当前位置:网站首页>Conversion of yolov5 XML dataset to VOC dataset
Conversion of yolov5 XML dataset to VOC dataset
2022-07-04 07:59:00 【Rain shallow listen to the wind sing】
List of articles
1XML transformation txt
stay xml Data set , These two files are available after decompression 
annotation in xml data format
annotation>
<folder>images</folder>
<filename>hard_hat_workers0.png</filename>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>357</xmin>
<ymin>116</ymin>
<xmax>404</xmax>
<ymax>175</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>4</xmin>
<ymin>146</ymin>
<xmax>39</xmax>
<ymax>184</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>253</xmin>
<ymin>139</ymin>
<xmax>275</xmax>
<ymax>177</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>300</xmin>
<ymin>145</ymin>
<xmax>323</xmax>
<ymax>181</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>116</xmin>
<ymin>151</ymin>
<xmax>138</xmax>
<ymax>180</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>80</xmin>
<ymin>151</ymin>
<xmax>100</xmax>
<ymax>180</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>62</xmin>
<ymin>144</ymin>
<xmax>83</xmax>
<ymax>172</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>322</xmin>
<ymin>141</ymin>
<xmax>345</xmax>
<ymax>178</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>175</xmin>
<ymin>156</ymin>
<xmax>194</xmax>
<ymax>186</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>222</xmin>
<ymin>151</ymin>
<xmax>240</xmax>
<ymax>182</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>200</xmin>
<ymin>146</ymin>
<xmax>216</xmax>
<ymax>173</ymax>
</bndbox>
</object>
<object>
<name>helmet</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>98</xmin>
<ymin>140</ymin>
<xmax>112</xmax>
<ymax>160</ymax>
</bndbox>
</object>
<object>
<name>head</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>157</xmin>
<ymin>150</ymin>
<xmax>175</xmax>
<ymax>177</ymax>
</bndbox>
</object>
</annotation>
After processing
xmlToVOC.py
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
from pathlib import Path
from xml.dom.minidom import parse
from shutil import copyfile
import os
classes = ['helmet','head','person']
def convert_annot(size , box):
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
dw = np.float32(1. / int(size[0]))
dh = np.float32(1. / int(size[1]))
w = x2 - x1
h = y2 - y1
x = x1 + (w / 2)
y = y1 + (h / 2)
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return [x, y, w, h]
def save_txt_file(img_jpg_file_name, size, img_box):
save_file_name = "./Safety_Helmet_Detection_datasets_xml/labels/" + img_jpg_file_name + ".txt"
print(save_file_name)
#file_path = open(save_file_name, "a+")
with open(save_file_name,"a+") as file_path:
for box in img_box:
cls_num = classes.index(box[0])
new_box = convert_annot(size, box[1:])
file_path.write(f"{
cls_num} {
new_box[0]} {
new_box[1]} {
new_box[2]} {
new_box[3]}\n")
file_path.flush()
file_path.close()
def get_xml_data(file_path, img_xml_file):
img_path = file_path + '/' + img_xml_file + '.xml'
#print(img_path)
dom = parse(img_path)
root = dom.documentElement
img_name = root.getElementsByTagName("filename")[0].childNodes[0].data
img_size = root.getElementsByTagName("size")[0]
objects = root.getElementsByTagName("object")
img_w = img_size.getElementsByTagName("width")[0].childNodes[0].data
img_h = img_size.getElementsByTagName("height")[0].childNodes[0].data
img_c = img_size.getElementsByTagName("depth")[0].childNodes[0].data
img_box = []
for box in objects:
cls_name = box.getElementsByTagName("name")[0].childNodes[0].data
x1 = int(box.getElementsByTagName("xmin")[0].childNodes[0].data)
y1 = int(box.getElementsByTagName("ymin")[0].childNodes[0].data)
x2 = int(box.getElementsByTagName("xmax")[0].childNodes[0].data)
y2 = int(box.getElementsByTagName("ymax")[0].childNodes[0].data)
img_jpg_file_name = img_xml_file + '.jpg'
img_box.append([cls_name, x1, y1, x2, y2])
# test_dataset_box_feature(img_jpg_file_name, img_box)
save_txt_file(img_xml_file, [img_w, img_h], img_box)
files = os.listdir('./Safety_Helmet_Detection_datasets_xml/annotations')
for file in files:
print("file name: ", file)
file_xml = file.split(".")
print(file_xml[0])
get_xml_data('./Safety_Helmet_Detection_datasets_xml/annotations', file_xml[0])

txt data format
0 0.9146634956123307 0.3497596284141764 0.11298077343963087 0.14182692836038768
0 0.05168269423302263 0.39663463016040623 0.08413461851887405 0.09134615724906325
0 0.63461540825665 0.3798077064566314 0.05288461735472083 0.09134615724906325
0 0.748798104817979 0.39182693767361343 0.05528846359811723 0.08653846476227045
0 0.305288472911343 0.39783655328210443 0.05288461735472083 0.06971154105849564
0 0.21634616190567613 0.39783655328210443 0.04807692486792803 0.06971154105849564
1 0.1742788526462391 0.3798077064566314 0.05048077111132443 0.06730769481509924
1 0.8016827221726999 0.383413475821726 0.05528846359811723 0.08894231100566685
1 0.44350963190663606 0.41105770762078464 0.04567307862453163 0.07211538730189204
1 0.5552884822245687 0.40024039952550083 0.043269232381135225 0.07451923354528844
1 0.5000000186264515 0.383413475821726 0.03846153989434242 0.06490384857170284
0 0.25240385555662215 0.3605769365094602 0.03365384740754962 0.04807692486792803
1 0.39903847640380263 0.39302886079531163 0.043269232381135225 0.06490384857170284
2 split train val( test)
split_train_val.py Split and save
from sklearn.model_selection import train_test_split
import os
image_list = os.listdir('./Safety_Helmet_Detection_datasets_xml/images/')
''' Division train test val '''
#train_list, test_list = train_test_split(image_list, test_size=0.2, random_state=42)
#val_list, test_list = train_test_split(test_list, test_size=0.5, random_state=42)
# print('total =',len(image_list))
# print('train :',len(train_list))
# print('val :',len(val_list))
# print('test :',len(test_list))
''' Division train val '''
train_list, val_list = train_test_split(image_list, test_size=0.2, random_state=42)
print('total =',len(image_list))
print('train :',len(train_list))
print('val :',len(val_list))
total = 5000
train : 4000
val : 1000
from sklearn.model_selection import train_test_split
import os
from pathlib import Path
image_list = os.listdir('./Safety_Helmet_Detection_datasets_xml/images/')
from shutil import copyfile
''' Division train test val '''
#train_list, test_list = train_test_split(image_list, test_size=0.2, random_state=42)
#val_list, test_list = train_test_split(test_list, test_size=0.5, random_state=42)
# print('total =',len(image_list))
# print('train :',len(train_list))
# print('val :',len(val_list))
# print('test :',len(test_list))
''' Division train val '''
train_list, val_list = train_test_split(image_list, test_size=0.2, random_state=42)
print('total =',len(image_list))
print('train :',len(train_list))
def copy_data(file_list, img_labels_root, imgs_source, mode):
root_file = Path( './Safety_Helmet_Detection_datasets_VOC/images/'+ mode)
if not root_file.exists():
print(f"Path {
root_file} does not exit")
os.makedirs(root_file)
root_file = Path('./Safety_Helmet_Detection_datasets_VOC/labels/' + mode)
if not root_file.exists():
print(f"Path {
root_file} does not exit")
os.makedirs(root_file)
for file in file_list:
img_name = file.replace('.png', '')
img_src_file = imgs_source + '/' + img_name + '.png'
label_src_file = img_labels_root + '/' + img_name + '.txt'
#print(img_sor_file)
#print(label_sor_file)
# im = Image.open(rf"{img_sor_file}")
# im.show()
# Copy image
DICT_DIR = './Safety_Helmet_Detection_datasets_VOC/images/' + mode
img_dict_file = DICT_DIR + '/' + img_name + '.png'
copyfile(img_src_file, img_dict_file)
# Copy label
DICT_DIR = './Safety_Helmet_Detection_datasets_VOC/labels/' + mode
img_dict_file = DICT_DIR + '/' + img_name + '.txt'
copyfile(label_src_file, img_dict_file)
copy_data(train_list, './Safety_Helmet_Detection_datasets_xml/labels', './Safety_Helmet_Detection_datasets_xml/images', "train")
copy_data(val_list, './Safety_Helmet_Detection_datasets_xml/labels', './Safety_Helmet_Detection_datasets_xml/images', "val")
So here we are
python train.py --img 416 --batch 32 --epochs 300 --data data/helmet.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt
边栏推荐
- 博客停更声明
- L1-026 I love gplt (5 points)
- [real case] how to deal with the failure of message consumption?
- Email alarm configuration of ZABBIX monitoring system
- This article is enough for learning advanced mysql
- 【性能測試】一文讀懂Jmeter
- [go basics] 1 - go go
- Activiti common operation data table relationship
- Heap concept in JVM
- OKR vs. KPI 一次搞清楚这两大概念!
猜你喜欢
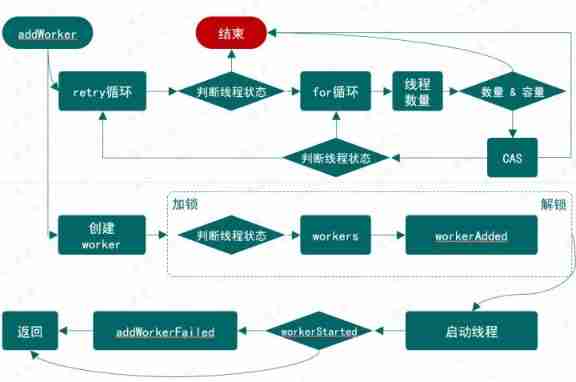
Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool

博客停更声明
ZABBIX monitoring system custom monitoring content
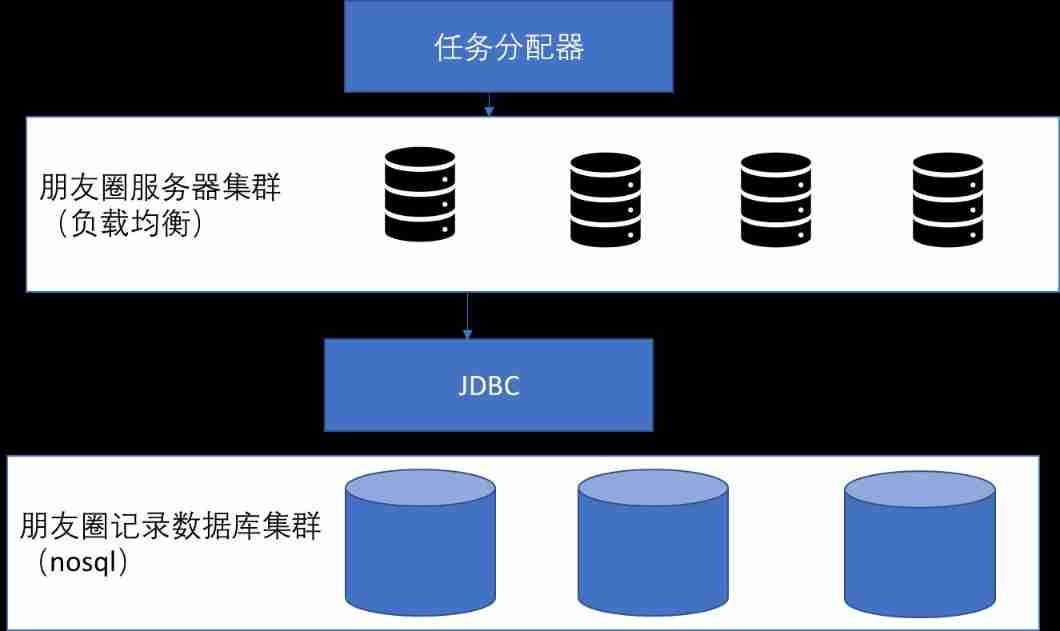
System architecture design of circle of friends

BUUCTF(4)
墨者学院-Webmin未经身份验证的远程代码执行

L1-027 rental (20 points)
【性能測試】一文讀懂Jmeter
Moher College phpmailer remote command execution vulnerability tracing
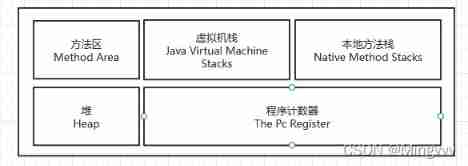
JVM -- class loading process and runtime data area
随机推荐
时序数据库 InfluxDB 2.2 初探
Node foundation ~ node operation
Is l1-029 too fat (5 points)
L1-024 the day after tomorrow (5 points)
【性能測試】一文讀懂Jmeter
Leetcode 146. LRU 缓存
The frost peel off the purple dragon scale, and the xiariba people will talk about database SQL optimization and the principle of indexing (primary / secondary / clustered / non clustered)
Div hidden in IE 67 shows blank problem IE 8 is normal
1、卡尔曼滤波-最佳的线性滤波器
Advanced MySQL: Basics (5-8 Lectures)
L2-013 red alarm (C language) and relevant knowledge of parallel search
Life planning (flag)
Distributed transaction management DTM: the little helper behind "buy buy buy"
PCIe knowledge points -010: where to get PCIe hot plug data
论文学习——基于极值点特征的时间序列相似性查询方法
Mysql database - function constraint multi table query transaction
【Go基础】1 - Go Go Go
This monitoring system can monitor the turnover intention and fishing all, and the product page has 404 after the dispute appears
The text box displays the word (prompt text) by default, and the text disappears after clicking.
Wechat has new functions, and the test is started again