当前位置:网站首页>[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution
[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution
2022-07-05 09:52:00 【hbw136】
Residual Local Feature Network for Efficient Super-Resolution
( Residual feature local network for efficient super-resolution )
NTIRE 2022
* The most influential international top event in the field of image restoration ——New Trends in Image Restoration and Enhancement(NTIRE)
author :Fangyuan Kong* Mingxi Li∗ Songwei Liu∗ Ding Liu Jingwen He Yang Bai Fangmin Chen Lean Fu
Company :ByteDance Inc
Code : https://github.com/fyan111/RLFN
Address of thesis :https://arxiv.org/pdf/2205.07514
One 、 Question motive
The method based on deep learning is used in single image super-resolution (SISR) Has achieved a good performance . However , Recent advances in efficient super-resolution focus on reducing parameters and FLOP The number of , They aggregate more powerful features by improving feature utilization through complex layer connection strategies . These structures are limited by today's mobile hardware architecture , This makes it difficult to deploy them to resource constrained devices .
Two 、 Main ideas and highlights
The author reexamines the most advanced and efficient SR Model RFDN , And try to achieve a better trade-off between the quality of the reconstructed image and the reasoning time . First , The author reconsidered RFDN The proposed residuals characterize the efficiency of several components of the distillation block . The author observed , Although characteristic distillation significantly reduces the number of parameters and contributes to overall performance , But it Not hardware friendly , And limit RFDN The reasoning speed of . In order to improve its efficiency , The author proposes a novel residual local feature network (RLFN), It can reduce network fragmentation and maintain model capacity . In order to further improve its performance , The author suggests using comparative loss . The author notes that , Its The selection of intermediate features of the feature extractor has a great impact on the performance . The author makes a comprehensive study of the properties of intermediate features , And come to the conclusion , Shallow features retain more accurate details and textures , This is for facing PSNR Our model is crucial . Based on this , author An improved feature extractor is constructed , It can effectively extract edges and details . In order to accelerate the convergence of the model and improve the final SR Recovery accuracy , author A novel multi-stage hot start training strategy is proposed . say concretely , At each stage ,SR Models can enjoy the benefits of pre training weights of models in all previous stages . Combined with the improved contrast loss and the proposed hot start training strategy ,RLFN It achieves the most advanced performance and maintains good reasoning speed . Besides , The author also obtained NTIRE 2022 High efficiency super-resolution challenge First place in the running time track .
The author's contributions can be summarized as follows :
- The author reconsidered RFDN The efficiency of , And studied its speed bottleneck . The author proposes a new residual local characteristic network , It successfully improves the compactness of the model , And without sacrifice SR In the case of restoring accuracy, the reasoning is accelerated .
- The author analyzes the intermediate features extracted by the contrast loss feature extractor . The author observed , Shallow features are critical to neural models , This inspired the author to propose a new feature extractor to extract more edge and texture information .
- The author proposes a multi-stage warm start training strategy . It can use the weight of the previous stage of training to improve SR performance .
3、 ... and 、 details
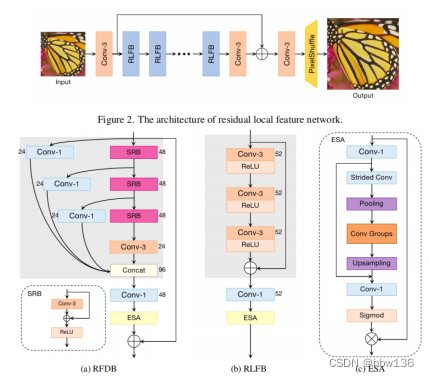
1、 Model structure
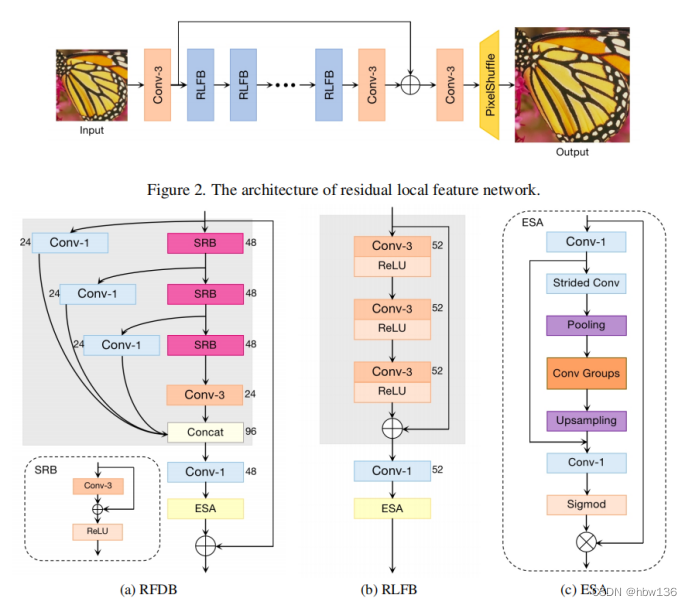
The residual local characteristic network proposed by the author (RLFN) The overall network architecture of is shown in the figure above . The author's RLFN It mainly consists of three parts : The first feature extraction convolution 、 Multiple stacked remaining local feature blocks (RLFBs) And refactoring module . The author will ILR and ISR Expressed as RLFN Input and output of . In the first phase , The author uses a single 3×3 Convolution layer to extract rough features :
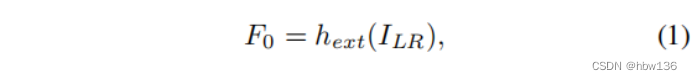
among ,hext(·) Convolution operation for feature extraction ,f0 Map the extracted features . then , The author uses multiple... In a cascading manner rlfb Depth feature extraction . This process can be used :
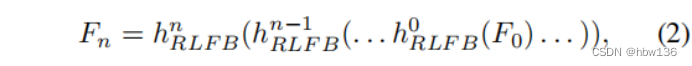
among ,hnRLFB(·) It means the first one n individual RLFB function ,Fn For the first time n Output feature mapping .
Besides , The author uses a 3×3 Convolution layer to smooth the gradually refined depth feature map . Next , Apply the refactoring module to generate the final output ISR.

among ,frec(·) Means by a 3×3 Convolution layer and a sub-pixel operation ( nonparametric ) Reconfiguration module . Besides ,fsmooth Express 3×3 Convolution operation .
Compared with the original RFDN(baseline) In contrast, the author mainly deleted the distillation branch and replaced it with residual connection , After redundancy analysis, each group Inside conv The quantity is reduced to one , Ensure the operation efficiency on mobile devices .
2、 Review and compare losses
Comparative learning shows impressive performance in self supervised learning . The basic idea behind it is to push positive numbers to anchor points in potential space , And push the negative number away from the anchor . Recent work has proposed a novel contrast loss , And by improving the quality of the reconstructed image to prove its effectiveness . The comparison loss is defined as :
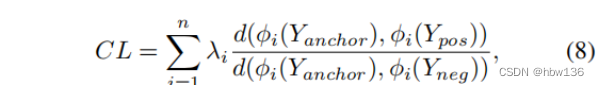
among ,φj It means the first one j The middle feature of the layer .d(x,y) yes x and y Between l1 distance ,λj Is the balance weight of each layer .AECR-Net and CSD After pre training VGG-19 Of the 1、 The first 3、 The first 5、 The first 9 And the 13 Extract features from layers . However , author It is found through experiments that , When using contrast loss ,PSNR The value is reduced .
Next , The author tries to investigate its reasons to explain this difference . The contrast loss defined in the equation (8) It mainly depends on two images Y1 and Y2 Differences between characteristic diagrams . therefore , The author attempts to visualize the model trained in advance φ The difference graph of the extracted feature graph :
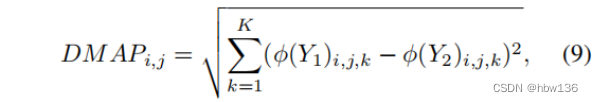
In style ,i、j by y1、y2 The space coordinates of ,k by y1、y2 Channel index . Author use DIV2K In dataset 100 A confirmatory high-resolution image is used as Y1, The corresponding image reduces the fuzzy kernel to Y2. The following figure shows an example of visualization . A surprising observation is , The feature difference map extracted from a deeper level is more semantic , But lack of accurate details . for example , Most of the edges and textures remain in the first layer , And the first 13 The characteristics of the layer only retain the overall spatial structure , And details are often missing . in summary , Deep features can improve the performance of real perception quality , Because it provides more semantic guidance . Features from shallow layers retain more accurate details and textures , This is for facing PSNR Our model is crucial . The author is suggested to use Shallow features to improve the training model PSNR.

In order to further improve the comparison loss , The author discusses the architecture of feature extractor again . The original contrast loss attempts at ReLU Minimize the distance between two active features after activating the function . However ,ReLU Functions are unbounded , The active feature map is sparse , Loss of information , Provide weak supervision . therefore , The author will feature extractor ReLU Replace the activation function with Tanh function .
Besides , because VGG-19 Yes, it is ReLU Activate the function for training , So if you don't go through any training, you will ReLU Replace activation with Tanh function , Then performance cannot be guaranteed . Some recent studies show that , A randomly initialized network with good structure is enough to capture the perceptual details . Inspired by these works , The author constructs a two-layer feature extractor with random initialization , It has Convk3s1-Tanh-Convk3s1 Architecture of . Trained in advance VGG-19 The difference diagram with the feature extractor proposed by the author is shown in the following figure . The author can observe , With pre trained VGG-19 Compared with the difference diagram , The difference graph of the feature extractor proposed by the author has stronger response ability , You can capture more details and textures . This also provides evidence , It shows that a randomly initialized feature extractor can capture some structural information , And pre training is unnecessary .

3、 Warm start strategy (warm start)
For things like SR In the task 3 or 4 Such a large-scale factor , Some previous work used 2x The model acts as a pre trained network , Instead of training them from scratch .2x The model provides good initialization weights , Accelerated convergence , Improved final performance . however , Due to the difference between the pre training model and the target model scale Different , Once for a specific scale Our training can't adapt to many scales .
To solve this problem , The author proposes a new multi-stage warm start training strategy , It can be improved through experience SISR Model performance . In the first phase , The author trains from scratch RLFN. Then in the next stage , The author is not training from scratch , Instead of loading the previous stage RLFN The weight of , This is called the warm start strategy . Training settings , Such as batch size and learning rate , Follow exactly the same training program in the first stage . In the following article , Author use RFLN_ws_i To indicate the use of warm start i Time ( stay i+1 After the phase ) Training model of . for example ,RFLN_ws_1 Represents a two-stage training process . In the first phase , The author trains from scratch RLFN. And then in the second stage ,RLFN Load the pre trained weights , And train according to the same training program as the first stage .
Four 、 experiment
1、 Set up
Data sets and indicators are used by authors DIV2K In dataset 800 Training images . The author tested the performance of the author's model on four benchmark data sets :Set5、Set14、BSD100 [35] and Urban100. The author in YCbCr Spatial Y Evaluation on the channel PSNR and SSIM. Training details the author's model is in RGB Trained on the channel , By randomly flipping and 90 Degree rotation to increase training data . LR The image is through MATLAB Bicubic interpolation pairs are used in HR The image is generated by down sampling . The author from ground truth The random clipping size in is 256×256 Of HR Patch , The small batch size is set to 64. The training process is divided into three stages . In the first phase , The author trains the model from scratch . Then the author adopts the hot start strategy twice . At each stage , The author sets β1 = 0.9、β2 = 0.999 and = 10−8 To adopt Adam Optimizer , And in RFDN Minimize after the training process L1 Loss . The initial learning rate is 5e-4, Every time 2 × 105 The second iteration is halved . Besides , The author also used the widely used contrast loss in the third stage . The author realizes two models ,RLFN-S and RLFN. RLFB The number of is set to 6. The author will RLFN The number of channels of is set to 52. For better running time ,RLFN-S The number of channels is small , by 48.
2、 experimental result

3、 Ablation Experiment
In order to evaluate the effectiveness of the author's model architecture optimization , The author designed RFDB Two variants of . Pictured 7 Shown , Author delete RFDB The characteristic distillation layer in RFDBR48, then RFDBR52 Increase the number of channels to 52,ESA The intermediate channel of is increased to 16, To reduce performance degradation ,RLFB Delete based on RFDBR52 Of SRB Internal intensive adding operations .RFDB、RFDBR48、RFDBR52 and RLFB As SR The main parts of the network are stacked , As shown in the following table ,RLFB And RFDB Maintain the same level of recovery performance , But it has obvious speed advantage .

To study the effectiveness of comparative losses , The author removed the contrast loss in the second hot start stage , Use only L1 Loss . As shown in the following table , On four benchmark datasets , The comparative loss continues to increase PSNR and SSIM Performance of .

Effectiveness of the hot start strategy in order to prove the effectiveness of the hot start strategy proposed by the author , The author compares RLFN-S ws 1 As two variants of baseline and different learning rate strategies ,RLFN-S e2000 and RLFNS clr. The comparison loss is not used in this comparison , Other training settings remain unchanged . They set the total period as 2000 In order to RLFN-S ws 1 Compare .RLFNS e2000 Every time 4 × 105 This iteration will halve the learning rate . RLFN-S clr Apply the circular learning rate strategy , And RLFN-S ws 1 identical . however , It loads the state of the optimizer , and RLFN-S ws 1 Apply default initialization . As shown in the following table , Compared with the hot start strategy proposed by the author ,RLFN-S e2000 and RLFN-S clr To reduce the PSNR and SSIM. It shows that the hot start strategy is helpful to jump out of the local minimum in the optimization process , Improve overall performance .

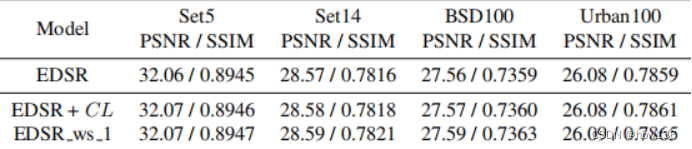
The author also studies the promotion of the contrast loss and hot start strategy proposed by the author . The author of this paper is concerned with EDSR Compare loss and hot start strategies . Quantitative comparison is shown in the following table , This shows that the method proposed by the author is universal , It can be applied to other existing SISR Model .
5、 ... and 、 summary
In this paper , The author puts forward an effective SISR The residual local characteristic network of . By reducing the number of layers and simplifying the connection between layers , The author's network is lighter 、 faster . then , The author reexamines the use of comparative loss , Change the structure of the feature extractor , And reselect the intermediate features used to compare losses . The author also proposes a hot start strategy , This is good for lightweight SR Model training . A lot of experiments show that , The author's overall plan , Including model structure and training methods , The balance between quality and reasoning speed is achieved .
6、 ... and 、 inspire
1、 After reading through the author's paper , We know that shallow features are crucial to face-to-face neural models , The author also proposes a new feature extractor to extract more edge and texture information , It can be used to improve the index performance of the model (?) And visual effects
2、 The multi-stage warm start training strategy proposed by the author . It can use the weight of the previous stage of training to improve SR performance .
边栏推荐
- Cross process communication Aidl
- Observation cloud and tdengine have reached in-depth cooperation to optimize the cloud experience of enterprises
- 卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
- [technical live broadcast] how to rewrite tdengine code from 0 to 1 with vscode
- La voie de l'évolution du système intelligent d'inspection et d'ordonnancement des petites procédures de Baidu
- How to use sqlcipher tool to decrypt encrypted database under Windows system
- 盗版DALL·E成梗图之王?日产5万张图像,挤爆抱抱脸服务器,OpenAI勒令改名
- 代码语言的魅力
- 【el-table如何禁用】
- How to choose the right chain management software?
猜你喜欢
解决idea调试过程中liquibase – Waiting for changelog lock….导致数据库死锁问题

Roll up, break 35 - year - old Anxiety, animation Demonstration CPU recording Function call Process
Unity skframework framework (XXIII), minimap small map tool
How to implement complex SQL such as distributed database sub query and join?
小程序启动性能优化实践
百度评论中台的设计与探索
卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
How to empty uploaded attachments with components encapsulated by El upload
oracle 多行数据合并成一行数据
基于模板配置的数据可视化平台
随机推荐
The writing speed is increased by dozens of times, and the application of tdengine in tostar intelligent factory solution
How to choose the right chain management software?
Community group buying has triggered heated discussion. How does this model work?
Community group buying exploded overnight. How should this new model of e-commerce operate?
Roll up, break 35 - year - old Anxiety, animation Demonstration CPU recording Function call Process
Tdengine can read and write through dataX, a data synchronization tool
Node-RED系列(二九):使用slider与chart节点来实现双折线时间序列图
Officially launched! Tdengine plug-in enters the official website of grafana
植物大战僵尸Scratch
Unity SKFramework框架(二十三)、MiniMap 小地图工具
The most comprehensive promotion strategy: online and offline promotion methods of E-commerce mall
uni-app---uni. Navigateto jump parameter use
Wechat applet obtains household area information
Thermometer based on STM32 single chip microcomputer (with face detection)
微信小程序获取住户地区信息
美图炒币半年亏了3个亿,华为被曝在俄罗斯扩招,AlphaGo的同类又刷爆一种棋,今日更多大新闻在此...
Android SQLite database encryption
从“化学家”到开发者,从甲骨文到 TDengine,我人生的两次重要抉择
cent7安装Oracle数据库报错
【饿了么动态表格】