当前位置:网站首页>[PaddleSeg源码阅读] PaddleSeg Validation 中添加 Boundary IoU的计算(1)——val.py文件细节提示
[PaddleSeg源码阅读] PaddleSeg Validation 中添加 Boundary IoU的计算(1)——val.py文件细节提示
2022-07-07 16:02:00 【氵文大师】
上一篇折腾了boundary IoU的计算方式,这篇说一下PaddleSeg 怎么添加 Boundary IoU 做 Val,训练和infer都差不多,hxdm自己踩坑吧
首先整个 PaddleSeg 精简版:
.travis.yml
.style.yapf
.pre-commit-config.yaml
.gitignore
.copyright.hook
LICENSE
README.md
README_CN.md
requirements.txt
export.py # 删不删都行,这个用来导出静态图模型文件的
setup.py # 这是用来安装 PaddleSeg 的,删了吧
benchmark
deploy
docs
EISeg # 基于飞桨开发的一个高效智能的交互式分割标注软件
slim
test_tipc # 飞桨训推一体认证 (Training and Inference Pipeline Certification(TIPC)) 信息和测试工具
tests
如果只是跑训练和推理,以上都可以直接删掉
contrib 就是一些其他功能,比如 matting、PPHumanSeg 之类的,可删
configs 嘛,就是那堆配置文件,懂得都懂
tools,里边一些常用的工具,标注啊,标注格式转化啊之类的,之后不想写轮子,就从这里找找(这是百宝箱)
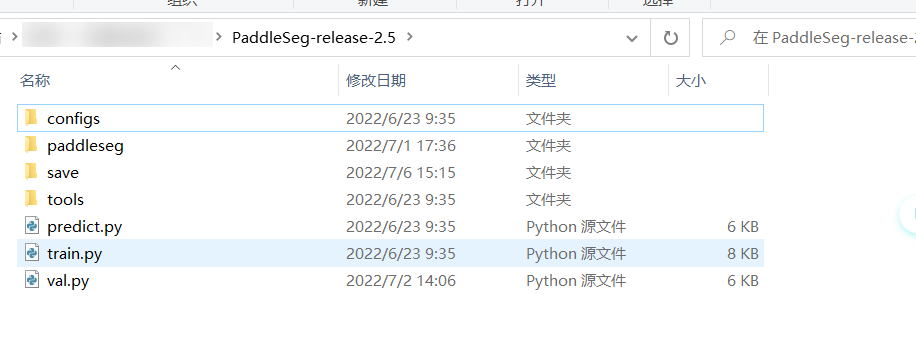
以上便是我的 PaddleSeg 精简版,
val.py 文件
没啥可看的,就两句代码
# 在这里直接 数据类 实例化
val_dataset = cfg.val_dataset
# 在这里直接 model 实例化
model = cfg.model
这里为啥直接实例化呢? 明明就是赋值了一个属性啊,其实单步调试的话,可以看到,他其实是给属性加了一个装饰器 @property
@property
def val_dataset(self) -> paddle.io.Dataset:
_val_dataset = self.val_dataset_config
if not _val_dataset:
return None
return self._load_object(_val_dataset)
@property
def model(self) -> paddle.nn.Layer:
model_cfg = self.dic.get('model').copy()
if not model_cfg:
raise RuntimeError('No model specified in the configuration file.')
if not 'num_classes' in model_cfg:
......
if not self._model:
self._model = self._load_object(model_cfg)
return self._model
看到了吗,有个 self._load_object 函数,所有的类都是通过该方法来加载(实例化)的
顺手看看这个方法(希望老铁们自行阅读一下):
def _load_object(self, cfg: dict) -> Any:
cfg = cfg.copy()
if 'type' not in cfg:
raise RuntimeError('No object information in {}.'.format(cfg))
component = self._load_component(cfg.pop('type'))
# 分界线往上是搞定类名
# ----------------- 这里是分界线 -----------------
# 分界线往下是搞定参数字典
params = {
}
for key, val in cfg.items():
if self._is_meta_type(val):
params[key] = self._load_object(val)
elif isinstance(val, list):
params[key] = [
self._load_object(item)
if self._is_meta_type(item) else item for item in val
]
else:
params[key] = val
# 将config中的类和参数拿出来之后,在return这一步返回对象
return component(**params)
里边还有一个 _is_meta_type 方法,猜一下意思呗,就是是不是可以实例化的判断
点开这个方法看看:
def _is_meta_type(self, item: Any) -> bool:
return isinstance(item, dict) and 'type' in item
如果是个字典,并且有 type 属性,在 PaddleSeg 的 Config 这个架构中,认为该类可以实例化
OK,现在不断的递归去看源码,现在咱们跳回去,看看 sellf._load_object 中 self._load_component 是怎么把那个类的名字给拿出来的
def _load_component(self, com_name: str) -> Any:
com_list = [
manager.MODELS, manager.BACKBONES, manager.DATASETS,
manager.TRANSFORMS, manager.LOSSES
]
for com in com_list:
if com_name in com.components_dict:
return com[com_name]
else:
raise RuntimeError(
'The specified component was not found {}.'.format(com_name))
看到这里,我相信诸位如果看过我的这篇博客,那么一定会有一种豁然开朗的感觉
[PaddleSeg 源码阅读] PaddleSeg 自定义数据类
这篇博客的结尾:
manager.MODELS
manager.BACKBONES
manager.DATASETS
manager.TRANSFORMS
manager.LOSSES
展示了这几个组件,我是这么认为的,PaddleSeg 将常用的组件做了抽象,直接抽象为 模型类,Backbone骨干网络类,数据集类,图片 Transform类 和 损失函数类
抽象为类的,则需要添加对应的装饰器,比如添加自定义类,需要这个装饰器:
@manager.DATASETS.add_component
看那个英语 .add_component 就是添加组件的意思,所以在 _load_component 的源码中,
for com in com_list:
if com_name in com.components_dict:
return com[com_name]
去看 com_name 是否在 manager.MODELS、manager.BACKBONES、manager.DATASETS、manager.TRANSFORMS和manager.LOSSES这几类的组件中
如果都不在,则raise这错:
raise RuntimeError(
'The specified component was not found {}.'.format(com_name))
“这个组件没有找到”
这里再插一句,像metrics那些指标(比如 IoU, acc 之类的),他们只是函数,不是类,所以不需要使用.add_component 来进行注册
(这一句是为了之后使用 Boundary IoU 进行铺垫)
差不多了吧,这篇博客从这两句:
val_dataset = cfg.val_dataset
model = cfg.model
引出了这么多
诸位自己总结一下,发到评论区
边栏推荐
- Tips of this week 135: test the contract instead of implementation
- Import requirements in batches during Yolo training Txt
- [principles and technologies of network attack and Defense] Chapter 3: network reconnaissance technology
- Show progress bar above window
- 2022年理财有哪些产品?哪些适合新手?
- 利用七种方法对一个文件夹里面的所有图像进行图像增强实战
- Youth experience and career development
- Sanxian Guidong JS game source code
- 自动化测试:Robot FrameWork框架大家都想知道的实用技巧
- 开发一个小程序商城需要多少钱?
猜你喜欢
Win11C盘满了怎么清理?Win11清理C盘的方法
Alertdialog create dialog
Introduction to OTA technology of Internet of things
![[principle and technology of network attack and Defense] Chapter 1: Introduction](/img/d0/f33447e46ab405c668eef820a8f9fb.png)
[principle and technology of network attack and Defense] Chapter 1: Introduction
Supplementary instructions to relevant rules of online competition
Click on the top of today's headline app to navigate in the middle
数学分析_笔记_第11章:Fourier级数
USB通信协议深入理解

Sanxian Guidong JS game source code
yolo训练过程中批量导入requirments.txt中所需要的包
随机推荐
[4500 word summary] a complete set of skills that a software testing engineer needs to master
Mobile app takeout ordering personal center page
Chapter 2 build CRM project development environment (database design)
SD_DATA_RECEIVE_SHIFT_REGISTER
Functions and usage of tabhost tab
Personal best practice demo sharing of enum + validation
[trusted computing] Lesson 13: TPM extended authorization and key management
元宇宙带来的创意性改变
数字化转型的主要工作
mui侧边导航锚点定位js特效
Functions and usage of serachview
基于RGB图像阈值分割并利用滑动调节阈值
[OKR target management] value analysis
仿今日头条APP顶部点击可居中导航
Please insert the disk into "U disk (H)" & unable to access the disk structure is damaged and cannot be read
Audio Device Strategy 音频设备输出、输入 选择 基于7.0 代码
Tips for this week 140: constants: safety idioms
< code random recording two brushes> linked list
MRS离线数据分析:通过Flink作业处理OBS数据
Slider plug-in for swiper left and right switching