当前位置:网站首页>Preliminary study on temporal database incluxdb 2.2
Preliminary study on temporal database incluxdb 2.2
2022-07-04 07:31:00 【sp42a】
What is a time series database ? There is no popular science here , Please Baidu . Timing data is a scenario of writing more and reading less .
InfluxDB use Go Language writing , Open source , It should be good . But the disadvantage is : The stand-alone version is free and open source , There is a charge for the cluster version .
install
Download the database separately Server And command line tools CLI, Two separate programs . After installation , perform influx start-up Server, Pay attention to exposure 8086 Default port .
influx
This is a temporary start , We changed the daemon to execute ,
nohup ./influx &
Then on Server Configure accordingly , Yes WebUI The interface of , Visit its 8086 Web The service can be , As shown in the figure below .
Set the initial user , All required items .
Successful initialization .
Java Client calls
Our application is Java, So do it :
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>6.1.0</version>
</dependency>
Measurement
Excerpt from netizens :
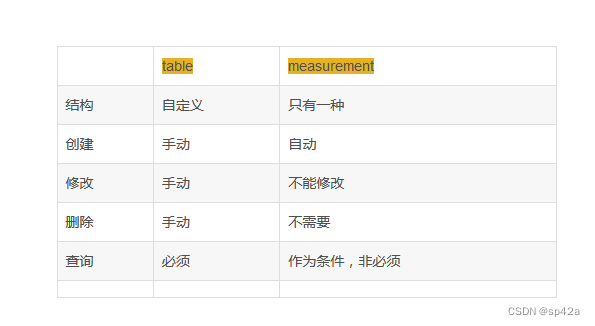
In a relational database , We are all on the watch table Query data in , According to the understanding of inertial thinking , Will also put influxdb Of measurement Understood as a table , Then when you query, you will naturally bring
_measurement, However, in the actual query, this is only used as influxdb Query criteria for , In fact, it is an optional condition , Even if not, it can still be queried correctly . But when writing, you must measurement Of .It can also be seen from here ,influxdb Of measurement With a relational database table Not exactly a concept , stay influxdb in measurement It's just bucket As a grouping .influxdb In fact, there is only one data structure , therefore measurement It's the only one ,measurement It will be automatically created when writing data , If the data does not exist ,measurement It will disappear naturally .
Simply compare the two :
Write data
Writing tools can support :influx Command line or API client , For example, we write Java It is officially provided Java-client. Writing mode can support Line protocol Data format or Java Entity Bean, recommend Java Bean intuitive .
asynchronous / Sync
Java Data written by the client can be divided into synchronous writing and asynchronous writing .
WriteApiBlocking writeApi = client.getWriteApiBlocking(); // Blocking , Synchronization
WriteApi makeWriteApi = client.makeWriteApi(); // Non blocking , Asynchronous
Better asynchronous performance , You can write to the database once in either of the following two cases :
- Timer flush operation , Such as once a second
- Write data to 5000 pen , Write once , Control this quantity to
batch_size( Adjustable )
Before writing data , Data is overstocked buffer In cache .
// write in , Specify a precision of ns nanosecond
writeApi.writeMeasurement(WritePrecision.NS, vo);
Browsing data
Database tools we will think NativeCat And so on. , but influx What about ? Please rest assured that it is officially provided UI Tools , And it's beautifully made , Access the deployment location with a browser , Such as http://localhost:8086, Click on Data Explorer You can browse .
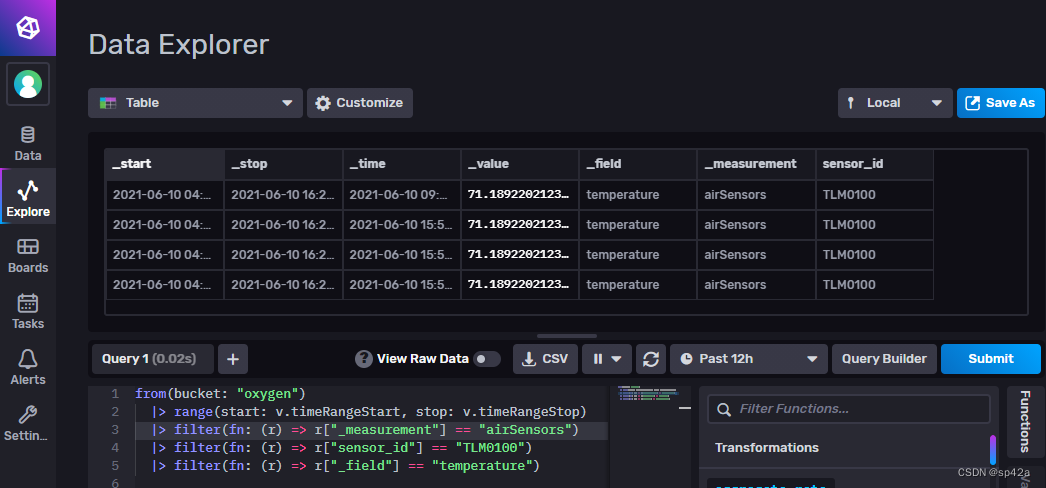
Flux
Flux(flux: n. Traffic ; Changes ; unstable ; Flow out ; vt. Melt ; Treat with flux ; vi. melt ; Flow out ) yes InfluxDB 2.0 A query language introduced , The new version v2 Abandoned v1 Similar SQL grammar , Completely use self-made query methods , be called "Flux". Every Flux Queries need to include the following parts :1. data source ,2 Time range ,3 Data filters .
data source :bucket Identify the name of the database
from(bucket:"example-bucket")
Time range ,stop It's not necessary , The time range can be a specific time (UTC Time ) Or timestamps , It can also be a relative time range , Such as -1h Show the past 1 Data in hours ( Relative to the current time ), Optional units are s,m( minute ),h,d,mo( month ),y
|> range(start: -1h, stop: -10m)
When querying time series data ,Flux Need a time frame ." unbounded " Queries are very resource intensive , As a protective measure ,Flux The database will not be queried without a specified range .
Data filters , Multiple filters can be used and or or Connect , Or start another filter
|> filter(fn: (r) =>)
filter The optional values for are :_measurement ,_field ,_value,_time, Some tag The name of
Generate query data ( Optional )
|> yield()
The output table usually contains :_start, _stop, _field,_value, _measurement,_time,[tag name ] Field
Every flux Grammar is written in “from” Start , Every other part needs to be marked with " |> " start .
About Tag Field
Start using Flux when , Find even simple SQL where The specified condition query cannot be done , Very disappointed ! I asked a lot and didn't know , Later, I read the English documents tag Talent inspiration , There is no designation tag Why .influx in , Distinguish ordinary field and tag field, The former is not indexed , So it can't be searched , The latter can . So when you want to search a field , It must be specified as tag field, Like the one below uavId Field
/** * The battery 、 voltage */
@Measurement(name = "Power")
public class Power extends InfluxValueObject {
@Column(tag = true)
public String uavId;
@Column
public Integer batteryRemaining;
@Column
public Float voltageBattery;
}
If you build too many indexes , write in 、 Query performance will decline .
Two kinds of function
The first one is : aggregate function; The second kind :selector function. The most important difference between these two types of functions is ,aggregate funciton Is to return a data record through aggregation ;selector funciton Is to return a set of original data . These two kinds of functions can be mixed in some places , Sometimes you can't .
similar SQL Of OR perhaps IN Inquire about
- stay filter Use in
orConnect :|> filter(fn: (r) => r.eq == "1" or r.eq == "2") - Use
containsfunction : stay from Previously defined arrayfields = ["1", "2"], And then in filter Use in|> filter(fn: (r) => contains(value: r.eq, set: fields))
The data backup
Reference resources :https://www.sunzhongwei.com/influxdb-20-data-backup-recovery-exportimport?from=bottom
边栏推荐
- One of the general document service practice series
- 【森城市】GIS数据漫谈(一)
- flask-sqlalchemy 循环引用
- What are the work contents of operation and maintenance engineers? Can you list it in detail?
- Pangu open source: multi support and promotion, the wave of chip industry
- Zephyr learning notes 1, threads
- I was pressed for the draft, so let's talk about how long links can be as efficient as short links in the development of mobile terminals
- Improve the accuracy of 3D reconstruction of complex scenes | segmentation of UAV Remote Sensing Images Based on paddleseg
- [real case] how to deal with the failure of message consumption?
- Zhanrui tankbang | jointly build, cooperate and win-win zhanrui core ecology
猜你喜欢
In the era of low code development, is it still needed?
Detailed introduction to the big changes of Xcode 14
【森城市】GIS数据漫谈(一)

Handwritten easy version flexible JS and source code analysis

Routing decorator of tornado project
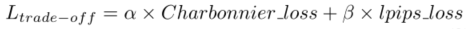
用于压缩视频感知增强的多目标网络自适应时空融合
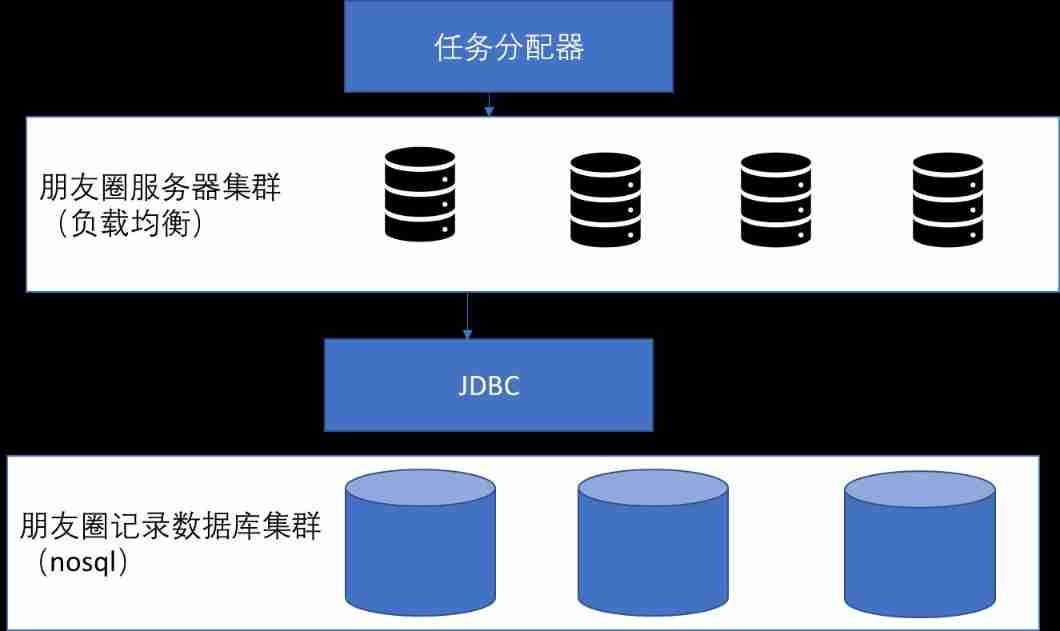
System architecture design of circle of friends
Four sets of APIs for queues
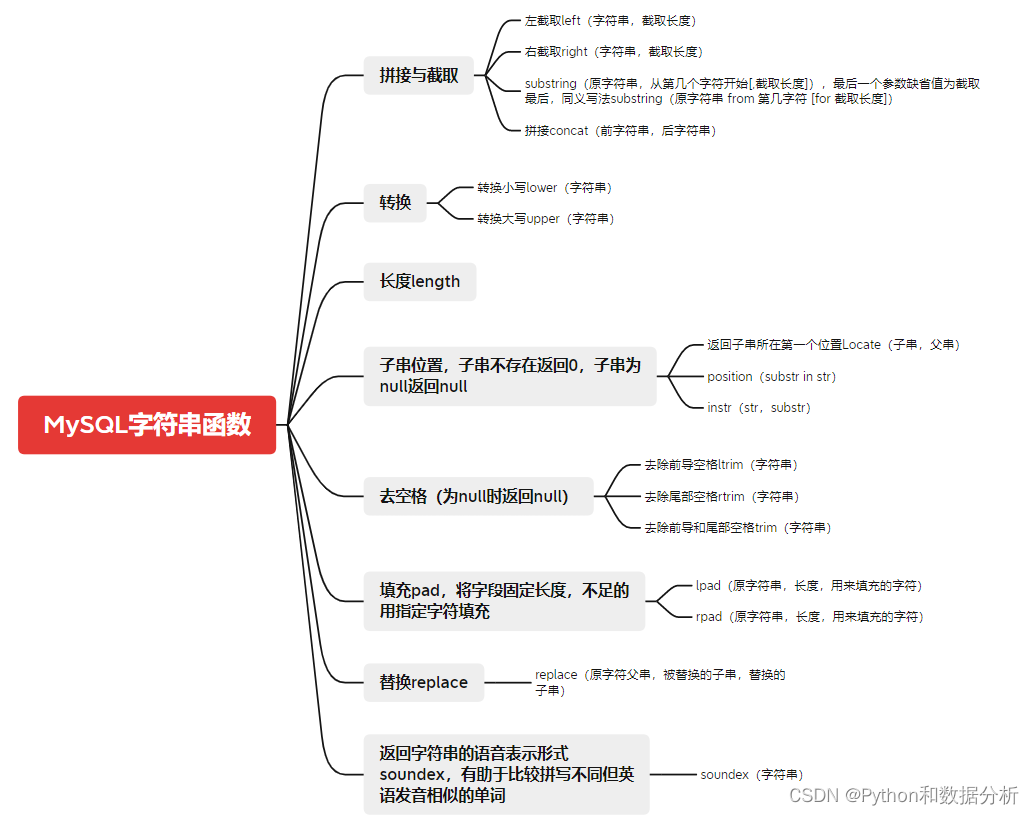
MySQL中的文本处理函数整理,收藏速查
How to send mail with Jianmu Ci
随机推荐
Label management of kubernetes cluster
The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
MySQL error resolution - error 1261 (01000): row 1 doesn't contain data for all columns
Enter the year, month, and determine the number of days
Zephyr 學習筆記2,Scheduling
Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and
Node foundation ~ node operation
The cloud native programming challenge ended, and Alibaba cloud launched the first white paper on application liveliness technology in the field of cloud native
MySQL中的文本处理函数整理,收藏速查
Go learning notes - constants
NLP-文献阅读总结
Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Technical experts from large factories: common thinking models in architecture design
Unity 从Inspector界面打开资源管理器选择并记录文件路径
Valentine's Day is coming! Without 50W bride price, my girlfriend was forcibly dragged away...
Cell reports: Wei Fuwen group of the Institute of zoology, Chinese Academy of Sciences analyzes the function of seasonal changes in the intestinal flora of giant pandas
The difference between synchronized and lock
Mysql database - function constraint multi table query transaction
Node connection MySQL access denied for user 'root' @ 'localhost' (using password: yes
Guoguo took you to write a linked list, and the primary school students said it was good after reading it