当前位置:网站首页>Pytorch fine tuning (Fortune): hollowed out design or cheating
Pytorch fine tuning (Fortune): hollowed out design or cheating
2022-07-05 01:34:00 【FakeOccupational】
steal the beams and pillars and replace them with rotten timbers or Mink tail dog
# Import package
import glob
import os
import torch
import matplotlib.pyplot as plt
import random # For data iterators to generate random data
# Generate data set x1 Category 0,x2 Category 1
n_data = torch.ones(50, 2) # The basic form of data
x1 = torch.normal(2 * n_data, 1) # shape=(50, 2)
y1 = torch.zeros(50) # type 0 shape=(50, 1)
x2 = torch.normal(-2 * n_data, 1) # shape=(50, 2)
y2 = torch.ones(50) # type 1 shape=(50, 1)
# Be careful x, y The data form of data must be like the following (torch.cat Is consolidated data )
x = torch.cat((x1, x2), 0).type(torch.FloatTensor)
y = torch.cat((y1, y2), 0).type(torch.FloatTensor)
# Dataset Visualization
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show()
# data fetch :
def data_iter(batch_size, x, y):
num_examples = len(x)
indices = list(range(num_examples))
random.shuffle(indices) # The reading order of samples is random
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # The last time may be less than one batch
yield x.index_select(0, j), y.index_select(0, j)
import torch.nn as nn
import torch.optim as optim
class net(nn.Module):
def __init__(self, **kwargs):
super(net, self).__init__(**kwargs)
self.net = nn.Sequential(
nn.Linear(2, 2),
nn.Linear(2, 2),
nn.Linear(2, 1),
nn.ReLU())
def forward(self, x):
return self.net(x)
def loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def accuracy(y_hat, y): #@save
""" Calculate the correct number of predictions ."""
cmp = y_hat.type(y.dtype) > 0.5 # Greater than 0.5 Category 1
result=cmp.type(y.dtype)
acc = 1-float(((result-y).sum())/ len(y))
return acc;
lr = 0.03
num_epochs = 3 # The number of iterations
batch_size = 10 # Batch size
model = net()
params = list(model.parameters())
optimizer = torch.optim.Adam(params, 1e-4)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=1, bias=True)
# (1): Linear(in_features=1, out_features=2, bias=True)
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
for param in model.parameters():
param.requires_grad = False
print(model.net[2])
num_fc_in = model.net[2].in_features
print("fc The input dimension of the layer ",num_fc_in)
model.net[2] = nn.Linear(num_fc_in, 3) # steal the beams and pillars and replace them with rotten timbers Mink tail dog
print(model)
aa = model.net[1]# Parameters cannot be learned Parameter containing:tensor([-0.0303, -0.9412])
aa = model.net[2]# Parameters can be learned Parameter containing:tensor([0.4327, 0.1848, 0.3112], requires_grad=True)
Hollow design
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=1, bias=True)
# (1): Linear(in_features=1, out_features=2, bias=True)
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
================================》
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=2, bias=True)
# (1): Identity()
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
# https://discuss.pytorch.org/t/how-to-delete-layer-in-pretrained-model/17648/16
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
# Import package
import glob
import os
import torch
import matplotlib.pyplot as plt
import random # For data iterators to generate random data
# Generate data set x1 Category 0,x2 Category 1
n_data = torch.ones(50, 2) # The basic form of data
x1 = torch.normal(2 * n_data, 1) # shape=(50, 2)
y1 = torch.zeros(50) # type 0 shape=(50, 1)
x2 = torch.normal(-2 * n_data, 1) # shape=(50, 2)
y2 = torch.ones(50) # type 1 shape=(50, 1)
# Be careful x, y The data form of data must be like the following (torch.cat Is consolidated data )
x = torch.cat((x1, x2), 0).type(torch.FloatTensor)
y = torch.cat((y1, y2), 0).type(torch.FloatTensor)
# Dataset Visualization
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show()
# data fetch :
def data_iter(batch_size, x, y):
num_examples = len(x)
indices = list(range(num_examples))
random.shuffle(indices) # The reading order of samples is random
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # The last time may be less than one batch
yield x.index_select(0, j), y.index_select(0, j)
import torch.nn as nn
import torch.optim as optim
class net(nn.Module):
def __init__(self, **kwargs):
super(net, self).__init__(**kwargs)
self.net = nn.Sequential(
nn.Linear(2, 2),
nn.Linear(2, 2),
nn.Linear(2, 1),
nn.ReLU())
def forward(self, x):
return self.net(x)
def loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def accuracy(y_hat, y): #@save
""" Calculate the correct number of predictions ."""
cmp = y_hat.type(y.dtype) > 0.5 # Greater than 0.5 Category 1
result=cmp.type(y.dtype)
acc = 1-float(((result-y).sum())/ len(y))
return acc;
lr = 0.03
num_epochs = 3 # The number of iterations
batch_size = 10 # Batch size
model = net()
params = list(model.parameters())
optimizer = torch.optim.Adam(params, 1e-4)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
# for param in model.parameters():
# param.requires_grad = False
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
model.net[1] = Identity()
for epoch in range(num_epochs):
for X, y_train in data_iter(batch_size, x, y):
optimizer.zero_grad()
res = model(X)[:,0]
l = loss(res, y_train).sum() # l It's about small batches X and y The loss of
l.backward(retain_graph=True)
optimizer.step()
print(l)
Head bearing
# import some dependencies https://boscoj2008.github.io/customCNN/
import glob
import os
import torchvision
import torch
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import torch.optim as optim
import time
import torch.nn as nn
import torch.nn.functional as F
torch.set_printoptions(linewidth=120)
class Network(nn.Module): # extend nn.Module class of nn
def __init__(self):
super().__init__() # super class constructor
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=(5, 5))
self.batchN1 = nn.BatchNorm2d(num_features=6)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=(5, 5))
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.batchN2 = nn.BatchNorm1d(num_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t): # implements the forward method (flow of tensors)
t = self.addconv1(t)# TODO Be careful , Comment out this sentence when saving the model
# hidden conv layer
t = self.conv1(t)
t = F.max_pool2d(input=t, kernel_size=2, stride=2)
t = F.relu(t)
t = self.batchN1(t)
# hidden conv layer
t = self.conv2(t)
t = F.max_pool2d(input=t, kernel_size=2, stride=2)
t = F.relu(t)
# flatten
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
t = self.batchN2(t)
t = self.fc2(t)
t = F.relu(t)
# output
t = self.out(t)
return t
cnn_model = Network() # init model
print(cnn_model)
mean = 0.2859; std = 0.3530 # calculated using standization from the MNIST itself which we skip in this blog
def saver(model_state_dict, optimizer_state_dict, model_path, epoch, max_to_save=30):
total_models = glob.glob(model_path + '*')
if len(total_models) >= max_to_save:
total_models.sort()
os.remove(total_models[0])
state_dict = {}
state_dict["model_state_dict"] = model_state_dict
state_dict["optimizer_state_dict"] = optimizer_state_dict
torch.save(state_dict, model_path + 'h' + str(epoch))
print('models {} save successfully!'.format(model_path + 'hahaha' + str(epoch)))
optimizer = optim.Adam(lr=0.01, params=cnn_model.parameters())
# for epoch in range(3):
# start_time = time.time()
# total_correct = 0
# total_loss = 0
# for batch in range(10):
# imgs, lbls = torch.rand(10,1,28,28),torch.tensor([0, 5, 3, 4, 4, 4, 7, 6, 2, 5])
# preds = cnn_model(imgs) # get preds
# loss = F.cross_entropy(preds, lbls) # compute loss
# optimizer.zero_grad() # zero grads
# loss.backward() # calculates gradients
# optimizer.step() # update the weights
# accuracy = total_correct / 10
# end_time = time.time() - start_time
# print("Epoch no.", epoch + 1, "|accuracy: ", round(accuracy, 3), "%", "|total_loss: ", total_loss,
# "| epoch_duration: ", round(end_time, 2), "sec")
# saver(cnn_model.state_dict(), optimizer.state_dict(), "./", epoch + 1, max_to_save=100)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
cnn_model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
cnn_model.addconv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(1, 1))
for epoch in range(3):
start_time = time.time()
total_correct = 0
total_loss = 0
for batch in range(10):
imgs, lbls = torch.rand(10,1,28,28),torch.tensor([0, 5, 3, 4, 4, 4, 7, 6, 2, 5])
preds = cnn_model(imgs) # get preds
loss = F.cross_entropy(preds, lbls) # compute loss
optimizer.zero_grad() # zero grads
loss.backward() # calculates gradients
optimizer.step() # update the weights
accuracy = total_correct / 10
end_time = time.time() - start_time
print("Epoch no.", epoch + 1, "|accuracy: ", round(accuracy, 3), "%", "|total_loss: ", total_loss,
"| epoch_duration: ", round(end_time, 2), "sec")
saver(cnn_model.state_dict(), optimizer.state_dict(), "./", epoch + 1, max_to_save=100)
边栏推荐
- [wave modeling 3] three dimensional random real wave modeling and wave generator modeling matlab simulation
- 【大型电商项目开发】性能压测-优化-中间件对性能的影响-40
- Jcenter () cannot find Alibaba cloud proxy address
- Intel sapphire rapids SP Zhiqiang es processor cache memory split exposure
- MATLB|多微电网及分布式能源交易
- Global and Chinese market of network connected IC card smart water meters 2022-2028: Research Report on technology, participants, trends, market size and share
- 如果消费互联网比喻成「湖泊」的话,产业互联网则是广阔的「海洋」
- Async/await you can use it, but do you know how to deal with errors?
- FEG founder rox:smartdefi will be the benchmark of the entire decentralized financial market
- Global and Chinese markets for stratospheric UAV payloads 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢
Express routing, express middleware, using express write interface
JS implementation determines whether the point is within the polygon range
Roads and routes -- dfs+topsort+dijkstra+ mapping
MATLB | multi micro grid and distributed energy trading
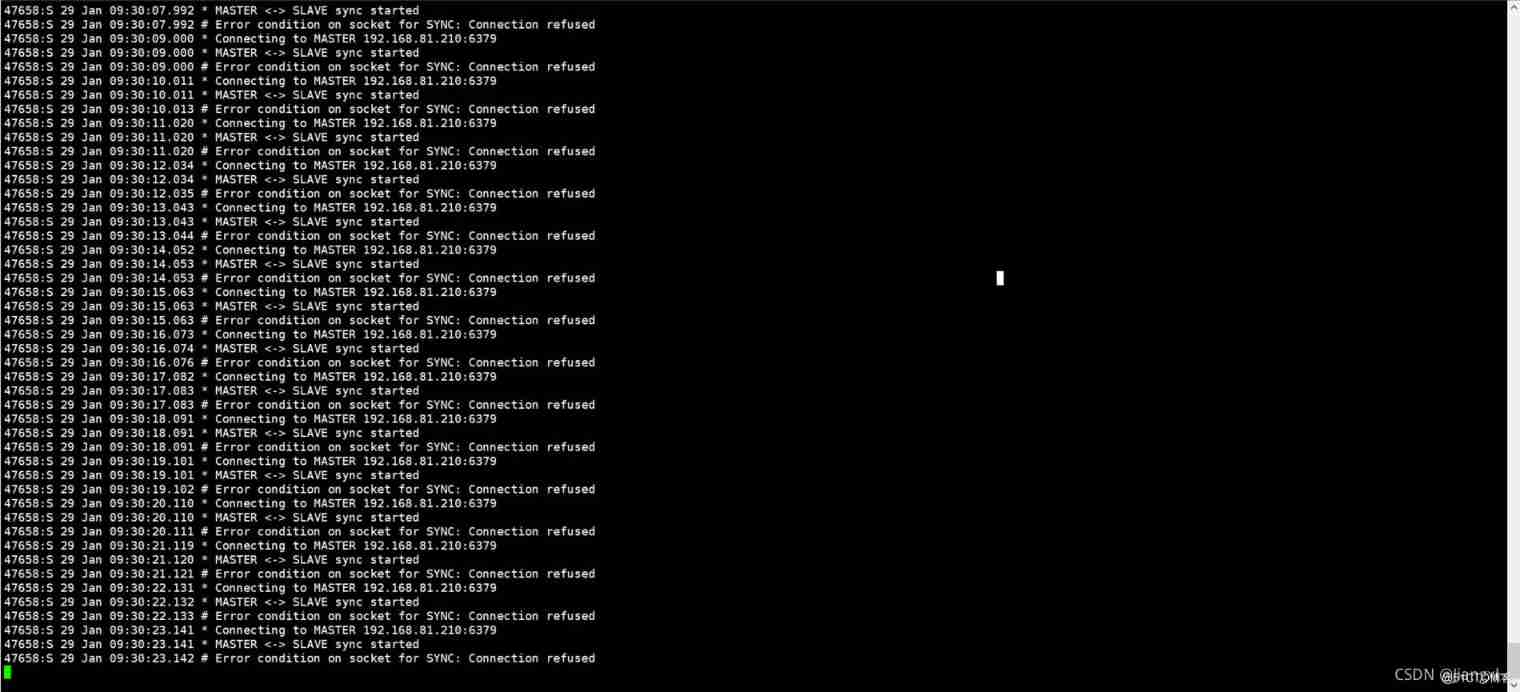
Redis master-slave replication cluster and recovery ideas for abnormal data loss # yyds dry goods inventory #
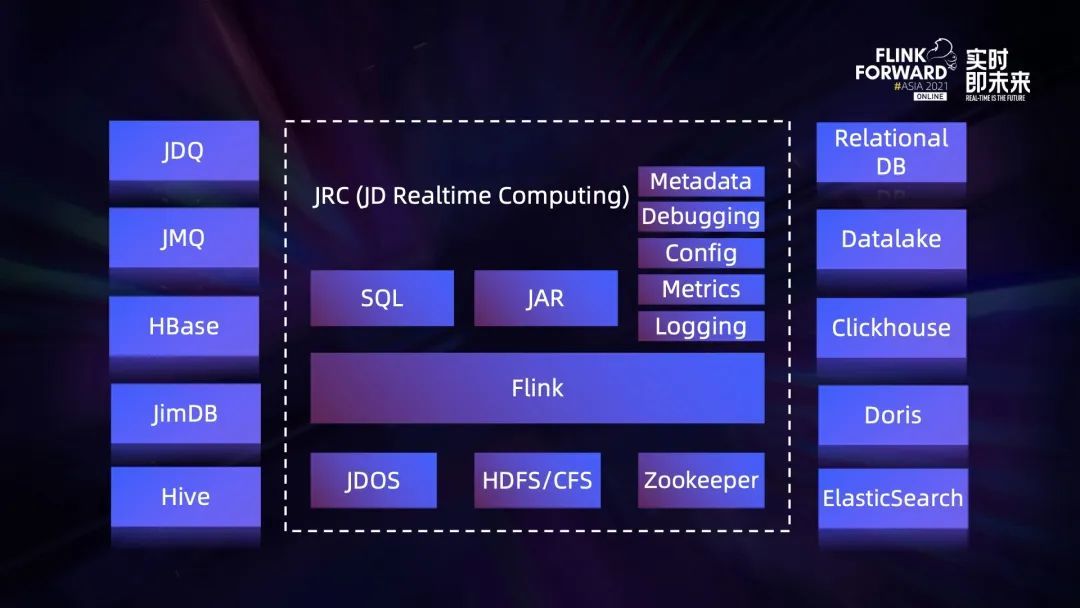
Exploration and Practice of Stream Batch Integration in JD
![[CTF] AWDP summary (WEB)](/img/4c/574742666bd8461c6f9263fd6c5dbb.png)
[CTF] AWDP summary (WEB)

Poap: the adoption entrance of NFT?

FEG founder rox:smartdefi will be the benchmark of the entire decentralized financial market
整理混乱的头文件,我用include what you use
随机推荐
If the consumer Internet is compared to a "Lake", the industrial Internet is a vast "ocean"
视频网站手绘
Database postragesq role membership
Delaying wages to force people to leave, and the layoffs of small Internet companies are a little too much!
Application and Optimization Practice of redis in vivo push platform
Win:使用 PowerShell 检查无线信号的强弱
Interesting practice of robot programming 16 synchronous positioning and map building (SLAM)
Global and Chinese market of nutrient analyzer 2022-2028: Research Report on technology, participants, trends, market size and share
Nebula Importer 数据导入实践
Take you ten days to easily complete the go micro service series (IX. link tracking)
Redis master-slave replication cluster and recovery ideas for abnormal data loss # yyds dry goods inventory #
La jeunesse sans rancune de Xi Murong
Logstash、Fluentd、Fluent Bit、Vector? How to choose the appropriate open source log collector
[wave modeling 2] three dimensional wave modeling and wave generator modeling matlab simulation
JS implementation determines whether the point is within the polygon range
Global and Chinese markets of emergency rescue vessels (errv) 2022-2028: Research Report on technology, participants, trends, market size and share
FEG founder rox:smartdefi will be the benchmark of the entire decentralized financial market
The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
LeetCode周赛 + AcWing周赛(T4/T3)分析对比
Classification of performance tests (learning summary)