当前位置:网站首页>Redis cluster and expansion
Redis cluster and expansion
2022-07-07 18:51:00 【A vegetable chicken that is working hard】
Redis High availability
1. Why high availability
- Prevent a single point of failure , Make the whole cluster unavailable
- The common way to achieve high availability is to replicate multiple copies of the database to deploy on different servers , One of them hangs up and can continue to provide services
- Redis There are three deployment modes to achieve high availability : A master-slave mode , Sentinel mode , Cluster pattern
2. A master-slave mode
- Master node be responsible for Reading and writing operation
- From the node Only responsible for read operation
- The data from the slave node comes from the master node , The principle is Master slave replication mechanism
- Master slave replication includes Copy in full , Incremental replication Two kinds of
- When slave Start the connection for the first time master, Or it is considered that full replication is adopted for the first connection
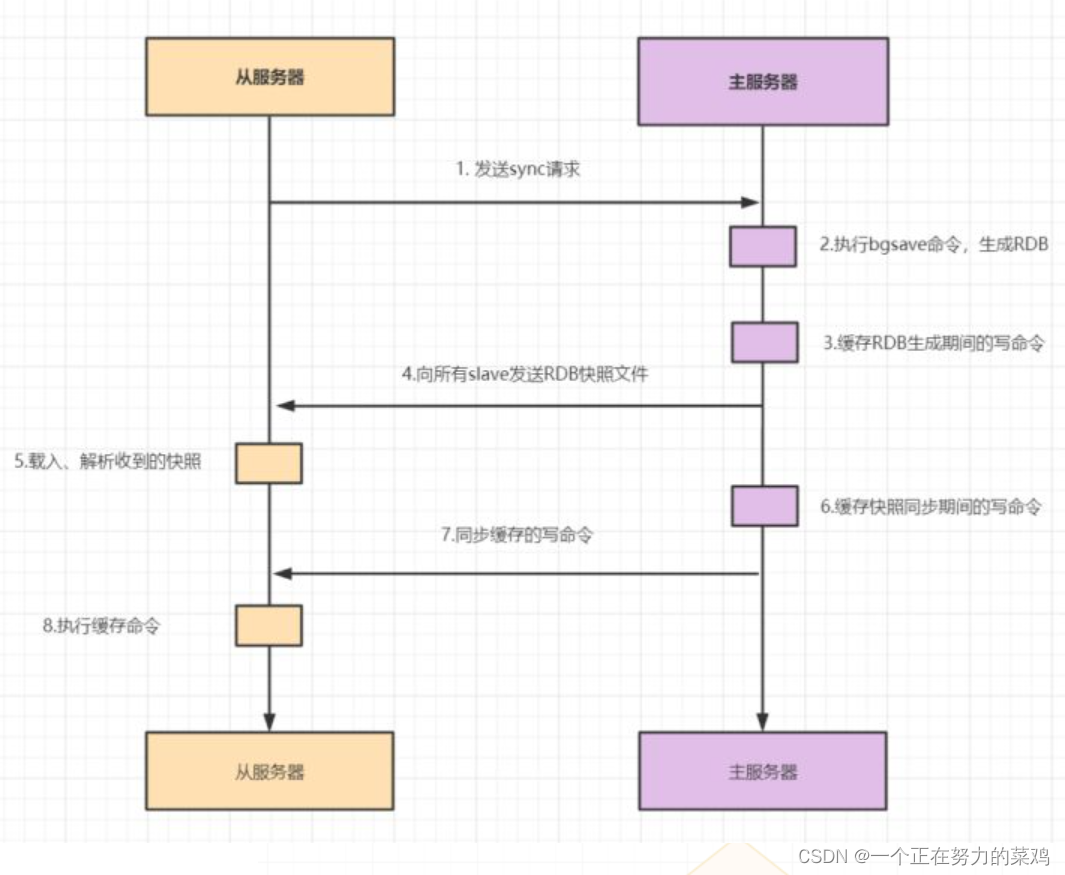
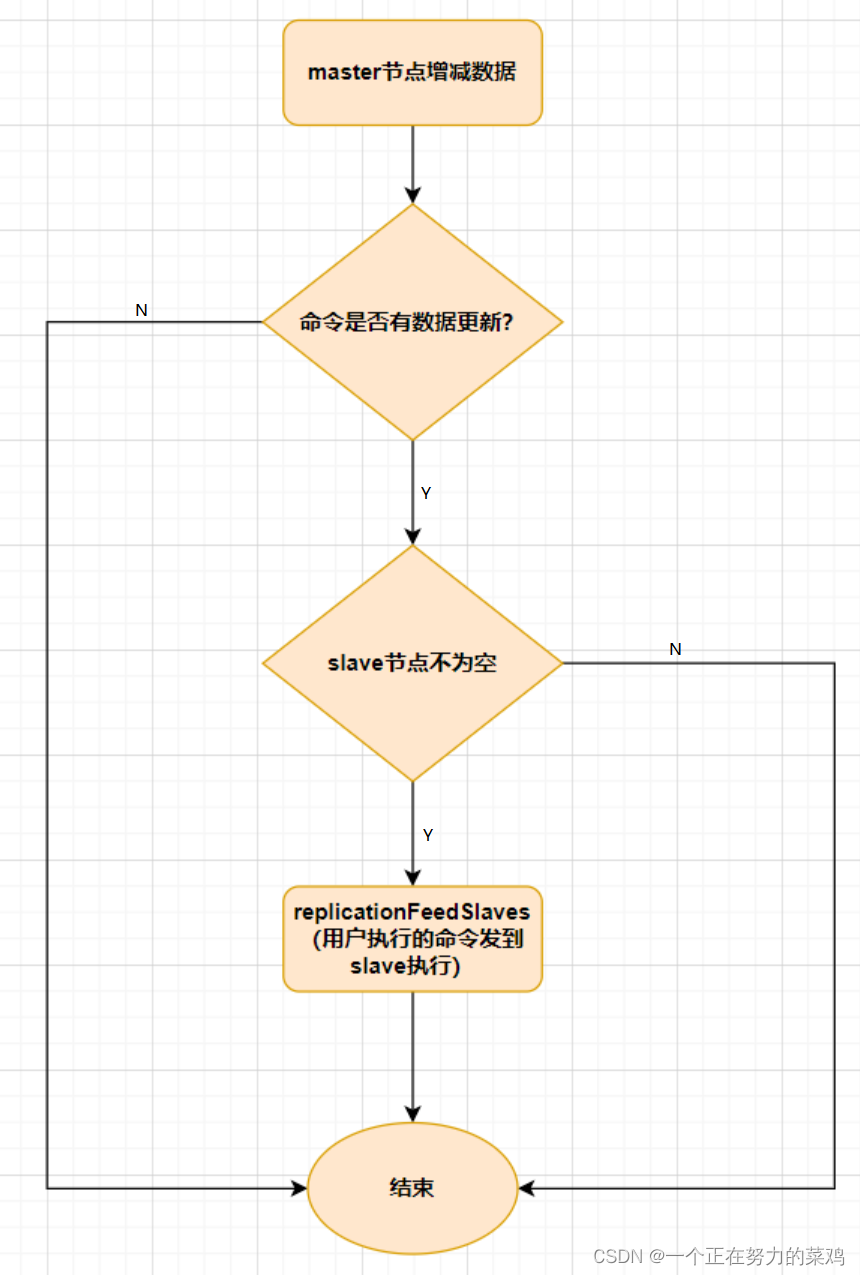
- slave And master After full synchronization ,master If the data on is updated again , This triggers incremental replication
3. Sentinel mode
- In master-slave mode , Once the primary node fails to provide service , Need to manually upgrade from node to primary node , At the same time, the application should be notified to update the primary node address , Obviously, most business scenarios cannot accept this kind of fault handling ,Redis from 2.8 It began to officially offer Redis Sentinel( sentry ) Architecture to solve this problem
- Sentinel mode consists of one or more Sentinel Examples of Sentinel System , Sure Monitor all Redis Master and slave nodes , And in the monitored When the master node goes offline, it will automatically upgrade a slave node under the offline master server to a new master node
- But a sentinel process is right Redis Node monitoring , There may be problems ( Single point ), Therefore, multiple sentinels can be used for monitoring Redis node , And there will be monitoring between the Sentinels
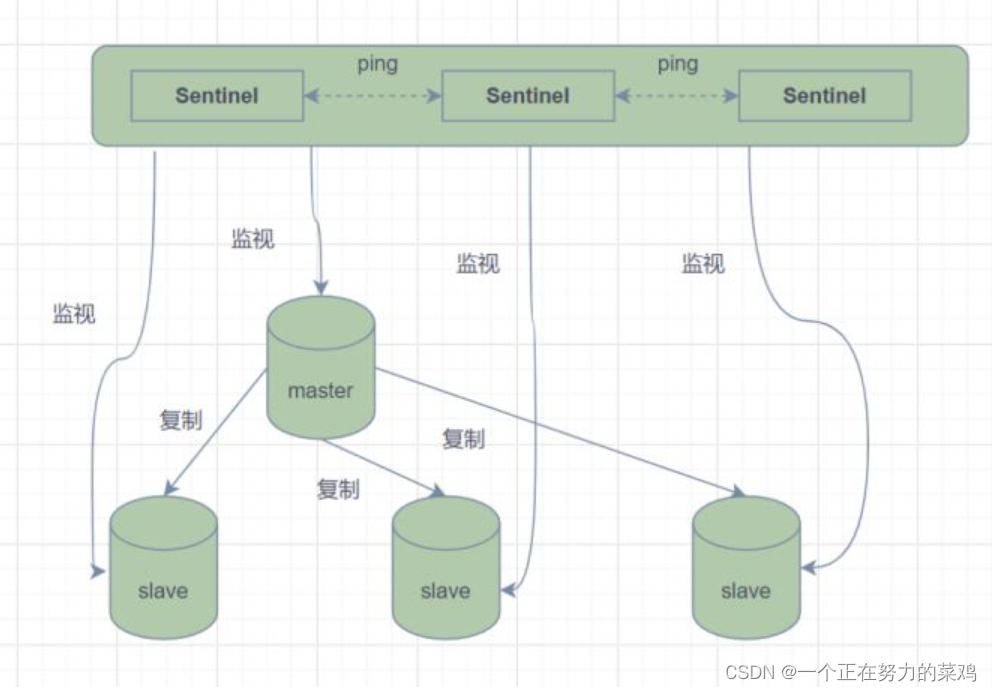
- Simply speaking , Sentinel mode has three functions
1. dispatch orders , wait for Redis The server ( Including the master and slave servers ) Return to monitor its running status
2. The sentinel automatically switches the slave node to the master node when it detects the downtime of the master node , Then notify other slave nodes to modify the configuration file through publish and subscribe mode , Let them switch hosts
3. Sentinels will also monitor each other , For high availability
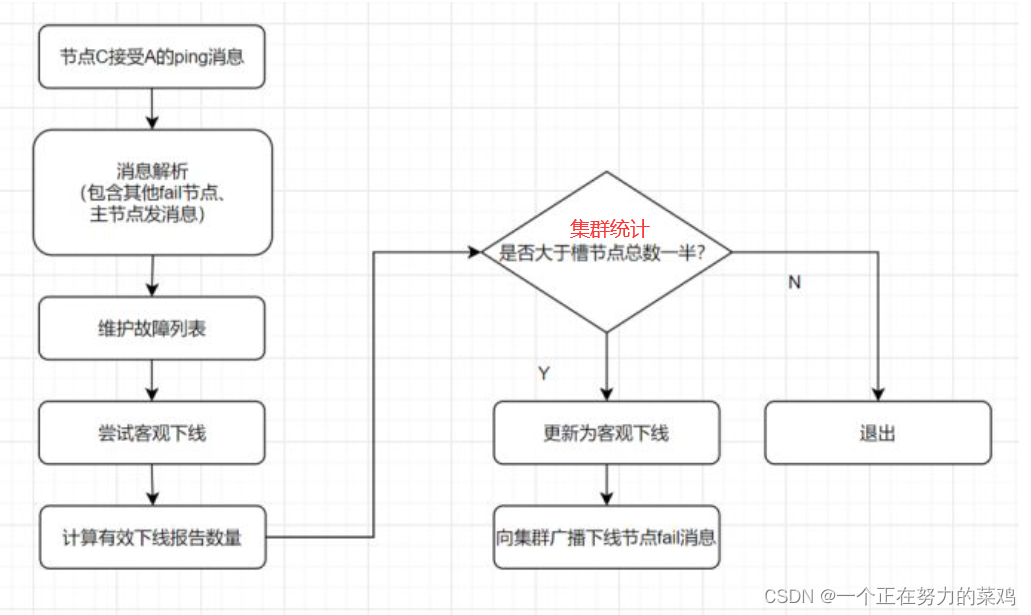
- The failover process is as follows
Suppose the primary server goes down , sentry 1 First detect the result , The system doesn't work right away failover The process , Just sentinels 1 Subjectively, the primary server is not available , This phenomenon is called subjective offline
When the sentinel behind also detects that the main server is unavailable and the number reaches a certain value , Then there will be a vote between the Sentinels , The result of the vote was sponsored by a sentinel , Conduct failover operation
After successful switching, publish and subscribe through the mode , Let each sentry switch the host from the server that they monitor , This process is called objective offline
So for clients , Everything is transparent
- The Sentinel's working mode
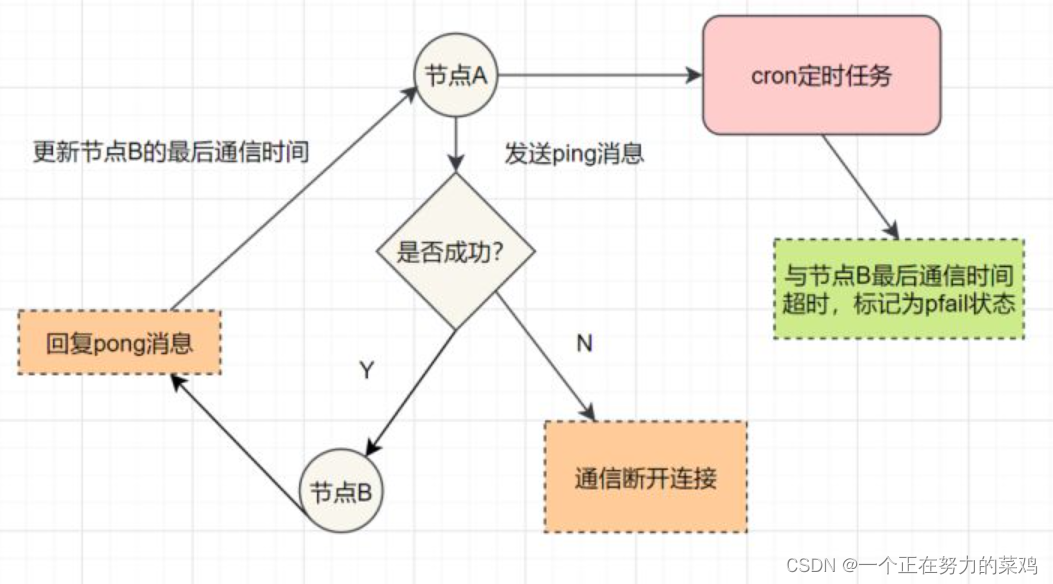
Every Sentinel At a rate of once per second to what it knows Master,Slave And other things Sentinel Instance sends a PING command
If the instance is far from the last valid reply PING The order took longer than down-after-milliseconds The value specified by the option , Then this instance will be Sentinel Mark as subjective offline
If one Master Marked as subjective offline , Is monitoring this Master All of the Sentinel Confirm... At a rate of once per second Master It has entered the subjective offline state
When there are enough Sentinel( Greater than or equal to the value specified in the configuration file ) Confirm... Within a specified time frame Master It has entered the subjective offline state , be Master Will be marked as objective offline
In general , Every Sentinel With every 10 Second frequency to all that it knows Master,Slave send out INFO command
When Master By Sentinel When marked as objective offline ,Sentinel Go offline Master All of the Slave send out INFO The frequency of the command will be from 10 Once per second to once per second
If there is not enough Sentinel agree! Master It's offline ,Master The objective offline status of will be removed ; if Master Reorientation Sentinel Of PING Command returns a valid reply ,Master Will be removed
4.Cluster Cluster pattern
- Sentinel mode is based on master-slave mode , Read and write separation , It can also switch automatically , Higher system availability , But the data stored in each node is the same , Waste of memory , And it's not easy to expand online , therefore Cluster Clusters came into being , It's in Redis3.0 Added
- Cluster colony Realization Redis Distributed storage , Slice the data , in other words Each station Redis Different content is stored on the node , Come on Solve the problem of online capacity expansion , And it also Provide replication and failover functions
- Redis Cluster Cluster adoption Gossip Protocol to communicate , Information is constantly exchanged between nodes , The information exchanged includes Node failure 、 New nodes join 、 Master slave node change information 、slot Information, etc. , frequently-used Gossip The messages are ping、pong、meet、fail
ping news : The most frequently exchanged messages in the cluster , Each node in the cluster sends messages to multiple other nodes per second ping news , It is used to detect whether nodes are online and exchange status information with each other
meet news : Notify the new node to join , The sender informs the receiver to join the current cluster ,meet After the message communication is completed normally , The receiving node will join the cluster and perform periodic ping、pong The message exchange
pong news : When receiving ping、meet When the news , As a response message, reply to the sender to confirm that the message communicates normally ;pong The message encapsulates its own state data , Nodes can also broadcast their messages to the cluster pong Message to inform the whole cluster to update its status
fail news : When a node decides that another node in the cluster is offline , It will broadcast a fail news , Other nodes receive fail After the message, update the corresponding node to offline status
- Hash Slot Slot algorithm
Since it's distributed storage ,Cluster The distributed algorithm used by the cluster is consistency Hash Well ? Not at all , It is Hash Slot Slot algorithm
The slot algorithm divides the entire database into 16384 individual slot( Slot ), Everyone enters Redis The key value pairs of are based on key To hash , Assigned here 16384 One of the slots
The hash mapping used is also relatively simple , use CRC16 The algorithm calculates a 16 The value of a , Right again 16384 modulus , Every key in the database belongs here 16384 One of the slots , Each node in the cluster can handle this 16384 Slot
Each node in the cluster is responsible for part of the hash Slot , For example, the current cluster has A、B、C Nodes , The number of hash slots on each node =16384/3, Then there is :
node A be responsible for 0~5460 Hash slot
node B be responsible for 5461~10922 Hash slot
node C be responsible for 10923~16383 Hash slot
Redis Cluster In the cluster , Need to ensure 16384 The slots correspond to node They all work , If a node Something goes wrong , It's responsible for slot It's going to fail , The whole cluster will not work
To ensure high availability ,Cluster Cluster introduces master-slave replication , A master node corresponds to one or more slave nodes , When other master nodes ping A master node A when , If more than half of the master nodes are connected with A Communication timeout , So think of the master node A Downtime , If the primary node goes down , The slave node will be enabled
Redis There are two things on every node of the , One is the slot slot(0~16383), The other is cluster, It can be understood as a plug-in for cluster management , When we access key On arrival ,Redis Will be based on Hash Slot The slot algorithm gets the number in 0~16383 The Hashi trough between , Use this value to find the node corresponding to the corresponding slot , Then directly and automatically jump to the corresponding node for access operation
5. Failover after high availability
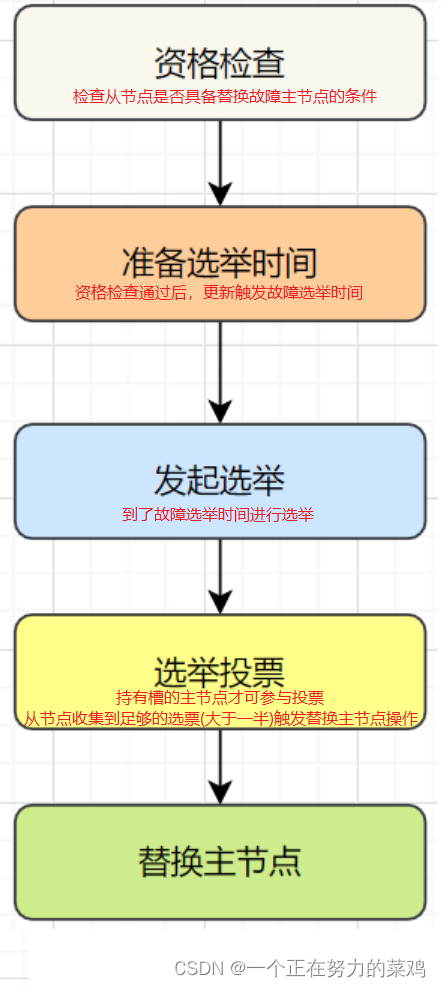
- Subjective offline : One node thinks another node is unavailable , That is, offline status , This state is not the final fault determination , It can only represent the opinions of one node , There may be misjudgment
- Objective offline : Mark a node as truly offline , Many nodes in the cluster think that the node is not available , The result of reaching a consensus , If the master node holding the slot fails , Need to fail over for this node
- Fault recovery : After the fault is found , If the offline node is the master node , You need to select one of its slave nodes to replace it , To ensure the high availability of the cluster
Redis A series of problems caused by distributed locks and their solutions
1.Redisson
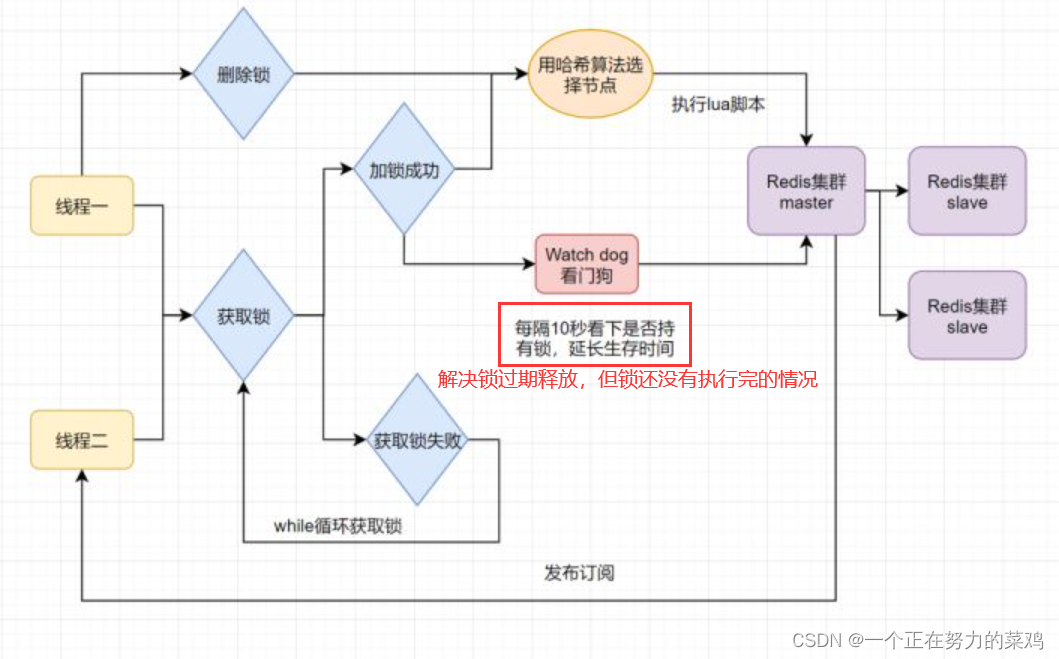
- Distributed locks may exist Lock expired release , The business is not finished The problem of
- Can you set the expiration time of the lock longer to solve this problem ? Obviously not very good , The execution time of the business is uncertain
- Redisson Solve the problem , Start the timing daemon thread for the thread that obtains the lock , Check whether the lock exists at regular intervals , If it exists, the expiration time of the lock will be extended , Prevent lock expiration and early release
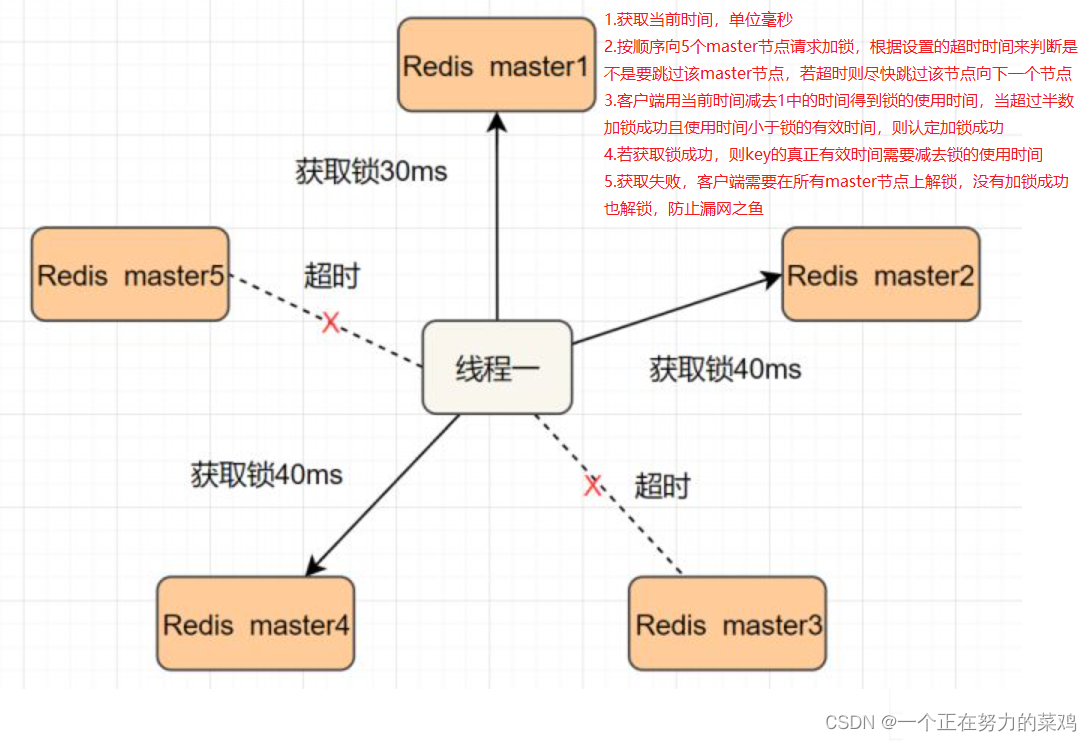
2.Redlock Algorithm
- Thread one in Redis Of master The lock is held on the node , But locked key It's not synced to slave node , Just then master Node failure , One slave The node will be upgraded to master node , Thread two can get the same key It's my lock , But thread one has got the lock , The security of the lock is gone
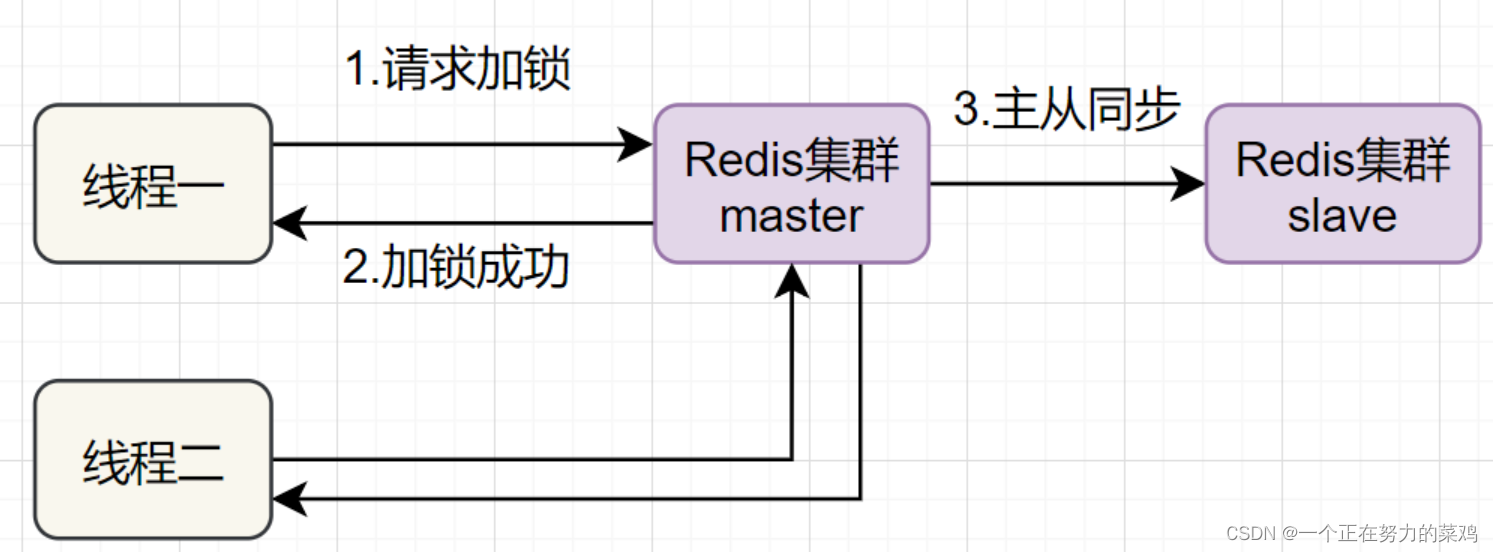
- Redlock Solve this problem , That is, deploy multiple Redis master To make sure they don't go down at the same time , And these master Node is Completely independent of each other Of , Between each other There is no data synchronization , The implementation steps are as follows
MySQL And Redis How to ensure double write consistency
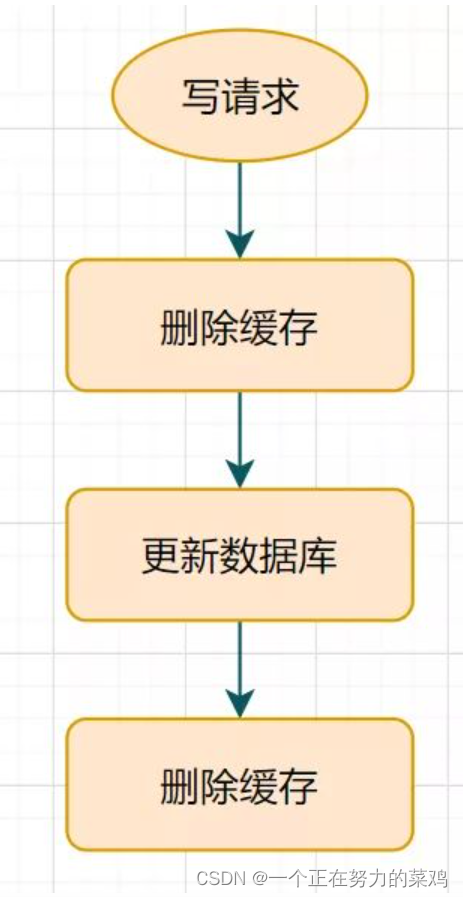
1. Delay double delete
- After updating the database, delay sleeping for a while before deleting the cache
- This scheme is ok , There may be dirty data only during sleep , General business will also accept
- But what if the second cache deletion fails ? The data in the cache and database may still be inconsistent
- to Key Set a natural expire Expiration time , How about letting it expire automatically ? What about the inconsistency of data accepted by the business within the expiration time ? There are other better solutions
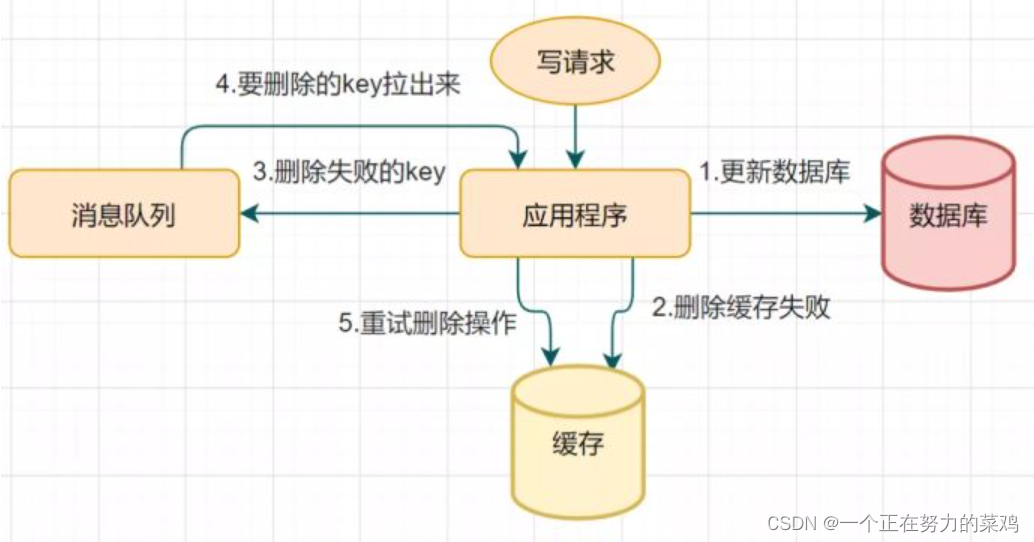
2. Delete cache retry mechanism
- Delayed double deletion may lead to the failure of deleting cache in the second step , Data inconsistency caused by
- If the deletion fails, please delete it several times , Just ensure that the cache is deleted successfully , So we can introduce Delete cache retry mechanism
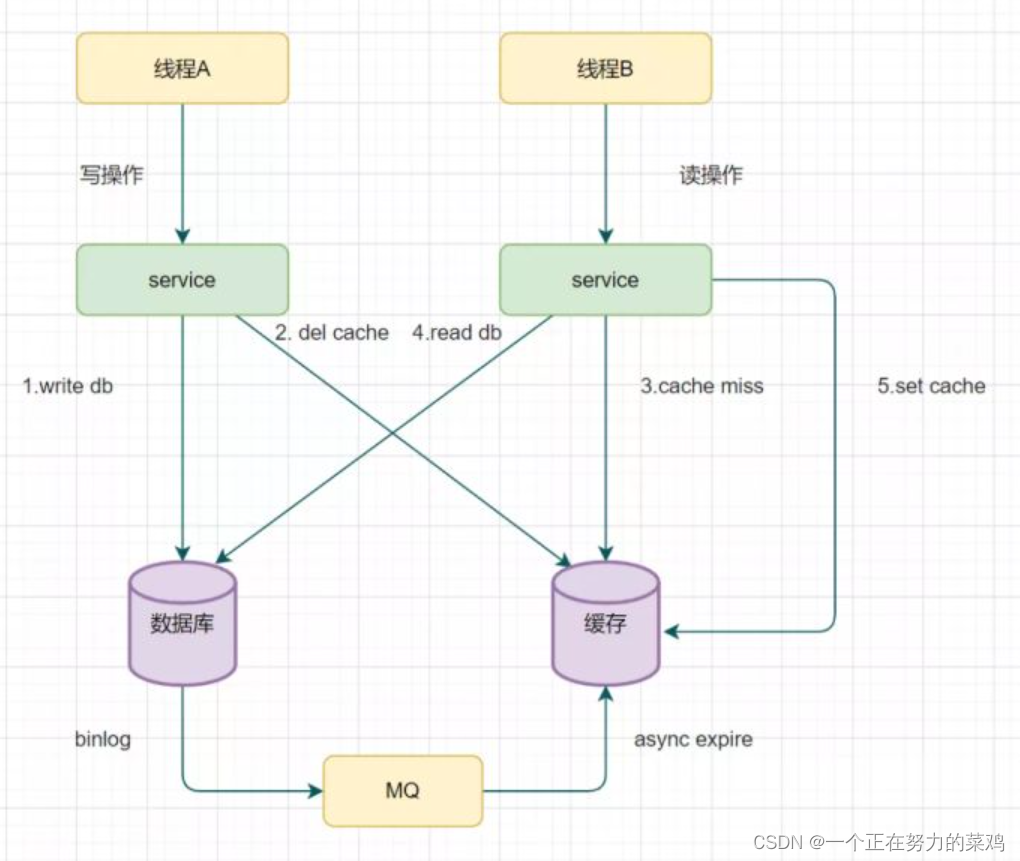
3. Read biglog Delete cache asynchronously
- Retry deleting the cache mechanism will cause many business code intrusions , So introduce reading biglog Delete cache asynchronously
边栏推荐
- Tear the Nacos source code by hand (tear the client source code first)
- 【Unity Shader】插入Pass实现模型遮挡X光透视效果
- Reject policy of thread pool
- 学习open62541 --- [67] 添加自定义Enum并显示名字
- 财富证券证券怎么开户?通过链接办理股票开户安全吗
- The highest level of anonymity in C language
- What is the general yield of financial products in 2022?
- 海量数据去重的hash,bitmap与布隆过滤器Bloom Filter
- Redis
- 高考填志愿规则
猜你喜欢

Calculation of torque target value (ftorque) in servo torque control mode

Tips for short-term operation of spot silver that cannot be ignored
海量数据去重的hash,bitmap与布隆过滤器Bloom Filter
小试牛刀之NunJucks模板引擎
磁盘存储链式的B树与B+树
How to clean when win11 C disk is full? Win11 method of cleaning C disk

Tsinghua, Cambridge and UIC jointly launched the first Chinese fact verification data set: evidence-based, covering many fields such as medical society

Kirk Borne的本周学习资源精选【点击标题直接下载】
Save the memory of the model! Meta & UC Berkeley proposed memvit. The modeling time support is 30 times longer than the existing model, and the calculation amount is only increased by 4.5%
Charles+drony的APP抓包
随机推荐
6.关于jwt
Thread pool and singleton mode and file operation
Cloud security daily 220707: Cisco Expressway series and telepresence video communication server have found remote attack vulnerabilities and need to be upgraded as soon as possible
[C language] string function
Interview vipshop internship testing post, Tiktok internship testing post [true submission]
[论文分享] Where’s Crypto?
『HarmonyOS』DevEco的下载安装与开发环境搭建
PHP面试题 foreach($arr as &$value)与foreach($arr as $value)的用法
[demo] circular queue and conditional lock realize the communication between goroutines
idea彻底卸载安装及配置笔记
Discuss | what preparations should be made before ar application is launched?
2022年理财有哪些产品?哪些适合新手?
体总:安全有序恢复线下体育赛事,力争做到国内赛事应办尽办
线程池的拒绝策略
Introduction of common API for socket programming and code implementation of socket, select, poll, epoll high concurrency server model
Kubernetes DevOps CD工具对比选型
[paper sharing] where's crypto?
debian10系统问题总结
Will low code help enterprises' digital transformation make programmers unemployed?
链式二叉树的基本操作(C语言实现)