当前位置:网站首页>Redis bloom filter
Redis bloom filter
2022-07-02 12:37:00 【Squat in the corner and count the ants】
What is a bloon filter
In essence, the bloom filter is a data structure , A more ingenious probabilistic data structure (probabilistic data structure), Features efficient insertion and query , It can be used to tell you “ Something must not exist or may exist ”.
Compared to traditional List、Set、Map And so on , It's more efficient 、 Take up less space , But the disadvantage is that the returned result is probabilistic , Not exactly .
Realization principle
HashMap The problem of
Before we talk about the principle of Bloom filter , Let's think about , Usually you judge whether an element exists by what ? Many people should answer HashMap Well , You can actually map values to HashMap Of Key, Then you can go to O(1) Return results within the time complexity of , Extremely efficient . however HashMap The implementation also has disadvantages , For example, the proportion of storage capacity is high , Considering the existence of load factor , Usually space cannot be used up , And once you are worth a lot, such as hundreds of millions , that HashMap The amount of memory occupied becomes considerable .
For example, your data set is stored on a remote server , Local services accept input , The data set is too large to be read into memory at one time HashMap When , There will be problems .
Data structure of Bloom filter
The bloom filter is a bit Vector or bit Array , Long like this :

If we want to map a value to a bloom filter , We need to use Multiple different hash functions Generate Multiple hash values , And for each generated hash value that points to bit Location 1, For example, for values “baidu” And three different hash functions generate hash values 1、4、7, Then the figure above changes to :

Ok, Let's save another value now “tencent”, If the hash function returns 3、4、8 Words , Figure goes on to :

It is worth noting that ,4 This bit Bit because the hash function for both values returns this bit position , So it's covered . Now if we want to check “dianping” Does this value exist , Hash function returned 1、5、8 Three values , As a result, we found that 5 This bit The value on bit is 0, It means that no value is mapped to this bit On a , So we can say for sure “dianping” This value does not exist . And when we need to query “baidu” If this value exists , The hash function must return 1、4、7, And then we checked and found these three bit All values on the bit are 1, So we can say “baidu” Does it exist ? The answer is no , Can only be “baidu” This value may exist .
Why is that ? Answer and simplicity , Because as the value increases, more and more , Be set to 1 Of bit More and more , Such a value “taobao” Even if it's not stored , But in case the hash function returns three bit Bits are set by other values 1 , Then the program will still judge “taobao” This value exists .
Do you support deletion
Thanks for the reminder in the comment area , Traditional Bloom filters don't support delete operations . But it's called Counting Bloom filter Can be used to test whether the number of element counts is absolutely less than a certain threshold , It supports element deletion . You can refer to the article Counting Bloom Filter Principle and implementation of
How to choose the number of hash functions and the length of Bloom filter
Obviously , Too small a bloon filter will soon all bit All positions are 1, Then any value queried will return “ Possible ”, Can't afford to filter . The length of the bloom filter directly affects the false alarm rate , The longer the bloom filter, the lower the false alarm rate .
in addition , The number of hash functions also needs to be weighed , The more the number, the more the bloom filter bit Position position 1 The faster , And the lower the efficiency of the bloom filter ; But if it's too little , Then our false alarm rate will be higher .

k Is the number of hash functions ,m Is the length of the bloom filter ,n Number of elements inserted for ,p Is the false positive rate
How to choose the right one for your business k and m Is it worth it , Here's a formula :

How to deduce this formula is just a sentence , Because it doesn't make much sense for use , If you ask a high school student to push, you will push quickly .k One time hash function bit Bit is not set to 1 The probability of is :
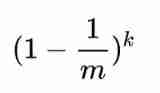
Insert n After three elements, it is still 0 The sum of the probabilities of is 1 The probabilities are :
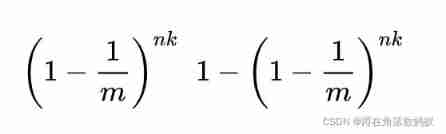
Indicates whether an element is required in the collection k Both positions are set to... As described above 1, However, this method may make the algorithm mistakenly think that an element that is not originally in the set is detected as in the set (False Positives), The probability is determined by the following formula
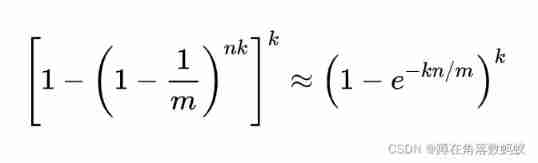
Best practices
Common applications are , Use a bloom filter to reduce disks IO Or network request , Because once a value must not exist , We don't have to make subsequent expensive query requests .
in addition , Since you use the bloom filter to speed up the search and determine whether it exists , Then a hash function with low performance is not a good choice , recommend MurmurHash、Fnv these .
Big Value Split
Redis Because of its support setbit and getbit operation , And high pure memory performance , Therefore, natural can be used as Bloom filter . However, the improper use of Bloom filter is very easy to produce large Value, increase Redis Blocking risk , Therefore, it is recommended to split the bulky bloom filter in the generation environment .
There are many forms and methods of splitting , But the essence is not to Hash(Key) The subsequent requests are scattered in multiple small nodes of multiple nodes bitmap On , Instead, it should be split into multiple small bitmap after , To a Key All hash functions fall into this small bitmap On .
边栏推荐
- Anti shake throttle
- SparkContext: Error initializing SparkContext解决方法
- Adding database driver to sqoop of cdh6
- Sweetheart leader: Wang Xinling
- Introduction to CPU instruction set
- Deep understanding of P-R curve, ROC and AUC
- MySQL与PostgreSQL抓取慢sql的方法
- Lekao: 22 year first-class fire engineer "technical practice" knowledge points
- Win10 system OmniPeek wireless packet capturing network card driver failed to install due to digital signature problem solution
- Post request body content cannot be retrieved repeatedly
猜你喜欢
spfa AcWing 851. spfa求最短路
中国交通标志检测数据集
Programmers can't find jobs after the age of 35? After reading this article, you may be able to find the answer
PR 2021 quick start tutorial, learn about the and functions of the timeline panel
Writing method of then part in drools
堆(優先級隊列)

JSON序列化 与 解析

趣味 面试题

Docker-compose配置Mysql,Redis,MongoDB

甜心教主:王心凌
随机推荐
Go学习笔记—多线程
[ybtoj advanced training guidance] judgment overflow [error]
MySQL与PostgreSQL抓取慢sql的方法
drools执行String规则或执行某个规则文件
Discrimination of the interval of dichotomy question brushing record (Luogu question sheet)
寻找二叉树中任意两个数的公共祖先
What data types does redis have and their application scenarios
Embedded Software Engineer career planning
线性DP AcWing 898. 数字三角形
China traffic sign detection data set
drools执行完某个规则后终止别的规则执行
The blink code based on Arduino and esp8266 runs successfully (including error analysis)
Docker-compose配置Mysql,Redis,MongoDB
Bom Dom
String palindrome hash template question o (1) judge whether the string is palindrome
单指令多数据SIMD的SSE/AVX指令集和API
Openssh remote enumeration username vulnerability (cve-2018-15473)
OpenCV中cv2.VideoWriter_fourcc()函数和cv2.VideoWriter()函数的结合使用
Enhance network security of kubernetes with cilium
Deep copy event bus