1. What is a reptile
Crawler is to crawl web data , As long as there is something on the web , Can be crawled down by reptiles , Such as the picture 、 Written comments 、 Product details, etc .
Generally speaking, two words ,Python Crawlers need the following steps :
- Find the page URL, Initiate request , Wait for the server to respond
- Get server response content
- Parsing content ( Regular expressions 、xpath、bs4 etc. )
- Save the data ( Local files 、 Database etc. )
2. Basic process of reptile
- Find the page URL, Initiate request , Wait for the server to respond
- Get server response content
- Parsing content ( Regular expressions 、xpath、bs4 etc. )
- Save the data ( Local files 、 Database etc. )
3. The difference between greedy and non greedy patterns of regular expressions
1) What is greedy matching and non greedy matching
- Greedy matching always tries to match as many characters as possible when matching strings
- Contrary to greedy matching , Non greedy matching always tries to match as few characters as possible when matching strings
2) difference
- In form , There is a non greedy pattern “?” As the end sign of this part
- Functionally , The greedy pattern is to match as many current regular expressions as possible , It may contain several strings that satisfy regular expressions ; Non greedy model , Under the condition that all regular expressions are satisfied, the current regular form expression should be matched as little as possible
3) expand
- *? Repeat any number of times , But repeat as little as possible
- +? repeat 1 Times or more , But repeat as little as possible
- ?? repeat 0 Time or 1 Time , But repeat as little as possible
- {n,m}? repeat n To m Time , But repeat as little as possible
- {n,}? repeat n More than once , But repeat as little as possible
4.re Module match And search The difference between
1) The same thing : Are looking for substrings in a string , If you can find , Just go back to one Match object , If you can't find it , Just go back to None.
2) Difference :mtach() The method is to match from the beginning , and search() Method , You can find it anywhere in the string .
5. How to find and replace strings with regular expressions
1) lookup :findall() function
re.findall(r" Target string ",“ Original string ”) re.findall(r" Zhang San ",“I love Zhang San ”)[0]
2) Replace :sub() function
re.sub(r" To replace the original character ",“ To replace a new character ”,“ Original string ”) re.sub(r" Li Si ",“python”,“I love Li Si ”)
6. Write a match ip Regular expression of
1)ip Address format :(1-255).(0-255).(0-255).(0-255)
2) Corresponding regular expression
- "^(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|[1-9])\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)$"
3) analysis
- \d Express 0~9 Any number of
- {2} It happened twice
- [0-4] Express 0~4 Any number of
- | perhaps
- parentheses ( ) It can't be less , To extract the matching string , There are several in the expression () It means that there are several corresponding matching strings
- 1\d{2}:100~199 Any number between
- 2[0-4]\d:200~249 Any number between
- 25[0-5]:250~255 Any number between
- [1-9]\d:10~99 Any number between
- [1-9]:1~9 Any number between
- \.: Escape point number .
7. Write a regular expression for the email address
[A-Za-z0-9_-][email protected][a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$
8.group and groups The difference between
- 1)m.group(N) Back to page N Group matching characters
- 2)m.group() == m.group(0) == All matching characters
- 3)m.groups() Returns all matching characters , With tuple( Tuples ) Format
- m.groups() == (m.group(0), m.group(1),……)
9.requests Requested returned content and text The difference between
1) Different return types
response.text The return is Unicode Type data ,response.content The return is bytes type , That's binary data
2) Different scenarios
Get text using ,response.text, Get pictures and files , Use response.content
3) Modify the coding method differently
- response.text type :str, according to HTTP The header makes a reasoned guess about the encoding of the response
- Change the encoding :response.encoding=”gbk”
- response.content type :bytes, Decoding type is not specified
- Change the encoding :response.content.decode(“utf8”)
10.urllib and requests Module differences
1)urllib yes python Built in bag , No need to install separately
2)requests It's a third party library , Separate installation required
3)requests Ku is in urllib On the basis of , Than urllib Modules are easier to use
4)requests It can be initiated directly get、post request ,urllib You need to build the request first , Then make a request
11. Why? requests The request needs to be brought with you header?
1) reason : Simulation browser , Spoofing servers , Get content consistent with the browser
2)header Format : Dictionaries
headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”}3) usage :requests.get(url, headers=headers)
12.requests What are the tips for using the module ?
1)reqeusts.util.dict_from_cookiejar hold cookie Object to dictionary
2) Set request not used SSL Certificate validation
response = requests.get("https://www.12306.cn/mormhweb/ ", verify=False)
3) Set timeout
response = requests.get(url, timeout=10)
4) Determine whether the request is successful with the status code
response.status_code == 200
13.json modular dumps、loads And dump、load Differences in methods
- json.dumps(), take python Of dict The data type code is json character string
- json.loads(), take json The string is decoded to dict Data type of
- json.dump(x, y),x yes json object ,y It's the file object , In the end, it will be json Object is written to a file
- json.load(y), From file object y Read from json object
14. common HTTP What are the request methods ?
- GET: Request the specified page information , Return the entity body
- HEAD: Be similar to get request , But there is no specific content in the response returned , Used to capture headers
- POST: Submit data to the specified resource for processing request ( Such as submitting forms or uploading files ), Data is contained in the request body
- PUT: Send data from the client to the server to replace the content of the specified document
- DELETE: Request to delete the specified page
- CONNNECT:HTTP1.1 The protocol is reserved for proxy servers that can change the connection mode to pipeline mode
- OPTIONS: Allow clients to view the performance of the server ; TRACE: Echo the server's request , Mainly used for testing or diagnosis
15.HTTPS What are the advantages and disadvantages of the agreement ?
1) advantage
- Use HTTPS The protocol authenticates users and servers , Make sure the data is sent to the correct client and server
- HTTPS Agreement is made SSL+HTTP The protocol is built for encrypted transmission 、 Network protocol for identity authentication , than http Security agreement , It can prevent data from being stolen during transmission 、 change , Ensure data integrity
- HTTPS Is the most secure solution under the current architecture , Although not absolutely safe , But it significantly increases the cost of man in the middle attacks
2) shortcoming
- HTTPS The encryption range of the protocol is also limited , In a hacker attack 、 Denial of service attacks 、 Server hijacking and other aspects have little effect
- HTTPS The protocol also affects caching , Increase data overhead and power consumption , Even existing security measures will be affected
- SSL Certificates need money , The more powerful the certificate, the higher the cost , Personal website 、 Small websites don't need to be used
- HTTPS Connecting to the server takes up a lot of resources , The handshake phase is more time-consuming and has a negative impact on the corresponding speed of the website
- HTTPS Connection caching is not as good as HTTP Efficient
16.HTTP Communication composition
HTTP Communication consists of two parts : Client request message and server response message .
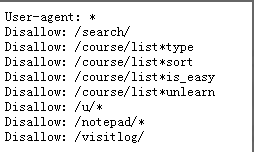
17.robots.txt What is the role of agreement documents ?
When a search engine visits a website , The first file to access is robots.txt, Website through Robots The protocol tells search engines which pages to grab , Which pages can't be crawled .
18.robots.txt Where are the documents ?
This file needs to be placed in the root directory of the website , And there are restrictions on the case of letters , The file name must be lowercase . The first letter of all commands should be capitalized , The rest are in lowercase , And there should be an English character space after the command .
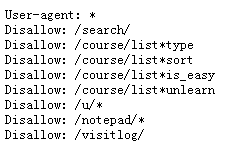
19. How to write Robots agreement ?
- User-agent: Indicates which search engine is defined , Such as User-agent:Baiduspider, Define Baidu
- Disallow: It means no access
- Allow: Indicates running access
20. Talk about your multi process , Multithreading , And understanding of the process , Whether to use... In the project ?
- process : A running program ( Code ) It's a process , No running code is called a program , Process is the smallest unit of system resource allocation , Processes have their own independent memory space , So data is not shared between processes , Spending big .
- Threads : The smallest unit of scheduling execution , It's also called the execution path , Can't exist independently , A dependent process has at least one thread , It's called the main thread , Multiple threads share memory ( Data sharing , Share global variables ), Thus greatly improving the efficiency of the program .
- coroutines : It's a lightweight thread in user mode , The scheduling of the process is completely controlled by the user . It has its own register context and stack . When the coordination scheduling is switched , Save register context and stack elsewhere , At the time of cutting back , Restore the previously saved register context and stack , The direct operation stack basically has no kernel switching overhead , You can access global variables without locking , So context switching is very fast .
- The project uses multithreading to crawl data , Improve efficiency .
21. The execution order of threads
- newly build : Thread creation (t=threading.Thread(target= Method name ) Or thread class )
- be ready : After starting the thread , The thread is ready , The thread in ready state will be put into a CPU In the scheduling queue ,cpu Will be responsible for making the threads run , Change to running state
- Running state :CPU Schedule a ready thread , The thread becomes running
- Blocked state : When the running thread is blocked, it becomes blocked , The thread in the blocking state will change to the ready state again before it can continue to run
- Death state : Thread execution completed
22. Advantages and disadvantages of multithreading and multiprocessing
1) Advantages of multithreading
- The program logic and control mode are complex
- All threads can share memory and variables directly
- The total resource consumed by thread mode is better than that by process mode
2) Disadvantages of multithreading
- Each thread shares the address space with the main program , Limited by 2GB address space
- Synchronization and lock control between threads are troublesome
- A thread crash may affect the stability of the whole program
3) Multi process advantages
- Each process is independent of each other , Does not affect the stability of the main program , It doesn't matter if the child process crashes
- By increasing the CPU, It's easy to scale performance
- Every subprocess has 2GB Address space and related resources , The overall performance limit that can be achieved is very large
4) Multi process disadvantages
- Logic control is complex , Need to interact with the main program
- Need to cross process boundaries , If there is a large amount of data transmission , It's not so good , Suitable for small amount of data transmission 、 Intensive Computing
- The cost of multi process scheduling is relatively large
In actual development , Choosing multithreading and multiprocessing should be based on the actual development , It's better to combine multi process and multi thread .
23. Writing a crawler is good with multiple processes ? It's better to multithread ? Why? ?
IO Intensive code ( File read / write processing 、 Web crawlers, etc ), Multithreading can effectively improve efficiency . Under single thread IO The operation will go on IO wait for , Cause unnecessary waste of time , And multithreading can be enabled in threads A When waiting for , Automatically switch to thread B, Can not waste CPU And so on , It can improve the efficiency of program execution .
In the actual data acquisition process , Consider both network speed and response , You also need to consider the hardware of your own machine , To set up multiprocessing or multithreading .
Multi process is suitable for CPU Intensive operation (cpu There are many operation instructions , Such as multi digit floating-point operation ). Multithreading is suitable for IO Intensive operation ( More data reading and writing operations , Like crawlers. ).
24. What is multithreading competition ?
Threads are not independent , Threads in the same process share data , When each thread accesses the data resource, there will be a competitive state , That is, data is almost synchronized and will be occupied by multiple threads , Data confusion , That is, the so-called thread is not safe .
So how to solve the problem of multithreading competition ? —— lock .
25. What is a lock , And the advantages and disadvantages of locks
lock (Lock) yes Python Provided object for thread control .
- Lock benefits : Ensure that a piece of key code ( Sharing data resources ) Only one thread can execute completely from beginning to end , It can solve the problem of multi-threaded resource competition .
- The harm of locks : Multithreaded concurrent execution is blocked , A piece of code that contains a lock can actually only be executed in a single thread mode , The efficiency is greatly reduced .
- The fatal problem of lock : Deadlock .
26. What is a deadlock ?
When several sub threads compete for system resources , Waiting for the other party to release the occupancy status of some resources , As a result, no one wants to unlock it first , Work with each other and wait , The program can't go on , This is a deadlock .
27.XPath What library is used to parse data
XPath Parsing data depends on lxml library .
28. For web crawlers XPath The main grammar of
- . Select the current node
- … Select the parent of the current node
- @ Select Properties
- * Any match ,//div/*,div Any element under
- // Select the node in the document from the current node that matches the selection , Regardless of their location
- //div Pick all div
- //div[@class=”demo”] selection class by demo Of div node
29.Mysql,Mongodb,redis Understanding of three databases
1)MySQL database : Open source relational database , Need to implement the creation of database 、 Data tables and table fields , Tables can be associated with each other ( One to many 、 Many to many ), It's persistent storage
2)Mongodb database : It's a non relational database , The three elements of a database are , database 、 aggregate 、 file , Persistent storage can be done , It can also be used as an in memory database , There is no need to format the data in advance , Data is stored in the form of key value pairs .
3)redis database : Non relational database , You don't need to set the format before use , Save as a key value pair , The file format is relatively free , Cache and database are mainly used , You can also do persistent storage
30.MongoDB Common command
- use yourDB; Switch / Create database
- show dbs; Query all databases
- db.dropDatabase(); Delete the currently used database
- db.getName(); View currently used databases
- db.version(); At present db edition
- db.addUser(“name”); Add users ,db.addUser(“userName”, “pwd123”, true);
- show users; Show all current users
- db.removeUser(“userName”); Delete user
- db.collectionName.count(); Query the number of data in the current set
- db.collectionName.find({key:value}); Query data
31. Why does the crawler project use MongoDB, Instead of using MySQL database
1)MySQL Belongs to relational database , It has the following characteristics :
- There are different storage methods on different engines
- The query statements are traditional sql sentence , Have a more mature system , Maturity is high
- The share of open source databases is growing ,MySQL The share of continues to grow
- The efficiency of processing massive amounts of data will be significantly slower
2)Mongodb It is a non-relational database , It has the following characteristics :
- The data structure consists of key value pairs
- storage : Virtual memory + Persistence
- Query statements are unique Mongodb Query mode of
- High availability
- The data is stored on the hard disk , Just the data that needs to be read frequently will be loaded into memory , Store data in physical memory , So as to achieve high-speed reading and writing
32.MongoDB The advantages of
File oriented 、 High performance 、 High availability 、 Easy to expand 、 It's sharable 、 Data storage friendly .
33.MongoDB What data types are supported ?
- String、Integer、Double、Boolean
- Object、Object ID
- Arrays
- Min/Max Keys
- Code、Regular Expression etc.
34.MongoDB "Object ID" What are the components of ?
"Object ID" Data types are used to store documents id
It's made up of four parts : Time stamp 、 client ID、 Customer process ID、 A three byte incremental counter
35.Redis What data types does the database support ?
1)String:String yes Redis The most commonly used data type ,String The data structure of is key/value type ,String Can contain any data . Common commands are set、get、decr、incr、mget etc. .
2)Hash:Hash Type can be regarded as a key/value All are String Of Map Containers . Common commands are hget、hset、hgetall etc. .
3)List:List Used to store an ordered list of strings , Common operations are to add elements to both ends of the queue or get a fragment of the list . Common commands are lpush、rpush、lpop、rpop、lrange etc. .
4)Set:Set It can be understood as a set of disordered characters ,Set The same element in will not repeat , Only one of the same elements is reserved . Common commands are sadd、spop、smembers、sunion etc. .
5)Sorted Set( Ordered set ): An ordered set is a set based on which each element is associated with a score ,Redis Sort the members of the set by scores . Common commands are zadd、zrange、zrem、zcard etc. .
36.Redis How many libraries are there ?
Redis There is 16 Databases , By default 0 library ,select 1 You can switch to 1 library .
37. Talk about Selenium frame
Selenium It's a Web Automated testing tools for , According to our instructions , Let the browser load the page automatically , Get the data you need , Even a screenshot of the page , Or judge whether some actions on the website happen .Selenium I don't have a browser , Browser functionality is not supported , It needs to work with Firefox、chrome It can only be used when third-party browsers are combined , You need to download the browser first Driver.
38.selenium There are several ways to locate elements , What kind of ?
1)selenium There are eight positioning methods
- and name Relevant :ByName、ByClassName、ByTagName
- and link Relevant :ByLinkText、ByPartialLinkText
- and id Relevant :ById
- Omnipotent :ByXpath and ByCssSelector
2) The most common is ByXpath, Because in many cases ,html The properties of the tag are not standardized , Cannot locate by a single attribute , At this time xpath You can reposition the unique element ; In fact, the fastest positioning should belong to ById, because id Is the only one. , However, most web page elements are not set id.
39.selenium What pits have you encountered in the process of use , It's all about how to solve it ?
The program is unstable , Sometimes the operation fails and the data cannot be retrieved
resolvent :
- Add element intelligence wait time driver.implicitly_wait(30)
- Add mandatory wait time ( such as python Write in time.sleep())
- multi-purpose try capture , Handling exceptions , Multiple ways to locate , If the first fails, you can automatically try the second
40.driver What are the common properties and methods of objects ?
- driver.page_source: The web page source code rendered by the current tab browser
- driver.current_url: Of the current tab url
- driver.close() : Close the current tab , If there is only one tab, close the entire browser
- driver.quit(): Close the browser
- driver.forward(): Page forward
- driver.back(): Page back
- driver.screen_shot(img_name): Screenshot of the page
41. Talk to you about Scrapy The understanding of the
Scrapy frame , Only a small amount of code needs to be implemented , Can quickly grab the data content .Scrapy Used Twisted Asynchronous network framework to handle network communication , Can speed up the download , No need to implement asynchronous framework by yourself , It also includes various middleware interfaces , Flexible to meet various needs .
scrapy The workflow of the framework :
- 1) First Spiders( Reptiles ) Will need to send the requested url(requests) the ScrapyEngine( engine ) hand Scheduler( Scheduler ).
- 2)Scheduler( Sort , The team ) After processing , the ScrapyEngine, hand Downloader.
- 3)Downloader Send a request to the Internet , And receive the download response (response), Will respond (response) the ScrapyEngine hand Spiders.
- 4)Spiders Handle response, Extract data and put data , the ScrapyEngine hand ItemPipeline preservation ( It can be local , It could be a database ), extract url Re menstruation ScrapyEngine hand Scheduler Go on to the next cycle , Until nothing Url The end of the request procedure .
42.Scrapy The basic structure of the framework
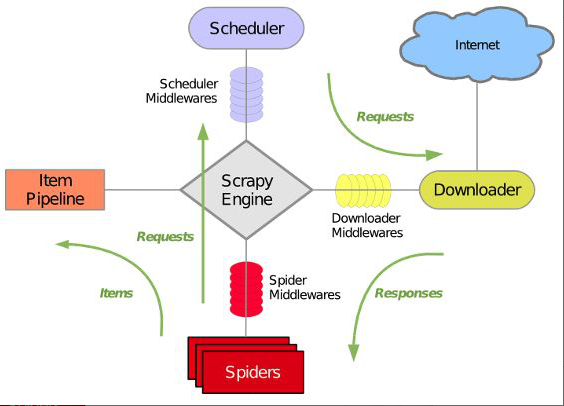
1) engine (Scrapy): Data flow processing for the whole system , Trigger transaction ( Framework core ).
2) Scheduler (Scheduler): To accept requests from the engine , Push into queue , And return when the engine requests it again . Think of it as a URL( Grab the web address or link ) Priority queue for , It's up to it to decide what's next , Remove duplicate URLs at the same time .
3) Downloader (Downloader): For downloading web content , And return the web content to the spider (Scrapy The Downloader is built on twisted On this efficient asynchronous model ).
4) Reptiles (Spiders): Reptiles are the main workers , Used to extract the information you need from a specific web page , The so-called entity (Item). Users can also extract links from it , Give Way Scrapy Continue to grab next page
5) Project pipeline (Pipeline): Responsible for dealing with entities extracted from web pages by Crawlers , The main function is to persist entities 、 Verify the validity of the entity 、 Clear unwanted information . When the page is parsed by the crawler , Will be sent to project pipeline , And process the data in several specific order .
6) Downloader middleware (Downloader Middlewares): be located Scrapy Framework between engine and Downloader , Mainly dealing with Scrapy Request and response between engine and Downloader .
7) Crawler middleware (Spider Middlewares): Be situated between Scrapy The frame between the engine and the reptile , The main work is to deal with the spider's response input and request output .
8) Scheduler middlewares (Scheduler Middewares): Be situated between Scrapy Middleware between engine and scheduling , from Scrapy Requests and responses sent by the engine to the schedule .
43.Scrapy Framework de duplication principle
Need to put dont_filter Parameter set to False, Open to remove heavy .
For each of these url Request , The dispatcher will encrypt a fingerprint information according to the relevant information requested , And combine fingerprint information with set() Compare the fingerprint information in the collection , If set() This data already exists in the collection , I'm not putting this Request Put it in the queue . If set() There is no , Will this Request Object into the queue , Waiting to be scheduled .
44.Scrapy Advantages and disadvantages of framework
1) advantage :
- Scrapy It's asynchronous , His asynchronous mechanism is based on twisted The asynchronous network framework deals with , stay settings.py The specific concurrency value can be set in the file ( Default concurrency 16)
- Take something more readable xpath Instead of regular
- Powerful statistics and log System
- At the same time in different url Crawling up
- Support shell The way , Easy to debug independently
- Write middleware, Easy to write some unified filters
- It's piped into the database
2) shortcoming :
- Distributed crawling cannot be realized
- The asynchronous framework will not stop other tasks after errors , It's hard to detect when the data goes wrong
45.Scrapy and requests The difference between
1)scrapy It's a packaged framework , Contains downloaders 、 Parser 、 Log and exception handling , Based on Multithreading , twisted How to deal with , Can speed up our Downloads , No need to implement asynchronous framework by yourself . Poor scalability , inflexible .
2)requests It's a HTTP library , It is only used to make requests , about HTTP request , He's a powerful library , download 、 Parse all by yourself , More flexibility , High concurrency and distributed deployment are also very flexible .
46.Scrapy and Scrapy-Redis The difference between
Scrapy It's a Python The crawler frame , Climbing efficiency is very high , Highly customized , But it doesn't support distributed .
and Scrapy-Redis A set of based on redis database 、 Running on the Scrapy Components above the frame , It can make Scrapy Support distributed strategy ,Slaver End share Master End Redis In the database item queue 、 Request queue and request fingerprint set .
47. Why do distributed crawlers choose Redis database ?
because Redis Support master-slave synchronization , And the data is cached in memory , So based on the Redis Distributed crawler of , The high frequency reading efficiency of requests and data is very high .
Redis The advantages of :
- Data read fast , Because the data is stored in memory
- Support transaction mechanism
- Data persistence , Support snapshots and logs , Easy to recover data
- With a wealth of data types :list,string,set,qset,hash
- Support master-slave replication , Data can be backed up
- Rich features : Can be used as a cache , Message queue , Set expiration time , Automatically delete when due
48. What problems do distributed crawlers mainly solve ?
IP、 bandwidth 、CPU、io Other questions .
49.Scrapy How does the framework implement distributed crawling ?
Can use scrapy_redis Class library to implement .
In distributed crawling , There will be master The machine and slave machine , among ,master As the core server ,slave For the specific crawler server .
stay master Installation on server Redis database , And we're going to grab url Store in redis In the database , be-all slave Crawler server in the crawl time from redis Database to link , because scrapy-redis Its own queue mechanism ,slave Acquired url They don't conflict with each other , The results of the fetch are then stored in the database .master Of redis The database will also fetch url Are stored , To heavy .