当前位置:网站首页>Csdn-nlp: difficulty level classification of blog posts based on skill tree and weak supervised learning (I)
Csdn-nlp: difficulty level classification of blog posts based on skill tree and weak supervised learning (I)
2022-07-06 10:43:00 【Alexxinlu】
Catalog
Team blog : CSDN AI team
1. background
CSDN Tens of thousands of blog data are generated every day , But these data have no difficulty level architecture , This architecture is in Personalized recommendation 、 User portrait 、 The list And other businesses have great role and value .
This paper mainly expounds how to build a difficulty level classification framework from scratch , Used to realize blog in primary 、 intermediate 、 senior Classification on three categories .
In the way of implementation , Because accurate annotation data is difficult to obtain , Therefore, according to the characteristics of each time stage , Use different methods , Gradually improve the effect of classification .
2. Method
The framework of this paper is based on different stages of framework construction , Mainly divided into the following 3 Parts of .
2.1 The rules : Fast implementation
The first 1 Part is rule building , Rules can open up the whole process , In ensuring accuracy (Precision) Under the premise of , Realize the difficulty level classification of some blog data .
To be specific , By observing the blog sample, we find , Some keywords or patterns in the title can clearly reflect the difficulty level of the article , We call it a strong rule . Through to primary 、 intermediate 、 senior Induction of three hierarchical strong rules , The following rules can be drawn ( For the sake of explaining the problem , The following is a simplified rule )
Primary category strong rules
primary_level_pat = re.compile(r' primary | The first step | introduction | Basics | Set of wrong questions | practice | After-school exercises | Exercise answer | Learning notes | Exam resumption | Practice every day | A daily topic | Daily real topic | Management system | Management platform | common | Commonly used | Environment building | install | With your hand | Notes | Clock in | Step on the pit | Tips ')
Intermediate category strong rules
middle_level_pat = re.compile(r'((?:(?: intermediate | framework | The architecture )(?!.*?(?: t | post )))|(?: Middle stage | Advanced | thorough ))')
Advanced category level strong rules
high_level_pat = re.compile(r' senior (?!.*?(?: t | post ))| Higher order (?! function )| The paper ')
Based on the above rules , Through regular matching of blog titles , It can quickly realize the judgment of blog difficulty level
def strong_rules_4_level(title):
''' Blog difficulty level classification strong rules '''
rule_level = None
kw_list = None
# primary
kw_list = primary_level_pat.findall(title)
if kw_list:
rule_level = "1"
kw_list = list(set(kw_list))
return rule_level, kw_list
# intermediate
kw_list = middle_level_pat.findall(title)
if kw_list:
rule_level = "2"
kw_list = list(set(kw_list))
return rule_level, kw_list
# senior
kw_list = high_level_pat.findall(title)
if kw_list:
rule_level = "3"
kw_list = list(set(kw_list))
return rule_level, kw_list
return rule_level, kw_list
Besides , Low quality blogs can be directly classified as primary categories . Please refer to the calculation logic of blog quality score Blog quality score calculation ( Two ), The value of quality score {0, 1, 2, 3, …, 100}, When the mass score is less than 20 time-sharing , Judged as a low-quality blog .
Optimize : Realize fast landing 、 Accuracy (Precision) high 、 Strong explanatory ability .
shortcoming : Lack of architecture 、 Coverage and recall (Recall) low ( Poor generalization ability ).
2.2 matching : Structured knowledge system
The first 2 Part is the integration of structured knowledge data system . In the 1 In the part , Usually, we can only observe the sample data , Build an extremely simple set of rules . This set of rules is usually simple 、 Lack of systematicness , And the architecture needs domain experts to build . therefore , In order to further improve the effect of difficulty level classification , This paper introduces the CSDN The skill tree , And based on the matching method , Realize the classification of blog difficulty level .
Example of skill tree architecture As shown below (C Simplified version of language skill tree )
C Language
├── C Elementary language
│ ├── C Language Overview
│ │ ├── C History of language development
│ │ ├── C Language features
│ │ └── Programming mechanism
│ ├── data type
│ │ ├── Variable
│ │ ├── Constant
│ │ └── Basic data type
│ └── Statement and control flow
│ ├── Statements and blocks
│ ├── Judgment statement
│ └── Loop statement
├── C Medium level language
│ ├── Function and program structure
│ │ ├── Function declaration and definition
│ │ ├── Function call
│ │ └── Recursion of a function
│ ├── Array
│ │ ├── One dimensional array
│ │ ├── Two dimensional array
│ │ └── Variable length array
│ └── The pointer
│ ├── Pointer and address
│ ├── Pointers and function parameters
│ └── Pointers and arrays
└── C Language high level
├── Structure
│ ├── Array of structs
│ ├── Structure pointer
│ └── The chain structure
├── The preprocessor
│ ├── Macro definition
│ ├── Conditional compilation
│ └── Inline function
└── Storage management
├── Storage class
└── Dynamic memory management
This article is based on some keywords in the tag or title of the blog , Through tags or keywords and Mapping relationship between skill trees , Determine the skill tree most relevant to the current blog , The mapping table is shown below ( With C Take the language skill tree as an example )
{
"tree_name": "c",
"keywords": [
"C Language ",
"C/C++",
" Structure ",
...
]
}
After determining the skill tree , Use skill tree matching algorithm , Calculate the similarity of knowledge points in blog and skill tree , See... For details CSDN Q & a tag skill tree ( Two ) —— Effect optimization Medium 2.2 Optimization of matching algorithm . After matching the most similar knowledge points , Pass the difficulty level of this knowledge point , And then get the difficulty level of the article .
advantage : authority 、 Strong explanatory ability .
shortcoming : Knowledge construction requires a lot of manpower and material resources .( The current online skill tree has not covered all fields ).
2.3 classification : Weak supervised learning
The first 3 Part is the use of classification model based on weak supervised learning . classification method It can alleviate the problem of 1 The problem of poor generalization ability in part , And the first 2 Part of the problem of imperfect knowledge system .
Training a classification model requires a lot of annotation data , In order to reduce the consumption of human and material resources caused by data annotation , This paper uses the method of weak supervised learning to realize the classification of difficulty levels .
To be specific , In blog data , Some data users have marked the difficulty level by themselves , But because everyone's cognition of the difficulty rating system is different , This leads to more noise in the data set , To alleviate the problem , This article uses data editing (data-editing) Methods to optimize data sets ( Reference paper A brief introduction to weakly supervised learning), Improve the quality of data sets . The detailed steps are as follows :
- (1) To quantify : Use TF-IDF The algorithm applies to all blog samples in the data set ( Blog title ) To quantify ;
- (2) Graph construction : Take Blog samples as nodes , The similarity between samples is edge weight , Build a sample diagram ;
- (3) Data editing :
- a) For a node , If top_n All adjacent nodes of are of the same category , And it is consistent with the category of the current node , Add directly to the new data set ;
- b) For a node , If top_n All adjacent nodes of are of the same category , And it is inconsistent with the category of the current node , After modifying the label to the category of adjacent nodes , Add to the new dataset ;
- c) Nodes in other situations , Give up directly .
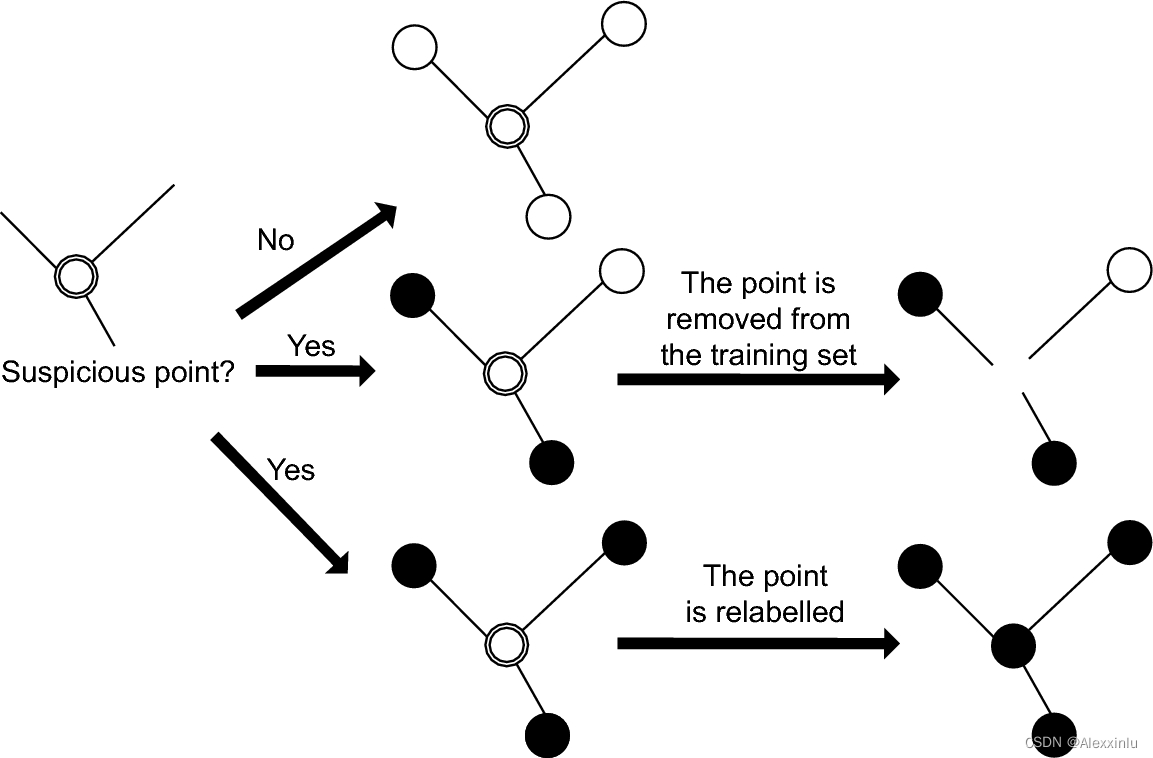
chart 1. Data editing
After getting the optimized data set , Use it directly sklearn.ensemble.RandomForestClassifier The classifier realizes the classification of blog samples .
advantage : The cost is low 、 The generalization ability is strong .
shortcoming : The credibility of weak supervision effect is low .
2.4 The fusion : Do your best
The above three methods have different advantages and disadvantages , The complementarity of different methods can be achieved through specific fusion strategies , While giving full play to the advantages of various methods , Weaken shortcomings . The specific strategies are as follows :
- (1) For samples identified by strong rule method , The result of using strong rules directly ;
- (2) For matching results ( Similarity score ) The sample of , Weighted fusion with classification probability value ;
- (3) For samples without matching results , Judge directly by classification probability .
Use the above strategy ,a) Can give full play to the role of strong rules , Improve the accuracy of the overall framework (Precision);b) Because the confidence of the results of weak supervision method is not high enough , Therefore, the result of skill tree matching , Adjust the classification results ;c) Because in the matching method , The skill tree knowledge system does not cover all areas , Therefore, samples in uncovered areas can be classified by direct classification .
3. Summary and prospect
3.1 summary
Difficulty level classification seems to be a simple classification problem , However, due to the lack of accurate annotation data, it is difficult , According to the idea of rapid landing and continuous rapid iteration , This paper has the same strong rule 、 Matching algorithm based on knowledge system 、 Classification algorithm based on weak supervision , Gradually improve the whole classification framework , It has strong enforceability and fast iteration speed .
3.2 expectation
- (1) The current matching algorithm is based on keyword matching , Next, we will consider the vector based matching method , To improve the generalization ability of the matching algorithm ;
- (2) The current weak supervision strategy is still relatively simple , A small amount of annotation data will be used later , Based on semi supervised method , Further optimize the data set .
4. Related links
CSDN The skill tree
Blog quality score calculation ( Two )
CSDN Q & a tag skill tree ( Two ) —— Effect optimization
A brief introduction to weakly supervised learning
边栏推荐
- [Julia] exit notes - Serial
- CSDN问答模块标题推荐任务(二) —— 效果优化
- API learning of OpenGL (2004) gl_ TEXTURE_ MIN_ FILTER GL_ TEXTURE_ MAG_ FILTER
- Super detailed steps for pushing wechat official account H5 messages
- Global and Chinese markets for aprotic solvents 2022-2028: Research Report on technology, participants, trends, market size and share
- Copy constructor template and copy assignment operator template
- MySQL20-MySQL的数据目录
- Pytorch LSTM实现流程(可视化版本)
- [Li Kou 387] the first unique character in the string
- Pytorch RNN actual combat case_ MNIST handwriting font recognition
猜你喜欢
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
Mysql30 transaction Basics
Mysql36 database backup and recovery

Super detailed steps for pushing wechat official account H5 messages

Use xtrabackup for MySQL database physical backup
The underlying logical architecture of MySQL
Mysql21 user and permission management
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
ZABBIX introduction and installation
CSDN问答标签技能树(五) —— 云原生技能树
随机推荐
February 13, 2022-2-climbing stairs
What is the current situation of the game industry in the Internet world?
Mysql34 other database logs
MySQL27-索引优化与查询优化
Download and installation of QT Creator
Copy constructor template and copy assignment operator template
First blog
UEditor国际化配置,支持中英文切换
在jupyter NoteBook使用Pytorch进行MNIST实现
The underlying logical architecture of MySQL
[after reading the series] how to realize app automation without programming (automatically start Kwai APP)
Software test engineer development planning route
C语言标准的发展
Typescript入门教程(B站黑马程序员)
Mysql27 index optimization and query optimization
Global and Chinese market for intravenous catheter sets and accessories 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of operational amplifier 2022-2028: Research Report on technology, participants, trends, market size and share
[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in
MySQL27-索引優化與查詢優化
解决扫描不到xml、yml、properties文件配置