当前位置:网站首页>深入浅出:了解时序数据库 InfluxDB
深入浅出:了解时序数据库 InfluxDB
2022-07-04 07:28:00 【sp42a】
时序数据库经常应用于机房运维监控、物联网IoT设备采集存储、互联网广告点击分析等基于时间线且多源数据连续涌入数据平台的应用场景,InfluxDB专为时序数据存储而生,尤其是在工业领域的智能制造,未来应用潜力巨大。
数据模型
时序数据的特征
时序数据应用场景就是在时间线上每个时间点都会从多个数据源涌入数据,按照连续时间的多种纬度产生大量数据,并按秒甚至毫秒计算的实时性写入存储。
传统的RDBMS数据库对写入的支持都是按行处理,并建立B树结构的索引,它并不是为了批量高速写入而设计,尤其像多纬度时序数据连续的涌入数据平台,RDBMS的存储引擎必然导致负载、吞吐在写入性能上的极不适应。因此时序数据的存储设计一般不会考虑传统RDBMS,都会将目光放在以LSM-Tree以及列式的数据结构存储方向。
LSM数据模型是对批量数据从内存到磁盘文件的层层下压,有些会对数据KV顺序排列,形成列簇存放文件,例如HBase,Cassandra;有些按列字段对应多个文件存储,形成列式存储,这样可以极大提升压缩率,例如 Druid.io。
再看时序数据结构:数据源(DataSource)+指标项(Metric)+时间戳(TimeStamp)=数据点,每个数据点就是时间线上的一个指标测量点。
如果从一个二维图来表示的话,就如同下图所示,横轴代表了时间,纵轴代表了测量值,而图中的每个点就是指标测量的数据点(Point)了。
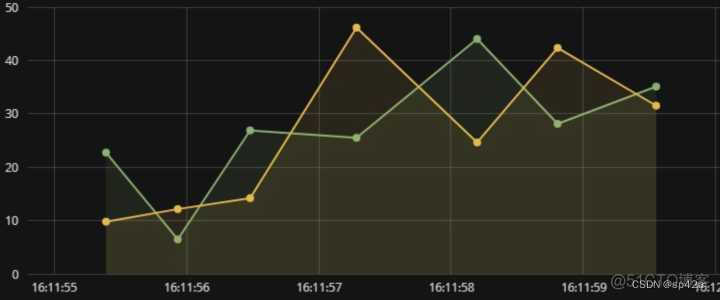
上图可以表述为:数据源1(动环检测-高新区机房-数据区)—指标(湿度),数据源2(动环检测-西咸新区机房-计算区)—指标(湿度)在连续时间点(TimeStamp)上的两条时序折线图。
其中动环检测代表了数据源的业务领域,机房、区域代表了数据源的标签(Tag),动环检测+机房+区域就确定了唯一的时序数据源。
基于HBase的OpenTSDB数据模型
时序数据库除了InfluxDB之外,还有另一个比较有名的时序库—OpenTSDB,OpenTSDB就是基于HBase平台的时序数据库实现,在我以前的回答中多次分析过HBase的内部机制,它的特征就是源自Google BigTable的数据模型,以列簇为数据组织和存储的整体单元。
我们可以理解列簇就是一张Excel宽表,表中每一个单元格就是由K/V组成,KEY由行键+列簇名+列名+时间等构成,那么对KEY排序后,类似单元格的K/V自然就形成了按照行键、列簇名、列名、时间的顺序排列。非常方便地按照行键去抓取列簇的一组列值。
我们从时序数据的特征可知,数据源+指标+时间戳就可以确定到一个数据点,那么在OpenTSDB的设计中,这个组合就是行键。不过由于时间戳是连续不同的,就会导致每个K/V的行键都不同,这会产生非常大量的单列数据。因此OpenTSDB进行了优化,将行键中的时间戳按照小时计,按照秒划分为3600个列,这样列簇的一行代表了一个小时的时序数据,每一列代表那一秒的值。
从机制设计的角度看,OpenTSDB基于HBase的特性进行优化,已经做得很好了。但是HBase的本质还是K/V作为一个原子单位,由多个K/V形成Block,再由Block形成HFile文件。
产生的缺点是:
- 每一个K/V都会因为KEY的构建带来大量的冗余,而且无法有效实现基于标签tag的条件索引,因为tag都揉进了行键之中,这就需要全量顺序扫描。
- KEY是无法在通用的压缩算法上进行有效压缩的,最终一定会占用更多的存储成本,本质问题还在于无法对时间戳(Timestamp)进行独立剥离处理。
InfluxDB数据模型
InfluxDB并没有打算完全搞一套全新的数据存储理论体系,而是在参考HBase的LSM-Tree数据模型后,建立一套适合时序数据的存储架构,名叫TSM。
我们再重复一下HBase的数据模型机制,追加WAL,在内存中建立批量写入的数据缓冲区MemStore,定期或写满的情况下MemStore冲刷(Flush)到磁盘StoreFile,StoreFile再定期进行文件合并,做归并排序并完成记录去重。这种基于LSM-Tree结构的数据模型能极大提升写入的性能,很多NoSQL系统都是这个操作路子。InfluxDB也不例外,继续这种LSM-Tree结构套路,时序数据写入时先追加WAL,然后再写入Cache,然后定期或写满的情况下冲刷(Flush)到磁盘TSM文件。
我们看它跟HBase不同的地方,主要在于数据结构的设计,HBase的MemStore对写入的数据直接封装成K/V然后组成一个个更大的Chunk块。这种结构最大的特点就是HBase以一种近乎于通用的方式顺序地将原子单元(K/V)排列并封装成更大的 Chunk 块,数据之间设计得非常松散,随机性查找不依赖数据结构优化,而是依赖索引基础上的扫描,属于万金油型,任何上层应用都可以拿来一用,例如:各种宽表业务的扫描查询、聚合分析或者设计出按时间线分析的TSDB。但是 InfluxDB 在 Cache 中重新优化了结构:Map集合<数据源,Map集合<指标,List列表<时间戳:数据值>>>,我们可以看到是一个 Map 套 Map 再套 List 的结构,第一层Map就是序列(Series)集合,Series就是InfluxDB定义的数据源(表 measurement + 多标签 tagset),第二层Map为指标集合,InfluxDB 定义指标为Fields,第三层就是某个数据源的某个指标的时间线记录列表了。
因此我们可以看到InfluxDB首先根据时序数据的特征,进行了数据结构上的重新调整来适应这种时序特征的需要,那么就有了以数据源为索引去定位指标,以指标为索引去定位时间线上的数据列表。
InfluxDB内存中Cache会Flush到TSM文件,TSM文件中也会根据上述结构建立磁盘文件的数据块排列和索引块排列,每个数据块就可以分别是Timestamps列表和Values列表组成。那么就可以对TimeStamps列表进行单独压缩(delta-delta编码),Values列表具有相同的类型Type,可以根据Type进行压缩。索引块建立数据块与Series之间的关系,并通过对时间范围的二分查找的方式快速定位待查数据的数据块位移。
InfluxDB索引
InfluxDb分为两种索引,一种是TSM文件内置的Series索引,另一种就是倒排索引,
- Series索引:在InfluxDB的内置索引中Series + field就是主键,定位到某项指标的一个索引块,索引块由N个索引实体组成,每个索引实体提供了最小时间和最大时间,以及这个时间范围对应到TSM文件Series数据块的偏移量,TSM文件有多个Series数据块组成,每个Series数据块就包含了时间列表(Timestamps),索引实体的最小时间和最大时间就对应了这个时间列表。因此Series索引块就可以通过Key排序,并通过时间范围进行二分查找,先快速定位某个时间范围上的时序数据,然后再做扫描匹配。
- 倒排索引:InfluxDB除了TSM结构之外,还有TSI结构,TSI主要是进行时序数据的倒排索引,例如:通过动环检测-高新区机房为条件查询高新区机房各个区域的各项指标,或者也可以通过动环检测-数据区域为条件查询所有机房的数据区域的各项指标。
TSI的数据结构为:Map集合<标签名,Map集合<标签值,List列表>>,第一层就是标签名集合,第二层就是某个标签名下的所有标签集合,例如:标签名为区域,就包含了数据区、计算区等标签值,第三层就是具体某个标签对应的数据源了,例如:包含数据区标签的数据源有动环检测-高新区-数据中心,动环检测-西咸新区-数据中心等数。
通过这种索引方式就能实现通过标签快速索引包含此标签的所有数据源。通过数据源的Series,再从TSM文件中按其他条件查找。TSI数据模型使用了与TSM一样的套路,本质上都是基于LSM数据结构,伴随数据写入,倒排索引先写WAL,在写内存In-Memory Index,当达到内存阀值后Flush倒TSI文件,而TSI文件就是基于磁盘的Disk-Based Index的倒排索引文件,里面包含了Series块和标签块,可以通过标签块中的标签值在Series块中找到对应的所有Series。
时序库在这种按数据源标签(Tag)分类的分析查询上会表现得非常高效,这也是InfluxDB充分应对了时序数据业务的需要。
分布式
InfluxDB在集群方面闭源了,这的确是件非常可惜的事情。不过可以理解,任何技术创业公司都要谋求生存和发展,商业输血是必须的,希望有一天InfluxDB的母公司能被巨头收购,然后再次完全开源。
我在以前专门讲过一期HBase和Cassandra的对比,有兴趣的朋友可以看看:HBase 与 Cassandra 架构对比分析的经验分享。
InfluxDB更倾向于去中心化的分布式,里面有我对两者分布式的对比,而InfluxDB更接近于Cassandra,Cassandra是一套去中心化的分布式架构,而InfluxDB包括了Meta节点和Data节点,但是Meta节点看似是主节点,但作用很薄弱,主要存储一些公共信息和连续查询调度,数据读写问题主要还是集中在Data节点,而Data节点之间的读写,更贴近于去中心化的方式。
InfluxDB是CAP定理中的AP分布式系统,非常侧重于高可用,而不是一致性。其次InfluxDB的主要是两级分片,第一级为ShardGroup,次一级是Shard。
ShardGroup是个逻辑概念,代表一个时间段内的多个Shard,在创建InfluxDb数据库(DataBase)和保留策略(RETENTION POLICY)后就确定了ShardGroup的连续时间段,这就相当于对时序数据首先进行了按照时间段范围的分区,例如1个小时作为一个ShardGroup。但是这1个小时内的数据并不是存储在一个数据节点上,这点就大大不同于HBase的Region了,Region首先会朝一个数据节点使劲地写,写饱了才进行Region拆分,然后实现Region迁移分布。而InfluxDB应该是参考了Cassandra那一套办法,使用了基于Series作为Key的Hash分布,将一个ShardGroup的多个Shard分布在集群中不同的数据节点上。
下面定位shard的代码中key就是Series,也就是唯一指定的数据源(表measurement +标签集合 tagset)。
shard := shardGroup.shards[fnv.New64a(key) % len(shardGroup.Shards)]
上面代码中shardGroup.Shards就是ShardGroup的Shard数量,该数量为N/X,N是集群中的数据节点数量,X就是副本因子。例如:集群有4个节点,2个副本,4/2就得到了需要将1个小时的ShardGroup范围数据拆成2个Shard,并各复制2份,分布在四个数据节点,就是通过这种Hash分布方式,更均匀的分布了时序数据,也充分利用集群每一个数据节点的读写优势。
InfluxDB是最终一致性,在写入一致性上实现了各种调节策略Any、One、Quorum、All,和Cassandra如出一辙,并且加强了协调节点的Hinted handoff的临时队列持久化作用,这就是完全为了高可用性。
即便真正的副本节点故障了,就先在协同节点的Hinted handoff队列中持久化保存,等到副本节点故障恢复后,再从Hinted handoff队列中复制恢复。就是为了达到最终一致性。
另外InfluxDB和Cassandra3.x及以前版本一样,具有后台碎片修复的反熵功能(anti-Entrory),不过有意思的地方是Cassandra在新的4.0版本已经不在保留后台读修复的功能了,而且之前版本也不推荐启用,因为具有了主动读修复能力,后台读修复作用不大,而且还影响性能。
当然InfluxDB是不是和Cassandra一样,在读取的过程中进行了主动读修复,因为是闭源系统,这点上我还不太清楚。
InfluxDB在删除问题上会表现的非常薄弱,只允许删除一个范围集合或者Series下的一个维度集合,这也是这种时序结构的设计使然,对单个Point的删除会很麻烦,成本很大。
删除方法上应该也是参考了Cassandra的Tombstone机制:去中心化的问题就是怕大家都删除副本后,某个正好处于故障中的副本节点又恢复了,它不知道发生了什么事情,但修复过程中它会认为被删除的副本大家弄丢了,而去让大家恢复。
有了Tombstone标记的长期存在,那么存在副本数据的故障节点,当恢复后根据其他副本节点Tombstone标记,也就知道自己故障期间曾经发生了删除的情况,马上进行自身对应副本数据的删除。
总结
首先Influxdb的出现,使得时序数据的存储体量大大减少,这极为有利于物联网时代的数据存储问题,关键是合理的存储结构设计,一方面能减少数据冗余量,另一方面能充分利用特定的压缩算法,例如:delta-delta压缩算法对TSM文件中时间戳集合的高度压缩;
其次我们在面对时间为主线的存储上,以前很难找到合适的方案,例如我们通过使用Elasticsearch建立日期索引来保存日志,但是我们总是在什么条件下创建,什么时候销毁的问题上纠结,而在编码层面费很大力气,但是Influxdb的保留策略与分区分组很好解决了这类问题;
最后就是更为合适时序模型的索引建立,尤其是倒排索引TSI,非常高效的实现了在一段时间内,按照某个纬度的数据抓取、聚合与分析,这又恰恰是时序应用场景的核心需求,能极大提升整体计算资源的应用效率。
边栏推荐
- Why does the producer / consumer mode wait () use while instead of if (clear and understandable)
- Industrial computer anti-virus
- Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
- [kubernetes series] kubesphere is installed on kubernetes
- University stage summary
- The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
- Enter the year, month, and determine the number of days
- Rapidjson reading and writing JSON files
- Introduction to rce in attack and defense world
- Novel website program source code that can be automatically collected
猜你喜欢
节点基础~节点操作
Flink memory model, network buffer, memory tuning, troubleshooting
The idea of implementing charts chart view in all swiftui versions (1.0-4.0) was born
Crawler (III) crawling house prices in Tianjin
BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment
![[kubernetes series] kubesphere is installed on kubernetes](/img/2b/eb39cf78b3bb9908b01f279e2f9958.png)
[kubernetes series] kubesphere is installed on kubernetes
用于压缩视频感知增强的多目标网络自适应时空融合
Transition technology from IPv4 to IPv6

NLP literature reading summary
Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
随机推荐
[Valentine's day] - you can change your love and write down your lover's name
Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
window上用.bat文件启动项目
University stage summary
Cell reports: Wei Fuwen group of the Institute of zoology, Chinese Academy of Sciences analyzes the function of seasonal changes in the intestinal flora of giant pandas
Experience installing VMware esxi 6.7 under VMware Workstation 16
Introduction to deep learning Ann neural network parameter optimization problem (SGD, momentum, adagrad, rmsprop, Adam)
2022-021ARTS:下半年開始
Computer connects raspberry pie remotely through putty
SQL foundation 9 [grouping data]
The number of patent applications in China has again surpassed that of the United States and Japan, ranking first in the world for 11 consecutive years
NLP-文献阅读总结
Tri des fonctions de traitement de texte dans MySQL, recherche rapide préférée
【森城市】GIS数据漫谈(一)
Campus network problems
tornado项目之路由装饰器
[kubernetes series] kubesphere is installed on kubernetes
Routing decorator of tornado project
Zephyr Learning note 2, Scheduling
Improve the accuracy of 3D reconstruction of complex scenes | segmentation of UAV Remote Sensing Images Based on paddleseg