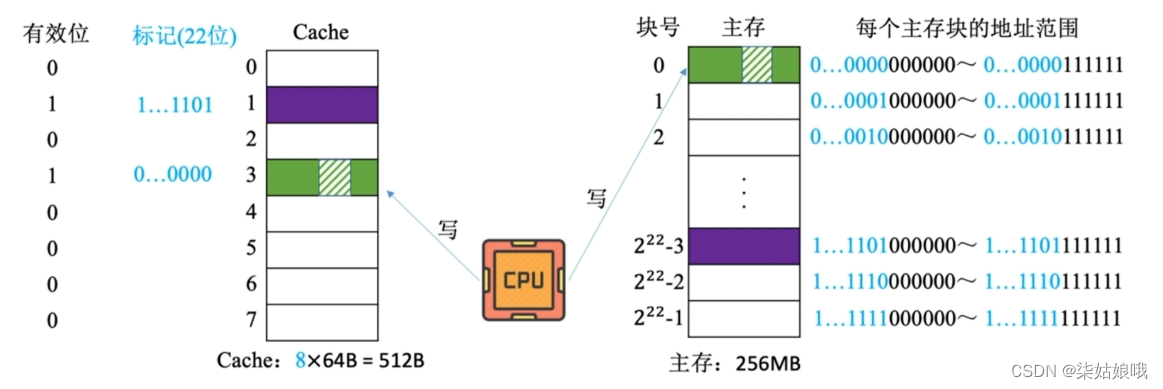
访存次数增加,速度变慢,但更能保证数据一致性
一般使用写缓冲(write buffer)
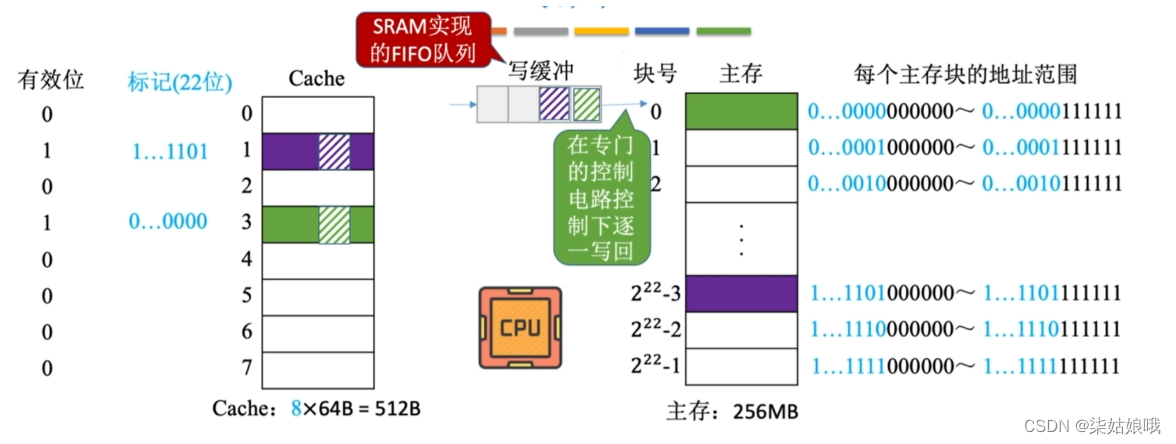
使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞。
写不命中
写分配法(write-allocate)———当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。通常搭配写回法使用。
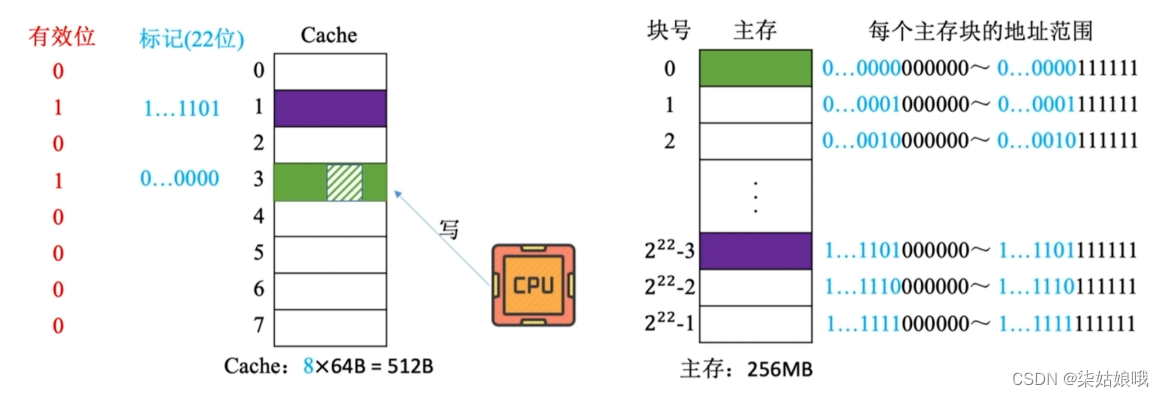
非写分配法
非写分配法(not-write-allocate)—当CPU对Cache写不命中时只写入主存,不调入Cache。搭配全写法使用。
只有“读”未命中时才调入Cache
多级Cache
现代计算机常采用多级Cache。离CPU越近的速度越快,容量越小;离CPU越远的速度越慢,容量越大
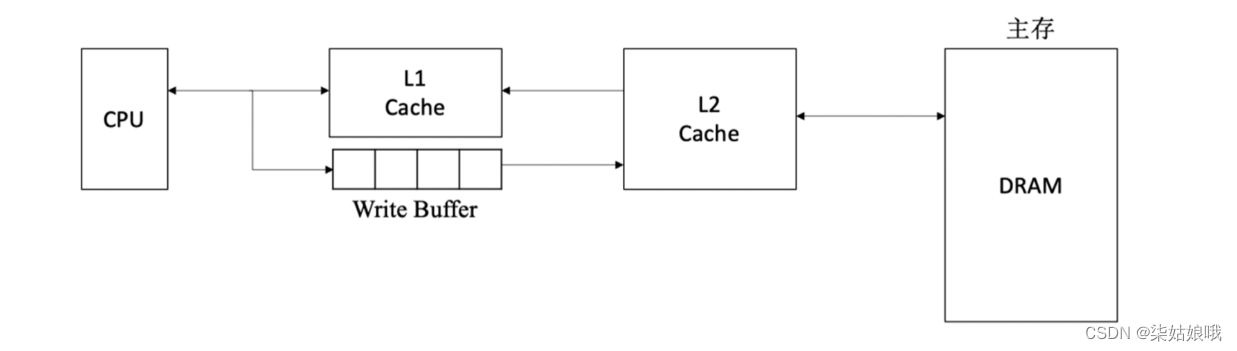
各级Cache之间常采用“全写法+非写分配法”
Cache-主存之间常采用“写回法+写分配法”
页式存储器
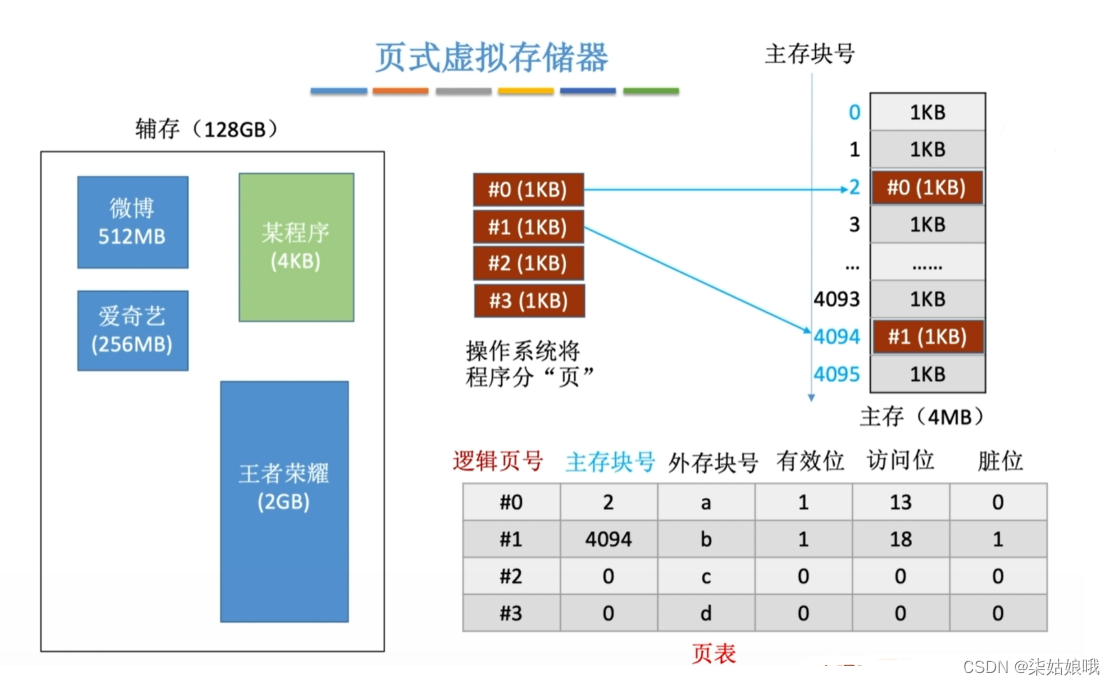
页式存储
4KB的程序被分为4个“页”,每个页面的大小和“物理块”的大小相同
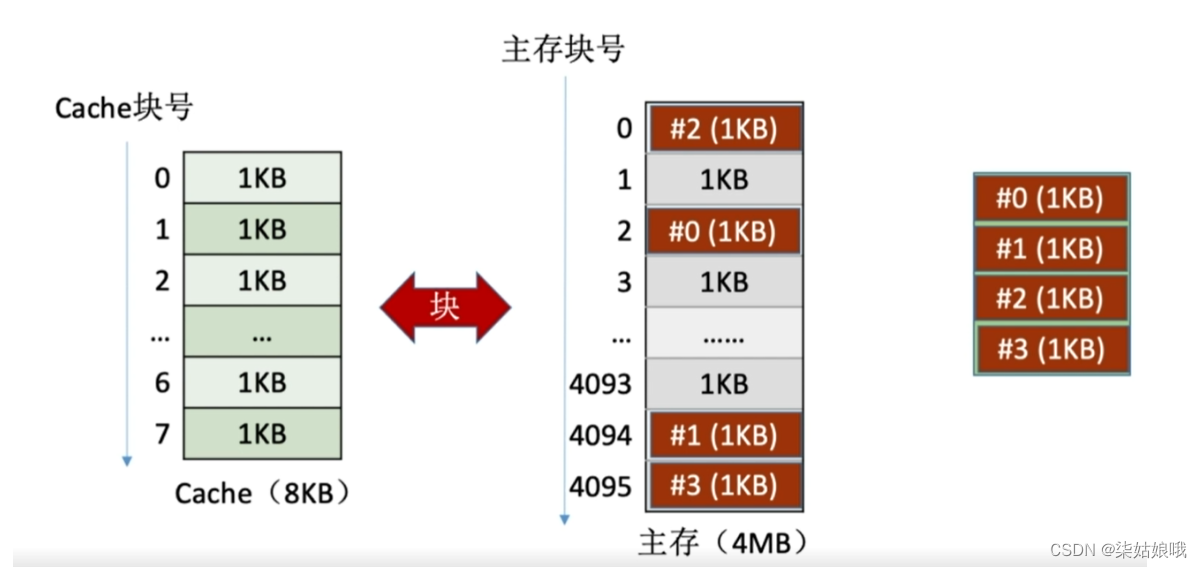
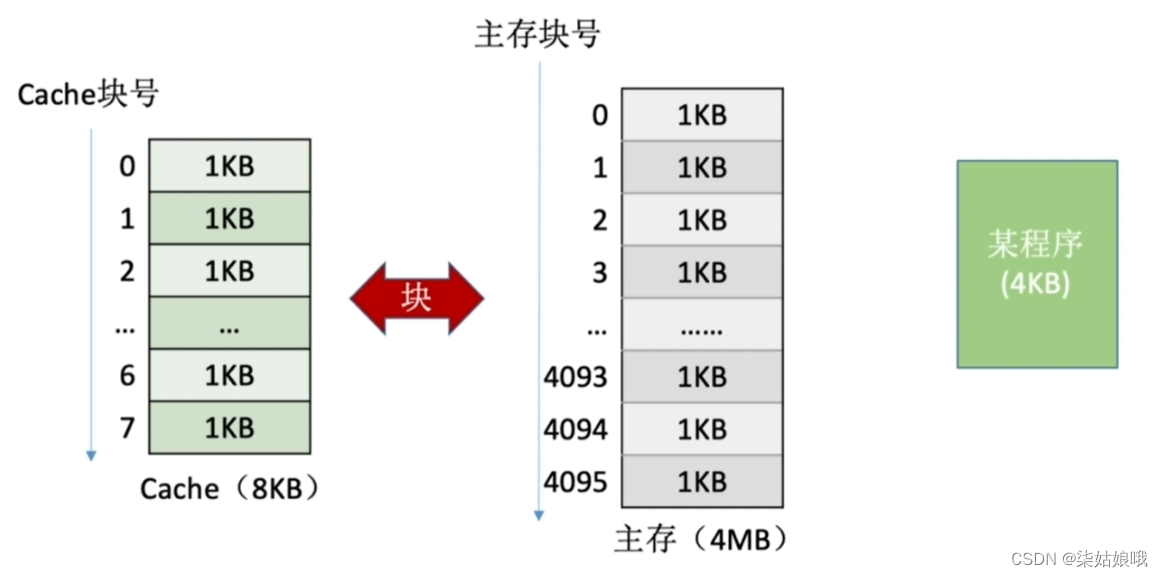
页式存储系统:一个程序(进程)在逻辑上被分为若干个大小相等的“页面”,“页面”大小与“块”的大小相同。
每个页面可以离散地放入不同的主存块中。
虚地址 vs 实地址
逻辑地址(虚地址):程序员视角看到的地址
物理地址(实地址):实际在主存中的地址
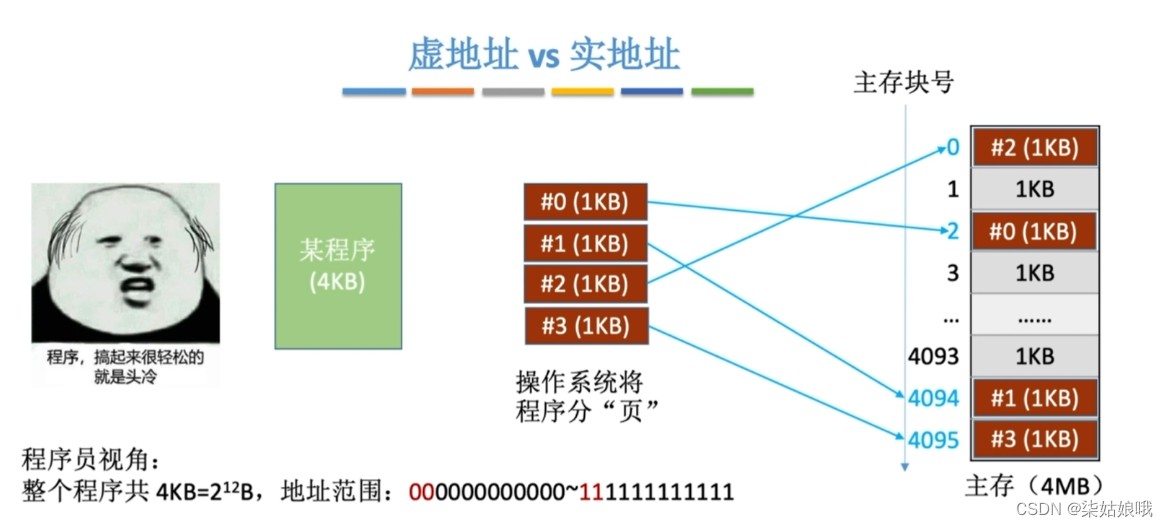
页表:逻辑页号→主存块号
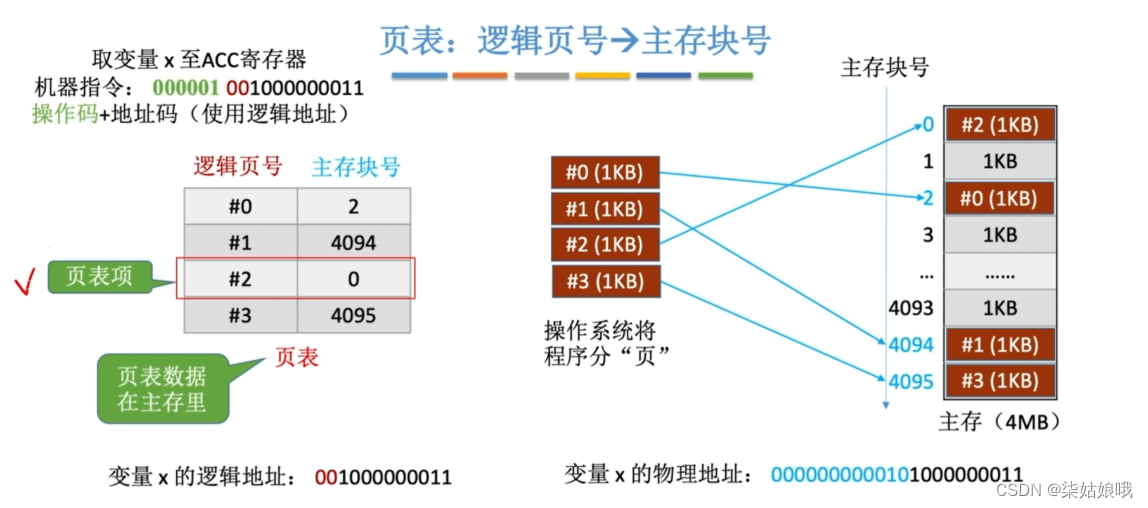
CPU执行的机器指令中,使用的是“逻辑地址”,因此需要通“页表”将逻辑地址转为物理地址。
页表的作用:记录了每个逻辑页面存放在哪个主存块中
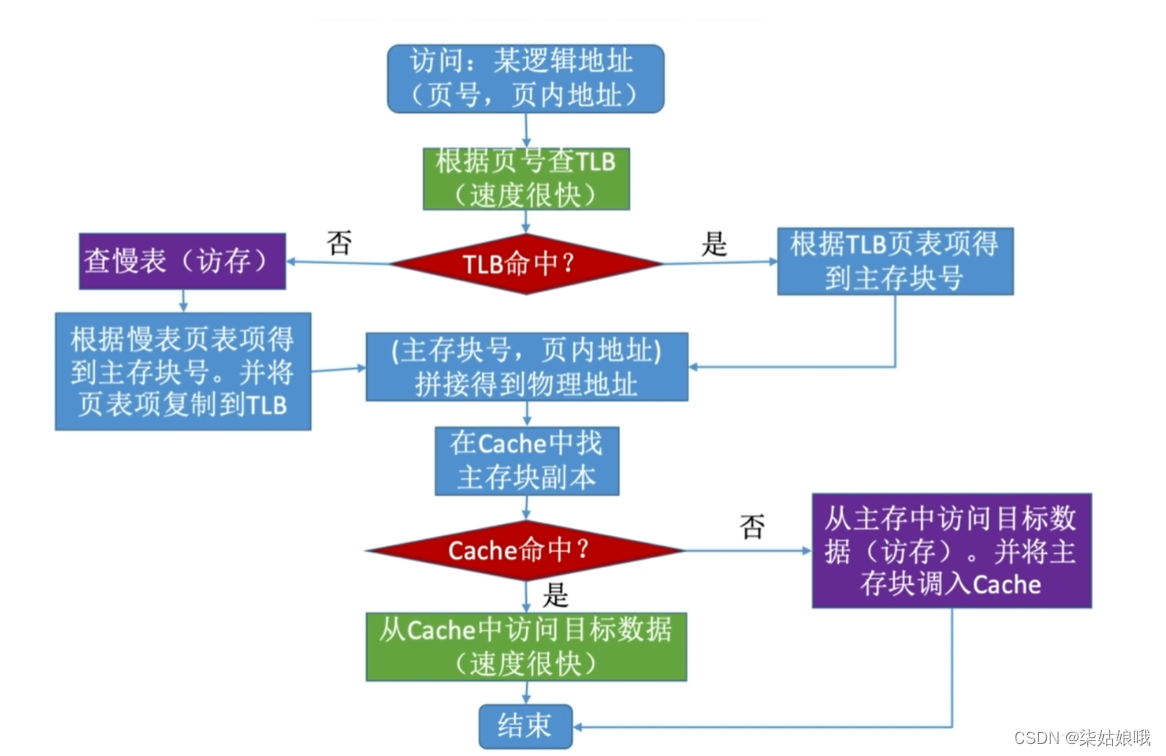
地址变换过程
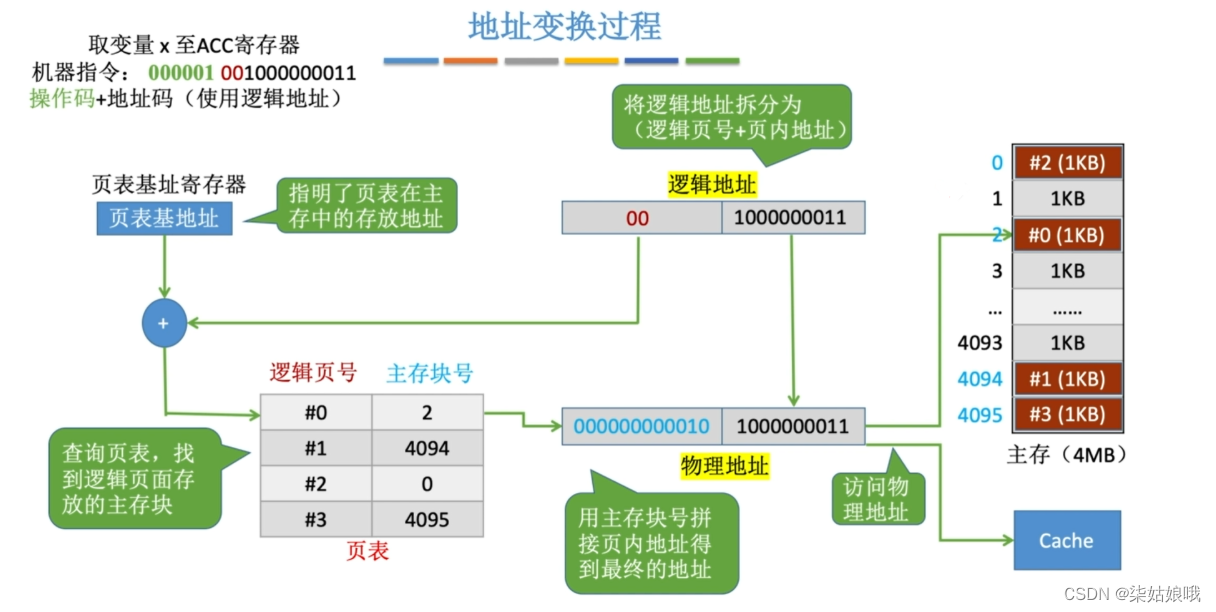
CPU访问某个主存地址:这个块的数据可能在Cache中
将近期访问的页表项放入更高速的存储器,可加快地址变换的速度
地址变换过程((增加TLB快表)
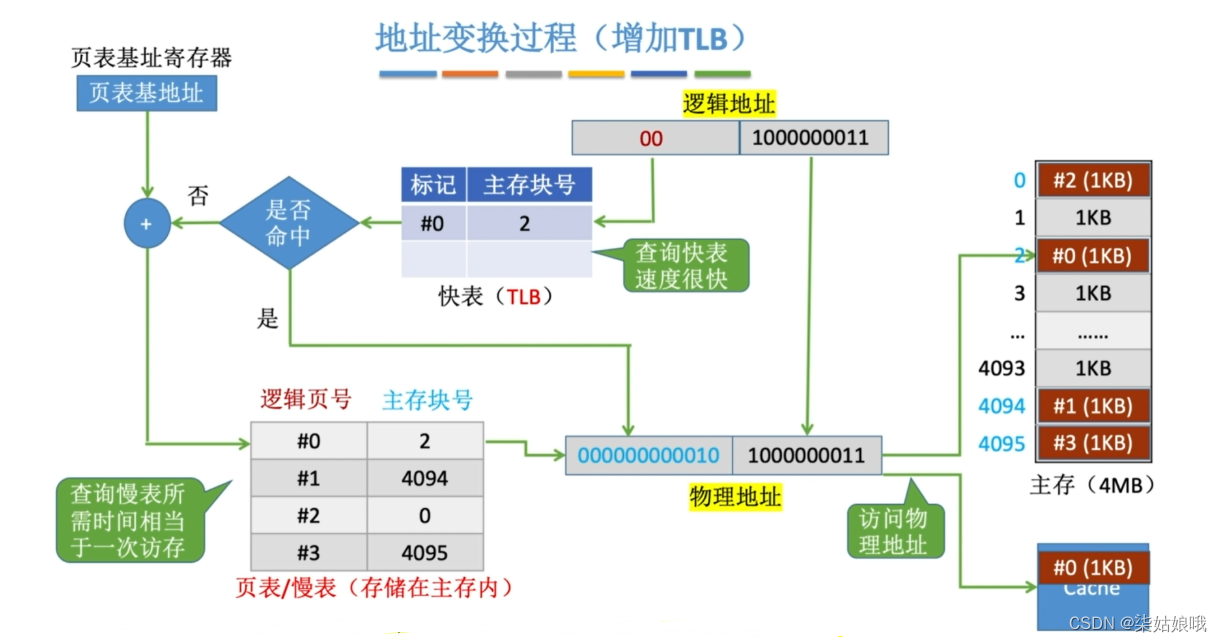
快表是一种“相联存储器”,可以按内容寻访
注意区别:快表中存储的是页表项副本;Cache中存储的是主存块的副本
快表用了SRAM芯片,但是不属于RAM呢,而是CAM啊
虚拟存储器
页式虚拟存储器
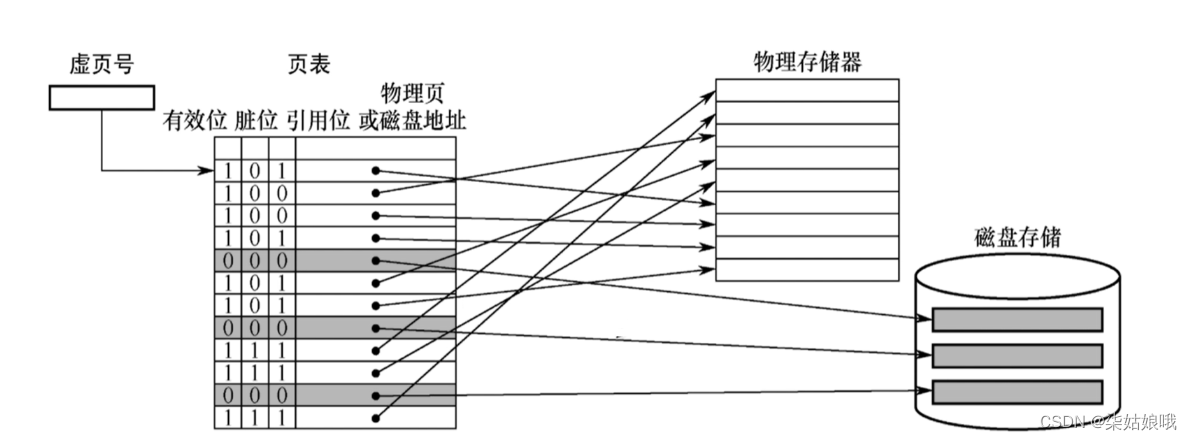
有效位:这个页面是否已调入主存
脏位:这个页面是否被修改过
引用位:用于“页面置换算法”,比如,可以用来统计这个页面被访问过多少次
物理页:即主存块号
磁盘地址:即这个页面的数据在磁盘中的存放位置
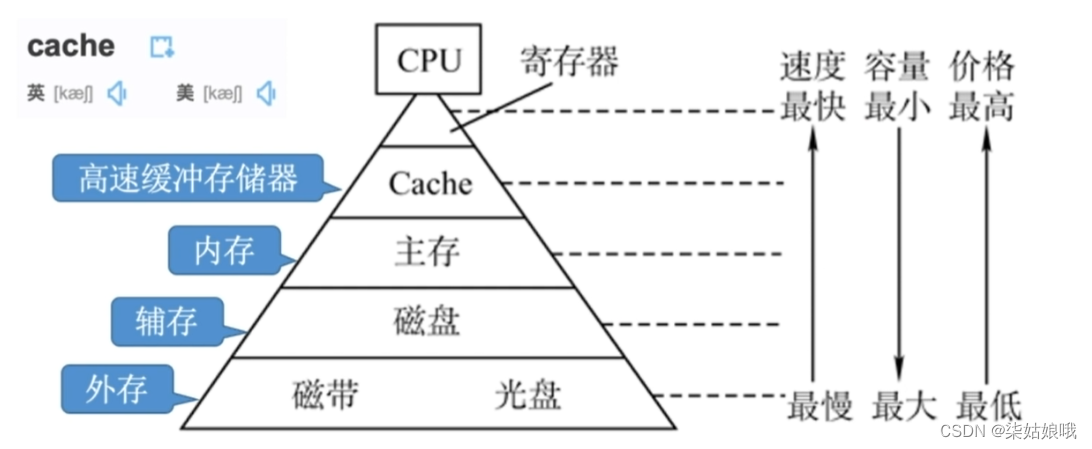
存储器的层次化结构
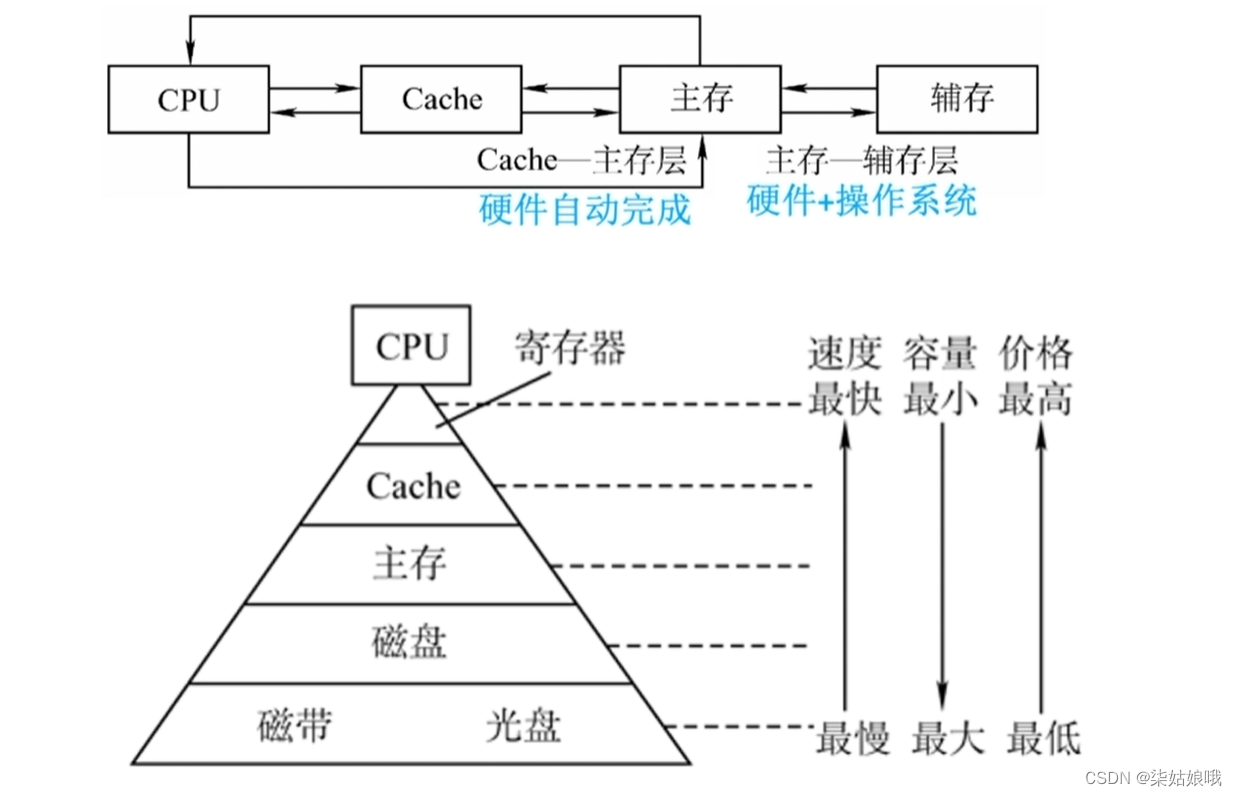
主存―辅存:实现虚拟存储系统,解决了主存容量不够的问题
Cache—主存:解决了主存与CPU速度不匹配的问题
段式虚拟存储器
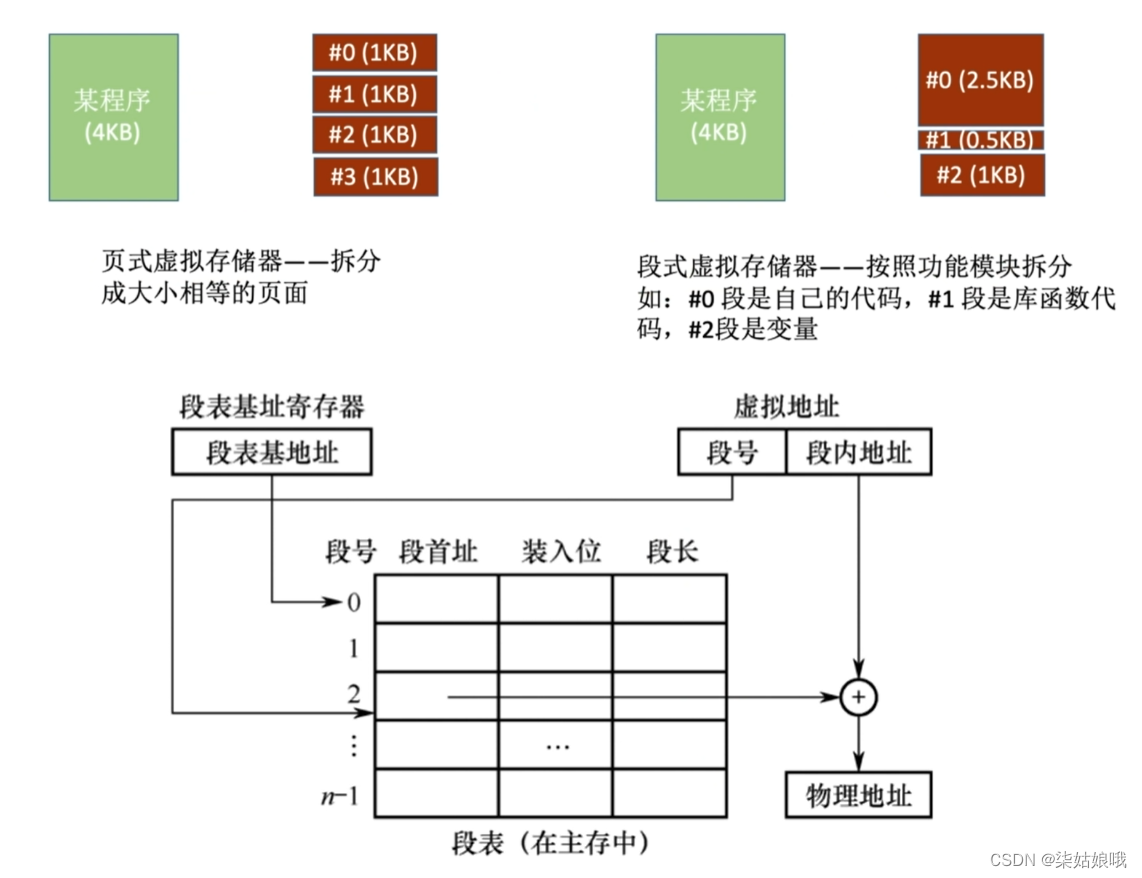
段页式虚拟存储器
把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,
程序对主存的调入、调出仍以页为基本传送单位。
每个程序对应一个段表,每段对应一个页表。
虚拟地址:段号+段内页号+页内地址
换过程
[外链图片转存中…(img-J5692y5P-1656828939646)]
CPU访问某个主存地址:这个块的数据可能在Cache中
将近期访问的页表项放入更高速的存储器,可加快地址变换的速度
地址变换过程((增加TLB快表)
[外链图片转存中…(img-Wlq763i6-1656828939646)]
快表是一种“相联存储器”,可以按内容寻访
注意区别:快表中存储的是页表项副本;Cache中存储的是主存块的副本
快表用了SRAM芯片,但是不属于RAM呢,而是CAM啊
虚拟存储器
页式虚拟存储器
[外链图片转存中…(img-2dOgpdZF-1656828939646)]
[外链图片转存中…(img-NJKNGsiA-1656828939647)]
有效位:这个页面是否已调入主存
脏位:这个页面是否被修改过
引用位:用于“页面置换算法”,比如,可以用来统计这个页面被访问过多少次
物理页:即主存块号
磁盘地址:即这个页面的数据在磁盘中的存放位置
存储器的层次化结构
[外链图片转存中…(img-unKahxcV-1656828939647)]
[外链图片转存中…(img-Vj3c0odt-1656828939650)]
主存―辅存:实现虚拟存储系统,解决了主存容量不够的问题
Cache—主存:解决了主存与CPU速度不匹配的问题
段式虚拟存储器
[外链图片转存中…(img-BrfSDX1h-1656828939652)]
[外链图片转存中…(img-G0W6o0l8-1656828939653)]
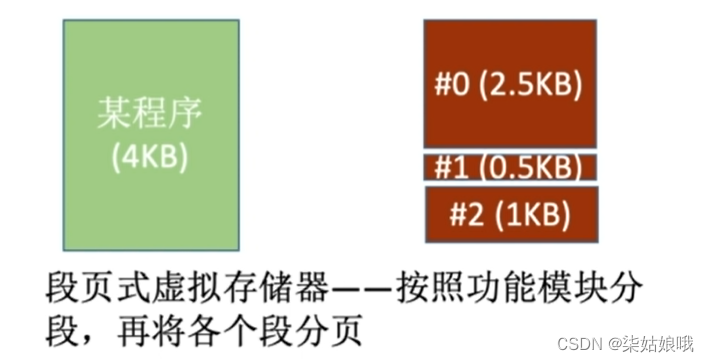
段页式虚拟存储器
把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,
程序对主存的调入、调出仍以页为基本传送单位。
每个程序对应一个段表,每段对应一个页表。
虚拟地址:段号+段内页号+页内地址
[外链图片转存中…(img-EMejIKXm-1656828939654)]
边栏推荐
- Summary of common problems in development
- 韩国AI团队抄袭震动学界!1个导师带51个学生,还是抄袭惯犯
- 5g TV cannot become a competitive advantage, and video resources become the last weapon of China's Radio and television
- 一文概览2D人体姿态估计
- [information retrieval] link analysis
- LVLG 8.2 circular scrolling animation of a label
- ML之shap:基于boston波士顿房价回归预测数据集利用shap值对XGBoost模型实现可解释性案例
- Map of mL: Based on Boston house price regression prediction data set, an interpretable case of xgboost model using map value
- LVGL 8.2 Draw label with gradient color
- Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)
猜你喜欢
Real time data warehouse
Gin integrated Alipay payment

数据湖(十三):Spark与Iceberg整合DDL操作

金额计算用 BigDecimal 就万无一失了?看看这五个坑吧~~
Detailed analysis of pytorch's automatic derivation mechanism, pytorch's core magic
Wt588f02b-8s (c006_03) single chip voice IC scheme enables smart doorbell design to reduce cost and increase efficiency
Opencv learning notes - linear filtering: box filtering, mean filtering, Gaussian filtering

Digi XBee 3 rf: 4 protocols, 3 packages, 10 major functions

How to match chords

leetcode:6110. 网格图中递增路径的数目【dfs + cache】
随机推荐
产业互联网则具备更大的发展潜能,具备更多的行业场景
Solutions to the problems of miui12.5 red rice k20pro using Au or povo2
LVGL 8.2 Line
PyTorch的自动求导机制详细解析,PyTorch的核心魔法
Free, easy-to-use, powerful lightweight note taking software evaluation: drafts, apple memo, flomo, keep, flowus, agenda, sidenote, workflow
關於miui12.5 紅米k20pro用au或者povo2出現問題的解决辦法
自动控制原理快速入门+理解
Leetcode T48: rotating images
LVGL 8.2 keyboard
Ml: introduction, principle, use method and detailed introduction of classic cases of snap value
利用Shap值进行异常值检测
实战解惑 | OpenCV中如何提取不规则ROI区域
Is it safe to open an account online for stock speculation? Will you be cheated.
leetcode:6109. 知道秘密的人数【dp的定义】
各大主流编程语言性能PK,结果出乎意料
Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)
[information retrieval] experiment of classification and clustering
一文概览2D人体姿态估计
Some problems and ideas of data embedding point
LVGL 8.2 Line wrap, recoloring and scrolling