当前位置:网站首页>Interview assault 63: how to remove duplication in MySQL?
Interview assault 63: how to remove duplication in MySQL?
2022-07-06 17:48:00 【InfoQ】
1. Create test data
-- Create test table
drop table if exists pageview;
create table pageview(
id bigint primary key auto_increment comment ' Since the primary key ',
aid bigint not null comment ' article ID',
uid bigint not null comment '( visit ) user ID',
createtime datetime default now() comment ' Creation time '
) default charset='utf8mb4';
-- Add test data
insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(1,1);
insert into pageview(aid,uid) values(2,1);
insert into pageview(aid,uid) values(2,2);
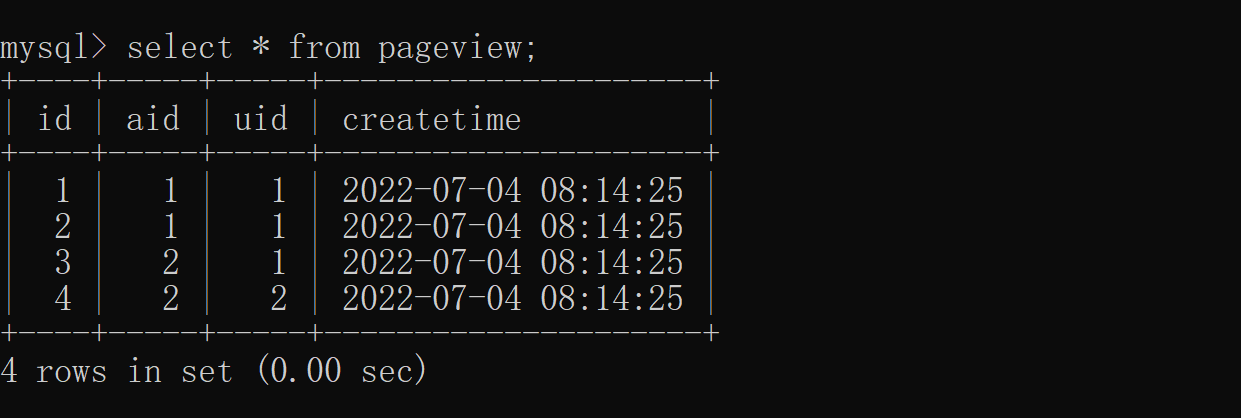
2.distinct Use
SELECT DISTINCT column_name,column_name FROM table_name;
2.1 Separate the heavy ones

2.2 More than one, more than one

2.3 Aggregate functions + duplicate removal
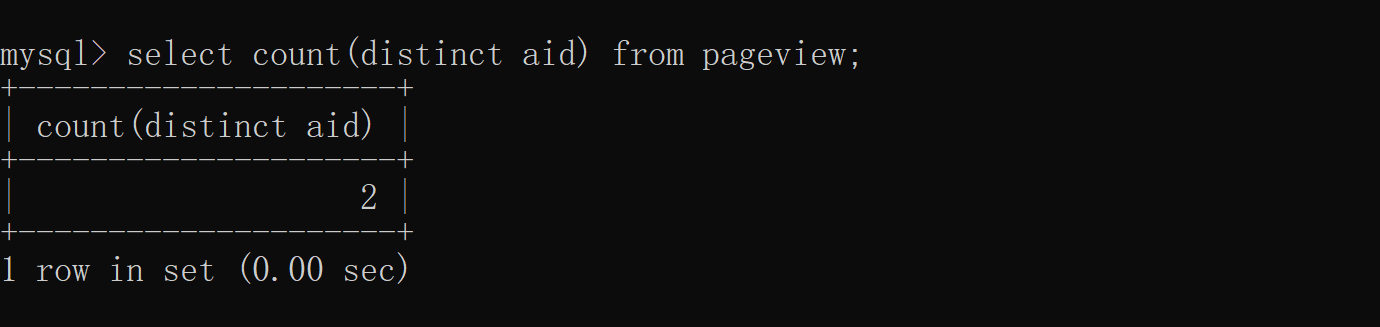
3.group by Use
SELECT column_name,column_name FROM table_name
WHERE column_name operator value
GROUP BY column_name
3.1 Separate the heavy ones
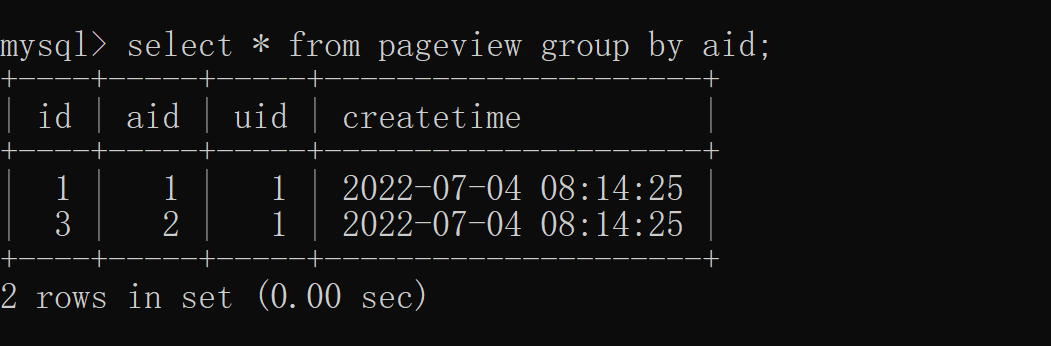
3.2 More than one, more than one
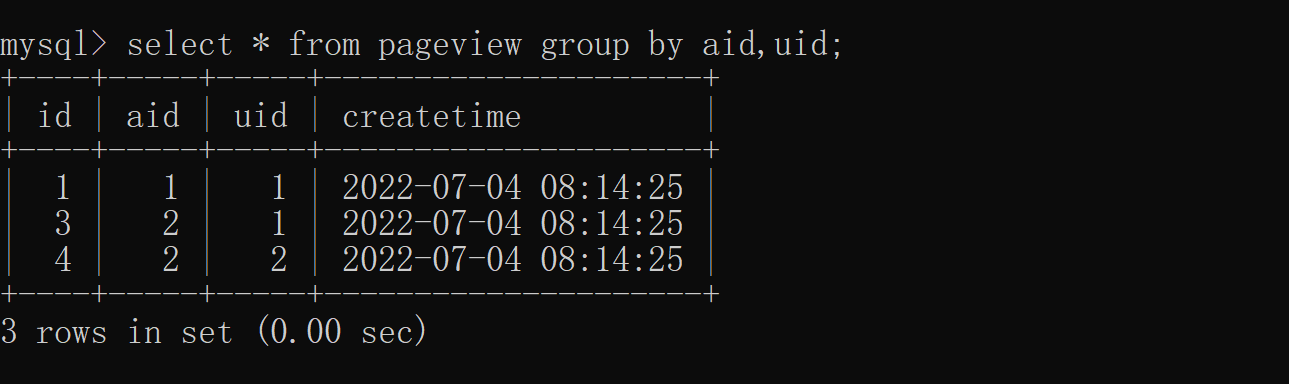
3.3 Aggregate functions + group by
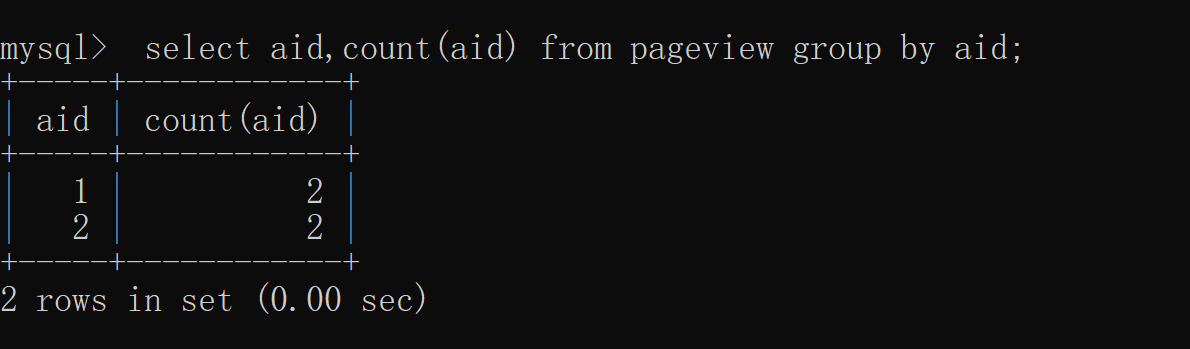
4.distinct and group by The difference between

difference 1: The query result set is different
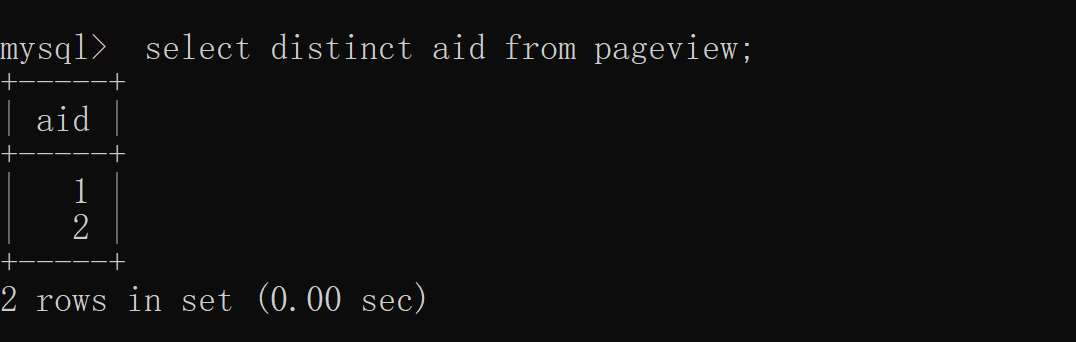

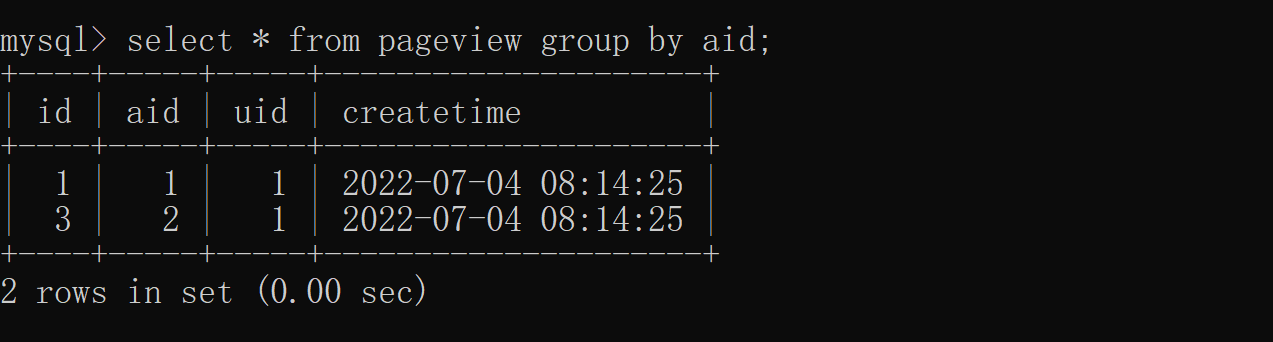
difference 2: Different business scenarios
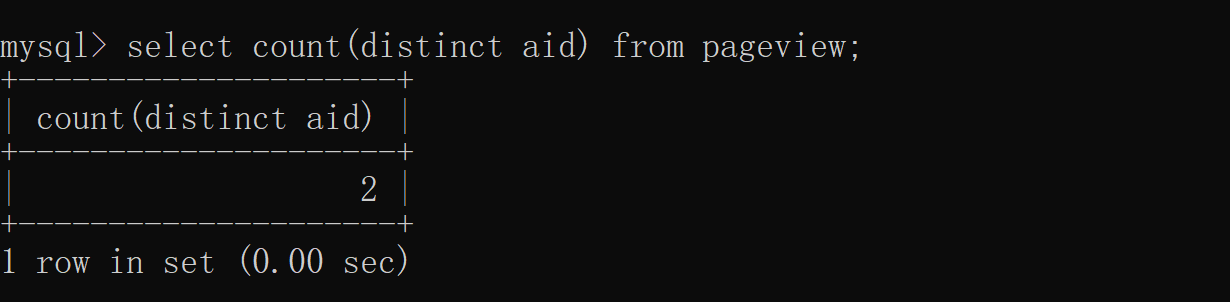
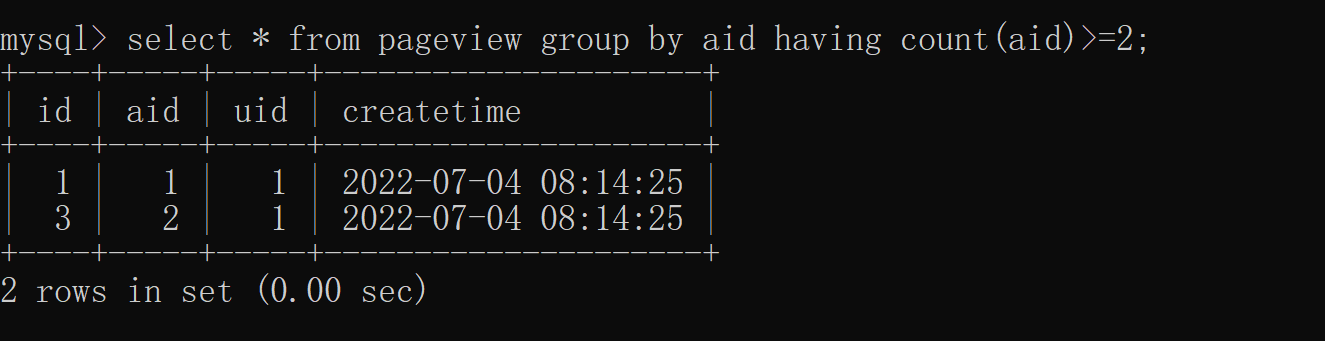
difference 3: Different performance
summary
Reference resources & Acknowledgement
边栏推荐
- Example of batch update statement combining update and inner join in SQL Server
- Development and practice of lightweight planning service tools
- Summary of study notes for 2022 soft exam information security engineer preparation
- connection reset by peer
- 面试突击62:group by 有哪些注意事项?
- C# NanoFramework 点灯和按键 之 ESP32
- [getting started with MySQL] fourth, explore operators in MySQL with Kiko
- TCP connection is more than communicating with TCP protocol
- Pyspark operator processing spatial data full parsing (5): how to use spatial operation interface in pyspark
- Reppoints: advanced order of deformable convolution
猜你喜欢
Pytorch extract middle layer features?
Concept and basic knowledge of network layering

The problem of "syntax error" when uipath executes insert statement is solved
Vscode matches and replaces the brackets

2022年大厂Android面试题汇总(二)(含答案)

yarn : 无法加载文件 D:\ProgramFiles\nodejs\yarn.ps1,因为在此系统上禁止运行脚本

Unity particle special effects series - treasure chest of shining stars

C # nanoframework lighting and key esp32

历史上的今天:Google 之母出生;同一天诞生的两位图灵奖先驱
C# NanoFramework 点灯和按键 之 ESP32
随机推荐
Uipath browser performs actions in the new tab
C WinForm series button easy to use
Essai de pénétration du Code à distance - essai du module b
Error: Publish of Process project to Orchestrator failed. The operation has timed out.
Pyspark operator processing spatial data full parsing (4): let's talk about spatial operations first
【MySQL入门】第一话 · 初入“数据库”大陆
10 advanced concepts that must be understood in learning SQL
yarn : 无法加载文件 D:\ProgramFiles\nodejs\yarn.ps1,因为在此系统上禁止运行脚本
Summary of Android interview questions of Dachang in 2022 (I) (including answers)
MySQL报错解决
Selenium test of automatic answer runs directly in the browser, just like real users.
Debug xv6
Unity粒子特效系列-闪星星的宝箱
BearPi-HM_ Nano development environment
Chrome prompts the solution of "your company management" (the startup page is bound to the company's official website and cannot be modified)
面试突击63:MySQL 中如何去重?
The art of Engineering (2): the transformation from general type to specific type needs to be tested for legitimacy
EasyCVR电子地图中设备播放器loading样式的居中对齐优化
Run xv6 system
一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升