当前位置:网站首页>Comprendre la méthode de détection des valeurs aberrantes des données
Comprendre la méthode de détection des valeurs aberrantes des données
2022-07-04 07:58:00 【Analyse des données - zhongzhi】
La méthode de détection des valeurs aberrantes est une étape importante du processus d'analyse des données,C'est aussi l'une des compétences essentielles des analystes de données.Voici une brève introduction aux méthodes de détection liées à l'analyse des données,S'il y a des lacunes, veuillez les critiquer et les corriger.
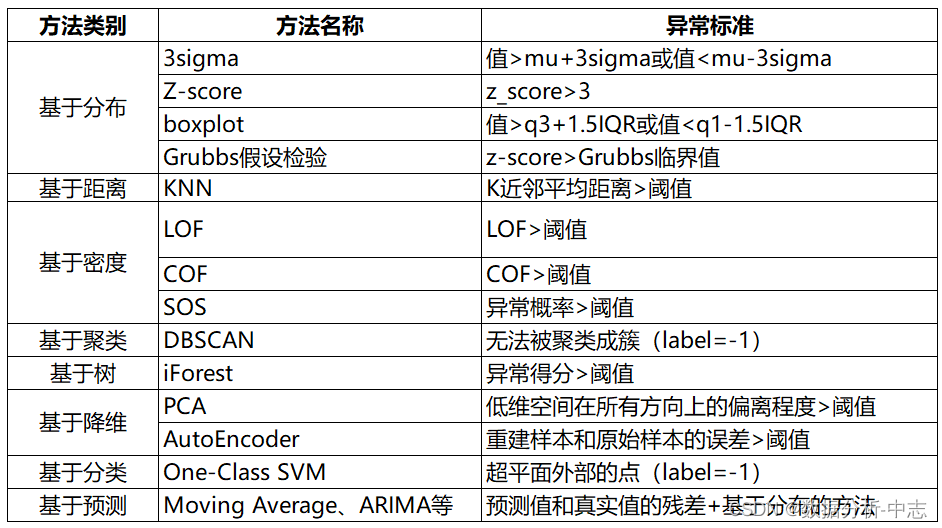
Un.、Méthode de détection des valeurs aberrantes basée sur la distribution
1. 3sigma
Basé sur une distribution normale,3sigmaSelon le Code, plus de3sigmaLes données pour sont des points d'exception.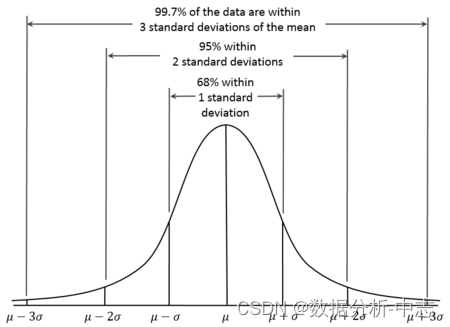
pythonMise en oeuvre du programme:
def three_sigma(s):
mu, std = np.mean(s), np.std(s)
lower, upper = mu-3*std, mu+3*std
return lower, upper
2.Z-score
Z-scoreEst la note standard,Mesurer la distance entre le point de données et la moyenne,SiADifférence par rapport à la moyenne2Écart type,Z-scorePour2.Quand?Z-score=3Lors de l'élimination des points d'exception comme seuil,C'est l'équivalent de3sigma.
def z_score(s):
z_score = (s - np.mean(s)) / np.std(s)
return z_score
3. boxplot
Le diagramme de la boîte est basé sur l'espacement des quartiles (IQR) Pour trouver un point d'exception .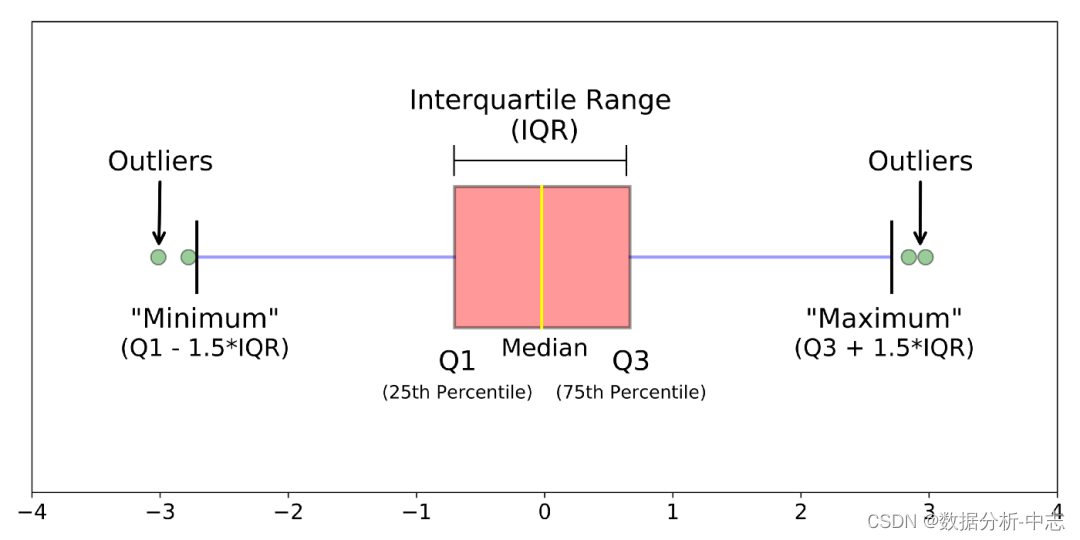
def boxplot(s):
q1, q3 = s.quantile(.25), s.quantile(.75)
iqr = q3 - q1
lower, upper = q1 - 1.5*iqr, q3 + 1.5*iqr
return lower, upper
4.GrubbsTest d'hypothèse
Grubbs’Test Une méthode de vérification des hypothèses , Est souvent utilisé pour tester des ensembles de données univariables qui suivent une distribution normale (univariate data set)Y Valeurs aberrantes individuelles dans . S'il y a des valeurs aberrantes , Doit être le maximum ou le minimum de l'ensemble de données . Les hypothèses initiales et alternatives sont les suivantes: :
● H0: Il n'y a pas d'exception dans l'ensemble de données
● H1: Il y a une exception dans l'ensemble de données
UtiliserGrubbs L'essai exige une distribution normale de la population .Processus algorithmique:
1, Les échantillons sont triés de petit à grand
2, Pour l'échantillon meanEtdev
3, Calculmin/maxAvecmeanÉcarts, La plus grande est la valeur suspecte
4, Pour trouver la valeur suspecte z-score (standard score),Si plus deGrubbsSeuil,Alors c'estoutlier
Grubbs La valeur critique peut être trouvée dans le tableau , Il est déterminé par deux valeurs : Niveau de détection α( Plus c'est strict, moins c'est ),Nombre d'échantillonsn,Exclusionoutlier, Pour les cycles de séquence restants 1-4 Étapes [1]. Un exemple de calcul détaillé peut être référencé à .
from outliers import smirnov_grubbs as grubbs
print(grubbs.test([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.min_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_outliers([8, 9, 10, 1, 9], alpha=0.05))
print(grubbs.max_test_indices([8, 9, 10, 50, 9], alpha=0.05))
Limites:
1、 Seules les données unidimensionnelles peuvent être détectées
2、 Plage normale de sortie non précise
3、 Son mécanisme de jugement est “ Retirer un par un ”, Donc chaque valeur d'exception calcule l'ensemble de l'étape individuellement , Les données sont trop volumineuses pour être consommées .
4、 On suppose que les données suivent une distribution normale ou quasi normale.
2.、 Méthode de détection des valeurs aberrantes basée sur la distance
1、KNN
Calculer à tour de rôle chaque point d'échantillonnage le plus proche K Distance moyenne des échantillons , Distance calculée pour la réutilisation par rapport au seuil ,Si elle est supérieure au seuil, Est considéré comme un point anormal . L'avantage est qu'il n'est pas nécessaire de supposer la distribution des données , L'inconvénient est que seules les exceptions globales peuvent être trouvées , Impossible de trouver un point d'exception local .
from pyod.models.knn import KNN
# Initialisation du détecteurclf
clf = KNN( method='mean', n_neighbors=3, )
clf.fit(X_train)
# Retour à l'onglet classification sur les données de formation (0: Valeur normale, 1: Valeurs aberrantes)
y_train_pred = clf.labels_
# Renvoie une valeur anormale sur les données d'entraînement (Plus le score est élevé, plus il est anormal)
y_train_scores = clf.decision_scores_
Trois、Approche fondée sur la densité
1、 Local Outlier Factor (LOF)
LOFEst un algorithme classique basé sur la densité(Breuning et. al. 2000),En attribuant à chaque point de données un facteur d'aberration dépendant de la densité du voisinage LOF,Pour déterminer si le point de données est un point aberrant. L'avantage est qu'il est possible de quantifier le degré d'anomalie à chaque point de données. (outlierness).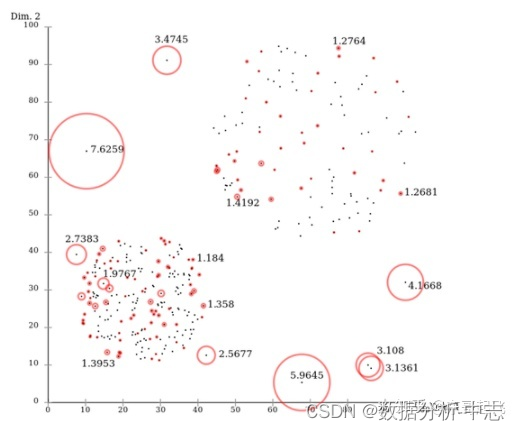
Point de donnéesPDensité relative locale de(Facteur d'anomalie locale)=PointP Densité locale moyenne réalisable des points dans le voisinage Suivez - moi. Point de donnéesP Densité locale réalisable de Rapport de: Point de donnéesP Densité locale réalisable de =P Inverse de la distance moyenne accessible du voisin le plus proche .Plus la distance est grande,Plus la densité est faible.
PointPAu pointODekDistance accessible=max(PointODekDistance du voisin le plus proche,PointPAu pointODistance de).
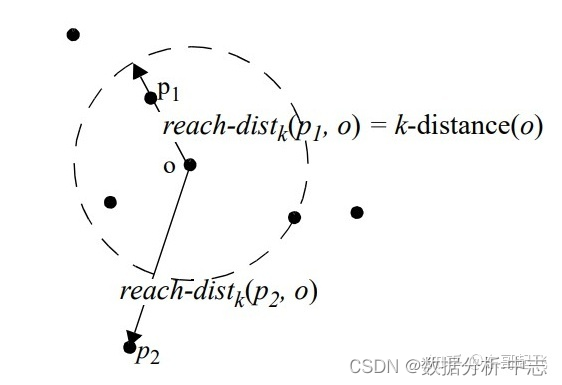
PointODekDistance du voisin le plus proche=No kLes points les plus prochesOLa distance entre.
Dans l'ensemble,LOFLe processus de l'algorithme est le suivant:
● Pour chaque point de données, Calcule sa distance de tous les autres points ,Et trier de près en loin;
● Pour chaque point de données,Je l'ai trouvé.K-Nearest-Neighbor,CalculLOFScore.
from sklearn.neighbors import LocalOutlierFactor as LOF
X = [[-1.1], [0.2], [100.1], [0.3]]
clf = LOF(n_neighbors=2)
res = clf.fit_predict(X)
print(res)
print(clf.negative_outlier_factor_)
2.Connectivity-Based Outlier Factor (COF)
COF- Oui.LOFUne variante de,Par rapport àLOF,COF Peut gérer des valeurs aberrantes à faible densité ,COF La densité locale est calculée à partir de la distance moyenne de la chaîne . Au début, on calcule chaque point. k-nearest neighbor. Et ensuite nous calculons chaque point Set based nearest Path,Comme le montre la figure ci - dessous::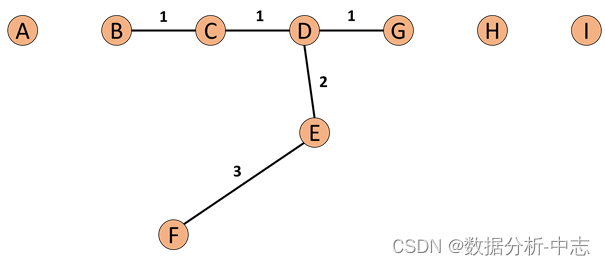
Si nous avions aujourd'hui notre k=5,Alors...FDeneighborPourB、C、D、E、G.Et pourF Le point le plus proche de lui est E,Alors...SBN PathLe premier élément deF、Le deuxième estE.Partez.E Le point le plus proche est D Donc le troisième élément est D, Et ensuite D Le point le plus proche est CEtG, Donc les quatrième et cinquième éléments sont CEtG, Et enfin C Le point le plus proche est B,Le sixième élément estB. Donc tout le processus descend ,FDeSBN PathPour{F, E, D, C, G, C, B}.Et pourSBN Path La distance correspondante e={e1, e2, e3,…,ek}, Selon l'exemple ci - dessus e={3,2,1,1,1}.
Donc nous pouvons dire que si nous voulons calculer pCommandéSBN Path, Il suffit de calculer directement p Point et neighbor Ce que tous les points font graphDeminimum spanning tree, Après ça, on prendra p Le point est le point de départ de l'exécution shortest pathAlgorithmes,Pour avoir notreSBN Path.
Et ensuite nous avons SBN Path On va continuer à calculer ,p Distance de chaîne du point : C'est bon.ac_distanceAprès,On peut calculerCOF:
from pyod.models.cof import COF
cof = COF(contamination = 0.06, ## Proportion de valeurs aberrantes
n_neighbors = 20, ## Nombre de voisins immédiats
)
cof_label = cof.fit_predict(iris.values) # Iris Data
print(" Le nombre de valeurs aberrantes détectées est :",np.sum(cof_label == 1))
3.Stochastic Outlier Selection (SOS)
Matrice caractéristique(feature martrix) Ou la matrice de différence de phase (dissimilarity matrix)Entrez dansSOSAlgorithmes, Renvoie un vecteur de valeur de probabilité anormal ( Chaque point correspond à un ).SOSL'idée est: Quand un point est associé à tous les autres points (affinity)Très jeune., C'est une anomalie .
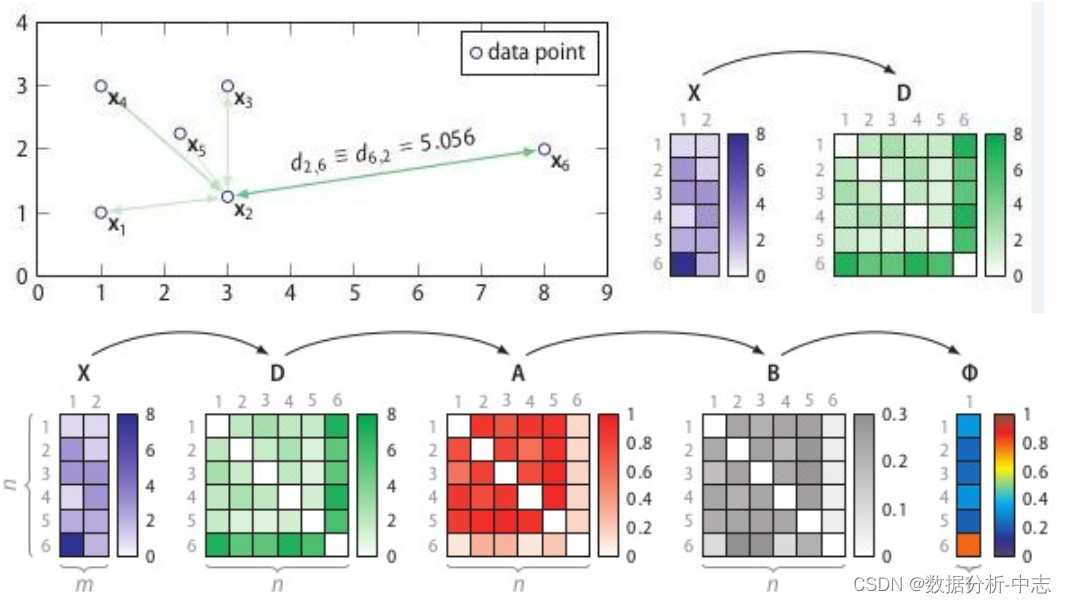
SOSProcessus:
Calcul de la matrice de différence de phase D;
Calculer la matrice des degrés de corrélation A;
Calculer la matrice de probabilité de corrélation B;
Calculer le vecteur de probabilité anormal .
Matrice de divergence D Est la distance mesurée entre deux échantillons , Comme la distance européenne ou la distance Hamming, etc. . La matrice des degrés de corrélation reflète la variance de la distance métrique ,Comme le montre la figure7,Point La densité maximale de , Variance minimale ; Densité minimale de , Variance maximale . Et la matrice de probabilité de corrélation B(binding probability matrix) Est de mettre la matrice de corrélation (affinity matrix) Normalisé par ligne ,Comme le montre la figure8Comme indiqué.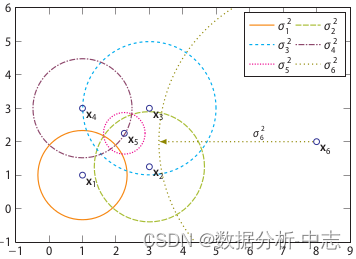
La figure ci - dessus montre la visualisation de la densité dans la matrice des degrés de corrélation , La figure ci - dessous montre la matrice de probabilité de corrélation 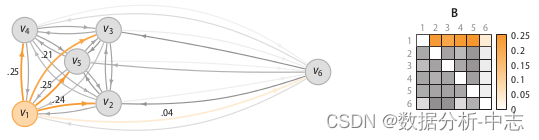
Je l'ai.binding probability matrix, La probabilité anormale de chaque point est calculée à l'aide de la formule suivante: , Quand un point est associé à tous les autres points (affinity)Très jeune., C'est une anomalie .
import pandas as pd
from sksos import SOS
iris = pd.read_csv("http://bit.ly/iris-csv")
X = iris.drop("Name", axis=1).values
detector = SOS()
iris["score"] = detector.predict(X)
iris.sort_values("score", ascending=False).head(10)
Quatre:Approche fondée sur le regroupement
DBSCANAlgorithmes(Density-Based Spatial Clustering of Applications with Noise) Les entrées et sorties de , Pour les points isolés qui ne peuvent pas être groupés , C'est le point d'exception (Point de bruit).
● Entrée:Ensemble de données,Rayon de voisinageEps, Seuil de nombre d'objets de données dans le voisinage MinPts;
● Produits: Densité des grappes connectées .
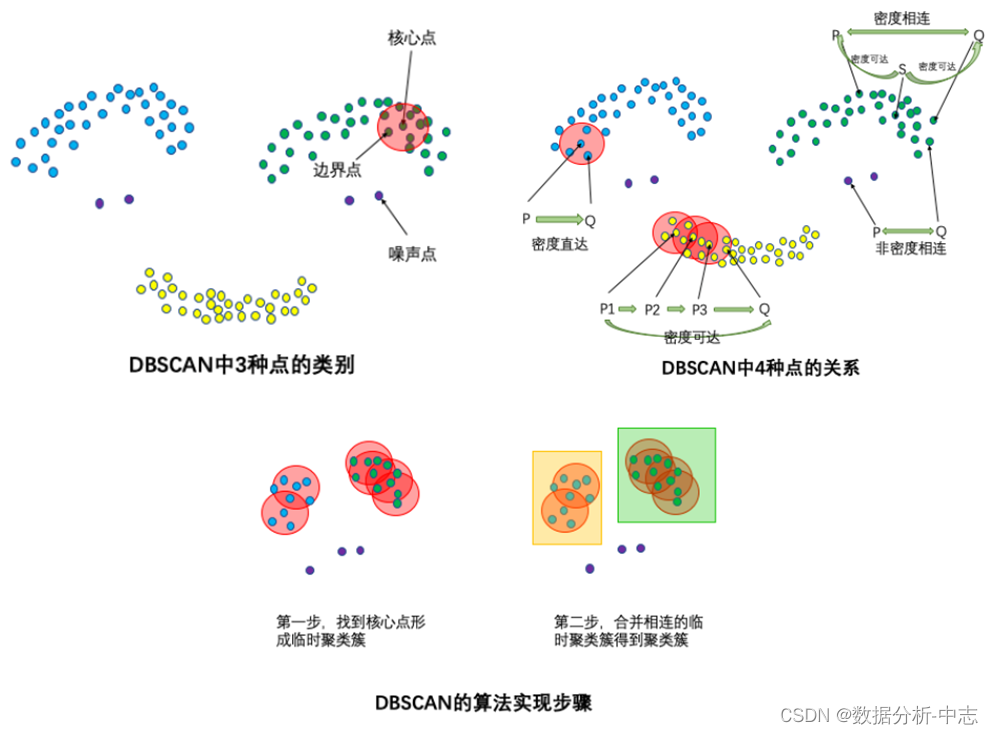
Le processus de traitement est le suivant.
Sélectionnez n'importe quel point d'objet de données dans l'ensemble de données p;
Si pour les paramètres EpsEtMinPts, Point de l'objet de données sélectionné pPour le point central, Alors trouvez tout à partir de p Points d'objets de données avec densité accessible ,Former un Cluster;
Si vous sélectionnez un point d'objet de données p C'est le point de bord , Sélectionnez un autre point d'objet de données ;
Répétez ce qui précède.2、3Pas, Jusqu'à ce que tous les points soient traités .
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
array([ 0, 0, 0, 1, 1, -1])
# 0,,0,,0: Indique que les trois premiers échantillons sont divisés en un groupe
# 1, 1: Les deux intermédiaires sont divisés en un groupe
# -1: Le dernier est un point d'exception , N'appartient à aucun groupe
Cinq、Approche arborescente
Dans une forêt isolée “Isolement” (isolation) Ça veut dire “ Isoler les anomalies de tous les échantillons ”, L'article original est “separating an instance from the rest of the instances”.
Nous utilisons un hyperplan aléatoire pour couper un espace de données , Deux sous - espaces peuvent être générés en coupant une fois .Et puis..., Nous allons continuer à sélectionner des hyperplans au hasard , Pour couper les deux sous - espaces de la première étape ,Ça tourne en rond, Jusqu'à ce qu'il n'y ait qu'un seul point de données dans chaque sous - espace .On peut trouver, Les grappes denses doivent être coupées plusieurs fois avant de s'arrêter. , C'est - à - dire que chaque point existe seul dans un sous - espace , Mais ces points dispersés , La plupart se sont arrêtés dans un sous - espace très tôt. .Alors..., Algorithme de toute la forêt isolée : Les échantillons anormaux sont plus susceptibles de tomber rapidement dans les noeuds foliaires, ou , L'échantillon d'exception est dans l'arbre de décision , Plus près du noeud racine .
Sélection aléatoiremCaractéristiques, Diviser les points de données en sélectionnant au hasard une valeur entre la valeur maximale et la valeur minimale de la caractéristique sélectionnée . La Division des observations se répète Récursivement , Jusqu'à ce que toutes les observations soient isolées .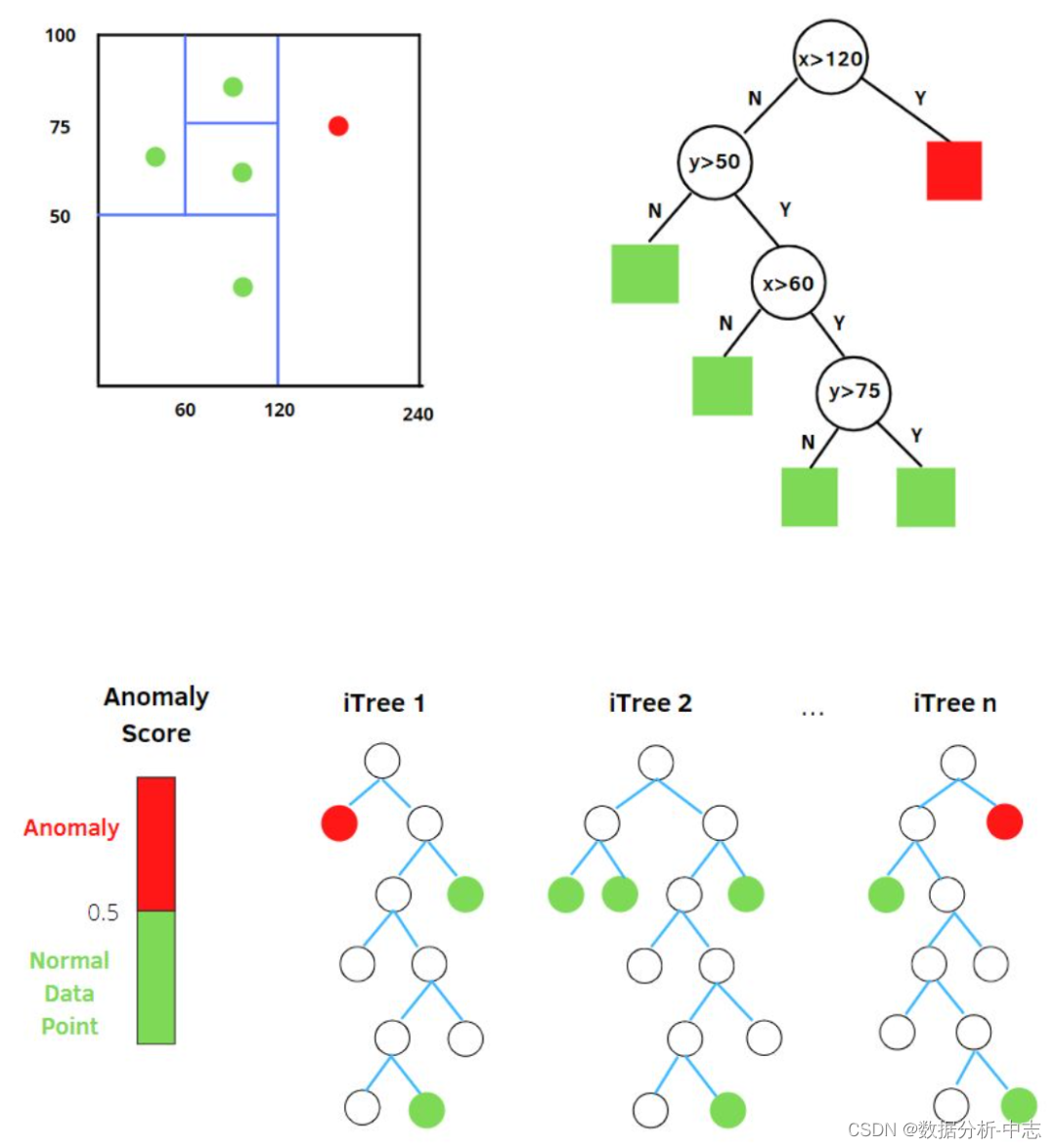
Obtenir t Derrière les arbres isolés , L'entraînement d'un seul arbre est terminé. . Ensuite, vous pouvez utiliser l'arbre isolé généré pour évaluer les données d'essai , C'est - à - dire calculer la fraction d'exception s.Pour chaque échantillon x, Les résultats de chaque arbre doivent être calculés de façon exhaustive. , Calculer le score d'exception à l'aide de la formule suivante: : ● h(x): Pour l'échantillon à iTreeOui.PathLength;
● E(h(x)): Pour l'échantillon à tArbreiTreeDePathLengthLa moyenne de;
● c(n):Pourn Échantillons pour construire un arbre de recherche binaire BST Recherche infructueuse longueur moyenne du chemin en (Moyenneh(x) L'estimation des terminaux de noeuds externes est équivalente à BST Recherche infructueuse dans ). C'est un échantillon xLongueur du chemin pourh(x)Traitement normalisé.H(n-1) C'est un nombre harmonique ,Disponible enln(n-1)+0.5772156649(Constante Euler)Estimation. La plage de valeurs de la partie exponentielle est (−∞,0),Donc,sLa plage de valeurs est(0,1).QuandPathLengthPlus petit.,sPlus vous approchez1, Plus la probabilité que l'échantillon soit anormal est élevée .
from sklearn.datasets import load_iris
from sklearn.ensemble import IsolationForest
data = load_iris(as_frame=True)
X,y = data.data,data.target
df = data.frame
# Formation sur modèle
iforest = IsolationForest(n_estimators=100, max_samples='auto',
contamination=0.05, max_features=4,
bootstrap=False, n_jobs=-1, random_state=1)
# fit_predict Fonctions Formation et prévision On peut déterminer si le modèle est anormal ou non. ,-1Est une exception,1Normal.
df['label'] = iforest.fit_predict(X)
# Prévisions decision_function On peut conclure que Note anormale
df['scores'] = iforest.decision_function(X)
Six、 Une approche basée sur la réduction des dimensions
1、Principal Component Analysis (PCA)
PCA Pratique en matière de détection des anomalies , Il y a deux façons de penser :
(1) Cartographie des données dans les espaces de fonctions de faible dimension , Ensuite, examinez l'écart de chaque point de données par rapport aux autres données dans différentes dimensions de l'espace caractéristique ;
(2) Cartographie des données dans les espaces de fonctions de faible dimension , Ensuite, l'espace de fonctionnalité de faible dimension est redessiné à l'espace d'origine , Essayer de reconstruire les données originales avec des caractéristiques de faible dimension , Regardez la taille de l'erreur de reconstruction .
PCA Je fais une décomposition propre ,Je l'aurai.:
● Vecteur caractéristique: Différentes directions reflétant le degré de variation de la variance des données brutes ;
● Valeur propre: Taille de la variance des données dans la direction correspondante .
Alors...,Le vecteur caractéristique correspondant à la valeur caractéristique maximale est la direction dans laquelle la variance des données est la plus grande,Le vecteur caractéristique correspondant à la valeur caractéristique minimale est la direction dans laquelle la variance des données est la plus faible.Les variations de variance des données brutes dans différentes directions reflètent leurs caractéristiques intrinsèques. Si un seul échantillon de données ne correspond pas exactement aux caractéristiques de l'ensemble de l'échantillon de données , Par exemple, dans certaines directions, il y a un écart important par rapport à d'autres échantillons de données. ,Cela pourrait indiquer que l'échantillon de données est un point anormal.
Dans la première approche mentionnée précédemment, ,Échantillons x i x_i xi La fraction anormale de est le degré de déviation de l'échantillon dans toutes les directions : Parmi eux, Est la distance entre l'échantillon et le vecteur caractéristique dans l'espace reconstruit . Plus le point d'échantillonnage est éloigné de chaque composant principal , Plus grand sera, Ça veut dire un grand décalage , Score anormal élevé . Est la valeur caractéristique,Pour la normalisation, Rendre comparables les degrés de déviation dans différentes directions .
Lors du calcul de la fraction anormale , À propos des vecteurs de caractéristiques ( C'est - à - dire l'étalonnage utilisé pour mesurer les exceptions ) Il y a deux autres façons de choisir :
● Pensez - y avant k Déviation dans la direction des vecteurs caractéristiques :Avantk Les vecteurs de caractéristiques correspondent souvent directement à certaines caractéristiques des données brutes , Échantillons de données présentant des écarts importants dans les directions des vecteurs caractéristiques précédents , C'est souvent l'Extremum de ces caractéristiques dans les données brutes. .
● Après réflexionr Déviation dans la direction des vecteurs caractéristiques :Aprèsr Les vecteurs caractéristiques représentent généralement une combinaison linéaire de plusieurs caractéristiques originales , La faible variance après la combinaison linéaire reflète une certaine relation entre ces caractéristiques . Échantillons de données présentant des écarts importants dans les dernières directions caractéristiques , Indique qu'il y a eu une situation qui n'est pas tout à fait conforme aux prévisions pour les caractéristiques correspondantes dans les données brutes . Score supérieur au seuil C Est considéré comme anormal .
Deuxième approche,PCA Principales caractéristiques des données extraites , Si un échantillon de données n'est pas facilement reconstruit , Indique que les caractéristiques de cet échantillon de données ne correspondent pas à celles de l'ensemble de l'échantillon de données , Donc C'est clairement un échantillon anormal :
Parmi eux, Est basé surk Exemple de reconstruction du vecteur caractéristique dimensionnel .
Lors de la reconstruction d'échantillons de données basés sur des caractéristiques de faible dimension , L'information dans la direction du vecteur caractéristique correspondant à la plus petite valeur caractéristique est rejetée .En un mot, .En fait, l'erreur de reconstruction provient principalement de l'information dans la direction du vecteur caractéristique correspondant à la plus petite valeur propre . Sur la base de cette compréhension intuitive ,PCA Deux approches différentes de la détection des anomalies accordent une attention particulière aux vecteurs caractéristiques correspondant à des valeurs propres plus petites .Alors...,On a dit:PCA Les deux façons de penser à la détection des anomalies sont essentiellement similaires , Bien sûr, la première méthode peut également se concentrer sur les vecteurs propres correspondant à des valeurs propres plus grandes .
rom sklearn.decomposition import PCA
pca = PCA()
pca.fit(centered_training_data)
transformed_data = pca.transform(training_data)
y = transformed_data
# Calculer le score d'exception
lambdas = pca.singular_values_
M = ((y*y)/lambdas)
# Avantk Les vecteurs caractéristiques et rVecteurs caractéristiques
q = 5
print "Explained variance by first q terms: ", sum(pca.explained_variance_ratio_[:q])
q_values = list(pca.singular_values_ < .2)
r = q_values.index(True)
# Calcul de la somme de distance pour chaque point d'échantillonnage
major_components = M[:,range(q)]
minor_components = M[:,range(r, len(features))]
major_components = np.sum(major_components, axis=1)
minor_components = np.sum(minor_components, axis=1)
# Réglage artificielc1、c2Seuil
components = pd.DataFrame({
'major_components': major_components,
'minor_components': minor_components})
c1 = components.quantile(0.99)['major_components']
c2 = components.quantile(0.99)['minor_components']
# Faire un classificateur
def classifier(major_components, minor_components):
major = major_components > c1
minor = minor_components > c2
return np.logical_or(major,minor)
results = classifier(major_components=major_components, minor_components=minor_components)
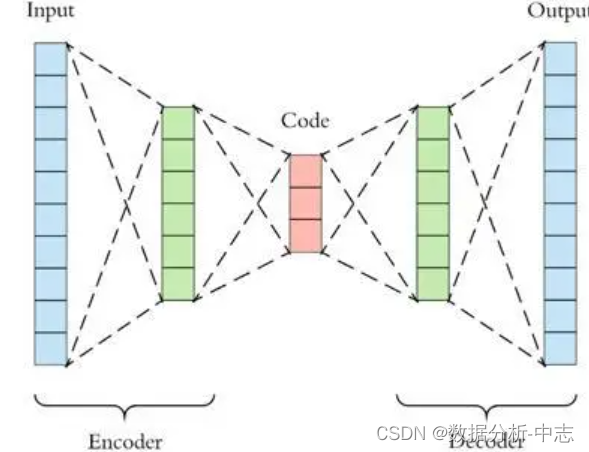
2、AutoEncoder
PCA C'est une réduction linéaire ,AutoEncoder C'est une réduction non linéaire . Formé à partir de données normales AutoEncoder, Capable de reconstruire et de restaurer des échantillons normaux , Mais les points de données qui ne sont pas normalement distribués ne peuvent pas être restaurés correctement , Cause une grande erreur de restauration . Donc si un nouvel échantillon est codé ,Après décodage, Son erreur dépasse la plage d'erreur normale après codage et décodage des données , Est considéré comme des données anormales .Il est important de noter que,AutoEncoder Les données utilisées pour la formation sont normales ( C'est - à - dire qu'il n'y a pas d'exception ), Ce n'est qu'ainsi qu'il est raisonnable et normal d'obtenir la plage de distribution des erreurs après reconstruction .Alors...AutoEncoder Lors de la détection d'anomalies ici , C'est une méthode d'apprentissage supervisée. .
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
# Données normalisées
scaler = preprocessing.MinMaxScaler()
X_train = pd.DataFrame(scaler.fit_transform(dataset_train),
columns=dataset_train.columns,
index=dataset_train.index)
# Random shuffle training data
X_train.sample(frac=1)
X_test = pd.DataFrame(scaler.transform(dataset_test),
columns=dataset_test.columns,
index=dataset_test.index)
tf.random.set_seed(10)
act_func = 'relu'
# Input layer:
model=Sequential()
# First hidden layer, connected to input vector X.
model.add(Dense(10,activation=act_func,
kernel_initializer='glorot_uniform',
kernel_regularizer=regularizers.l2(0.0),
input_shape=(X_train.shape[1],)
)
)
model.add(Dense(2,activation=act_func,
kernel_initializer='glorot_uniform'))
model.add(Dense(10,activation=act_func,
kernel_initializer='glorot_uniform'))
model.add(Dense(X_train.shape[1],
kernel_initializer='glorot_uniform'))
model.compile(loss='mse',optimizer='adam')
print(model.summary())
# Train model for 100 epochs, batch size of 10:
NUM_EPOCHS=100
BATCH_SIZE=10
history=model.fit(np.array(X_train),np.array(X_train),
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
validation_split=0.05,
verbose = 1)
plt.plot(history.history['loss'],
'b',
label='Training loss')
plt.plot(history.history['val_loss'],
'r',
label='Validation loss')
plt.legend(loc='upper right')
plt.xlabel('Epochs')
plt.ylabel('Loss, [mse]')
plt.ylim([0,.1])
plt.show()
# Voir la distribution des erreurs pour la restauration des ensembles de formation , Pour établir une plage normale de distribution des erreurs
X_pred = model.predict(np.array(X_train))
X_pred = pd.DataFrame(X_pred,
columns=X_train.columns)
X_pred.index = X_train.index
scored = pd.DataFrame(index=X_train.index)
scored['Loss_mae'] = np.mean(np.abs(X_pred-X_train), axis = 1)
plt.figure()
sns.distplot(scored['Loss_mae'],
bins = 10,
kde= True,
color = 'blue')
plt.xlim([0.0,.5])
# Comparaison des seuils d'erreur ,Trouver des valeurs aberrantes
X_pred = model.predict(np.array(X_test))
X_pred = pd.DataFrame(X_pred,
columns=X_test.columns)
X_pred.index = X_test.index
threshod = 0.3
scored = pd.DataFrame(index=X_test.index)
scored['Loss_mae'] = np.mean(np.abs(X_pred-X_test), axis = 1)
scored['Threshold'] = threshod
scored['Anomaly'] = scored['Loss_mae'] > scored['Threshold']
scored.head()
Sept、Approche fondée sur la classification
1、One-Class SVM
One-Class SVM, L'idée de cet algorithme est très simple , Est de trouver un hyperplan pour encercler l'échantillon positif , La prédiction est d'utiliser cet hyperplan pour prendre des décisions , L'échantillon dans le cercle est considéré comme positif , L'échantillon à l'extérieur du cercle est négatif , Pour la détection des anomalies , Un échantillon négatif peut être considéré comme un échantillon anormal . Il s'agit d'un apprentissage non supervisé , Donc pas besoin d'étiquettes .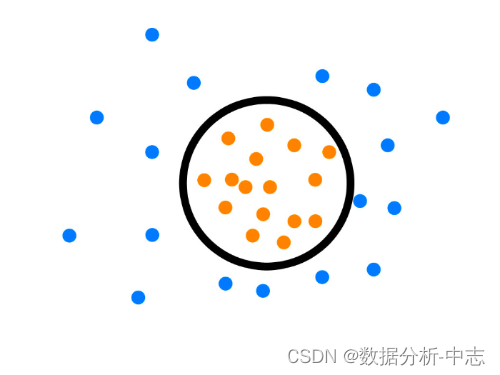
One-Class SVM Une autre façon de déduire est SVDD(Support Vector Domain Description, Support Vector Field description ),PourSVDDDis, Nous nous attendons à ce que tous les échantillons qui ne sont pas anormaux soient positifs. , En même temps, il utilise une Hypersphère , Au lieu d'un hyperplan pour diviser , L'algorithme obtient la limite sphérique autour des données dans l'espace caractéristique , S'attendre à minimiser le volume de cette Hypersphère , Pour minimiser l'impact des données aberrantes .
Supposons que les paramètres hypersphériques générés soient centrés o Et le rayon hypersphérique correspondant r>0, Volume hypersphérique VMinimisé,Centreo Est une combinaison linéaire de lignes de support ;Avec la traditionSVMLa méthode est similaire, Tous les points de données de formation peuvent être demandés xi La distance du Centre est strictement inférieure à r. Mais en même temps, nous construisons un coefficient de pénalité C Variable de relaxation pour ζi, Les problèmes d'optimisation sont présentés ci - dessous :
C Est d'ajuster l'influence de la variable de relaxation ,C'est très populaire., Combien d'espace de relaxation pour les points de données qui ont besoin de relaxation ,SiCPlus petit., Donne plus d'élasticité au point de départ , De sorte qu'ils ne puissent pas être inclus dans l'Hypersphère .
from sklearn import svm
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel='rbf', gamma=0.1)
clf.fit(X)
y_pred = clf.predict(X)
n_error_outlier = y_pred[y_pred == -1].size
Huit、Approche fondée sur les prévisions
Pour une seule série de données , Les courbes de séries chronologiques prédites sont comparées aux données réelles , Trouver les résidus pour chaque point , Et modéliser la séquence résiduelle ,UtilisationKSigma Ou le quantile peut être utilisé pour détecter les anomalies .Le processus spécifique est le suivant::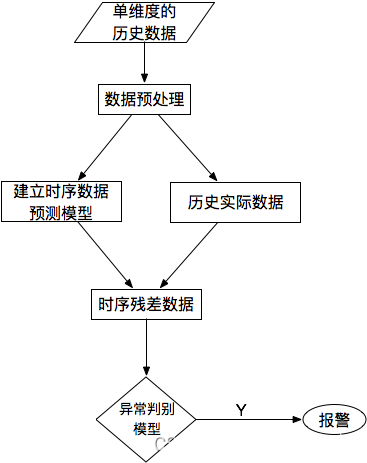
Neuf、Résumé
Les méthodes de détection des anomalies sont résumées comme suit: :
边栏推荐
- 墨者学院-Webmin未经身份验证的远程代码执行
- How to reset IntelliSense in vs Code- How to reset intellisense in VS Code?
- [network security] what is emergency response? What indicators should you pay attention to in emergency response?
- Life planning (flag)
- Is l1-029 too fat (5 points)
- Handwritten easy version flexible JS and source code analysis
- 深入浅出:了解时序数据库 InfluxDB
- Sports [running 01] a programmer's half horse challenge: preparation before running + adjustment during running + recovery after running (experience sharing)
- Activiti常见操作数据表关系
- Example analysis of C # read / write lock
猜你喜欢
ZABBIX 5.0 monitoring client
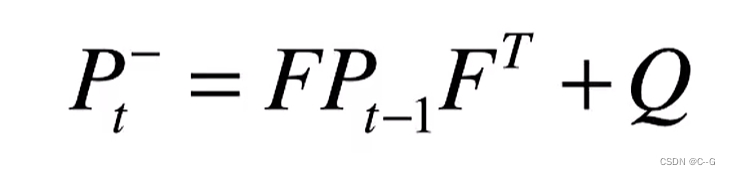
1. Kalman filter - the best linear filter
Introduction to neural network (Part 2)

Used on windows Bat file startup project

What does range mean in PHP
【性能测试】一文读懂Jmeter

Heap concept in JVM
System architecture design of circle of friends

How to improve your system architecture?

Oracle stored procedures and functions
随机推荐
The idea of implementing charts chart view in all swiftui versions (1.0-4.0) was born
运动【跑步 01】一个程序员的半马挑战:跑前准备+跑中调整+跑后恢复(经验分享)
墨者学院-phpMyAdmin后台文件包含分析溯源
Thesis learning -- time series similarity query method based on extreme point characteristics
Div hidden in IE 67 shows blank problem IE 8 is normal
博客停更声明
Common components of flask
How to write a summary of the work to promote the implementation of OKR?
string. Format without decimal places will generate unexpected rounding - C #
Cannot click button when method is running - C #
论文学习——基于极值点特征的时间序列相似性查询方法
Relations courantes de la fiche de données d'exploitation pour les activités
The right way to capture assertion failures in NUnit - C #
Zephyr study notes 2, scheduling
Unity write word
zabbix 5.0监控客户端
Blog stop statement
It's healthy to drink medicinal wine like this. Are you drinking it right
R language uses cforest function in Party package to build random forest based on conditional inference trees, uses varimp function to check feature importance, and uses table function to calculate co
Tri des fonctions de traitement de texte dans MySQL, recherche rapide préférée