当前位置:网站首页>Mlsys 2020 | fedprox: Federation optimization of heterogeneous networks
Mlsys 2020 | fedprox: Federation optimization of heterogeneous networks
2022-07-06 00:55:00 【Cyril_ KI】
Preface

subject : Federated Optimization for Heterogeneous Networks
meeting : Conference on Machine Learning and Systems 2020
Address of thesis :Federated Optimization for Heterogeneous Networks
FedAvg There is no good solution to device heterogeneity and data heterogeneity ,FedProx stay FedAvg Some improvements have been made to try to alleviate these two problems .
stay Online Learning in , In order to prevent the model from departing too far from the original model after being updated according to the new data , That is to prevent over regulation , Usually, a remainder term is added to limit the difference of model parameters before and after updating .FedProx A remainder is also introduced in , Works in a similar way .
I. FedAvg
Google Our team proposed federal learning for the first time , And the basic algorithm of Federated learning is introduced FedAvg. The general form of the problem :
The formula 1: f i ( w ) = l ( x i , y i ; w ) f_i(w)=l(x_i,y_i;w) fi(w)=l(xi,yi;w) It means the first one i i i Loss of samples , That is to minimize the average loss of all samples .
The formula 2: F k ( w ) F_k(w) Fk(w) Represents the average loss of all data in a client , f ( w ) f(w) f(w) Represents the weighted average loss of all clients under the current parameter .
It is worth noting that , If all P k P_k Pk( The first k Client data ) It is formed by randomly and evenly distributing the training samples on the client , So each of these F k ( w ) F_k(w) Fk(w) Our expectations are f ( w ) f(w) f(w). This is usually done by distributed optimization algorithms IID hypothesis : That is, the data of each client is independent and identically distributed .
FedAvg:
Simply speaking , stay FedAvg Under the framework of : In every round of communication , The server distributes global parameters to each client , Each client uses local data to train the same epoch, Then upload the gradient to the server for aggregation to form the updated parameters .
FedAvg There are two defects :
- Device heterogeneity : The communication and computing capabilities of different devices are different . stay FedAvg in , The selected clients train the same locally epoch, Although the author points out that promotion epoch It can effectively reduce the communication cost , But the bigger epoch Next , There may be a lot of equipment that can't complete the training on time . Whether it's direct drop Drop this part of the client model or directly use this part of the unfinished model to aggregate , Will have a bad impact on the convergence of the final model .
- Data heterogeneity : Data in different devices may be non independent and identically distributed . If the data is independent and identically distributed , Then the local model training epoch Larger will only accelerate the convergence of the global model ; If not identically distributed , When different equipment uses local data for training and the number of training rounds is large , The local model will deviate from the original global model .
II. FedProx
In order to alleviate the above two problems , The author of this paper proposes a new federal learning framework FedProx.FedProx Can handle heterogeneity well .
To define a :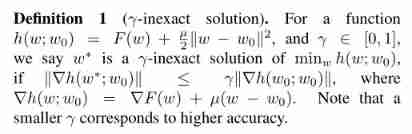
So-called γ \gamma γ inexact solution: For an objective function to be optimized h ( w ; w 0 ) h(w;w_0) h(w;w0), If there is :
∣ ∣ ∇ h ( w ∗ ; w 0 ) ∣ ∣ ≤ γ ∣ ∣ ∇ h ( w 0 ; w 0 ) ∣ ∣ ||\nabla h(w^*;w_0)|| \leq \gamma ||\nabla h(w_0;w_0)|| ∣∣∇h(w∗;w0)∣∣≤γ∣∣∇h(w0;w0)∣∣
here γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1], We said w ∗ w^* w∗ yes h h h One of the γ − \gamma- γ− Inexact solution .
For this definition , We can understand it as : The smaller the gradient, the more accurate , Because the greater the gradient , It takes more time to converge . So obviously , γ \gamma γ The smaller it is , Explain w ∗ w^* w∗ The more accurate .
We know , stay FedAvg in , equipment k k k When training locally , The objective function that needs to be minimized is :
F k ( w ) = 1 n k ∑ i ∈ P k f i ( w ) F_k(w)=\frac{1}{n_k}\sum_{i \in P_k}f_i(w) Fk(w)=nk1i∈Pk∑fi(w)
Simply speaking , Every client is an optimization loss function , This is a normal idea , Make the global model perform better on local datasets .
But if the data between devices is heterogeneous , The model obtained after optimization of each client is too different from the global model allocated by the server at the beginning , The local model will deviate from the original global model , This will slow down the convergence of the global model .
In order to effectively limit this deviation , The author of this paper proposes , equipment k k k When training locally , The following objective functions need to be minimized :
h k ( w ; w t ) = F k ( w ) + μ 2 ∣ ∣ w − w t ∣ ∣ 2 h_k(w;w^t)=F_k(w)+\frac{\mu}{2}||w-w^t||^2 hk(w;wt)=Fk(w)+2μ∣∣w−wt∣∣2
The author in FedAvg Based on the loss function , Introduced a proximal term, We can call it the proximal term . After introducing the proximal term , The model parameters obtained by the client after local training w w w It will not be associated with the initial server parameters w t w^t wt Too much deviation .
By observing the above formula, we can find , When μ = 0 \mu=0 μ=0 when ,FedProx The optimization goal of the client is similar to FedAvg Agreement .
This idea is actually very common , In machine learning , To prevent over regulation , Or to limit parameter changes , Usually, such a similar term will be added to the original loss function . For example, in online learning , We can add this item , To prevent the original model from deviating too much from the original model after online updating with new data .
FedProx Algorithm pseudo code of :
Input : Total number of clients K K K、 Number of communication rounds T T T、 μ \mu μ and γ \gamma γ、 Server initialization parameters w 0 w^0 w0, Number of selected clients N N N, The first k k k Probability of clients being selected p k p_k pk.
For every round of communication :
- The server starts with probability p k p_k pk Select a batch of clients randomly , Their collection is S t S_t St.
- The server will set the current parameters w t w^t wt Send to the selected client .
- Each selected client needs to find one w k t + 1 w_k^{t+1} wkt+1, there w k t + 1 w_k^{t+1} wkt+1 No more FedAvg According to local data SGD Optimized , It's about optimization h k ( w ; w t ) h_k(w;w^t) hk(w;wt) Later obtained γ − \gamma- γ− Inexact solution .
- Each client passes the inexact solution back to the server , The server aggregates these parameters to get the next round of initial parameters .
By observing this step, we can find ,FedProx stay FedAvg Two improvements have been made on :
- The near term is introduced , Limits model deviation due to data heterogeneity .
- An inexact solution is introduced , Each client no longer needs to train the same number of rounds , Just get an inexact solution , This effectively relieves the calculation pressure of some equipment .
III. experiment
chart 1 The influence of data heterogeneity on the convergence of the model is given :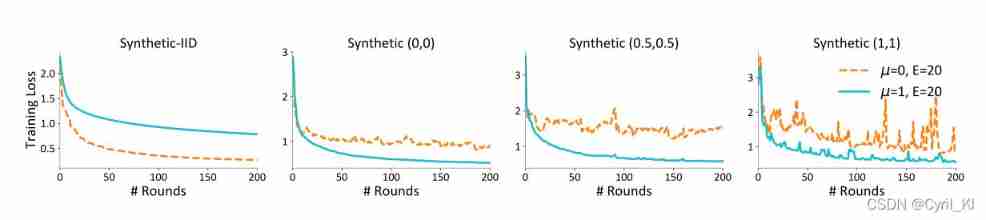
The figure above shows how the loss changes as the number of communication rounds increases , The heterogeneity of data increases from left to right , among μ = 0 \mu=0 μ=0 Express FedAvg. You can find , The stronger the heterogeneity between data , Worse convergence , But if we let μ > 0 \mu>0 μ>0, Will effectively alleviate this situation , That is, the model will converge faster .
chart 2: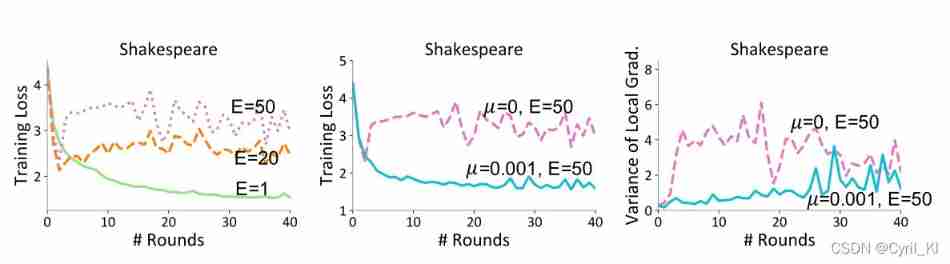
On the left :E After adding, it is necessary to μ = 0 \mu=0 μ=0 The impact of the situation . You can find , Too much local training will cause the model to deviate from the global model , Convergence slows .
Chinese : The same data set , increase μ \mu μ after , Convergence will accelerate , Because this effectively alleviates the model offset , So that FedProx The performance of depends less on E E E.
The author gives a trick: In practice , μ \mu μ It can be selected adaptively according to the current performance of the model . The simpler way is to increase when the loss increases μ \mu μ, When the loss decreases μ \mu μ.
But for γ \gamma γ, The author doesn't seem to specify how to choose , Can only go to GitHub Study the source code and then give an explanation .
IV. summary
The heterogeneity of data and devices is important to traditional FedAvg The algorithm presents a challenge , The author of this paper FedAvg On the basis of that, the paper puts forward FedProx,FedProx Compared with FedAvg There are two main differences :
- The differences in communication and computing capabilities of different devices are considered , And the inexact solution is introduced , Different equipment does not need to train the same number of rounds , Just get an inexact solution .
- The near term is introduced , In the case of heterogeneous data , It limits the deviation of the local training model from the global model .
边栏推荐
- ubantu 查看cudnn和cuda的版本
- Arduino hexapod robot
- Idea远程提交spark任务到yarn集群
- Anconda download + add Tsinghua +tensorflow installation +no module named 'tensorflow' +kernelrestart: restart failed, kernel restart failed
- Promise
- 云导DNS和知识科普以及课堂笔记
- Browser reflow and redraw
- Gartner released the prediction of eight major network security trends from 2022 to 2023. Zero trust is the starting point and regulations cover a wider range
- Five challenges of ads-npu chip architecture design
- esxi的安装和使用
猜你喜欢

Anconda download + add Tsinghua +tensorflow installation +no module named 'tensorflow' +kernelrestart: restart failed, kernel restart failed
MCU通过UART实现OTA在线升级流程
Meta AI西雅图研究负责人Luke Zettlemoyer | 万亿参数后,大模型会持续增长吗?
![[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)](/img/e4/a41fe26efe389351780b322917d721.jpg)
[groovy] compile time meta programming (compile time method interception | method interception in myasttransformation visit method)

MIT博士论文 | 使用神经符号学习的鲁棒可靠智能系统
Beginner redis
Illustrated network: the principle behind TCP three-time handshake, why can't two-time handshake?
VSphere implements virtual machine migration
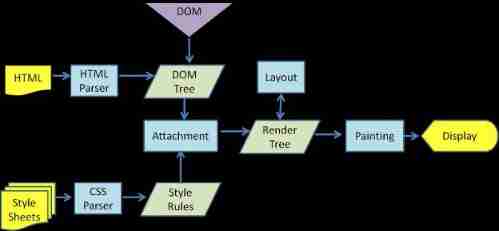
Browser reflow and redraw

KDD 2022 | EEG AI helps diagnose epilepsy
随机推荐
Exciting, 2022 open atom global open source summit registration is hot
Set data real-time update during MDK debug
[groovy] JSON string deserialization (use jsonslurper to deserialize JSON strings | construct related classes according to the map set)
【文件IO的简单实现】
Why can't mathematics give machine consciousness
Leetcode 44 Wildcard matching (2022.02.13)
Cve-2017-11882 reappearance
[simple implementation of file IO]
如何制作自己的機器人
Beginner redis
MIT doctoral thesis | robust and reliable intelligent system using neural symbol learning
1791. Find the central node of the star diagram / 1790 Can two strings be equal by performing string exchange only once
MCU通过UART实现OTA在线升级流程
golang mqtt/stomp/nats/amqp
Common API classes and exception systems
Spark获取DataFrame中列的方式--col,$,column,apply
Live broadcast system code, custom soft keyboard style: three kinds of switching: letters, numbers and punctuation
直播系统代码,自定义软键盘样式:字母、数字、标点三种切换
[groovy] JSON serialization (convert class objects to JSON strings | convert using jsonbuilder | convert using jsonoutput | format JSON strings for output)
Logstash clear sincedb_ Path upload records and retransmit log data