当前位置:网站首页>Easy to understand: understand the time series database incluxdb
Easy to understand: understand the time series database incluxdb
2022-07-04 07:31:00 【sp42a】
Time series database is often used in computer room operation and maintenance monitoring 、 The Internet of things IoT Device acquisition and storage 、 Internet advertising click analysis and other application scenarios based on timeline and continuous influx of multi-source data into the data platform ,InfluxDB Designed for sequential data storage , Especially intelligent manufacturing in the industrial field , The future application potential is huge .
Data model
Characteristics of time series data
The application scenario of time series data is that data will flow from multiple data sources at each time point on the timeline , Generate a large amount of data according to multiple latitudes of continuous time , And write to the memory in real time calculated by seconds or even milliseconds .
Conventional RDBMS database Write support is handled on a line by line basis , And establish B Index of tree structure , It is not designed for batch high-speed writing , Especially like the continuous influx of multi latitude time series data into the data platform ,RDBMS Your storage engine will inevitably lead to load 、 Throughput is extremely unsuitable for write performance . Therefore, the storage design of timing data generally does not consider the traditional memory RDBMS, Will focus on LSM-Tree And the data structure storage direction of the column .
LSM Data model It is the layer by layer pressing of batch data from memory to disk files , Some will be sensitive to the data KV Sequential arrangement , Form clusters to store files , for example HBase,Cassandra; Some fields by column correspond to multiple file stores , Form column storage , This can greatly improve the compression ratio , for example Druid.io.
Look again Temporal data structure : data source (DataSource)+ Index item (Metric)+ Time stamp (TimeStamp)= The data points , Each data point is an indicator measurement point on the timeline .
If you represent it from a two-dimensional diagram , As shown in the figure below , The horizontal axis represents time , The longitudinal axis represents the measured value , Each point in the figure is the data point of index measurement (Point) 了 .
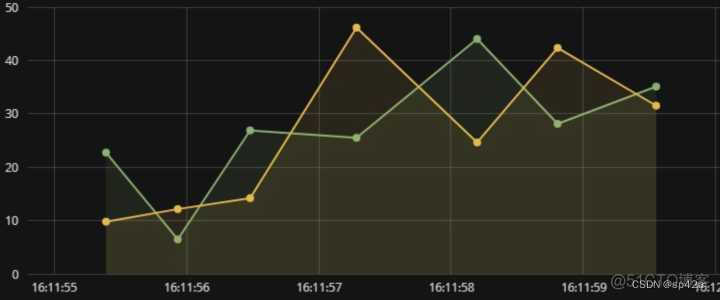
The above figure can be expressed as : data source 1( Moving ring detection - Hi tech Zone computer room - Data area )— indicators ( humidity ), data source 2( Moving ring detection - Xixian new area computer room - Calculation area )— indicators ( humidity ) At successive points in time (TimeStamp) Two time series broken line diagrams on .
Among them, dynamic ring detection represents the business field of data source , Computer room 、 The area represents the label of the data source (Tag), Moving ring detection + Computer room + The region determines the only temporal data source .
be based on HBase Of OpenTSDB Data model
Time series database except InfluxDB outside , There is another well-known timing library —OpenTSDB,OpenTSDB Is based on HBase The timing database implementation of the platform , I have analyzed many times in my previous answers HBase Internal mechanism , Its characteristic is derived from Google BigTable Data model of , The column cluster is the overall unit of data organization and storage .
We can understand that a column cluster is a Excel A wide watch , Each cell in the table is composed of K/V form ,KEY By line key + Column cluster name + Name + Composition of time, etc , So right. KEY After ordering , Like a cell K/V Naturally, it is formed by pressing the line key 、 Column cluster name 、 Name 、 In chronological order . It is very convenient to grab a set of column values of a column cluster according to the row key .
We know from the characteristics of time series data , data source + indicators + The timestamp can determine a data point , So in OpenTSDB In the design of , This combination is the row key . However, because the timestamp is continuous and different , It will lead to every K/V The line keys are different , This produces a very large amount of single column data . therefore OpenTSDB optimized , The time stamp in the line key is counted in hours , Divided into... In seconds 3600 Columns , In this way, one row of the column cluster represents one hour of time series data , Each column represents the value of that second .
From the perspective of mechanism design ,OpenTSDB be based on HBase To optimize the characteristics of , Well done . however HBase The essence of is K/V As an atomic unit , By multiple K/V formation Block, Again by Block formation HFile file .
The disadvantage is :
- every last K/V Because of KEY The construction of brings a lot of redundancy , And it can't effectively implement label based tag Conditional index of , because tag All rubbed into the line keys , This requires full sequential scanning .
- KEY It is impossible to compress effectively on the general compression algorithm , Eventually, it will take up more storage costs , The essential problem is that time stamps cannot be (Timestamp) Separate stripping treatment .
InfluxDB Data model
InfluxDB There is no plan to completely develop a new theoretical system of data storage , But in reference to HBase Of LSM-Tree After the data model , Establish a set of storage architecture suitable for time series data , named TSM.
Let's repeat HBase Data model mechanism , Additional WAL, Create a batch write data buffer in memory MemStore, On a regular or full basis MemStore Scour (Flush) To disk StoreFile,StoreFile Then merge files regularly , Do merge sort and complete record de duplication . This is based on LSM-Tree The data model of the structure can greatly improve the performance of writing , quite a lot NoSQL This is the way the system operates .InfluxDB No exception , Continue this LSM-Tree Structural routine , When writing timing data, first append WAL, And then write Cache, Then wash it regularly or when it is full (Flush) To disk TSM file .
Let's see what it's like HBase Different places , It mainly lies in the design of data structure ,HBase Of MemStore Directly encapsulate the written data into K/V Then form bigger Chunk block . The biggest feature of this structure is HBase In an almost universal way, the atomic units are sequentially (K/V) Arrange and package into larger Chunk block , The data is designed very loosely , Randomness lookup does not depend on data structure optimization , Instead, it relies on index based scanning , It belongs to the golden oil type , Any upper layer application can be used , for example : Scan and query of various wide table services 、 Aggregate analysis or design analysis by timeline TSDB. however InfluxDB stay Cache The structure is re optimized :Map aggregate < data source ,Map aggregate < indicators ,List list < Time stamp : Data values >>>, We can see that it's a Map set Map Repeat List Structure , first floor Map It's sequence (Series) aggregate ,Series Namely InfluxDB Defined data source ( surface measurement + Multi label tagset), The second floor Map Is the indicator set ,InfluxDB Define the indicator as Fields, The third layer is the timeline record list of an indicator of a data source .
So we can see InfluxDB Firstly, according to the characteristics of time series data , The data structure is readjusted to meet the needs of this timing feature , Then there is the index to locate the index based on the data source , Use the index to locate the data list on the timeline .
InfluxDB In the memory Cache Meeting Flush To TSM file ,TSM The data block arrangement and index block arrangement of disk files will also be established according to the above structure , Each data block can be Timestamps List and Values The list consists of . Then it's OK to TimeStamps The list is compressed separately (delta-delta code ),Values The list has the same type Type, According to Type Compress . Index blocks build data blocks and Series The relationship between , The data block displacement of the data to be checked is quickly located by bisection search of the time range .
InfluxDB Indexes
InfluxDb There are two indexes , One is TSM File built-in Series Indexes , The other is inverted index ,
- Series Indexes : stay InfluxDB In the built-in index of Series + field It's the primary key , Locate an index block for an indicator , The index block consists of N An index entity consists of , Each index entity provides a minimum time and a maximum time , And this time range corresponds to TSM file Series The offset of the data block ,TSM There are multiple files Series Data block composition , Every Series The data block contains the time list (Timestamps), The minimum time and maximum time of the index entity correspond to this time list . therefore Series The index block can be passed through Key Sort , And binary search through the time range , First, quickly locate the timing data in a certain time range , Then do scan matching .
- Inverted index :InfluxDB except TSM Outside the structure , also TSI structure ,TSI It is mainly used for inverted indexing of time series data , for example : Through the moving ring detection - Query the indicators of each area of the High-tech Zone Computer Room Based on the high-tech zone computer room , Or it can be detected by moving ring - The data area is used to query all indicators of the data area of all machine rooms .
TSI The data structure of is :Map aggregate < Tag name ,Map aggregate < Label value ,List list >>, The first layer is the collection of tag names , The second layer is the collection of all tags under a tag name , for example : The tag name is area , It contains the data area 、 Calculate tag values such as area , The third layer is the data source corresponding to a specific label , for example : The data source containing the data area label has moving ring detection - High-tech zone - Data Center , Moving ring detection - Xixian New District - Data center, etc .
Through this indexing method, you can quickly index all data sources containing this tag through the tag . Through the data source Series, Again from TSM Find by other criteria in the file .TSI The data model uses and TSM The same routine , It's all based on LSM data structure , Accompanying data writing , Inverted index first write WAL, Writing memory In-Memory Index, When the memory threshold is reached Flush pour TSI file , and TSI Files are disk based Disk-Based Index Inverted index file , It contains Series Block and label block , You can use the tag value in the tag block to Series Find all the corresponding... In the block Series.
Time series libraries are labeled by data source in this way (Tag) The analysis and query of classification will be very efficient , This is also InfluxDB It fully meets the needs of time series data business .
Distributed
InfluxDB In terms of clustering, the source is closed , It's really a pity . But it's understandable , Any technology start-up company should seek survival and development , Commercial blood transfusion is necessary , I hope one day InfluxDB Our parent company can be acquired by giants , And then completely open source again .
I've talked about one issue before HBase and Cassandra Comparison of , Interested friends can have a look at :HBase And Cassandra Experience sharing of architecture comparative analysis .
InfluxDB More decentralized distributed , There is my comparison between the two , and InfluxDB Closer to Cassandra,Cassandra It is a decentralized distributed architecture , and InfluxDB It includes Meta Nodes and Data node , however Meta The node appears to be the master node , But the effect is weak , It mainly stores some public information and continuous query scheduling , Data reading and writing problems mainly focus on Data node , and Data Read and write between nodes , Closer to a decentralized approach .
InfluxDB yes CAP In the theorem AP Distributed systems , Very focused on high availability , Not consistency . secondly InfluxDB It is mainly two-stage segmentation , The first level is ShardGroup, The next level is Shard.
ShardGroup It's a logical concept , Represents multiple... Within a time period Shard, Creating InfluxDb database (DataBase) And retention policies (RETENTION POLICY) It was determined after ShardGroup A continuous period of time , This is equivalent to first partitioning the time series data according to the time period range , for example 1 An hour as a ShardGroup. But this 1 The data within an hour is not stored on a data node , This is very different from HBase Of Region 了 ,Region First, it will write hard towards a data node , Only when you are full Region Split , Then implement Region Migration distribution . and InfluxDB It should be a reference Cassandra That set of methods , Based on Series As Key Of Hash Distribution , Will a ShardGroup The multiple Shard Distributed on different data nodes in the cluster .
Position below shard In the code of key Namely Series, That is, the only specified data source ( surface measurement + Label set tagset).
shard := shardGroup.shards[fnv.New64a(key) % len(shardGroup.Shards)]
In the above code shardGroup.Shards Namely ShardGroup Of Shard Number , The quantity is N/X,N Is the number of data nodes in the cluster ,X Is the copy factor . for example : Cluster has 4 Nodes ,2 Copies ,4/2 You get the need to 1 Hour ShardGroup Split the range data into 2 individual Shard, And each copy 2 Share , Distributed over four data nodes , Through this Hash Distribution , More uniform distribution of time series data , It also makes full use of the read-write advantages of each data node in the cluster .
InfluxDB It's ultimate consistency , Various adjustment strategies are implemented on write consistency Any、One、Quorum、All, and Cassandra cut from the same cloth , It also strengthens the coordination of nodes Hinted handoff The temporary queue persistence function of , This is all about high availability .
Even if the real replica node fails , Let's start at the... Of the collaboration node Hinted handoff Persist in the queue , Wait until the replica node fails to recover , Again from Hinted handoff Replication recovery in queue . Is to achieve final consistency .
in addition InfluxDB and Cassandra3.x As in previous versions , It has the anti entropy function of background fragment repair (anti-Entrory), But the interesting thing is Cassandra In the new 4.0 The version no longer retains the function of background read and repair , And it is not recommended to enable in previous versions , Because it has the ability of active read and repair , Background read repair has little effect , It also affects performance .
Of course InfluxDB Is it right? Cassandra equally , Active read repair is carried out in the process of reading , Because it's a closed source system , I'm not sure about that .
InfluxDB It will be very weak on deletion , Only one range set or Series Next dimension set , This is also the result of the design of this timing structure , For single Point The deletion of will be troublesome , It costs a lot .
The deletion method should also be a reference Cassandra Of Tombstone Mechanism : The problem of decentralization is that everyone will delete the copy , A replica node that is just in failure has recovered , It doesn't know what happened , But during the repair process, it will think that the deleted copy has been lost , And let everyone recover .
With Tombstone The long-term existence of markers , Then there is a failed node with replica data , After recovery, according to other replica nodes Tombstone Mark , That is, you know that deletion occurred during your failure , Delete the corresponding replica data immediately .
summary
First Influxdb Appearance , The storage volume of time series data is greatly reduced , This is extremely conducive to the data storage problem in the era of the Internet of things , The key is reasonable storage structure design , On the one hand, it can reduce data redundancy , On the other hand, it can make full use of specific compression algorithms , for example :delta-delta Compression algorithm for TSM A highly compressed collection of timestamps in a file ;
Secondly, we are facing the storage with time as the main line , It was hard to find a suitable solution before , For example, we use Elasticsearch Build a date index to save the log , But we always create under what conditions , The question of when to destroy , And it takes a lot of effort at the coding level , however Influxdb The retention policy and partition grouping solve this kind of problem well ;
Finally, the index establishment of more appropriate time series model , Especially the inverted index TSI, Very efficient implementation in a period of time , Capture data according to a certain latitude 、 Aggregation and Analysis , This is precisely the core requirement of timing application scenarios , It can greatly improve the application efficiency of the overall computing resources .
边栏推荐
- Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and
- It's healthy to drink medicinal wine like this. Are you drinking it right
- Detailed introduction to the big changes of Xcode 14
- The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
- System architecture design of circle of friends
- Chapter 1 programming problems
- kubernetes集群之Label管理
- socket inet_ pton() inet_ Ntop() function (a new network address translation function, which converts the expression format and numerical format to each other. The old ones are inet_aton(), INET_ ntoa
- Would you like to go? Go! Don't hesitate if you like it
- 提升复杂场景三维重建精度 | 基于PaddleSeg分割无人机遥感影像
猜你喜欢
Oceanbase is the leader in the magic quadrant of China's database in 2021
Introduction to deep learning Ann neural network parameter optimization problem (SGD, momentum, adagrad, rmsprop, Adam)
Zephyr 学习笔记1,threads
MySQL中的文本處理函數整理,收藏速查

The cloud native programming challenge ended, and Alibaba cloud launched the first white paper on application liveliness technology in the field of cloud native
The idea of implementing charts chart view in all swiftui versions (1.0-4.0) was born
win10微软拼音输入法输入文字时候下方不出现中文提示
Xcode 14之大变化详细介绍

NLP-文献阅读总结
NLP literature reading summary
随机推荐
Unity 从Inspector界面打开资源管理器选择并记录文件路径
Experience installing VMware esxi 6.7 under VMware Workstation 16
Routing decorator of tornado project
Oceanbase is the leader in the magic quadrant of China's database in 2021
Boast about Devops
Transition technology from IPv4 to IPv6
电子协会 C语言 1级 35 、银行利息
com. alibaba. nacos. api. exception. NacosException
Jianmu continuous integration platform v2.2.2 release
[MySQL transaction]
flask-sqlalchemy 循环引用
L1-023 output gplt (20 points)
Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Text processing function sorting in mysql, quick search of collection
[untitled] notice on holding "2022 traditional fermented food and modern brewing technology"
This monitoring system can monitor the turnover intention and fishing all, and the product page has 404 after the dispute appears
win10微软拼音输入法输入文字时候下方不出现中文提示
I was pressed for the draft, so let's talk about how long links can be as efficient as short links in the development of mobile terminals
BUUCTF(4)
socket inet_ pton() inet_ Ntop() function (a new network address translation function, which converts the expression format and numerical format to each other. The old ones are inet_aton(), INET_ ntoa