当前位置:网站首页>Neon Optimization: performance optimization FAQ QA
Neon Optimization: performance optimization FAQ QA
2022-07-07 01:14:00 【To know】
NEON Optimize : Performance optimization FAQs QA
NEON Optimization series :
- NEON Optimize 1: Software performance optimization 、 How to reduce power consumption ?link
- NEON Optimize 2:ARM Summary of optimized high frequency instructions , link
- NEON Optimize 3: Matrix transpose instruction optimization case ,link
- NEON Optimize 4:floor/ceil Optimization case of function ,link
- NEON Optimize 5:log10 Optimization case of function ,link
- NEON Optimize 6: About cross access and reverse cross access ,link
- NEON Optimize 7: Performance optimization experience summary ,link
- NEON Optimize 8: Performance optimization FAQs QA,link
This article will encounter everyday NEON The summary of optimization problems is recorded here .
CPU Main frequency Mhz And expenses MCPS What is your relationship ?
- Main frequency Mhz It does not directly represent the operation speed MCPS
- Main frequency :1.8GHz=1800MHz, That is, the theory is the largest 1800MCPS, The dominant frequency is the theoretical ceiling of overhead calculation
The relationship between power consumption and overhead ?
- Usually, the cost refers to the time complexity cost , How many? M Changes in expenses , How much mA Changes in power consumption , As it involves hardware optimization and specific device performance , Unable to calculate theoretically .
Soft imitation MIPS Number and hard imitation MIPS Number differences and MCPS?
- CPU It's not the same , Soft imitation is the most CPI by 1, That is, generally MCPS than MIPS Big . But the chip of the mobile phone is very good , Can do CPI<1.
armv7/armv8a,arm64-v7/arm64-v8a The difference between ?Cortex-A9/A8/A53/A55 The difference between ?
First ,armv7/v8 yes Architecture framework ,cortex It is concrete. processor processor , The architecture is updated every few years or even every ten years , Processors are refurbished every year .
secondly , Yes armv7-A/armv8-A/armv8-M Classify and delimit
The overall
- v7/v8 Indicates the generation
- -A/-M/-R Express Application/Microcontroller/Real-time, Suitable for mobile phones and computers 、 Embedded devices and other different platforms
- v8-a,2011 Released in ,armv8-a After a Follow cortex-a Is consistent
armv8-a framework
- Yes 32 Also have 64 position ,32 position processor:cortex-a32;64 position processor:cortex-a34/cortex-a53;
armv7-a framework
- Only 32 position , Corresponding processor:cortex-a5/a7/…/a17
See... For more details :wiki
What is? MCPS?
- MCPS, Millions of cycles per second , An indicator of time expenditure
- MIPS, Million instructions per second , Generally, one instruction corresponds to one or more calculation cycles , So usually MIPS Than MCPS The data is small
Vector lines and N What does element structure mean ?
- Number of vector lines , amount to 1 individual NEON How many corresponding basic data type values are there in the register (int16/uint32/float32 etc. ).
- n Element structure , amount to n individual NEON register .
NEON Some of the instructions add q, Some do not add q, What's the difference ?
- After the operator q, Such as vmulq, Express 128 Bit full width register operation
- v After q, Such as vqrdmulh,q Indicates saturation operation , After overflow , To automatically limit to the maximum range of data types .
- rdmul It represents the specific operational significance of double multiplication between vector and scalar .
- hq Indicates high saturation ,lq Indicates low saturation .
NEON Normal command in 、 Wide command 、 Narrow instructions 、 Saturation command 、 What do long instructions mean ?
- Normal command : Generate a result vector with the same size and type as the operand vector
- Long instruction : Performs an operation on a doubleword vector operand , Produce quadword vectors to the result . The generated element is usually twice the width of the operand element , And belong to the same type .L Mark , Such as VMOVL.
- Wide command : A doubleword vector operand and a quadword vector operand perform operations , Generate quadword vector results .W Mark , Such as VADDW.
- Narrow instructions : A quadword vector operand performs an operation , And generate double word vector results , The generated element is generally half the width of the operand element .N Mark , Such as VMOVN.
- Saturation command : When the data type exceeds the specified range, it will be automatically limited within the range .Q Mark , Such as VQSHRUN
NEON What is the naming rule of variables ?
There are no uniform rules , If you want to standardize , The following naming methods can be adopted .
Variable type Variable name :
vTNnVarexplain
- v, Represents vector operation
- T, Represents the type of variable , Use them separately s Represents a signed integer ,u Represents an unsigned integer ,f It means floating point
- N, Indicates the bit width occupied by variable elements , Such as s32,u16,f32 The number in is N, Represents element occupancy
- n, Represents the vector line element structure , Such as x4,x4x2
- Var, Indicates the name of the variable customization
give an example
Definition :int16x4x2_t vs16x4x2Tmp;
explain : Element is int16, save 4x2 Two dimensional vector of ( Be careful 2 Yes ,4 Is listed , Shell from back to front ), namely val[0]/val[1] Separate deposit 4 A vector line , A variable called tmp
detailed :
vs16x4x2Tmp Variable name v Express vector,s16 Express 16 Signed number of bits ,x4 Express 4 A vector line ,x2 Express 2 Elements ,Tmp Is the actual variable name .
The two elements are vs16x4x2Tmp.val[0] and vs16x4x2Tmp.val[1], Its type is int16x4,4 Four vector lines store four data respectively , And it is cross read from continuous memory and written to vs16x4x2Tmp Medium .
such as :
short tmp[8] = { 0 1 2 3 4 5 6 7}; vs16x4x2Tmp = vld2q_s16(tmp); // And what you get is vs16x4x2Tmp.val[0]: 0 2 4 6 vs16x4x2Tmp.val[1]: 1 3 5 7
Definition :float32x2_t vf32x2Tmp;
explain : Element is float32, Store a one-dimensional vector of two elements , A variable called tmp
NEON In variables .val[0]/.val[1] What does it mean ?
- Represents the vector line structure corresponding to the data type , Index the value corresponding to the register respectively .
When viewing disassembly code , How to judge whether there is an interlock in the code ?
- stay rvds in , Look at the disassembly code , Select an original C Code , It will automatically correspond to the corresponding disassembly code , If CPI The next column exists
Black spot, It means that there is an interlock between the codes .
边栏推荐
- Informatics Orsay Ibn YBT 1172: find the factorial of n within 10000 | 1.6 14: find the factorial of n within 10000
- Come on, don't spread it out. Fashion cloud secretly takes you to collect "cloud" wool, and then secretly builds a personal website to be the king of scrolls, hehe
- JTAG debugging experience of arm bare board debugging
- 系统休眠文件可以删除吗 系统休眠文件怎么删除
- from . cv2 import * ImportError: libGL. so. 1: cannot open shared object file: No such file or direc
- 再聊聊我常用的15个数据源网站
- Deeply explore the compilation and pile insertion technology (IV. ASM exploration)
- 重上吹麻滩——段芝堂创始人翟立冬游记
- NEON优化:关于交叉存取与反向交叉存取
- golang中的atomic,以及CAS操作
猜你喜欢
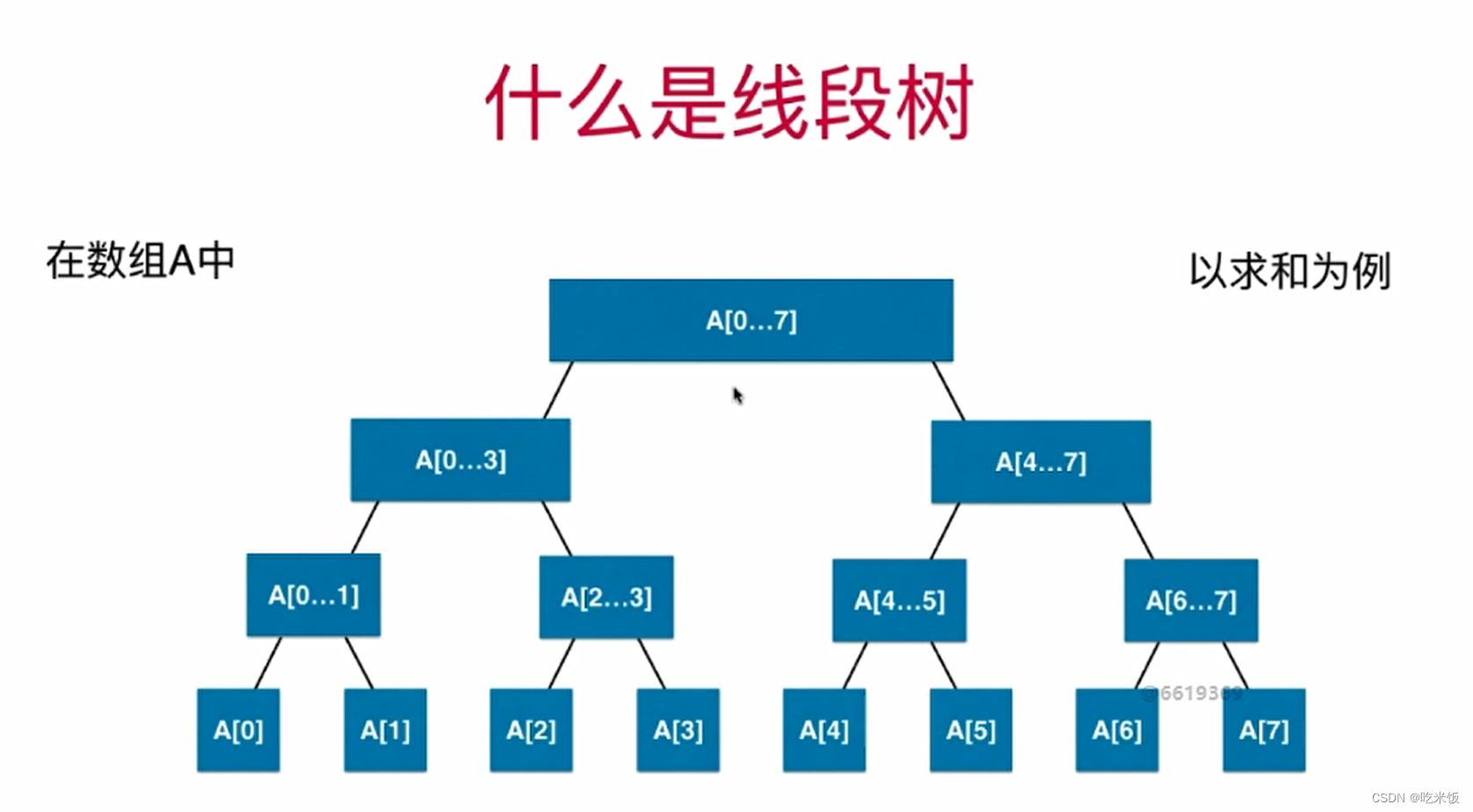
Segmenttree
Make a simple graphical interface with Tkinter
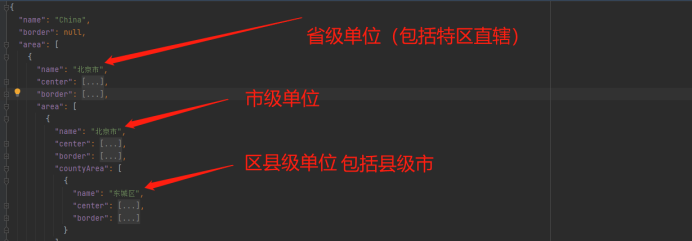
Provincial and urban level three coordinate boundary data CSV to JSON
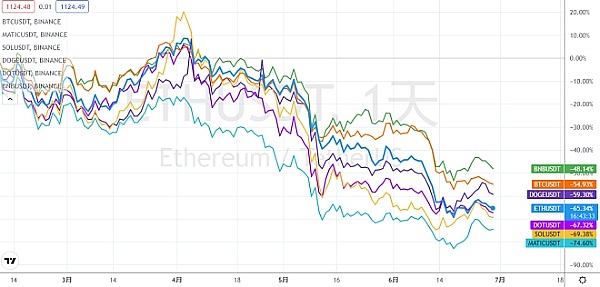
Asset security issues or constraints on the development of the encryption industry, risk control + compliance has become the key to breaking the platform
省市区三级坐标边界数据csv转JSON

The MySQL database in Alibaba cloud was attacked, and finally the data was found
Can the system hibernation file be deleted? How to delete the system hibernation file
深入探索编译插桩技术(四、ASM 探秘)
![[batch dos-cmd command - summary and summary] - jump, cycle, condition commands (goto, errorlevel, if, for [read, segment, extract string]), CMD command error summary, CMD error](/img/a5/41d4cbc070d421093323dc189a05cf.png)
[batch dos-cmd command - summary and summary] - jump, cycle, condition commands (goto, errorlevel, if, for [read, segment, extract string]), CMD command error summary, CMD error

力扣1037. 有效的回旋镖

随机推荐
pytorch之数据类型tensor
接收用户输入,身高BMI体重指数检测小业务入门案例
Lldp compatible CDP function configuration
Part 7: STM32 serial communication programming
随时随地查看远程试验数据与记录——IPEhub2与IPEmotion APP
Building a dream in the digital era, the Xi'an station of the city chain science and Technology Strategy Summit ended smoothly
taro3.*中使用 dva 入门级别的哦
Analysis of mutex principle in golang
批量获取中国所有行政区域经边界纬度坐标(到县区级别)
Rainstorm effect in levels - ue5
LLDP兼容CDP功能配置
NEON优化:关于交叉存取与反向交叉存取
Taro 小程序开启wxml代码压缩
The difference between spin and sleep
Meet in the middle
A brief history of deep learning (I)
Install Firefox browser on raspberry pie /arm device
第三方跳转网站 出现 405 Method Not Allowed
界面控件DevExpress WinForms皮肤编辑器的这个补丁,你了解了吗?
【案例分享】网络环路检测基本功能配置