当前位置:网站首页>Pytorch common code snippet collection
Pytorch common code snippet collection
2022-07-05 01:35:00 【Xiaobai learns vision】
This article is about PyTorch A collection of common code snippets , Cover basic configuration 、 Tensor processing 、 Model definition and operation 、 Data processing 、 Model training and testing 5 In terms of , It also gives a number of noteworthy Tips, It's very comprehensive .
PyTorch The best information is official documents . This article is about PyTorch Common code snippets , In resources [1]( Zhang Hao :PyTorch Cookbook) Some repairs have been made on the basis of , It is convenient to refer to .
1. Basic configuration
Import package and version query
import torch import torch.nn as nn import torchvision print(torch.__version__) print(torch.version.cuda) print(torch.backends.cudnn.version()) print(torch.cuda.get_device_name(0))
Reproducibility
On hardware device (CPU、GPU) Different time , Complete reproducibility is not guaranteed , Even if the random seeds are the same . however , On the same device , Reproducibility should be guaranteed . The specific way is , Fixed at the beginning of the program torch Of random seeds , At the same time numpy The random seeds of .
np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False
Video card settings
If you only need one graphics card
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')If you need to specify multiple graphics cards , such as 0,1 No. 1 video card .
import os os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
You can also set the graphics card when running code on the command line :
CUDA_VISIBLE_DEVICES=0,1 python train.py
Clear video memory
torch.cuda.empty_cache()
You can also use reset... On the command line GPU Instructions
nvidia-smi --gpu-reset -i [gpu_id]
2. tensor (Tensor) Handle
The data type of the tensor
PyTorch Yes 9 Kind of CPU Tensor types and 9 Kind of GPU Tensor type .
Tensor basic information
tensor = torch.randn(3,4,5) print(tensor.type()) # data type print(tensor.size()) # Tensor shape, Is a tuple print(tensor.dim()) # The number of dimensions
Name tensor
Tensor naming is a very useful method , This makes it easy to use the name of the dimension for indexing or other operations , Greatly improved readability 、 Ease of use , Prevent mistakes .
# stay PyTorch 1.3 Before , You need to use comments
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)
# PyTorch 1.3 after
NCHW = [‘N’, ‘C’, ‘H’, ‘W’]
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C')
images.select('C', index=0)
# It can also be set like this
tensor = torch.rand(3,4,1,2,names=('C', 'N', 'H', 'W'))
# Use align_to You can easily sort dimensions
tensor = tensor.align_to('N', 'C', 'H', 'W')Data type conversion
# Set the default type ,pytorch Medium FloatTensor Far faster than DoubleTensor torch.set_default_tensor_type(torch.FloatTensor) # Type conversion tensor = tensor.cuda() tensor = tensor.cpu() tensor = tensor.float() tensor = tensor.long()
torch.Tensor And np.ndarray transformation
except CharTensor, All of the other CPU All tensors on support the transformation to numpy Format and then convert back .
ndarray = tensor.cpu().numpy() tensor = torch.from_numpy(ndarray).float() tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride.
Torch.tensor And PIL.Image transformation
# pytorch The tensor in the defaults to [N, C, H, W] The order of , And the data range is [0,1], It needs to be transposed and normalized # torch.Tensor -> PIL.Image image = PIL.Image.fromarray(torch.clamp(tensor*255, min=0, max=255).byte().permute(1,2,0).cpu().numpy()) image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way # PIL.Image -> torch.Tensor path = r'./figure.jpg' tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))).permute(2,0,1).float() / 255 tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently way
np.ndarray And PIL.Image Transformation
image = PIL.Image.fromarray(ndarray.astype(np.uint8)) ndarray = np.asarray(PIL.Image.open(path))
Extract values from a tensor that contains only one element
value = torch.rand(1).item()
Tensor deformation
# When the convolution layer is input into the fully connected layer, the tensor usually needs to be deformed , # comparison torch.view,torch.reshape It can automatically handle the discontinuous input tensor . tensor = torch.rand(2,3,4) shape = (6, 4) tensor = torch.reshape(tensor, shape)
Out of order
tensor = tensor[torch.randperm(tensor.size(0))] # Disrupt the first dimension
Flip horizontal
# pytorch I won't support it tensor[::-1] This negative step operation , Horizontal flipping can be achieved by tensor indexing # Suppose the dimension of the tensor is [N, D, H, W]. tensor = tensor[:,:,:,torch.arange(tensor.size(3) - 1, -1, -1).long()]
Copy tensor
# Operation | New/Shared memory | Still in computation graph | tensor.clone() # | New | Yes | tensor.detach() # | Shared | No | tensor.detach.clone()() # | New | No |
Tensor splicing
''' Be careful torch.cat and torch.stack The difference is that torch.cat Stitching along a given dimension , and torch.stack One dimension will be added . For example, if the parameter is 3 individual 10x5 Tensor ,torch.cat The result is 30x5 Tensor , and torch.stack The result is 3x10x5 Tensor . ''' tensor = torch.cat(list_of_tensors, dim=0) tensor = torch.stack(list_of_tensors, dim=0)
Convert integer label to one-hot code
# pytorch The default tag is from 0 Start tensor = torch.tensor([0, 2, 1, 3]) N = tensor.size(0) num_classes = 4 one_hot = torch.zeros(N, num_classes).long() one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())
Get non-zero elements
torch.nonzero(tensor) # index of non-zero elements torch.nonzero(tensor==0) # index of zero elements torch.nonzero(tensor).size(0) # number of non-zero elements torch.nonzero(tensor == 0).size(0) # number of zero elements
Judge that two tensors are equal
torch.allclose(tensor1, tensor2) # float tensor torch.equal(tensor1, tensor2) # int tensor
Tensor expansion
# Expand tensor of shape 64*512 to shape 64*512*7*7. tensor = torch.rand(64,512) torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)
Matrix multiplication
# Matrix multiplcation: (m*n) * (n*p) * -> (m*p). result = torch.mm(tensor1, tensor2) # Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p) result = torch.bmm(tensor1, tensor2) # Element-wise multiplication. result = tensor1 * tensor2
Calculate the distance between two sets of data
utilize broadcast Mechanism
dist = torch.sqrt(torch.sum((X1[:,None,:] - X2) ** 2, dim=2))
3. Model definition and operation
An example of a simple two-layer convolution network
# convolutional neural network (2 convolutional layers)
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model = ConvNet(num_classes).to(device)The calculation and display of convolution layer can be assisted by this website .
Bilinear convergence (bilinear pooling)
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling assert X.size() == (N, D, D) X = torch.reshape(X, (N, D * D)) X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization X = torch.nn.functional.normalize(X) # L2 normalization
Multi card synchronization BN(Batch normalization)
When using torch.nn.DataParallel Run the code on multiple GPU On the card ,PyTorch Of BN Layer default operation is to calculate the mean value and standard deviation of data on each card independently , Sync BN Use all the data on the card to calculate BN The mean and standard deviation of layers , Ease when batch size (batch size) Compare the situation when the mean value and standard deviation are not estimated correctly , It is an effective skill to improve performance in the task of target detection .
sync_bn = torch.nn.SyncBatchNorm(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)All of the existing network BN Change layer to synchronization BN layer
def convertBNtoSyncBN(module, process_group=None):
'''Recursively replace all BN layers to SyncBN layer.
Args:
module[torch.nn.Module]. Network
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
sync_bn = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum,
module.affine, module.track_running_stats, process_group)
sync_bn.running_mean = module.running_mean
sync_bn.running_var = module.running_var
if module.affine:
sync_bn.weight = module.weight.clone().detach()
sync_bn.bias = module.bias.clone().detach()
return sync_bn
else:
for name, child_module in module.named_children():
setattr(module, name) = convert_syncbn_model(child_module, process_group=process_group))
return modulesimilar BN moving average
If you want to achieve something similar BN Sliding average operation , stay forward Function to use in place (inplace) The operation assigns a value to the sliding average .
class BN(torch.nn.Module)
def __init__(self):
...
self.register_buffer('running_mean', torch.zeros(num_features))
def forward(self, X):
...
self.running_mean += momentum * (current - self.running_mean)Calculate the overall parameters of the model
num_parameters = sum(torch.numel(parameter) for parameter in model.parameters())
View parameters in the network
Can pass model.state_dict() perhaps model.named_parameters() Function to see all the training parameters ( Including the parameters in the parent class obtained by inheritance )
params = list(model.named_parameters())
(name, param) = params[28]
print(name)
print(param.grad)
print('-------------------------------------------------')
(name2, param2) = params[29]
print(name2)
print(param2.grad)
print('----------------------------------------------------')
(name1, param1) = params[30]
print(name1)
print(param1.grad)Model visualization ( Use pytorchviz)
szagoruyko/pytorchvizgithub.com
similar Keras Of model.summary() Output model information , Use pytorch-summary
sksq96/pytorch-summarygithub.com
Model weight initialization
Be careful model.modules() and model.children() The difference between :model.modules() Will iterate through all the sub layers of the model , and model.children() Only one layer under the model will be traversed .
# Common practise for initialization.
for layer in model.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out',
nonlinearity='relu')
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.BatchNorm2d):
torch.nn.init.constant_(layer.weight, val=1.0)
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.Linear):
torch.nn.init.xavier_normal_(layer.weight)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
# Initialization with given tensor.
layer.weight = torch.nn.Parameter(tensor)Extract a layer in the model
modules() Iterators for all modules in the model will be returned , It can access the innermost layer , such as self.layer1.conv1 This module , Another corresponding to them is name_children() Properties and named_modules(), These two not only return the iterator of the module , It also returns the name of the network layer .
# Take the first two layers in the model
new_model = nn.Sequential(*list(model.children())[:2]
# If you want to extract all the convolution layers in the model , You can do this as follows :
for layer in model.named_modules():
if isinstance(layer[1],nn.Conv2d):
conv_model.add_module(layer[0],layer[1])Part of the layer uses the pre training model
Note that if the saved model is torch.nn.DataParallel, The current model also needs to be
model.load_state_dict(torch.load('model.pth'), strict=False)Will be in GPU The saved model is loaded into CPU
model.load_state_dict(torch.load('model.pth', map_location='cpu'))Import the same part of another model into the new model
When importing parameters from the model , If the structure of the two models is inconsistent , If you import parameters directly, an error will be reported . You can import the same part of another model into the new model by using the following method .
# model_new Represents a new model
# model_saved Represent other models , For example, use torch.load Imported saved model
model_new_dict = model_new.state_dict()
model_common_dict = {k:v for k, v in model_saved.items() if k in model_new_dict.keys()}
model_new_dict.update(model_common_dict)
model_new.load_state_dict(model_new_dict)4. Data processing
Calculate the mean and standard deviation of the dataset
import os
import cv2
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
def compute_mean_and_std(dataset):
# Input PyTorch Of dataset, Output mean and standard deviation
mean_r = 0
mean_g = 0
mean_b = 0
for img, _ in dataset:
img = np.asarray(img) # change PIL Image to numpy array
mean_b += np.mean(img[:, :, 0])
mean_g += np.mean(img[:, :, 1])
mean_r += np.mean(img[:, :, 2])
mean_b /= len(dataset)
mean_g /= len(dataset)
mean_r /= len(dataset)
diff_r = 0
diff_g = 0
diff_b = 0
N = 0
for img, _ in dataset:
img = np.asarray(img)
diff_b += np.sum(np.power(img[:, :, 0] - mean_b, 2))
diff_g += np.sum(np.power(img[:, :, 1] - mean_g, 2))
diff_r += np.sum(np.power(img[:, :, 2] - mean_r, 2))
N += np.prod(img[:, :, 0].shape)
std_b = np.sqrt(diff_b / N)
std_g = np.sqrt(diff_g / N)
std_r = np.sqrt(diff_r / N)
mean = (mean_b.item() / 255.0, mean_g.item() / 255.0, mean_r.item() / 255.0)
std = (std_b.item() / 255.0, std_g.item() / 255.0, std_r.item() / 255.0)
return mean, stdGet the basic information of video data
import cv2 video = cv2.VideoCapture(mp4_path) height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)) width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH)) num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT)) fps = int(video.get(cv2.CAP_PROP_FPS)) video.release()
TSN Each paragraph (segment) Sample a video
K = self._num_segments
if is_train:
if num_frames > K:
# Random index for each segment.
frame_indices = torch.randint(
high=num_frames // K, size=(K,), dtype=torch.long)
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.randint(
high=num_frames, size=(K - num_frames,), dtype=torch.long)
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), frame_indices)))[0]
else:
if num_frames > K:
# Middle index for each segment.
frame_indices = num_frames / K // 2
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), torch.arange(K - num_frames))))[0]
assert frame_indices.size() == (K,)
return [frame_indices[i] for i in range(K)]Common training and validation data preprocessing
among ToTensor The operation will PIL.Image Or in the shape of H×W×D, The range of values is [0, 255] Of np.ndarray Convert to shape D×H×W, The range of values is [0.0, 1.0] Of torch.Tensor.
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])5. Model training and testing
Classification model training code
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i ,(images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch: [{}/{}], Step: [{}/{}], Loss: {}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))Classification model test code
# Test the model
model.eval() # eval mode(batch norm uses moving mean/variance
#instead of mini-batch mean/variance)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test accuracy of the model on the 10000 test images: {} %'
.format(100 * correct / total))Customize loss
Inherit torch.nn.Module Class writes its own loss.
class MyLoss(torch.nn.Moudle):
def __init__(self):
super(MyLoss, self).__init__()
def forward(self, x, y):
loss = torch.mean((x - y) ** 2)
return lossLabel smoothing (label smoothing)
Write a label_smoothing.py The file of , Then reference... In the training code , use LSR Instead of cross entropy loss .label_smoothing.py The contents are as follows :
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
"""
Convert labels to one hot vectors
Args:
labels: torch tensor in format [label1, label2, label3, ...]
classes: int, number of classes
value: label value in one hot vector, default to 1
Returns:
return one hot format labels in shape [batchsize, classes]
"""
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth
them.
Args:
target: target in form with [label1, label2, label_batchsize]
length: length of one-hot format(number of classes)
smooth_factor: smooth factor for label smooth
Returns:
smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1 - smooth_factor)
one_hot += smooth_factor / (length - 1)
return one_hot.to(target.device)
def forward(self, x, target):
if x.size(0) != target.size(0):
raise ValueError('Expected input batchsize ({}) to match target batch_size({})'
.format(x.size(0), target.size(0)))
if x.dim() < 2:
raise ValueError('Expected input tensor to have least 2 dimensions(got {})'
.format(x.size(0)))
if x.dim() != 2:
raise ValueError('Only 2 dimension tensor are implemented, (got {})'
.format(x.size()))
smoothed_target = self._smooth_label(target, x.size(1), self.e)
x = self.log_softmax(x)
loss = torch.sum(- x * smoothed_target, dim=1)
if self.reduction == 'none':
return loss
elif self.reduction == 'sum':
return torch.sum(loss)
elif self.reduction == 'mean':
return torch.mean(loss)
else:
raise ValueError('unrecognized option, expect reduction to be one of none, mean, sum')Or do it directly in the training file label smoothing
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
score = model(images)
log_prob = torch.nn.functional.log_softmax(score, dim=1)
loss = -torch.sum(log_prob * smoothed_labels) / N
optimizer.zero_grad()
loss.backward()
optimizer.step()Mixup Training
beta_distribution = torch.distributions.beta.Beta(alpha, alpha)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
# Mixup images and labels.
lambda_ = beta_distribution.sample([]).item()
index = torch.randperm(images.size(0)).cuda()
mixed_images = lambda_ * images + (1 - lambda_) * images[index, :]
label_a, label_b = labels, labels[index]
# Mixup loss.
scores = model(mixed_images)
loss = (lambda_ * loss_function(scores, label_a)
+ (1 - lambda_) * loss_function(scores, label_b))
optimizer.zero_grad()
loss.backward()
optimizer.step()L1 Regularization
l1_regularization = torch.nn.L1Loss(reduction='sum')
loss = ... # Standard cross-entropy loss
for param in model.parameters():
loss += torch.sum(torch.abs(param))
loss.backward()Do not weight the offset term (weight decay)
pytorch Inside weight decay amount to l2 Regular
bias_list = (param for name, param in model.named_parameters() if name[-4:] == 'bias')
others_list = (param for name, param in model.named_parameters() if name[-4:] != 'bias')
parameters = [{'parameters': bias_list, 'weight_decay': 0},
{'parameters': others_list}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)Gradient cut (gradient clipping)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=20)
Get the current learning rate
# If there is one global learning rate (which is the common case).
lr = next(iter(optimizer.param_groups))['lr']
# If there are multiple learning rates for different layers.
all_lr = []
for param_group in optimizer.param_groups:
all_lr.append(param_group['lr'])Another way , In a batch In the training code , Current lr yes optimizer.param_groups[0]['lr']
Learning rate decline
# Reduce learning rate when validation accuarcy plateau.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)
for t in range(0, 80):
train(...)
val(...)
scheduler.step(val_acc)
# Cosine annealing learning rate.
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)
# Reduce learning rate by 10 at given epochs.
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)
for t in range(0, 80):
scheduler.step()
train(...)
val(...)
# Learning rate warmup by 10 epochs.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)
for t in range(0, 10):
scheduler.step()
train(...)
val(...)Optimizer chain update
from 1.4 Version start ,torch.optim.lr_scheduler Support chain update (chaining), That is, the user can define two schedulers, And use it alternately in training .
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR, StepLR
model = [torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = StepLR(optimizer, step_size=3, gamma=0.1)
for epoch in range(4):
print(epoch, scheduler2.get_last_lr()[0])
optimizer.step()
scheduler1.step()
scheduler2.step()Model training Visualization
PyTorch have access to tensorboard To visualize the training process .
Installation and operation TensorBoard.
pip install tensorboard tensorboard --logdir=runs
Use SummaryWriter Class to collect and visualize the corresponding data , Put it for easy viewing , You can use different folders , such as 'Loss/train' and 'Loss/test'.
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)Save and load breakpoints
Note that in order to be able to resume training , We need to keep the state of both the model and optimizer , And the current number of training rounds .
start_epoch = 0
# Load checkpoint.
if resume: # resume Is the parameter , Set to... During the first training 0, Set to... When retraining is interrupted 1
model_path = os.path.join('model', 'best_checkpoint.pth.tar')
assert os.path.isfile(model_path)
checkpoint = torch.load(model_path)
best_acc = checkpoint['best_acc']
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('Load checkpoint at epoch {}.'.format(start_epoch))
print('Best accuracy so far {}.'.format(best_acc))
# Train the model
for epoch in range(start_epoch, num_epochs):
...
# Test the model
...
# save checkpoint
is_best = current_acc > best_acc
best_acc = max(current_acc, best_acc)
checkpoint = {
'best_acc': best_acc,
'epoch': epoch + 1,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
model_path = os.path.join('model', 'checkpoint.pth.tar')
best_model_path = os.path.join('model', 'best_checkpoint.pth.tar')
torch.save(checkpoint, model_path)
if is_best:
shutil.copy(model_path, best_model_path)extract ImageNet The convolution characteristics of a certain layer in the pre training model
# VGG-16 relu5-3 feature.
model = torchvision.models.vgg16(pretrained=True).features[:-1]
# VGG-16 pool5 feature.
model = torchvision.models.vgg16(pretrained=True).features
# VGG-16 fc7 feature.
model = torchvision.models.vgg16(pretrained=True)
model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])
# ResNet GAP feature.
model = torchvision.models.resnet18(pretrained=True)
model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
with torch.no_grad():
model.eval()
conv_representation = model(image)extract ImageNet The convolution characteristics of the pre training model
class FeatureExtractor(torch.nn.Module):
"""Helper class to extract several convolution features from the given
pre-trained model.
Attributes:
_model, torch.nn.Module.
_layers_to_extract, list<str> or set<str>
Example:
>>> model = torchvision.models.resnet152(pretrained=True)
>>> model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
>>> conv_representation = FeatureExtractor(
pretrained_model=model,
layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image)
"""
def __init__(self, pretrained_model, layers_to_extract):
torch.nn.Module.__init__(self)
self._model = pretrained_model
self._model.eval()
self._layers_to_extract = set(layers_to_extract)
def forward(self, x):
with torch.no_grad():
conv_representation = []
for name, layer in self._model.named_children():
x = layer(x)
if name in self._layers_to_extract:
conv_representation.append(x)
return conv_representationFine tune the full connection layer
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, 100) # Replace the last fc layer
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)Fine tune the full connection layer with a large learning rate , Small learning rate, fine-tuning volume layer
model = torchvision.models.resnet18(pretrained=True)
finetuned_parameters = list(map(id, model.fc.parameters()))
conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)
parameters = [{'params': conv_parameters, 'lr': 1e-3},
{'params': model.fc.parameters()}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)6. Other matters needing attention
Don't use too large linear layers . because nn.Linear(m,n) Using memory , If the linear layer is too large, it is easy to have video memory .
Don't use... On too long sequences RNN. because RNN Back propagation uses BPTT Algorithm , The memory required is linear with the length of the input sequence .
model(x) Pre use model.train() and model.eval() Switch network status .
Do not need to calculate the gradient of the code block with torch.no_grad() Include .
model.eval() and torch.no_grad() The difference is that ,model.eval() It is to switch the network to the test state , for example BN and dropout Use different calculation methods during training and testing .torch.no_grad() It's closing PyTorch The automatic derivation mechanism of tensor , To reduce storage usage and accelerate Computing , The result obtained cannot be carried out loss.backward().
model.zero_grad() Will return the gradient of the parameters of the whole model to zero , and optimizer.zero_grad() Only the gradient of the parameters passed in will be reset to zero .torch.nn.CrossEntropyLoss The input of does not need to go through Softmax.torch.nn.CrossEntropyLoss Equivalent to torch.nn.functional.log_softmax + torch.nn.NLLLoss.loss.backward() Pre use optimizer.zero_grad() Clear the cumulative gradient .
torch.utils.data.DataLoader Try to set pin_memory=True, For very small data sets such as MNIST Set up pin_memory=False It's faster .num_workers We need to find the fastest value in the experiment . use del Delete unused intermediate variables in time , save GPU Storage .
Use inplace Operation can save GPU Storage , Such as
x = torch.nn.functional.relu(x, inplace=True)
Reduce CPU and GPU Data transfer between . For example, if you want to know a epoch Each of them mini-batch Of loss And accuracy , First, accumulate them in GPU Medium one epoch After the end of the transmission back together CPU It's better than every one mini-batch All once GPU To CPU The transmission is faster .
Use semi precision floating point numbers half() There will be a certain speed increase , Specific efficiency depends on GPU model . It is necessary to be careful of the stability problems caused by low numerical accuracy . Use... Often assert tensor.size() == (N, D, H, W) As a means of debugging , Make sure that the tensor dimension is consistent with what you envision . Except for tags y Outside , Try to use less one-dimensional tensor , Use n*1 Instead of , It can avoid some unexpected calculation results of one-dimensional tensor .
It takes time to count all parts of the code
with torch.autograd.profiler.profile(enabled=True, use_cuda=False) as profile: ...print(profile)# Or run... On the command line python -m torch.utils.bottleneck main.py
Use TorchSnooper To debug PyTorch Code , When the program is executed , It will automatically print Show the execution result of each line tensor The shape of the 、 data type 、 equipment 、 Whether gradient information is needed .
# pip install torchsnooperimport torchsnooper# For the function , Use decorators @torchsnooper.snoop()# If it's not a function , Use with Statement to activate TorchSnooper, Put the training cycle into with Go in the statement .with torchsnooper.snoop(): The original code
Reference material
- Zhang Hao :PyTorch Cookbook( A collection of common code snippets ),https://zhuanlan.zhihu.com/p/59205847?
- PyTorch Official documents and examples
- https://pytorch.org/docs/stable/notes/faq.html
- https://github.com/szagoruyko/pytorchviz
- https://github.com/sksq96/pytorch-summary
- other
end
边栏推荐
- How to safely eat apples on the edge of a cliff? Deepmind & openai gives the answer of 3D security reinforcement learning
- Basic operations of database and table ----- create index
- 【纯音听力测试】基于MATLAB的纯音听力测试系统
- Lsblk command - check the disk of the system. I don't often use this command, but it's still very easy to use. Onion duck, like, collect, pay attention, wait for your arrival!
- node工程中package.json文件作用是什么?里面的^尖括号和~波浪号是什么意思?
- Common bit operation skills of C speech
- Huawei machine test question: longest continuous subsequence
- Expansion operator: the family is so separated
- MySQL REGEXP:正则表达式查询
- Great God developed the new H5 version of arXiv, saying goodbye to formula typography errors in one step, and mobile phones can also easily read literature
猜你喜欢
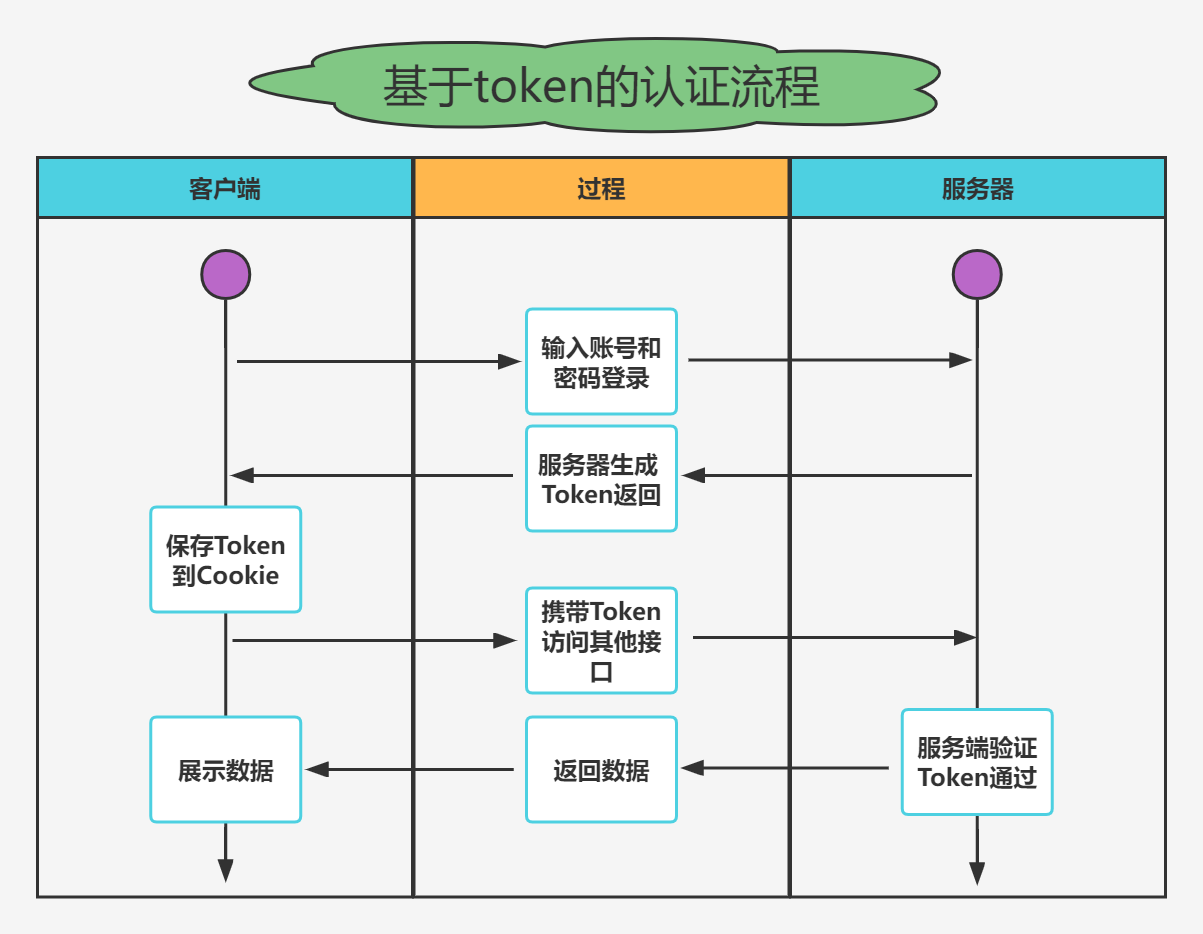
Actual combat simulation │ JWT login authentication
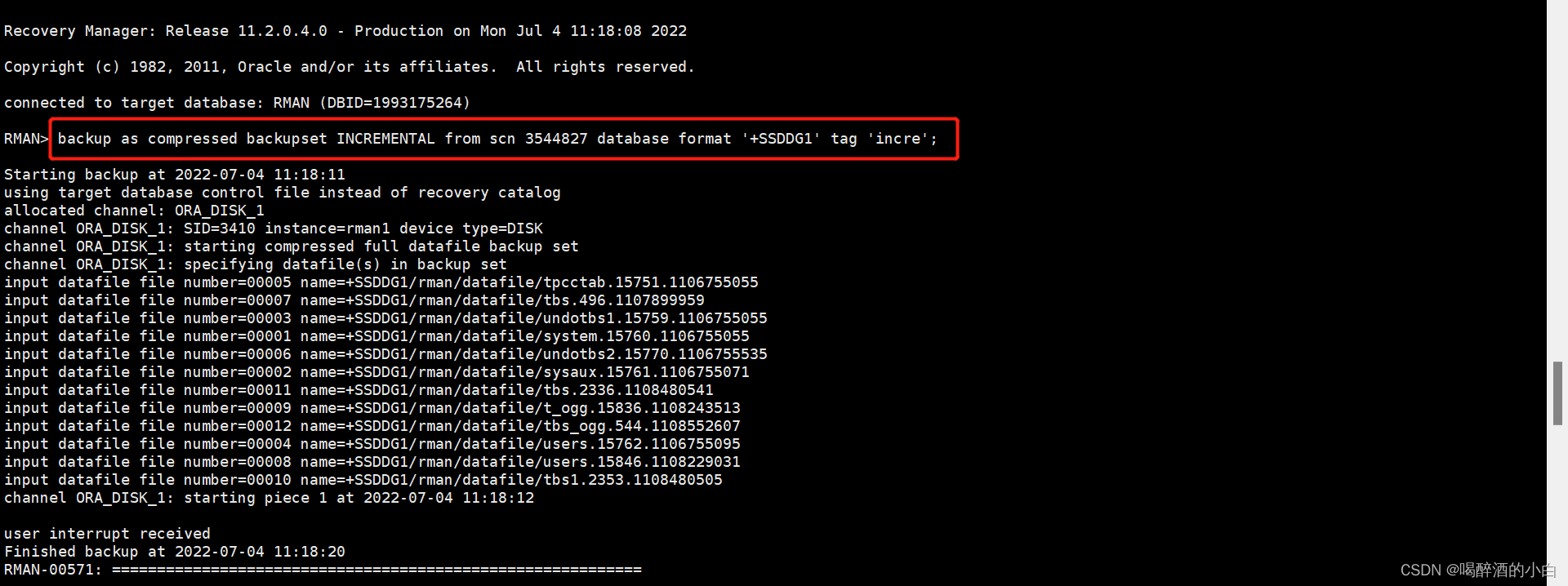
Incremental backup? db full
How to use words to describe breaking change in Spartacus UI of SAP e-commerce cloud
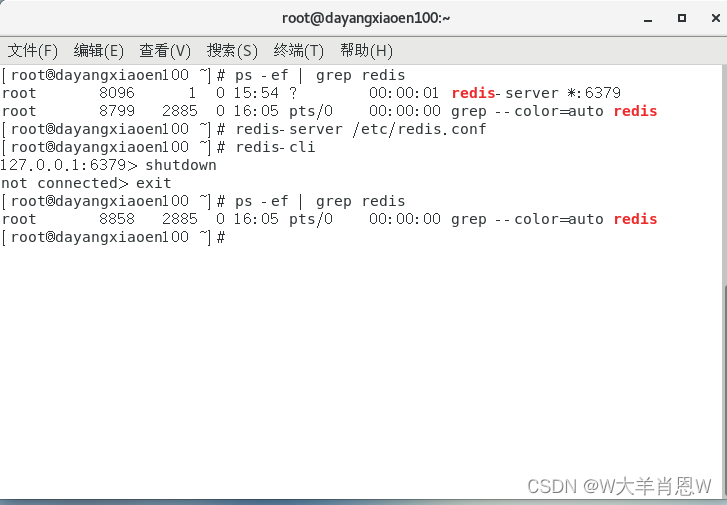
Introduction to redis (1)

Yyds dry goods inventory kubernetes management business configuration methods? (08)
![[CTF] AWDP summary (WEB)](/img/4c/574742666bd8461c6f9263fd6c5dbb.png)
[CTF] AWDP summary (WEB)
One plus six brushes into Kali nethunter

Basic operations of database and table ----- create index

The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
Lsblk command - check the disk of the system. I don't often use this command, but it's still very easy to use. Onion duck, like, collect, pay attention, wait for your arrival!
随机推荐
Global and Chinese market of optical densitometers 2022-2028: Research Report on technology, participants, trends, market size and share
Nebula importer data import practice
Research Report on the overall scale, major producers, major regions, products and application segmentation of agricultural automatic steering system in the global market in 2022
Jcenter () cannot find Alibaba cloud proxy address
I was beaten by the interviewer because I didn't understand the sorting
Database postragesq PAM authentication
One plus six brushes into Kali nethunter
[CTF] AWDP summary (WEB)
[wave modeling 2] three dimensional wave modeling and wave generator modeling matlab simulation
Great God developed the new H5 version of arXiv, saying goodbye to formula typography errors in one step, and mobile phones can also easily read literature
增量备份 ?db full
Huawei machine test question: longest continuous subsequence
Kibana installation and configuration
【LeetCode】88. Merge two ordered arrays
Database postragesql lock management
PHP 约瑟夫环问题
Win:使用 PowerShell 检查无线信号的强弱
Database postragesq peer authentication
微信小程序:全新独立后台月老办事处一元交友盲盒
微信小程序:全网独家小程序版本独立微信社群人脉