当前位置:网站首页>【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
2022-07-02 06:26:00 【bryant_meng】

arXiv-2018
文章目录
1 Background and Motivation
CV 社区大部分聚焦于设计更好的网络结构,Less attention has been paid to finding better data augmentation methods that incorporate more invariances(teach a model about invariances in the data domain)
作者旨在 automate(Reinforcement Learning) the process of finding an effective data augmentation policy for a target dataset
2 Related Work
略
3 Advantages / Contributions
automate 数据增广,在多个分类数据集上取得了 SOTA,且 can generalize well across different models and datasets(数据分布还是要有一定的相关性的,此前提下增广策略能屏蔽模型,跨越数据集)
Despite the observed transferability, we find that policies learned on data distributions closest to the target yield the best performance

4 Method
强化学习(Proximal Policy Optimization algorithm)搜数据增广策略,
搜索空间为
https://pillow.readthedocs.io/en/stable/reference/ImageOps.html(PIL实现)
ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout, Sample Pairing
invert 按给定的概率值将部分或全部通道的像素值从 v 设置为 255-v
Equalize 直方图均衡化
Solarize 在指定的阈值范围内,反转所有的像素点(高于阈值,则255-v)。
from PIL import Image, ImageOps # creating a image1 object im1 = Image.open("1.jpg") im2 = ImageOps.solarize(im1, threshold = 130) im2.show()Posterize:保留 Image 各通道像素点数值的高 bits 位
from PIL import Image, ImageOps im1 = Image.open("1.jpg") im2 = ImageOps.posterize(im1, bits=2) im2.show()128-64-32-16-8-4-2-1
bits=1,图像各通道最大值为 128
bits=2,图像各通道最大值为 128+64 = 192依次类推 bits 1~8 对应的图像最大值 128-192-224-240-248-252-254-255

16 种 data augmentation 方法(不同概率 probability——11个 values uniform spacing,不同参数配置 magnitude——10个等级 uniform spacing),部分增广方法没有 magnitude,eg:invert
每个 sub-policies 两种数据增广方法(16 选 2)串行组合——each sub-policy consisting of two image operations to be applied in sequence
一共会搜索出 5 种 sub-policies,搜索空间大致为 ( ( 16 × 11 × 10 ) 2 ) 5 = ( 16 × 11 × 10 ) 10 = 2.9 × 1 0 32 ((16 \times 11 \times 10)^2)^5 = (16 \times 11 \times 10)^{10} = 2.9 \times 10^{32} ((16×11×10)2)5=(16×11×10)10=2.9×1032
增广形式
训练时,a sub-policie is randomly chosen(5选1) for each image in each mini-batch
奖励机制,child model(a neural network trained as part of the search process) 的 acc
5 Experiments
5.1 Datasets
- CIFAR-10,5W,reduced CIFAR-10(which consists of 4,000 randomly chosen examples, to save time for training child models during the augmentation search process)
- CIFAR-100
- SVHN,reduced SVHN dataset of 1,000 examples sampled randomly from the core training set.
- ImageNet,reduced ImageNet,with 120 classes (randomly chosen) and 6,000 samples
- Stanford Cars
- FGVC Aircraft
5.2 Experiments and Results
1)CIFAR-10 and CIFAR-100 Results
选出来比较多的增广方式为 Equalize, AutoContrast, Color, and Brightness,而 ShearX/Y 较少
下面看看结果
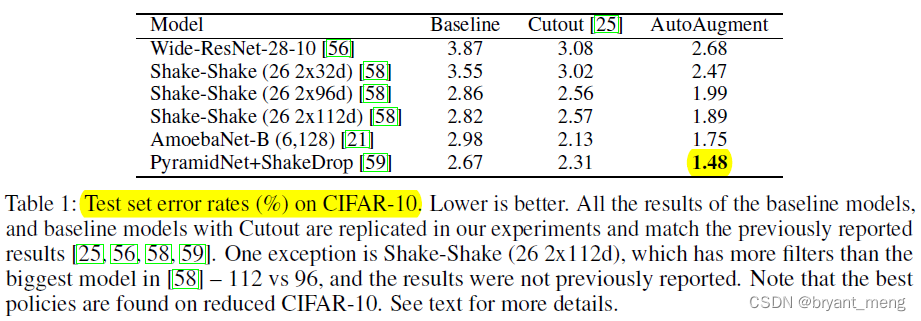
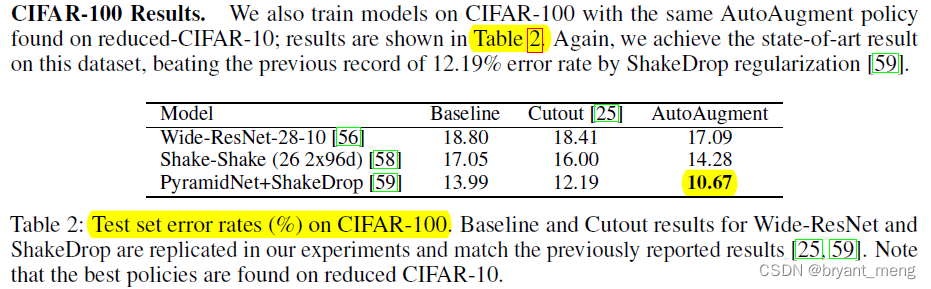
再看看和半监督方法对比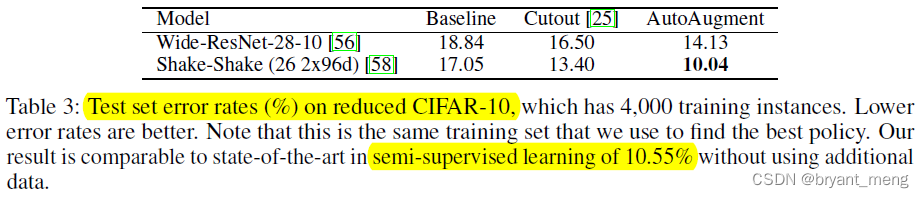
作者仅用了 4000 张 labeled samples,半监督方法 use an additional 46,000 unlabeled samples in their training
效果上作者的更好
2)SVHN Results
Invert, Equalize, ShearX/Y, and Rotate 被选出来的比较多
the specific color of numbers is not as important as the relative color of the number and its background.
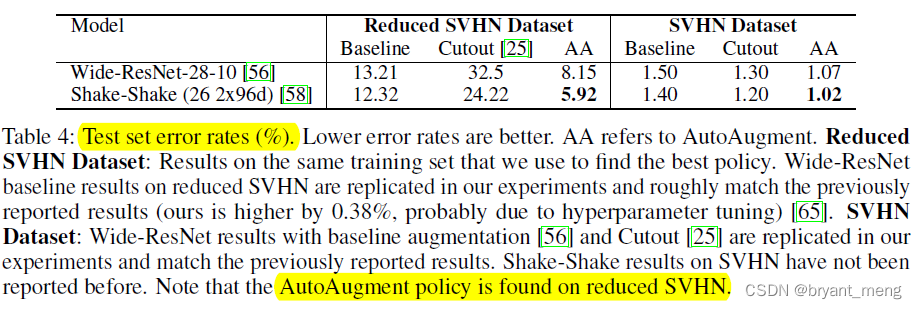
AutoAugment leads to more significant improvements on the reduced dataset than the full dataset(哈哈哈,数据本身才是王道,数据增广也是去增加数据的多样性)
3)ImageNet Results
focusing on color-based transformations + rotation

4)Fine Grained Visual Classification Datasets
用 table 4 的增广策略
增益效果明显,Stanford Cars 上还是 SOTA
5)Importance of Diversity in AutoAugment Policies

20 基本最好啦
6 Conclusion(own) / Future work
《Data Augmentation by Pairing Samples for Images Classification》(arXiv-2018)

We find that for a fixed amount of training time, it is more useful to allow child models to train for more epochs rather than train for fewer epochs with more training data.
代码 [CVPR2019]AutoAugment:一种基于NAS方法的数据增强策略


边栏推荐
- latex公式正体和斜体
- Yaml file of ingress controller 0.47.0
- Calculate the difference in days, months, and years between two dates in PHP
- PHP returns the abbreviation of the month according to the numerical month
- Open failed: enoent (no such file or directory) / (operation not permitted)
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
- Pratique et réflexion sur l'entrepôt de données hors ligne et le développement Bi
- 【信息检索导论】第七章搜索系统中的评分计算
- Two table Association of pyspark in idea2020 (field names are the same)
- ModuleNotFoundError: No module named ‘pytest‘
猜你喜欢
Using compose to realize visible scrollbar

The first quickapp demo
MySQL has no collation factor of order by
Cognitive science popularization of middle-aged people
软件开发模式之敏捷开发(scrum)
SSM second hand trading website
![[introduction to information retrieval] Chapter 6 term weight and vector space model](/img/42/bc54da40a878198118648291e2e762.png)
[introduction to information retrieval] Chapter 6 term weight and vector space model
中年人的认知科普
Installation and use of image data crawling tool Image Downloader

深度学习分类优化实战
随机推荐
【信息检索导论】第三章 容错式检索
win10+vs2017+denseflow编译
[torch] some ideas to solve the problem that the tensor parameters have gradients and the weight is not updated
基于pytorch的YOLOv5单张图片检测实现
parser.parse_args 布尔值类型将False解析为True
win10解决IE浏览器安装不上的问题
【调参Tricks】WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach
Oracle general ledger balance table GL for foreign currency bookkeeping_ Balance change (Part 1)
使用 Compose 实现可见 ScrollBar
【BERT,GPT+KG调研】Pretrain model融合knowledge的论文集锦
yolov3训练自己的数据集(MMDetection)
程序的内存模型
PointNet理解(PointNet实现第4步)
Jordan decomposition example of matrix
MySQL composite index with or without ID
【深度学习系列(八)】:Transoform原理及实战之原理篇
Get the uppercase initials of Chinese Pinyin in PHP
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'