当前位置:网站首页>蚂蚁集团时序数据库CeresDB正式开源
蚂蚁集团时序数据库CeresDB正式开源
2022-08-04 19:27:00 【支付宝技术】
“我挺好奇的,为什么叫 CeresDB?”
“当时正在看热播的美剧《苍穹浩瀚》(The Expanse),其中提到谷神星(Ceres)是第一颗被人类发现的小行星,CeresDB 是 TimeSeries 的谐音,而且读起来还挺顺口的就决定是它了。”
“...这么简单?”
“可能就是种缘分吧。”
1.背 景
CeresDB 诞生于蚂蚁集团内部,是一个分布式、高可用、高可靠的时间序列数据库 Time Series Database。经过多年双11打磨,作为蚂蚁全站监控数据存储的时间序列数据库,承载了每天数万亿数据点的写入,并提供多维度查询。今天 CeresDB 宣布正式开源,通过开源,我们希望帮助用户解决时间序列数据存储的水平扩展与高可用的痛点,乃至针对时序数据的复杂分析计算能力的需求。本次正式开源也伴随着我们开源版本 0.2.0 的发布。
2.时序数据介绍
时序数据是基于时间的一系列数据点的集合,在有时间的坐标中将这些数据点连成线,从时间维度往前看可以做成多维度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析、机器学习、实现预测和预警。
我们经常会在 IoT 以及一些异常检测的分析场景中听到时序数据这个名词,如下图:
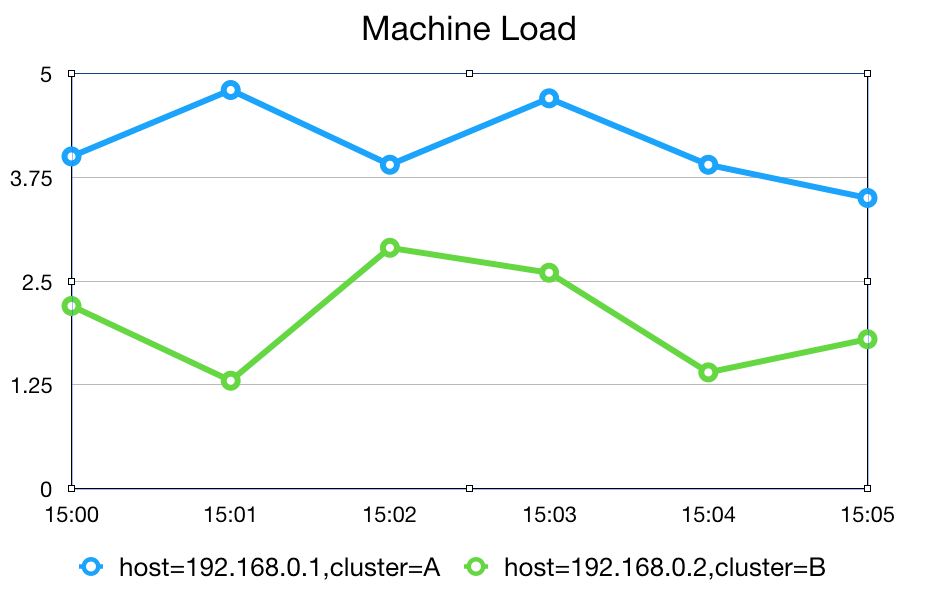
可以看出时序数据其实就是按照时间维度记录的数据列,并且前后数据具备可对比行,从而通过观察数据列随着时间的变化,提取出所需要的有用信息。
下面的文本也就是上图的原始数据点:
host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:00 ==> 4host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:01 ==> 4.8host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:02 ==> 3.9host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:03 ==> 4.7host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:04 ==> 3.9host=192.168.0.1,cluster=A | timestamp=2022-06-26 15:05 ==> 3.5host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:00 ==> 2.2host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:01 ==> 1.3host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:02 ==> 2.9host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:03 ==> 2.6host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:04 ==> 1.4host=192.168.0.2,cluster=B | timestamp=2022-06-26 15:05 ==> 1.8
2.1 数据的写入特点
写入持续、平稳、高吞吐:一般以固定频率写入数据
写多读少:通常只关心几个特定关键指标或特定场景下的指标
实时写入最新的数据:随着时间推进,新写入的数据从时间属性看都是新的数据,很少甚至不存在旧数据的更新
2.2 数据查询/分析的特点
按照时间范围读取
最近的数据被读取的概率最高
历史数据粗粒度查询的概率高
多种精度查询
多种维度查询
2.3 数据存储的特点
量大:TB 甚至 PB,数据压缩是降低成本的关键
冷热分明:越是历史数据,被查询的概率越低,对数据的时间精度的要求越低
时效性:数据有生命周期,超过生命周期的数据可以被清理
多精度数据存储:基于存储成本和查询效率上的考虑,需要将数据降为多种更粗时间精度进行存储
可预聚合:固定条件查询场景多,基于查询效率上的考虑,通常会提供预聚合来避免每次查询时进行后计算
由于时序数据记录规模巨大,这就导致数据的实时写入成为瓶颈,大规模数据存储的成本,成为新的技术挑战。传统的数据库如 MySQL 由于未能充分利用这些时序数据鲜明的特点,很难去解决相应的写入和分析性能、存储成本等问题,如果基于传统数据库存储时序数据,通常企业的运营维护成本会急剧上升。
3.业界时序数据库现状
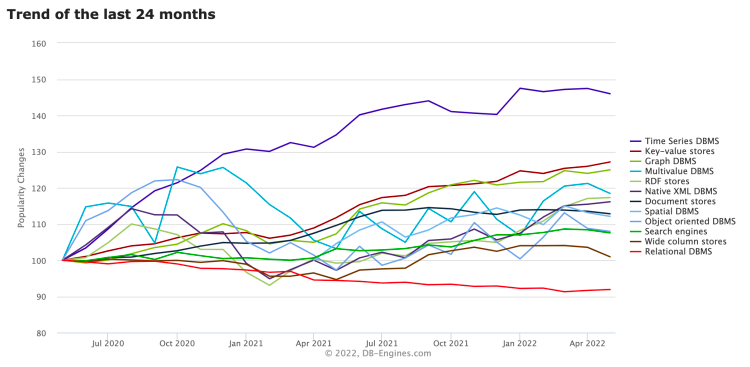
由上图 (来自 DB-Engines Ranking)不难看出,最近几年时序数据库正处于高速发展阶段,涌现出一批优秀的开源产品,把时序数据库技术深度推向了一个更高的台阶。
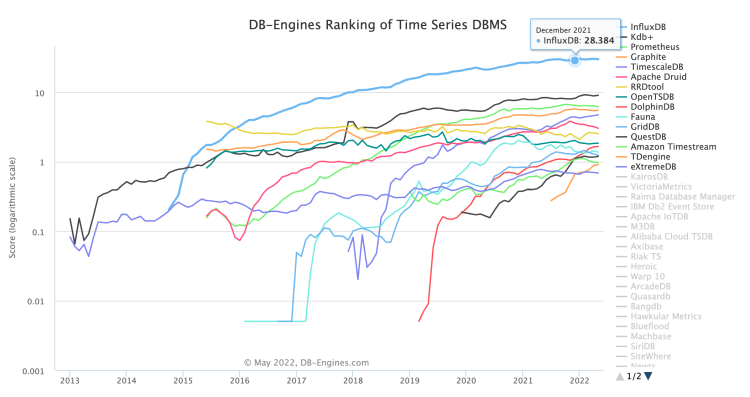
再看时序数据库的排名(上图来自 DB-Engines TimeSeries),热度前三分别是 InfluxDB、Kdb+、Prometheus。时下最受欢迎的时序数据库非 InfluxDB 莫属,常年霸榜 DB-Engines TimeSeries 分类。InfluxDB 实际上是围绕着时序数据打造了一个生态,除了时序存储本身还有很多配合 InfluxDB 的项目,比如告警、日志收集等。不过遗憾的是 InfluxDB 仅仅开源了单机引擎存储,集群功能是作为商业服务提供。
大概在快两年以前,InfluxDB 启动了一个叫 InfluxDB IOx 项目,IOx 发音为 eye-ox,iron oxide(氧化铁)的简写,与锈(Rust)相呼应。IOx 项目准备在时序 OLAP 方向上发力。
是的你没看错,IOx 项目基于 Rust 开发,我们此次开源的 CeresDB 的主要技术栈也是 Rust。另一个流行的时序数据库是 Kdb+。提到 Kdb+,了解过的小伙伴们一定都知道,它是华尔街投行、各类日内交易和高频交易的量化基金近乎标准的配置。Kdb+ 既是一个数据库(Kdb)也是一个矢量语言(q),它是基于有序表的概念(时间序)的一个内存中面向列存的数据库,它的主要数据存储在 RAM 中。Kdb+ 的查询速度非常之快,我认为这主要归功于三点:
Kdb+ 充分利用了向量化,向量化允许一次同时对多个数据点进行操作,可以很大程度减少实现某项操作所需的操作次数,这消除了对每一块数据的重复操作,大大减少了开销;
Kdb+ 具有内置的查询语言,计算直接在引擎内执行,不需要额外的数据传输。借助内置的查询语言,数据可以直接库内分析计算,无需通过网络和计算分析层进行移动数据。库内分析对于扫描大量原始数据但聚合计算后结果却很小的场景,无疑会呈数量级的加速查询速度;
列存结构对分析型场景的查询更加有效,大家一定都能想明白列存对少数列查询场景的好处,以及对向量化操作的友好度,这里不多做解释了。
再到排名第三的 Prometheus,在云原生的大背景下 Prometheus 可谓既定事实的监控标准。它不仅仅是一个时间序列数据库,而是一个监控系统,它有全套的数据抓取、检索、绘图、报警等功能。Prometheus 很大程度上受 Google 内部 Borgmon 系统的启发,基于 pull 模式实现的监控系统。需要强调的是,PromQL 可谓是为监控而生的查询语言。
4.CeresDB 有什么优势?
我们即将开源的是 CeresDB 最新的版本,上面介绍了 3 个业界非常厉害的时序数据库,那么可能有朋友会有疑问:”CeresDB 和它们有什么区别,CeresDB 是不是重复的轮子?“业界专注于监控或 IoT 领域并支持多维查询的时序数据库不少,但同时能兼顾海量数据分析场景的时序数据库少之又少。
相对应的,开源版本 CeresDB 脱胎于内部,它定位为高性能的、分布式的、Schema-Less 的新一代时间序列数据库。不同于传统时序数据库,CeresDB 的目标不仅仅是能够处理具备常规时序特征(Timeseries)的数据,同时也要能够应对复杂的分析型场景。
在传统的时序数据中,常用的处理手段是对 Tag 做倒排索引,但是在实际的使用过程中,会发现 Tag 的复杂度在不同场景下很不一样,有些场景复杂度会非常高,直接导致倒排索引完全无法工作,针对这样的场景,往往是通过分析型数据库采用的手段(扫描+剪枝)可以达到较好的效果。CeresDB 在吸取了蚂蚁内部时序数据大量实践经验后,从整体设计上重点考虑了 Timeseries 和 Analytical 的两种不同场景,采用不同的存储、查询模式,来达到一个综合上比较好的效果。
CeresDB 会在兼容 Prometheus、OpenTSDB 等传统时序数据库协议和生态并提供高吞吐写入的同时,还将支持 SQL 查询并提供类似 Kdb+ 以及 InfluxDB IOx 的分析能力(OLAP)。
5.为什么要开源?
CeresDB 还处于一个相对早期的阶段,本次正式开源以及同时发布的 0.2.0 版本仅仅是一个包含了 Analytical Engine 的分析型单机时序数据库和基本的分布式解决方案。但是想要说明的是,它仍是一个可用的版本,它也在蚂蚁集团内部一些场景中进行了落地。在此版本之前,我们在蚂蚁内部也积累了大量的时序使用经验,这些年在时序领域的研发我们从社区也吸取了大量营养,现在我们想要把一个融合团队多年经验的新一代产品回馈到社区。
此外,除了CeresDB,我们后续也会在这个领域开源更多组件。作为一个开放的项目,我们认为以开源方式进行研发,也有利于我们继续吸收社区的想法,推动这个项目往前走。项目开源之后,所有的研发与相关的工作都会在社区透明运行,希望能有更多的朋友参与到项目的研发。我们长远目标是希望 CeresDB 成为真正被广大开发者接受的基础软件。
6.Release 0.2.0 概要说明
在本次发布的 v0.2.0 版本,CeresDB实现了时序分析引擎的研发,支持常见 SQL 进行读写操作;实现了静态分布式部署方案,完成了云原生布式集群方案的一些前置工作。另外也完善了相关文档,方便开发者使用、了解 CeresDB。
0.2.0 版本主要特性:
●实现了时序分析引擎,实现了表模型,支持常见 SQL 进行读写操作
●底层存储支持本地文件与阿里云 OSS
●WAL 支持基于本地 RockDB 与 OBKV
●部署方案支持单机与基于配置文件的分布式部署
●支持 MySQL 通信协议
7.加入CeresDB 社区
你是否正在规划或者实施时序数据存储和分析的相关项目?你是否正在头疼现有时序存储面临海量时间线的调优问题?
非常欢迎你参与 CeresDB 开源社区,我们期待你的参与:
项目 Github 主仓库:
https://github.com/CeresDB/ceresdb
详细的里程碑可以参看:https://github.com/CeresDB/ceresdb/blob/main/docs/dev/roadmap.md


本文分享自微信公众号 - 支付宝技术(Ant-Techfin)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
边栏推荐
猜你喜欢

Dragoma (DMA) Metaverse System Development
华为企业组网实例:VRRP+MSTP典型组网配置

正则表达式未完

Jmeter - Heap配置原因报错Invalid initial heap size: -Xms1024m -Xmx2048mError
JS手写JSON.stringify() (面试)
SIGIR 2022 | 邻域建模Graph-Masked Transformer,显著提高CTR预测性能
红外图像滤波

正畸MIA微种植体支抗技术中国10周年交流会在沈举办
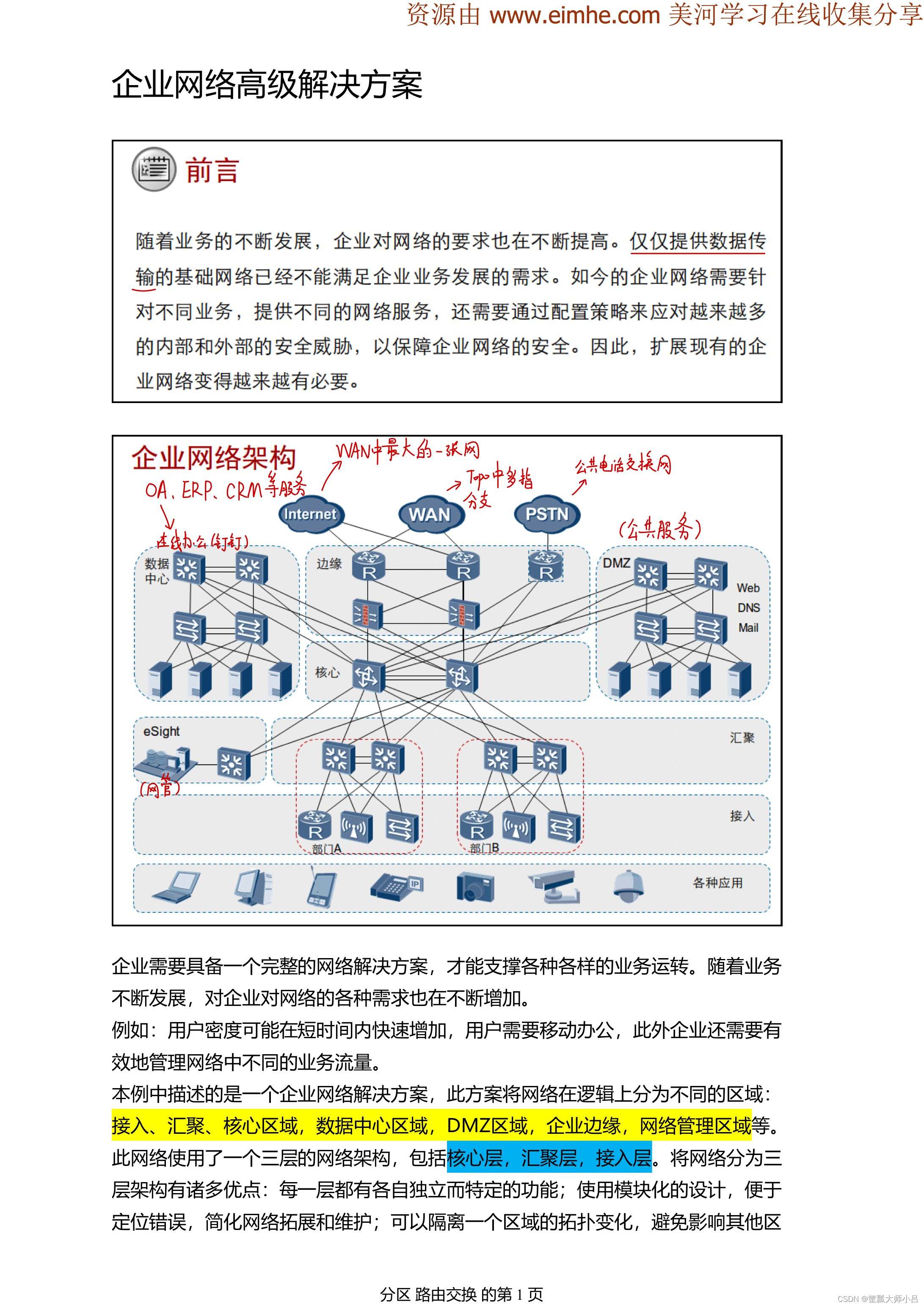
HCIP-R&S By Wakin自用笔记(1)企业网络高级解决方案
Go学习笔记(篇一)配置Go开发环境
随机推荐
企业应当实施的5个云安全管理策略
Notepad++更改显示背景
[Latest Information] 2 new regions will announce the registration time for the soft exam in the second half of 2022
win10 uwp MVVM 语义耦合
如何理解 SAP UI5 的 sap.ui.define 函数
zynq 记录
ERC20转账压缩
高效目标检测:动态候选较大程度提升检测精度(附论文下载)
查询APP Store已发布过的版本记录
对比几类主流的跨端技术方案
Those things about the curl command
win10 uwp ping
入门:人脸专集1 | 级联卷积神经网络用于人脸检测(文末福利)
Infrared image filtering
猜数字游戏
Go学习笔记(篇一)配置Go开发环境
迪赛智慧数——其他图表(主题河流图):近年居民消费、储蓄、投资意愿
JS 问号?妙用
如何让远在的老板看到你!----------来自财富中国网
lc marathon 8.3