当前位置:网站首页>Interpretation of Flink source code (II): Interpretation of jobgraph source code
Interpretation of Flink source code (II): Interpretation of jobgraph source code
2022-07-06 17:28:00 【Stray_ Lambs】
Catalog
JobGraph The generation process
JobGraph Source code interpretation
Last time when it comes to ,StreamGraph Which is generated on the client , And is generated Node Nodes and Edge, Mainly through StreamAPI Generate , Represents the topology , This time I will tell you about JobGraph Generation ( With Yarn Cluster pattern ).
First ,JobGraph Is based on StreamGraph To optimize ( Including settings Checkpoint、slot Group strategy , Memory ratio, etc ), The most important thing is Transfer multiple qualified StreamNode link chain Together as a node , Reduce the serialization required for the flow of data between nodes 、 Deserialization 、 Transmission consumption .
Just a quick note JobGraph The process of , Will meet the conditions Operator Operators are combined into ChainableOperator, Generate corresponding JobVertex、InermediateDataSet and JobEdge etc. , And through JobEdge Connected to the IntermediateDataSet and JobVertex, This is just to generate the logical structure of coarse-grained user code ( Such as data structure ), The real data is generated later Task Time structured ResultSubPartition and InputGate Will interact with the user's physical data .
JobGraph The core object
1、JobVertex
stay StreamGraph in , Each operator corresponds to a StreamNode. stay JobGraph in , Eligible multiple StreamNode Will merge into one JobVertex, That is, a JobVertex Contains one or more operators .
2、JobEdge
stay StreamGraph in ,StreamNode The connection between StreamEdge Express , And in the JobGraph in ,JobVertex The connection between JobEdge Express .JobEdge amount to JobGraph Data flow channel in , The upstream data is IntermediateDataSet,IntermediateDataSet yes JobEdge Input dataset for , Downstream consumers are JobVertex.
JobEdge Stored the target JobVertex Information , No source JobVertex Information , But the source is stored IntermediateDataSet.
3、IntermediateDataSet
IntermediateDataSet Is by an operator 、 The data set produced by the source or any intermediate operation , Used to represent JobVertex Output .

JobGraph The generation process
JobGraph The generation entry of is StreamingJobGraphGenerator.createJobGraph(this, jobID), The final call StreamingJobGraphGenerator.createJobGraph().
Entry function
Procedure of entry function call :executeAsync( Generate YarnJobClusterExecutorFactory)->execute( Generate JobGraph, And issue deployment tasks to the cluster )->getJobGraph( according to Pipeline Type generation offline planTranslator Or in real time streamGraphTranslator)->createJobGraph( Generate StreamingJobGraphGenerator Instance and create JobGraph)
@Internal
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
// call DefaultExecutorServiceLoader Generate YarnJobClusterExecutorFactory
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
// Generate YarnJobClusterExecutor Call to generate JobGraph Then submit the task resource application to the cluster
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration) //new YarnJobClusterExecutor
.execute(streamGraph, configuration, userClassloader);
........
}
@Override
public CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration, @Nonnull final ClassLoader userCodeClassloader) throws Exception {
// Generate JobGraph
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
try (final ClusterDescriptor<ClusterID> clusterDescriptor = clusterClientFactory.createClusterDescriptor(configuration)) {
final ExecutionConfigAccessor configAccessor = ExecutionConfigAccessor.fromConfiguration(configuration);
final ClusterSpecification clusterSpecification = clusterClientFactory.getClusterSpecification(configuration);
// Start publishing deployment tasks to the cluster
final ClusterClientProvider<ClusterID> clusterClientProvider = clusterDescriptor
.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
// Start the asynchronous callable thread , Return to the deployment task completed
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}
}
public static JobGraph getJobGraph(
Pipeline pipeline,
Configuration optimizerConfiguration,
int defaultParallelism) {
// according to Pipeline Type generation offline planTranslator Or in real time streamGraphTranslator
FlinkPipelineTranslator pipelineTranslator = getPipelineTranslator(pipeline);
return pipelineTranslator.translateToJobGraph(pipeline,
optimizerConfiguration,
defaultParallelism);
}
// Generate StreamingJobGraphGenerator Instance and create JobGraph and
public static JobGraph createJobGraph(StreamGraph streamGraph, @Nullable JobID jobID) {
return new StreamingJobGraphGenerator(streamGraph, jobID).createJobGraph();
}createJobGraph function
stay StreamingJobGraphGenerator In the generator , Basically, all member variables are used to help generate the final JobGraph.
among createJobGraph The process of a function : First, generate a unique for all nodes hash id, This hash function can be defined by the user , If the node has not changed in multiple submissions ( Such as group 、 Concurrency 、 The relationship between upstream and downstream, etc ), So this hash id It won't change , This is mainly for Fault recovery . And then in chaining Handle 、 Generate JobVetex、JobEdge etc. , Then write various configuration information, such as cache 、checkpoints etc. .
public class StreamingJobGraphGenerator {
private StreamGraph streamGraph;
private JobGraph jobGraph;
// id -> JobVertex
private Map<Integer, JobVertex> jobVertices;
// Already built JobVertex Of id aggregate
private Collection<Integer> builtVertices;
// Physical edge set ( Exclude chain Inner edge ), Sort by creation order
private List<StreamEdge> physicalEdgesInOrder;
// preservation chain Information , It is used to build OperatorChain,startNodeId -> (currentNodeId -> StreamConfig)
private Map<Integer, Map<Integer, StreamConfig>> chainedConfigs;
// Configuration information of all nodes ,id -> StreamConfig
private Map<Integer, StreamConfig> vertexConfigs;
// Save the name of each node ,id -> chainedName
private Map<Integer, String> chainedNames;
// Constructors , Only StreamGraph
public StreamingJobGraphGenerator(StreamGraph streamGraph) {
this.streamGraph = streamGraph;
}
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices start immediately
// First step :
// Not batch The default mode is EAGER
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
// Generate deterministic hashes for the nodes in order to identify them across
// submission if they didn't change.
// The second step Determine the node hash value
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
// The third step Determine the node user-defined userHash value
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
// Step four Build links
setChaining(hashes, legacyHashes);
// Step five JobVertex Corresponding input InphysicalEdge Set to this physical StreamEdge
// Save all JobEdge Time corresponds to StreamEdge
setPhysicalEdges();
// Step 6 set whether it is in a slot perform task
// Set up slot Group strategy
setSlotSharingAndCoLocation();
// Set the cache size
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
// To configure checkpoint attribute
configureCheckpointing();
// To configure savepoint attribute
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
// Configure user customization files
JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
// Traverse and cache all sourceNode And generate the following as checkpoint Of SourceCoordinatorProvider
final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
final Collection<OperatorChainInfo> initialEntryPoints = new ArrayList<>(chainEntryPoints.values());
// iterate over a copy of the values, because this map gets concurrently modified
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}Explain the above steps :
First step :JobGraph Boot mode
- EAGER: All nodes start immediately
- LAZY_FROM_SOURCES: Lazy load mode , Default mode , Restart when all input conditions are ready
The second step 、 The third step : Determine the node hash value
if Flink The mission failed , Each operator is able to start from checkpoint To restore to the state before failure , The basis for recovery is JobVertexID(hash value ) Do state recovery . The same task requires the operator when recovering hash The value remains the same , Therefore, the corresponding state can be obtained for recovery .
among ,Set<Integer> visited = new HashSet<>(); Records have been generated hash The value of the node ,Queue<StreamNode> remaining = new ArrayDeque<>(); The remaining records have not been generated hash The value of the node .
Below while The cycle is Breadth traversal , Build the entire node hash value .currentNode = remaining.poll() Get to build hash The value of the node ,generateNodeHash(currentNode, hashFunction, hashes,streamGraph.isChainingEnabled(), streamGraph) production hash The method of value , Below for loop , Get all the output nodes of this node , And add remaining and visited Collection , Traverse... Again , until remaining No value .
Step four : Build links
Before building , First judge whether it can be connected .isChainable Function to judge .
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
return downStreamVertex.getInEdges().size() == 1
&& isChainableInput(edge, streamGraph);
}
private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& edge.getShuffleMode() != ShuffleMode.BATCH
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled())) {
return false;
}share 9 Conditions :
- The downstream node has only one input
- The downstream node's operator is not null
- The upstream node's operator is not null
- The upstream and downstream nodes are in a slot sharing group
- The connection strategy of downstream nodes is ALWAYS
- The connection strategy of the upstream node is HEAD perhaps ALWAYS
- edge The partition function of is ForwardPartitioner Example
- The parallelism of upstream and downstream nodes is equal
- You can connect nodes
The process of linking :
/**
* Sets up task chains from the source {@link StreamNode} instances.
*
* <p>This will recursively create all {@link JobVertex} instances.
*/
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
final Collection<OperatorChainInfo> initialEntryPoints = new ArrayList<>(chainEntryPoints.values());
// iterate over a copy of the values, because this map gets concurrently modified
// Loop the link information of all operators , Create operator chains
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // Operator from position 1 Start ,0 Represents the input of the source
info,
chainEntryPoints);
}
}Get into setChain After the function , Call again createChain Function to generate concrete . The function parameters sourceNodeId and currentNodeId, If currentNodeId The output edge of is a non merging edge , Then all of them StreamNode Will build JobGraph The vertices ,currentNodeId The edges of will build JobGraph The edge of .
- transitiveOutEdges: Get edges that cannot be merged , That is, how to build it at the beginning JobGraph The edge of , That is to get filter->keyBy edge , That is, the problem in the above figure 3.
- chainableOutputs: Edges to be merged , for example source->filter edge
- nonChainableOutputs: Edges that cannot be merged , for example filter->keyBy edge
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
Integer startNodeId = chainInfo.getStartNodeId();
// Traverse the unsolved streamNode(createJobVertex after builtVertices Will join the current nodeId Avoid subsequent repeated calls )
if (!builtVertices.contains(startNodeId)) {
// must not chain Of edges
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
// At present streamNode There could be multiple outEdges
for (StreamEdge outEdge : currentNode.getOutEdges()) {
// Judge whether you can chain
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
// If above streamNode But the chain continues to call circularly createChain
// Get the next streamNodeId Repeat the above steps and addAll All non chainable edge Used for the back connect Until current streamNode Of outEdge Not chainable
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(chainable.getTargetId(), chainIndex + 1, chainInfo, chainEntryPoints));
}
// Come here There are two cases :
// One : At present streamNode Of outEdge Not chainable But downstream streamNode
// Two : At present streamNode Of outEdge Not chainable Downstream none streamNode, Belong to end stream node
// 3、 ... and : At present streamNode Of outEdge Not chainable The downstream has been created JobVertex(transitiveOutEdges.addAll(createChain....) Loop call completed )
for (StreamEdge nonChainable : nonChainableOutputs) {
// Entering here belongs to outEdge Not chainable But downstream streamNode, Cache it first , Use the next streamNode Continue to call createChain, And initialize chainIndex by 1( Because next streamNode It's a chain head
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
// The code came here for the first time to explain createChain Traverse to the last streamNode, So start here ( reverse ) establish JobVertex
// First, traverse out chainableOutputs and merge All in the current chain StreamNode Resources for ( such as cpuCores,HeapMemory etc. )
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId = chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
// Cache all inputFormat( such as jdbcinputformat,hbaseInputFormat etc. )
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
// ditto
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
// If it belongs to the starting node, it generates JobVertex, It mainly includes the following three steps
//1: establish JobVertex( If it is inputFormat perhaps outputFormat The type is InputOutputFormatVertex)
//2: Set parallelism , Resources and other attributes
//3: Cache into StreamingJobGraphGenerator in
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs, chainInfo.getChainedSources());
// Follow the above generation JobVertex equally Only current operator yes head When To generate IntermediateDataSet and JobEdge And connected with the downstream
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
// Traverse out the unlinkable edge, Generate IntermediateDataSet and JobEdge And follow the current currentNodeId Connected to a
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
config.setOutEdgesInOrder(transitiveOutEdges);
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}stay 89 Row or so , There is one connect function , Where link JobVertex The logic of .
private void connect(Integer headOfChain, StreamEdge edge) {
....
ResultPartitionType resultPartitionType;
// according to outEdge Of shuffleMode Types generate different ResultPartition
//ResultPartition The type of determines the flow or batch mode in the subsequent data interaction and whether it can be used as backpressure and based on Credit Communication mode of ( Analysis will be done later )
// The default is UNDEFINED, This will be done by partitioner The type and GlobalDataExchangeMode decision
switch (edge.getShuffleMode()) {
case PIPELINED:
resultPartitionType = ResultPartitionType.PIPELINED_BOUNDED;
break;
case BATCH:
resultPartitionType = ResultPartitionType.BLOCKING;
break;
case UNDEFINED:
resultPartitionType = determineResultPartitionType(partitioner);
break;
default:
throw new UnsupportedOperationException("Data exchange mode " +
edge.getShuffleMode() + " is not supported yet.");
}
checkAndResetBufferTimeout(resultPartitionType, edge);
// establish JobEdge, Upstream IntermediateDataSet, Downstream is JobVertex
//IntermediateDataSet Just maintain its producer and consumers Queues
JobEdge jobEdge;
if (isPointwisePartitioner(partitioner)) {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
resultPartitionType);
} else {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL,
resultPartitionType);
}
// set strategy name so that web interface can show it.
jobEdge.setShipStrategyName(partitioner.toString());
if (LOG.isDebugEnabled()) {
LOG.debug("CONNECTED: {} - {} -> {}", partitioner.getClass().getSimpleName(),
headOfChain, downStreamVertexID);
}
}
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType) {
IntermediateDataSet dataSet = input.createAndAddResultDataSet(partitionType);
// establish JobEdge
JobEdge edge = new JobEdge(dataSet, this, distPattern);
this.inputs.add(edge);
dataSet.addConsumer(edge);
return edge;
}
public IntermediateDataSet createAndAddResultDataSet(
IntermediateDataSetID id,
ResultPartitionType partitionType) {
// Just maintain the current JobVertex all outEdge and ResultPartitionType
IntermediateDataSet result = new IntermediateDataSet(id, partitionType, this);
// We're creating JobVertex According to results.size Generate the same number of IntermediateResult
this.results.add(result);
return result;
}Code that groups all edges
for (StreamEdge outEdge : streamGraph.getStreamNode(currentNodeId).getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
Recursively call , Find the edges that can be merged , A merger .
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));
}
If edges cannot be merged , There are output nodes , Then continue to call recursively , Until the end of the whole topology .
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);
}
The specific process is : above transitiveOutEdges.add(nonChainable); Is to find the edge that cannot be merged , That is from startNodeId To currentNodeId, All edges in the middle can be merged , You can construct a new JobGraph node . The output node of the edge that cannot be merged , take Do it again startNodeId node , Traverse down . From the above two recursions, we can find , structure JobGraph In fact, it is built from the back .
then obtain JobGraph Merged in nodes StreamNode Corresponding hash value , These nodes are combined to build a vertex .
List<Tuple2<byte[], byte[]>> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
byte[] primaryHashBytes = hashes.get(currentNodeId);
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
next Get the chain name , If edges or topology tail nodes cannot be merged , Then the name is interrupted .
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
The concrete is Whether to create or merge nodes depends on equals(startNodeId) Function judgement .
If the current node is the start node , It shows that recursion has come back , All downstream nodes to be connected have obtained , be All on this connection StreamNode Nodes should jointly build a new JobGraph node , therefore JobGraph The node of needs to save these StreamNode Of hash value . If not , shows The current node is an internal node , Initialize the configuration directly , No need to build JobGraph node .
StreamConfig config = currentNodeId.equals(startNodeId)? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes): new StreamConfig(new Configuration());
And then put StreamNode The information of the node is transferred to JobGraph in
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
If it is JobGraph The node of , Description encountered an edge that cannot be merged , Build JobGraph The edge of . Different ways to build edges , And take the edge as the downstream JobGraph Input side of this.inputs.add(edge);
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
if (partitioner instanceof ForwardPartitioner || partitioner instanceof RescalePartitioner) {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
ResultPartitionType.PIPELINED_BOUNDED);
} else {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL,
ResultPartitionType.PIPELINED_BOUNDED);
}
If not JobGraph The node of , Then put the SteamNode Information about , Put in startNodeId Collection , Finally put JobGraph Node config in , And every node hash Value is unique , Put it into the configuration of each node .
The specific process of vertex construction
By building vertices, you are putting StreamNode(source,filter) Combine into JobVertex(source->filter) The process of . Among them, construction JobVertex The main thing is that the new node needs to get the corresponding StreamNode Configuration information , Combine into a new node . and except StartNode, Other StreamNode My mission is chainedConfigs in .
// obtain StreamNode
StreamNode streamNode = streamGraph.getStreamNode(streamNodeId);
// Get corresponding hash value
byte[] hash = hashes.get(streamNodeId);
if (hash == null) {
throw new IllegalStateException("Cannot find node hash. " +
"Did you generate them before calling this method?");
}
// initialization
JobVertexID jobVertexId = new JobVertexID(hash);
// Initialize user-defined hash
List<JobVertexID> legacyJobVertexIds = new ArrayList<>(legacyHashes.size());
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
hash = legacyHash.get(streamNodeId);
if (null != hash) {
legacyJobVertexIds.add(new JobVertexID(hash));
}
}
// Get merged StreamNode Corresponding hash Value and corresponding user-defined hash value
List<Tuple2<byte[], byte[]>> chainedOperators = chainedOperatorHashes.get(streamNodeId);
List<OperatorID> chainedOperatorVertexIds = new ArrayList<>();
List<OperatorID> userDefinedChainedOperatorVertexIds = new ArrayList<>();
if (chainedOperators != null) {
for (Tuple2<byte[], byte[]> chainedOperator : chainedOperators) {
chainedOperatorVertexIds.add(new OperatorID(chainedOperator.f0));
userDefinedChainedOperatorVertexIds.add(chainedOperator.f1 != null ? new OperatorID(chainedOperator.f1) : null);
}
}
structure JobVertex
if (streamNode.getInputFormat() != null) {
jobVertex = new InputFormatVertex(
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
TaskConfig taskConfig = new TaskConfig(jobVertex.getConfiguration());
taskConfig.setStubWrapper(new UserCodeObjectWrapper<Object>(streamNode.getInputFormat()));
} else {
jobVertex = new JobVertex(
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
}
...
Set the work content of this node
jobVertex.setInvokableClass(streamNode.getJobVertexClass());
// Join in JobGraph
jobVertices.put(streamNodeId, jobVertex);
builtVertices.add(streamNodeId);
jobGraph.addVertex(jobVertex);
other StreamNode The task of .
Map<Integer, StreamConfig> chainedConfs = chainedConfigs.get(startNodeId);
if (chainedConfs == null) {
chainedConfigs.put(startNodeId, new HashMap<Integer, StreamConfig>());
}
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
structure JobGraph The process of the side of
The constructed edge is placed in the downstream vertex inputs in , The destination node of the edge is JobVertex target, however source nevertheless IntermediateDataSet, And it is headVertex Produced , So the process is :headVertex->IntermediateDataSet->target.
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType) {
IntermediateDataSet dataSet = input.createAndAddResultDataSet(partitionType);
JobEdge edge = new JobEdge(dataSet, this, distPattern);
this.inputs.add(edge);
dataSet.addConsumer(edge);
return edge;
}
Constructor of edges .
public JobEdge(IntermediateDataSet source, JobVertex target, DistributionPattern distributionPattern) {
if (source == null || target == null || distributionPattern == null) {
throw new NullPointerException();
}
this.target = target;
this.distributionPattern = distributionPattern;
this.source = source;
this.sourceId = source.getId();
}
Last , The conclusion is :StreamNode Turn into JobVertex,StreamEdge Turn into JobEdge,JobEdge and JobVertex Create between IntermediateDataSet To connect . The key point is to integrate multiple SteamNode chain Become a JobVertex The process of .
Reference resources
flink Of JobGraph Generate source code analysis _ A blog to pick up eggshells with you -CSDN Blog
边栏推荐
- 04 products and promotion developed by individuals - data push tool
- Garbage first of JVM garbage collector
- 8086 segmentation technology
- 02个人研发的产品及推广-短信平台
- Only learning C can live up to expectations top2 P1 variable
- Basic knowledge of assembly language
- 03个人研发的产品及推广-计划服务配置器V3.0
- Display picture of DataGridView cell in C WinForm
- 【逆向】脱壳后修复IAT并关闭ASLR
- 07 personal R & D products and promotion - human resources information management system
猜你喜欢
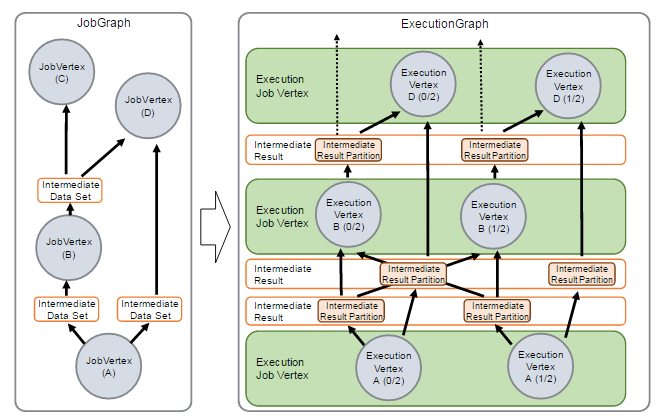
Interpretation of Flink source code (III): Interpretation of executiongraph source code
Flink 解析(一):基础概念解析
![[reverse intermediate] eager to try](/img/5a/568533850ddfd1c41117da0df50e20.png)
[reverse intermediate] eager to try
案例:检查空字段【注解+反射+自定义异常】
PySpark算子处理空间数据全解析(4): 先说说空间运算
JUnit unit test

肖申克的救赎有感
Idea breakpoint debugging skills, multiple dynamic diagram package teaching package meeting.
Development and practice of lightweight planning service tools
06 products and promotion developed by individuals - code statistical tools
随机推荐
[VNCTF 2022]ezmath wp
【逆向】脱壳后修复IAT并关闭ASLR
Programmer orientation problem solving methodology
À propos de l'utilisation intelligente du flux et de la carte
基于Infragistics.Document.Excel导出表格的类
学习投资大师的智慧
mysql高級(索引,視圖,存儲過程,函數,修改密碼)
当前系统缺少NTFS格式转换器(convert.exe)
基于LNMP部署flask项目
06 products and promotion developed by individuals - code statistical tools
CentOS7上Redis安装
Flink源码解读(二):JobGraph源码解读
JVM 垃圾回收器之Serial SerialOld ParNew
List set data removal (list.sublist.clear)
暑假刷题嗷嗷嗷嗷
肖申克的救赎有感
05个人研发的产品及推广-数据同步工具
程序员定位解决问题方法论
Only learning C can live up to expectations Top1 environment configuration
03 products and promotion developed by individuals - plan service configurator v3.0