当前位置:网站首页>Raki's notes on reading paper: code and named entity recognition in stackoverflow
Raki's notes on reading paper: code and named entity recognition in stackoverflow
2022-07-05 04:25:00 【Sleeping Raki】
Abstract & Introduction & Related Work
Research tasks
Identification code token Software related entitiesFacing the challenge
- These named entities are often vague , And there are implicit dependencies on the attached code fragments
Innovative ideas
- We propose a named entity recognizer (NER), It uses multi-level attention network to combine text context with code fragment knowledge
The experimental conclusion
SoftNER Than BiLSTM-CRF High 9.73 Of F1 fraction
Annotated StackOverflow Corpus
For every question , The four answers are marked , Including accepted answers 、 The most voted answer , And two randomly selected answers ( If it exists )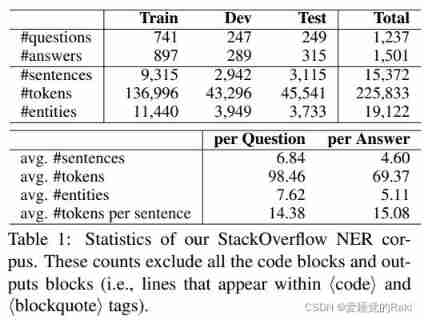
Annotation Schema
Define twenty fine-grained entities 
StackOverflow/GitHub Tokenization
Put forward a method called SOTOKENIZER New word breaker , It is specially customized for the community in the field of computer programming , We found that , Tokenization is not simple , Because many code related tags are incorrectly segmented by existing web text markers 
Named Entity Recognition
Model overview
- embedding Extraction layer
- Multi level attention level
- BiLSTM-CRF
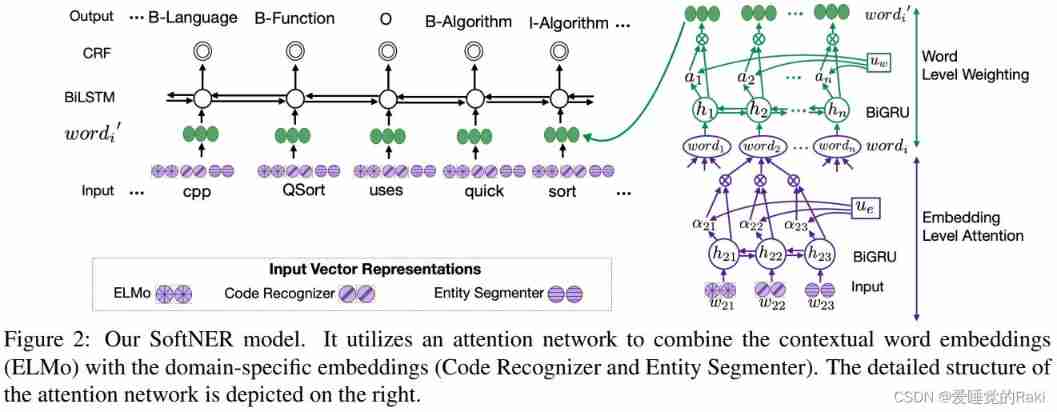
Input Embeddings
extract ELMo representation And two specific areas embedding
Code Recognizer, Indicates whether a word can be part of a code entity , Regardless of the context
Entity Segmenter, Predict whether a word is part of any named entity in a given sentence
In-domain Word Embeddings
Text in the field of software engineering contains programming language tags , Such as variable name or code segment , And interspersed with natural language vocabulary . This makes the input representation of pre training on general news network text unsuitable for the software field . therefore , We are StackOverflow Of 10 Pre training has been carried out for embedding words in different domains in the archives , Include ELMo、BERT and GloVe Vectorial 23 Billion marks
Context-independent Code Recognition
The input features include two language models (LMs) Of unigram word and 6-gram char probability , These two language models are in Gigaword Corpus and StackOverflow 10 All code fragments in the year file were trained separately
We also pre trained with these code snippets FastText(Joulin wait forsomeone ,2016) Words embedded in , One of the word vectors is represented by its character n-grams The sum of . We first use Gauss grading (Maddela and Xu,2018) Each one n-gram Probability turns into a k Dimension vector , This has been shown to improve the performance of neural models using digital features (Sil wait forsomeone ,2017;Liu wait forsomeone ,2016;Maddela and Xu,2018). then , We send vector features into the linear layer , Compare the output to FastText Character level embedded connection , And through another with sigmoid Active hidden layer . If the output probability is greater than 0.5, We predict that the tag is a code entity
Entity Segmentation
take ELMo embedding, And two manual features ,word frequency and code markdown concat Get up as input , Throw it BiLSTM-CRF Judge one in the model token Whether it is an entity mention
Word Frequency
Represents the number of words in the training set . Because of a lot of code token It is defined by individual users , Their frequency of occurrence is much lower than that of normal English words . in fact , In our corpus , Code and non code token The average frequencies of are 1.47 and 7.41. Besides , The average frequency of fuzzy markers that can be both code and non code entities is much higher , by 92.57. To take advantage of this observation , We take word frequency as a feature , The scalar value is converted into a k Dimension vector
Code Markdown
Represents a given token Whether it appears in Stack Overflow Of <code> Inside the label It is worth noting that , One <code> The label is noisy , Because users are not always hcodei The tag contains inline code , Or use this tag to highlight non code text . However , We found that we would markdown It is helpful to include information as a feature , Because it improves the performance of our segmentation model
Multi-Level Attention
For each of these word, Use ELMo embedding, Code Recognizer, Entity Segmenter As raw input , Throw it BiGRU Inside , Get the corresponding representation , Then through a linear layer , Connect tanh Activation function , The introduction of a embedding Level context vector , u e u_e ue, Learn during training , And then through a softmax Function to get the corresponding score a i t a_{it} ait
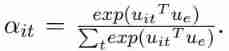
Finally, every one word Of embedding yes 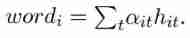
word level embedding Follow embedding level attention equally , A trainable vector is also introduced u w u_w uw
Finally get w o r d i = a i h i word_i = a_ih_i wordi=aihi, Then throw it to BiLSTM-CRF Make predictions in the layer 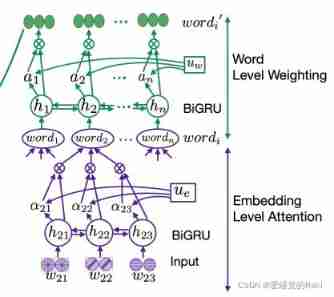
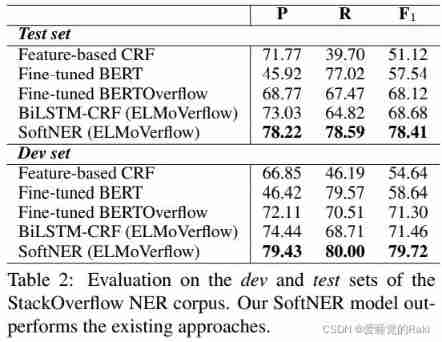
Evaluation

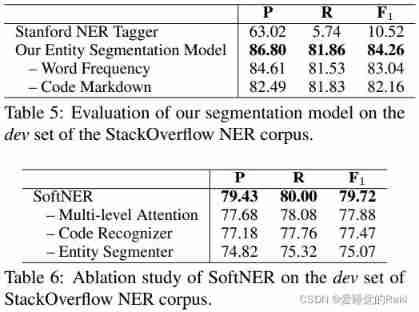


Conclusion
We developed a new NER corpus , Including from StackOverflow Of 15,372 Sentences and from GitHub Of 6,510 A sentence , And note 20 A fine-grained named entity
We prove that this new corpus is an ideal benchmark data set for contextual word representation , Because there are many challenging ambiguities , It often needs a long-distance context to solve . We propose a new attention based model , be known as SoftNER, Its performance on this data set exceeds that of the most advanced NER Model
Besides , We studied the important subtask of code recognition . Our new code recognition model is based on character ELMo Additional spelling information is captured in addition , And continuously improve NER The performance of the model . We believe that our corpus is based on StackOverflow Named entity markers will be useful for various language and code tasks , Such as code retrieval 、 Software knowledge base extraction and automatic question answering
Remark
I think the main contribution is to build a new data set , The model is regular , Doing a good job in data sets can also lead to a summit !
边栏推荐
- Web开发人员应该养成的10个编程习惯
- Use threejs to create geometry, dynamically add geometry, delete geometry, and add coordinate axes
- How to get the first few pieces of data of each group gracefully
- After the deployment of web resources, the navigator cannot obtain the solution of mediadevices instance (navigator.mediadevices is undefined)
- 首席信息官如何利用业务分析构建业务价值?
- 函數(易錯)
- You Li takes you to talk about C language 7 (define constants and macros)
- Scheduling system of kubernetes cluster
- Learning MVVM notes (1)
- 假设检验——《概率论与数理统计》第八章学习笔记
猜你喜欢

A solution to the problem that variables cannot change dynamically when debugging in keil5
Interview related high-frequency algorithm test site 3
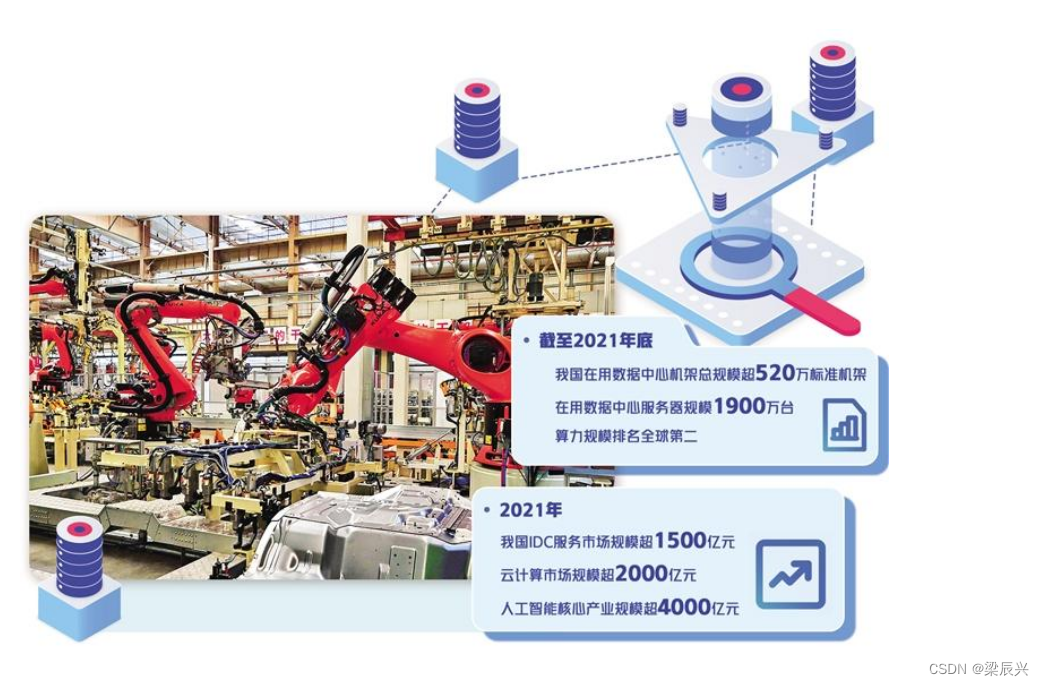
The scale of computing power in China ranks second in the world: computing is leaping forward in Intelligent Computing

Ctfshow web entry code audit
![[phantom engine UE] only six steps are needed to realize the deployment of ue5 pixel stream and avoid detours! (the principles of 4.26 and 4.27 are similar)](/img/eb/a93630aff7545c6c3b71dcc9f5aa61.png)
[phantom engine UE] only six steps are needed to realize the deployment of ue5 pixel stream and avoid detours! (the principles of 4.26 and 4.27 are similar)
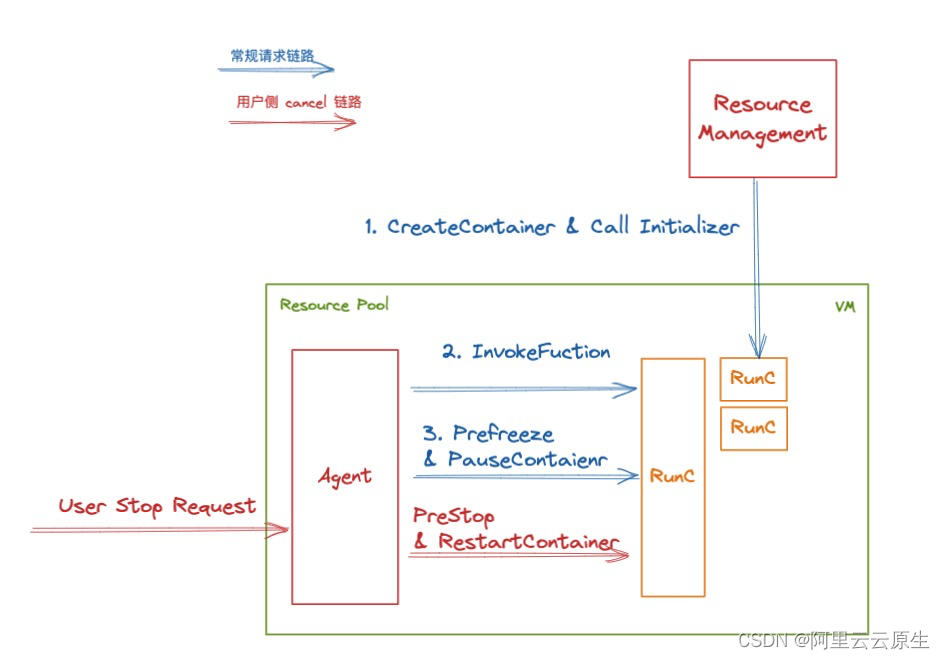
解密函数计算异步任务能力之「任务的状态及生命周期管理」
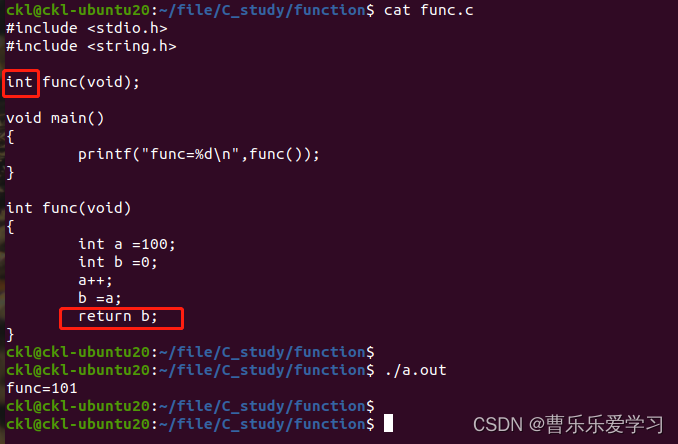
Pointer function (basic)
【虚幻引擎UE】打包报错出现!FindPin错误的解决办法

The development of mobile IM based on TCP still needs to keep the heartbeat alive
【虛幻引擎UE】實現UE5像素流部署僅需六步操作少走彎路!(4.26和4.27原理類似)
随机推荐
A application wakes up B should be a fast method
Ffmepg usage guide
首席信息官如何利用业务分析构建业务价值?
Open graph protocol
Key review route of probability theory and mathematical statistics examination
Decimal to hexadecimal
[moteur illusoire UE] il ne faut que six étapes pour réaliser le déploiement du flux de pixels ue5 et éviter les détours! (4.26 et 4.27 principes similaires)
Pointer function (basic)
Un réveil de l'application B devrait être rapide
[Chongqing Guangdong education] 2408t Chinese contemporary literature reference test in autumn 2018 of the National Open University
Power management bus (pmbus)
机器学习 --- 决策树
All in one 1413: determine base
根据入栈顺序判断出栈顺序是否合理
Ctfshow web entry code audit
Cookie learning diary 1
American 5g open ran suffered another major setback, and its attempt to counter China's 5g technology has failed
Threejs clicks the scene object to obtain object information, and threejs uses raycaster to pick up object information
Uni app change the default component style
Threejs realizes rain, snow, overcast, sunny, flame