当前位置:网站首页>Distributed ID
Distributed ID
2022-07-06 20:37:00 【mb61037a3723f67】
Catalog
- Scheme 1 :UUID: Universal unique identification code :
- Option two : Database primary key auto increment :
- Option three :Redis:
- Option four : Snowflake algorithm :
- 4.1: understand 64 The bit :
- 4.2: Clock back problem :
- 4.3: Shift operation of snowflake Algorithm :
- 4.4: Snowflake algorithm python edition :
Scheme 1 :UUID: Universal unique identification code :
- 1: UUID Include : network card MAC Address 、 Time stamp 、 Namespace (Namespace)、 Random or pseudorandom number 、 Time series and other elements .
- 2:UUID By 128 Bit binary composition , It's usually converted to hexadecimal , And then use String Express .
- 3: UUID The advantages of ::3.1: Generate... Locally , Not through the Internet I/O, Faster performance .3.2: disorder , It's impossible to predict the order of his generation .
- 4: UUID The shortcomings of :4.1:128 Bit binary is usually converted to 36 Bit 16 Base number , It's too long to use String Storage , More space . 4.2: Can't generate numbers that are increasing in order .
Option two : Database primary key auto increment :
- 1: The most easy thing for you to think about the unique ID is the self increasing primary key , This is also our most common method . For example, we have an order service , Then order id Set as the primary key auto increment .
- 2: A single database stores ,id The primary key can be increased automatically .
- 3: If the data is stored in different databases , Suppose there is 3 platform , Then set the initial values as 1 2 3 The steps are 3 Incrementing .
- 4: advantage : Easy and convenient , Orderly increase , Easy sorting and paging .
- 5: shortcoming :
- 5.1: Sub database and sub table will bring problems , Need to be transformed .
- 5.2: Concurrency performance is not high , Limited by the performance of the database .
- 5.3: Simple increase is easy to be used by others , For example, you have an incremental user service , Then others can analyze - 5.4: Registered users ID How many people are registered to get your service on that day , So we can guess the current situation of your service .
- 5.5: Database down service not available .
Option three :Redis:
- 1:Redis There are two orders in Incr,IncrBy, because Redis It's single threaded so it guarantees atomicity .
- 2: advantage : Better performance than database , Can satisfy the orderly increase .
- 3: shortcoming 1: because redis It's memory KV database , Even if there is AOF and RDB, But there will still be data loss , It could cause ID repeat .
- 4: shortcoming 2: Depend on redis,redis If it's not stable , It will affect ID Generate .
Option four : Snowflake algorithm :
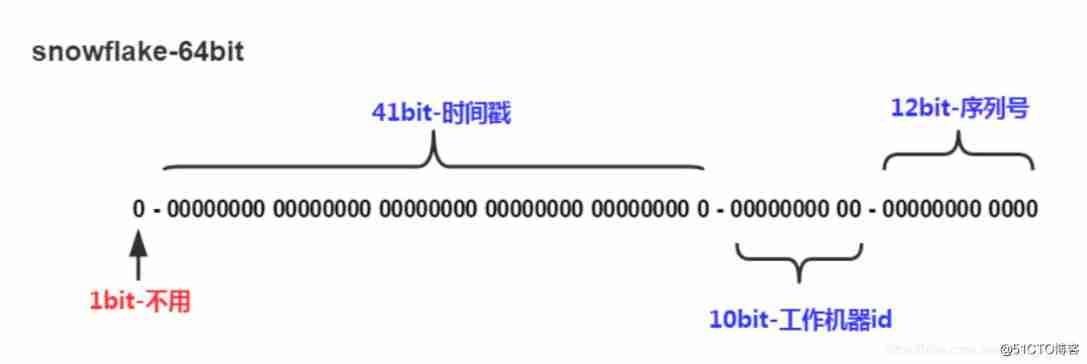
4.1: understand 64 The bit :
- 1bit: Sign bit
- 41bit: Time stamp : Here you can record 69 year .
- 10bit:10bit Used to record machines ID, It can be recorded in total 1024 Taiwan machine , Before use 5 Bit for Data Center , Back 5 Bit is a machine in a data center ID
- 12bit: Cyclic position , It is used to generate different ID,12 Bits can record at most 4095 individual , That is to say, in the same machine, the maximum number of records in the same millisecond 4095 individual , Extra need to wait for next milliseconds .
4.2: Clock back problem :
Time callback will occur because of the machine , Our snowflake algorithm is strongly dependent on our time , If time calls back , It's possible to generate duplicate ID, On top of us nextId We use the current time and the last time to judge , If the current time is less than the last time, there must be a callback , The algorithm will throw an exception directly .
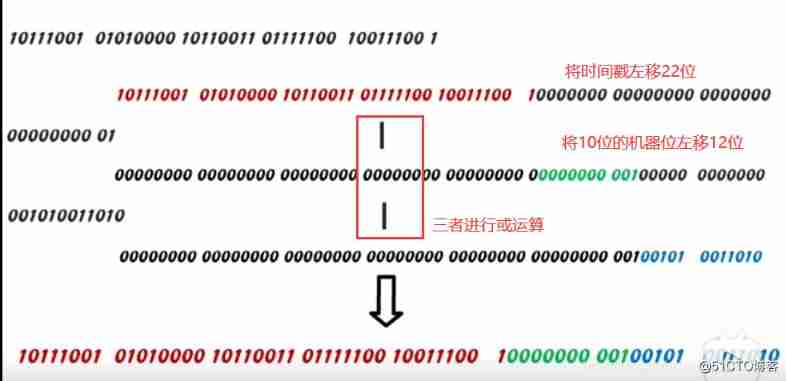
4.3: Shift operation of snowflake Algorithm :
4.4: Snowflake algorithm python edition :
import time
import logging
class InvalidSystemClock(Exception):
"""
Clock callback is abnormal
"""
pass
# 64 position ID Division
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
# Maximum value calculation
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# Shift offset calculation
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# Sequence number loop mask
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter First year time stamp
TWEPOCH = 1288834974657
logger = logging.getLogger('flask.app')
class IdWorker(object):
"""
Used to generate IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
initialization
:param datacenter_id: Data Center ( Machine area )ID
:param worker_id: machine ID
:param sequence: In fact, the serial number
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id It's worth crossing ')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id It's worth crossing ')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # Last calculated timestamp
def _gen_timestamp(self):
"""
Generate integer timestamps
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
Get new ID
:return:
"""
timestamp = self._gen_timestamp()
# Clock back
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests until {}'.format(self.last_timestamp))
raise InvalidSystemClock
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
Wait until the next millisecond
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
边栏推荐
- Design your security architecture OKR
- Logic is a good thing
- Application layer of tcp/ip protocol cluster
- JS get browser system language
- [network planning] Chapter 3 data link layer (3) channel division medium access control
- 8086指令码汇总表(表格)
- Problems encountered in using RT thread component fish
- Appx code signing Guide
- The mail command is used in combination with the pipeline command statement
- C language operators
猜你喜欢

Digital triangle model acwing 1018 Minimum toll

OLED屏幕的使用
【DSP】【第二篇】了解C6678和创建工程

Notes on beagleboneblack
小孩子學什麼編程?
Continuous test (CT) practical experience sharing
Detailed introduction of distributed pressure measurement system VIII: basic introduction of akka actor model
![[weekly pit] calculate the sum of primes within 100 + [answer] output triangle](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[weekly pit] calculate the sum of primes within 100 + [answer] output triangle

Why do novices often fail to answer questions in the programming community, and even get ridiculed?
Ideas and methods of system and application monitoring
随机推荐
动态切换数据源
BeagleBoneBlack 上手记
[cloud lesson] EI lesson 47 Mrs offline data analysis - processing OBS data through Flink
"Penalty kick" games
JS get browser system language
[weekly pit] calculate the sum of primes within 100 + [answer] output triangle
Continuous test (CT) practical experience sharing
Catch ball game 1
SSO single sign on
Discussion on beegfs high availability mode
Groovy basic syntax collation
Special topic of rotor position estimation of permanent magnet synchronous motor -- fundamental wave model and rotor position angle
PowerPivot - DAX (first time)
强化学习-学习笔记5 | AlphaGo
报错分析~csdn反弹shell报错
[DSP] [Part 1] start DSP learning
[DIY]如何制作一款个性的收音机
Recyclerview GridLayout bisects the middle blank area
Event center parameter transfer, peer component value transfer method, brother component value transfer
Is it difficult for small and micro enterprises to make accounts? Smart accounting gadget quick to use