当前位置:网站首页>Automatic classification of defective photovoltaic module cells in electronic images
Automatic classification of defective photovoltaic module cells in electronic images
2022-07-07 21:27:00 【wyypersist】
Automatic classification of defective photovoltaic module cells inelectroluminescence images
Automatic classification of defective photovoltaic module cells in electroluminescence images
//2022.7.2 In the morning 8:57 Start reading notes
Address of thesis
Contribution of thesis
The contribution of this paper includes three parts . First , We propose a resource efficient framework , It is used to supervise and classify defective solar cells using hand-made features and support vector machine classifiers , Support vector machine classifier can be used in a wide range of commodity hardware , Including tablet computers and unmanned aerial vehicles equipped with low-power single board computers . Low computational requirements make EL On site evaluation of images becomes possible , Similar to the analysis of low resolution infrared images (Dotenco wait forsomeone ,2016). secondly , We propose a supervised classification framework using convolutional neural networks , The frame is slightly more precise , But you need GPU Carry out effective training and classification . especially , We show how to incorporate uncertainty into these two frameworks , To improve classification accuracy . Third , We provide an annotation data set to the community , The data set is made from high resolution EL Extracted from the image 2624 Aligned solar cells , We use this data set to evaluate and compare the proposed methods extensively .
The content of the paper is
1. Introduce
Solar modules are usually protected by aluminum frames and glass laminations , In case of rain 、 Environmental impacts such as wind and snow . However , These protective measures do not always prevent photovoltaic modules from falling during installation 、 Branches fall 、 Mechanical damage caused by hail or thermal stress . Besides , Making mistakes ( Such as welding failure or wire defect ) It may also cause damage to photovoltaic modules . Defects in turn reduce the power efficiency of solar modules . therefore , It is necessary to monitor the condition of solar modules , And replace or repair defective units , To ensure the maximum efficiency of solar power plants .
Even for trained experts , Visual recognition of defective units is also particularly difficult . Except for obvious cracks on the glass , Many defects that reduce the efficiency of photovoltaic modules are invisible to the naked eye . contrary , Visible defects do not necessarily reduce module efficiency .
In order to accurately determine the efficiency of the module , The electrical output of the module must be measured directly . However , Such measurements require manual interaction with a single unit for diagnosis , Therefore, they cannot be well extended to large solar power plants with thousands of photovoltaic modules . Besides , Such measurements capture only one point in time , Therefore, some types of small cracks may not be revealed , as time goes on , This will be a problem (Kajari Schröder wait forsomeone ,2012).
infrared (IR) Imaging is a non-destructive 、 Non contact alternatives , Used to evaluate the quality of solar modules . Damaged solar modules can be easily identified by solar cells that are partially or completely disconnected from the circuit . therefore , Solar energy is no longer converted into electricity , Thus heating the solar cell . then , The emitted infrared radiation can be imaged by an infrared camera . However , The resolution of infrared camera is relatively low , Therefore, small defects that have not affected the photoelectric conversion efficiency of solar modules cannot be detected , Such as microcracks .
Electroluminescence (EL) imaging (Fuyuki wait forsomeone ,2005;Fuyuki and Kitiyanan,2009) It is another mature non-destructive technology for fault analysis of photovoltaic modules , It can image solar modules with higher resolution . stay EL Image , Defective cells look darker , Because the disconnected part will not radiate . In order to obtain electroluminescence image , Apply current to photovoltaic modules , Thus in 1150 nm Induced electroluminescence at the wavelength of . Emission can be achieved through silicon charge coupled devices (CCD) Sensor imaging . High spatial image resolution can detect microcracks (Breitenstein wait forsomeone ,2011),EL The image will not be blurred by transverse heat propagation . However ,EL Visual inspection of images is not only time-consuming and expensive , But also need trained experts . In this work , We propose an automatic classification EL Method of defect in image , Thus, this constraint is eliminated .
Generally speaking , Defects in solar modules can be divided into two categories (Fuyuki and Kitiyanan,2009):(1) Inherent defects due to material properties such as grain boundaries and dislocations , as well as (2) External defects caused by process , Such as microcracks and fractures , as time goes on , These defects will reduce the overall efficiency of the component .
chart 1 Examples with different types of defects are shown EL Images . chart 1(a) and (b) It shows the general material defects in the production process , For example, pointer interrupt , Unless it is caused by high strain at the solder joint , Otherwise, the service life of the affected solar panels will not necessarily be shortened (Köntges wait forsomeone ,2014). To be specific , The efficiency reduction caused by pointer interruption is its size 、 Complex interaction between location and number of interrupts (De Rose wait forsomeone ,2012;Köntges wait forsomeone ,2014). chart 1(c) to (e) Shows microcracks 、 Degradation of battery interconnection , And batteries with electrically separated or degraded parts that are known to reduce module efficiency . In particular, the detection of microcracks requires a camera with high spatial resolution .

For defect detection during monitoring , You can set different goals . Highlight the exact location of defects in the solar module , It can monitor the affected area with high accuracy . However , For the quality evaluation of the whole PV module , The exact location of defects in solar cells is not important . For this task , The overall possibility of indicating cell defects is more important . This can quickly identify defect areas , And it may supplement the prediction of future efficiency loss in photovoltaic modules . In this work , We propose two classification pipelines that automatically solve the second task , That is, determine the possibility of each unit defect that may lead to efficiency loss .
The classification methods studied in this paper are support vector machine and neural network classifier .
Support vector machine (SVM) According to from solar cells EL Various features extracted from the image are trained .
Convolutional neural networks (CNN) Directly input the image pixels and corresponding labels of solar cells .
Support vector machine method is especially efficient in the process of training and reasoning . This allows the method to be operated on a wide range of commodity hardware , For example, tablet computers or drones , Their use depends on their respective application scenarios . contrary ,CNN The prediction accuracy of is usually higher , Training and reasoning are more time-consuming , Usually GPU Run in an acceptable short time . However , Especially for aerial images , There may be other problems , Need to be solved .Kang and Cha(2018) Several challenges that need to be addressed before applying our approach outside the manufacturing environment are highlighted .
1.1 contribution
The contribution of this paper includes three parts . First , We propose a resource efficient framework , It is used to supervise and classify defective solar cells using hand-made features and support vector machine classifiers , Support vector machine classifier can be used in a wide range of commodity hardware , Including tablet computers and unmanned aerial vehicles equipped with low-power single board computers . Low computational requirements make EL On site evaluation of images becomes possible , Similar to the analysis of low resolution infrared images (Dotenco wait forsomeone ,2016). secondly , We propose a supervised classification framework using convolutional neural networks , The frame is slightly more precise , But you need GPU Carry out effective training and classification . especially , We show how to incorporate uncertainty into these two frameworks , To improve classification accuracy . Third , We provide an annotation data set to the community , The data set is made from high resolution EL Extracted from the image 2624 Aligned solar cells , We use this data set to evaluate and compare the proposed methods extensively .
chart 2 The evaluation results of solar panels using the proposed convolutional neural network are shown .EL Each solar cell in the image is covered by the possibility of defects in the corresponding unit .

1.2 summary
The rest of this work is organized as follows . The first 2 This section reviews the related work . The first 3 Section describes two proposed classification methods . In the 4 In the festival , We evaluated and compared these methods , The results are discussed . This work is in the 5 End of section .
2. Related work
adopt EL Imaging visual inspection of solar modules is an active research topic . However , The focus of most related work is to detect specific internal or external defects , Instead of predicting the defects that will eventually reduce the power efficiency of solar modules . Solar cell EL The detection of surface anomalies in images is related to structural health monitoring . However , It should be noted that , Some defects in solar cells are only specific to photovoltaic modules EL imaging . for example , Completely disconnected solar cells are only displayed as dark image areas ( It's similar to the picture 1(d)), Therefore, there is no comparable equivalent in terms of structural defects . Besides , Surface irregularities in solar wafers ( For example, finger interruption ) It is easily confused with battery cracks , Even if they do not significantly affect power loss .
In the context of visual inspection of solar modules ,Tsai wait forsomeone (2012) Use Fourier image reconstruction to detect polycrystalline photovoltaic modules EL Defective solar cells in the image . The external defect of the target is ( Small ) Crackle 、 Broken and broken fingers . Fourier image reconstruction eliminates possible defects by setting the high-frequency coefficient associated with line and strip artifacts to zero . Then convert the spectral representation back to the spatial domain . Then the defect can be recognized as the intensity difference between the original image and the high pass filtered image . Because of the shape assumption , This method is difficult to detect defects with more complex shapes .
Tsai wait forsomeone (2013) A supervised learning method is also introduced , Used to use independent component analysis (ICA) Basic image recognition defects . Using independent component analysis (ICA), Find a set of independent base images by using the sub images of flawless solar cells . The method in 300 It is implemented on a relatively small training data set of solar cell sub images 93.40% High precision of . However , Material defects such as finger interruption are treated as battery cracks . therefore , This strategy is only applicable to detect every abnormality on the surface of solar cells , It is not suitable for predicting future energy losses .
Anwar and Abdullah(2014) A microcrack detection algorithm for polycrystalline solar cells is developed . They use anisotropic diffusion filtering , Then perform shape analysis , To locate defects in solar cells . Although this method performs well in detecting microcracks , But it does not consider other defect types , For example, in EL The image shows completely dark and completely disconnected cells .
Tseng wait forsomeone (2015) A method for automatically detecting finger interruption in single crystal solar cells is proposed . This method uses binary clustering of candidate region features to detect defects . However , Finger interruption may not provide a suitable clue for predicting future power loss .
The success of deep learning has led to the gradual replacement of the traditional pattern recognition pipeline for optical detection . However , As far as we know , Has not been proposed for EL Graphic CNN framework , But it only applies to other modes or applications . Most closely related is Mehta wait forsomeone (2018 year ) The job of , They have proposed a method from solar modules RGB Image prediction power loss 、 Positioning and dirt type system . Their method does not require manual positioning of labels , But operate on the image , And take the corresponding power loss as the input .Masci wait forsomeone (2012) An end-to-end maxpooling CNN, Used to classify steel defects . Compare its network performance with multiple handmade feature descriptors trained by support vector machine . Although their data set contains only 2281 A training image and 646 A test image , but CNN The classification accuracy of the framework for steel defects is at least twice that of support vector machine . Zhang et al (2016) This paper presents a method for detecting road cracks CNN framework . For training CNN, Used about 45000 Manually marked image blocks . They show that ,CNN The performance is much better than that of handmade features, and then through support vector machine and boosting The combination of .. Cha wait forsomeone (2017 year ) In a wide range of images taken under various environmental and lighting conditions , Use a very similar method to detect concrete cracks .Kang and Cha(2018) Using deep learning to monitor the structural health of aerial images .Cha wait forsomeone (2018 year ) Also studied based on fast R-CNN Defect location of segmentation method based on modern learning of framework , The framework can be executed in real time .Lee wait forsomeone (2019) Semantic segmentation is also used to detect cracks in concrete .
In medicine ,Esteva wait forsomeone (2017) Using deep neural network to classify different types of skin cancer . They are in a place by 129450 Clinical images and 2032 On a big data set composed of different diseases CNN Conducted end-to-end training , Make it possible to achieve a high degree of accuracy .
3. Method
We subdivide each module into its solar cells , And analyze each battery separately , Finally infer the possibility of defects . This decomposes the analysis into the smallest meaningful unit , That is, the mechanical design of photovoltaic modules connects the battery cells in series . Besides , Decomposition greatly increases the number of available data samples for training . For the segmentation of solar cells , We used recently developed methods (Deitsch wait forsomeone ,2018), This method keeps each battery in a normal state , No perspective and lens distortion .
Unless otherwise stated , Otherwise, the proposed method is applicable to the resolution of ×300 Large scale of pixel solar cells EL Images . The image resolution is derived from the original PV module EL The median size of the image area corresponding to a single solar cell in the image . The solar cell image is directly used as pipeline input . The image resolution of field solar cells usually deviates from the required resolution , Therefore, it must be adjusted accordingly .CNN The architecture sets the minimum image resolution , This resolution is usually equal to CNN The receiving field of ( for example , original VGG-19 Architecture use ×224 224). If the resolution is lower than this minimum resolution , You must enlarge the image . In order to obtain higher resolution , The network can be applied in a cross window way , Then bring the output together ( Average or maximum aggregation is usually used ). We used another method , In this way ,CNN The architecture inherently encodes this process . For support vector machine pipeline , The resolution requirement is not so strict . In view of the scale invariance of local features , The image resolution of classified solar cells does not need to be adjusted , And may vary depending on the image .
3.1. Use support vector machine for classification
A general method of classification using support vector machines (Cortes and Vapnik,1995) as follows . First , Extract local descriptors from the segmented image of photovoltaic cells . Features are usually at salient points ( Also known as keys ) Or dense pixel grid . For training classifiers and subsequent prediction , You need to calculate the global representation from the local descriptor set , It is often called encoding . Last , The global descriptor of solar cell is divided into defect descriptor and function descriptor . chart 3 Shows the classification pipeline , Including masking 、 Key point detection 、 Feature description 、 Coding and classification . We describe these steps in the following sections .

3.1.1. Masking
We assume that solar cells are separated from photovoltaic modules , for example , Use the automatic algorithm we proposed in our early work (Deitsch wait forsomeone ,2018). then , The binary mask allows the foreground of each cell to be separated from the background . The cell background includes image areas that do not normally belong to silicon wafers , For example, bus and boundary between units . This mask can be used to strictly restrict feature extraction to the interior of the cell . In the evaluation , We studied the usefulness of masking , And found that its impact is very small , That is, in a few features / The performance is only slightly improved in the classifier combination .
3.1.2. feature extraction
To train support vector machines , First, extract the feature descriptor . The location of these local features is determined using two main sampling strategies :(1) Key point detection and (2) Dense sampling . These strategies are shown in the figure 4 Shown . Both of these strategies produce different feature sets , It is more suitable for specific types of solar chips than other strategies . Dense sampling ignores image content , Instead, a fixed feature point configuration is used . On the other hand , The key detector depends on the texture in the image , Therefore, the number of key points is proportional to the number of high-frequency elements , Such as edges and corners ( Pictured 4(c) and (d) Shown ). Key detector usually works in scale space , It allows feature detection at different scale levels and in different directions . chart 4(d) Shows KAZE Detected key points . ad locum , Each key point has a different proportion ( Displayed by the radius of the corresponding circle ), There are also specific directions , For example, the line drawn from the center to the boundary of the circle . The key points of capture scale and rotation are invariant to the changes of image resolution and in-plane rotation , This makes them very robust .

Dense sampling by comparing it with ×n A grid composed of cells is superimposed to subdivide ×300 Photovoltaic cells for pixels . The center of each grid cell specifies the location where the feature descriptor is subsequently extracted . The number of feature locations depends only on the mesh size . If computing resources are very limited , Or the purpose is to identify only defects in single crystal photovoltaic modules , Then dense sampling is very useful .
We use the combination of different popular key point detectors and feature extractors in the literature , As shown in the table 1 listed , And summarized as follows .

Several algorithms combine key point detection and feature description . Perhaps the most popular of these methods is scale invariant feature transformation (SIFT)(Lowe,1999), It detects and describes features on multiple scales .SIFT For rotation 、 Translation and scaling invariance , And it has partial elasticity to different lighting conditions . Accelerate robust features (SURF)(Bay wait forsomeone ,2008) yes SIFT A faster variant of , It also includes a key detector and a local feature descriptor . However ,SURF The detector part of is not invariant to affine transformation . In the initial experiment , We cannot successfully use SIFT and SURF Key point detector , Because the key point detector sometimes cannot detect the features in the relatively uniform single crystal cell image , So we only use the descriptor part .
KAZE(Alcantarilla wait forsomeone ,2012) It is a multiscale feature detector and descriptor . Key point detection algorithm and SIFT Very similar , It's just SIFT The linear Gaussian scale space used is replaced by nonlinear diffusion filtering . However , For feature description ,KAZE Use SURF The descriptor .
We also studied adaptive and universal acceleration segment testing (AGAST)(Mair wait forsomeone ,2010) As a special key detector without descriptor . It is based on a random forest classifier trained on a set of corner features , These features are called from accelerated segment testing (FAST) Characteristics of (Rosten and Drummond,20052006).
In the special descriptor , Visual text pyramid histogram (PHOW)(Bosch wait forsomeone ,2007) yes SIFT An extension of , It computes intensively on a uniformly distributed grid SIFT The descriptor . We use VLFEAT Implementation variants of (Vedaldi and Fulkerson,2008). Similarly , Directional gradient histogram (HOG)(Dalal and Triggs,2005) It is a gradient based feature descriptor intensively calculated on a group of uniform image blocks . Last , We also use the visual geometry Group (VGG) The descriptor , Use effective optimization methods for end-to-end training (Simonyan wait forsomeone ,2014). In our implementation , We used 120 Dimensional real value descriptor variable .
We omit binary descriptors from this selection . Although binary feature descriptors are usually very fast , But their performance is usually not better than that of real valued descriptors (Heinly wait forsomeone ,2012).
3.1.3 Combination of detector and extractor
To determine the most powerful feature detector \ Extractor combination , We evaluated all feature detector and feature extractor combinations , There are only a few exceptions .
in the majority of cases , We have not adjusted the parameters of the key detector , Nor did you adjust the parameters of the feature extractor , But use OPENCV(ITSEZ,2017) since 3.3.1 The default value from version . One notable exception is AGAST, We reduce the detection threshold to 5, In order to be able to detect the key points in single crystal photovoltaic modules . about SIFT and SURF, Similar adjustments have not been successful , This is why we only use their descriptors .HOG You need to overlap the mesh of the image area , This is incompatible with the key detector . contrary , We will 300×300 Pixel cell image down sampled to 256 X 256 Pixels ( Nearest 2 The power of ) Feature extraction . Due to implementation specific limitations , omitted HOG The shielding . Considering these exceptions , We made an overall assessment 12 A combination of characteristics .
3.1.4 code
The calculated features are encoded into the global feature descriptor . The purpose of encoding is to form a single fixed length global descriptor from multiple local descriptors . Coding is usually expressed as a histogram that extracts statistical information from the background model . So , We use the local aggregation descriptor vector (VLAD)(Jégou wait forsomeone ,2012), This provides a compact, state-of-the-art representation (Peng wait forsomeone ,2015).VLAD Coding is sometimes used for classification 、 Identify and retrieve features based on deep learning in tasks (Gong wait forsomeone ,2014;Ng wait forsomeone ,2015;Paulin wait forsomeone ,2016;Christlein wait forsomeone ,2017).
VLAD The dictionary is based on the subset of random feature descriptors in the training set k Mean clustering . For performance reasons , We use k-means Fast small batch variant of (Sculley,2010). Cluster centroid µk Corresponding to the positioning point of the dictionary . then , Aggregate the first-order statistics into all descriptors extracted from the solar cell image

Sum of residuals of . The residual is based on the nearest anchor in the dictionary µk Calculated by

among :

Is the indicator function of cluster membership , That is to say :

This shows that x Whether it is µk The nearest neighbor of . Final VLAD Express

Corresponding to all remaining items (1) Series to Kd D vector :

In order to make VLAD Descriptor is robust , Several normalization steps are required . Power normalization solves the problem that some local descriptors appear more frequently than others . here , global descriptor

Each element of is normalized to :

among , We choose from the literature

As a typical value . After power normalization , The vector is normalized , Make it - The norm is equal to 1.
Similarly , If at least two descriptors often appear together , There may be too many co occurrences .Jégou and Ondřej(2012) indicate , Principal component analysis (PCA) Albinism effectively eliminates such co-occurrence , And further eliminate the correlation of data .
To enhance codebook D For probability k Robustness of potential suboptimal solution of mean clustering , We calculated five from different training subsets using different random seeds VLAD Express . then , adopt PCA(Kessy wait forsomeone ,2016), Yes VLAD Concatenation of codes

Conduct joint decorrelation and albinism . The transformed representation is normalized again , Make it - The norm is equal to 1, The result is finally passed to the support vector machine classifier .
3.1.5. Support vector machine training
We use linear and radial basis function kernels to train support vector machines . For linear kernels , We use LIBLINEAR(Fan wait forsomeone ,2008), It is optimized for linear classification tasks and large data sets . For nonlinear RBF nucleus , We use LIBSVM(Chang and Lin,2011).
Support vector machine hyperparameters are evaluated by using grid search in the internal fivefold cross validation of the training set F1 fraction (van Rijsbergen,1979) To determine the . For linear support vector machines , We adopt 2 punishment . Penalty parameters C Is from a group 10 Power of , namely

. about RBF Support vector machine , Penalty parameters C Determined by a smaller set . Nuclear coefficient The search space of is constrained to , among S Indicates the number of training samples .
3.2 Regression using deep convolution neural networks
We considered several kinds of training CNN The strategy of . Given the limited amount of data we have , The best results are achieved through transfer learning . We used VGG-19 Network architecture (Simonyan and Zisserman,2015), First use 128 Ten thousand images and 1000 There are two classes in IMAGENET Data sets (Deng wait forsomeone ,2009) Training . then , We optimized the network using our dataset .
We use the global average pool (GAP) Replace VGG-19 Two fully connected layers of (Lin wait forsomeone ,2013), And separately 4096 and 2048 Two neurons replace two completely connected layers ( See the picture 5). The gap layer is used to make VGG-19 Network input tensor (×224 224 3) With the resolution of our solar cell image samples (×300 3) compatible , To avoid additional down sampling of samples . The output layer consists of a single neuron , Defect probability of output cells . By minimizing the mean square error (MSE) Loss function pair CNN To optimize . therefore , We essentially trained the deep regression network , The network allows us to use only two defect likelihood categories ( Functionality and defect ) To predict the ( continuity ) Defect probability . By rounding the predicted continuous probability to the nearest neighbor of the four original classes , We can directly CNN The decision is compared with the original ground truth label , There is no need to binarize it .

Data enhancement is used to generate additional 、 Slightly disturbed training samples . However , Enhance variability and keep it moderate , Because the segmented cells change only a few pixels along the translation axis , It changes only a few degrees along the axis of rotation . The training samples are at most... Of the original resolution 2% The zoom . The rotation range is limited to ±°3. The translation is limited to... Of the cell size ±2%. We also use random flipping along the vertical and horizontal axes . Because the bus can be arranged vertically and horizontally , We also include precise rotation 90° Training sample . The rotating sample is increased in the same way as above .
We fine tune the pre training data IMAGENET Model , In order to make CNN Adapt to new tasks , Be similar to Girshick wait forsomeone (2014). However , We did it in two stages . First , We only train fully connected layers with random initialization weights , At the same time, keep the weight of convolution block fixed . ad locum , We use ADAM Optimizer (Kingma and Ba,2014), The learning rate is 10^-3, Exponential decay rate =0.91 and =0.9992, Regularization value =10^-8. In the second step , We refine the weights of all layers . At this stage , We use random gradient descent (SGD) Optimizer , The learning rate is 5·104, Momentum is 0.9. We observed that , Compared with a single refinement step , Fine tune in several stages by subsequently increasing the number of superparameters CNN Slightly improve the generalization ability of the result model .
In these two stages , We are in two NVIDIA GeForce GTX 1080 In order to 16 Small batch processing of samples 1968 Enhanced version of training samples , And run at most 100 individual epoch Training process of . This amounts to 196800 Primitive 1968 Enhanced variants of training samples , Used to optimize the network . In order to realize deep regression network , We use... On the back end KERAS edition 2.0(Chollet wait forsomeone ,2015) and TENSORFLOW edition 1.4(Abadi wait forsomeone ,2015).
4. evaluation
For quantitative evaluation , We first evaluate the different feature descriptors extracted intensively on the grid . then , We compare the optimal configuration with the feature descriptor extracted at the key points of automatic detection , To determine the best performance change of support vector machine classification pipeline . Last , We associate the latter with the depth of presentation CNN Compare , And visualize CNN Internal feature mapping .
4.1 Data sets
We propose a high resolution from single crystal and polycrystalline photovoltaic modules EL The public data set of solar cells extracted from the image 1(Buerhop-Lutz wait forsomeone ,2018). The data set is composed of 2624 Images of solar cells , A resolution of ×300 Pixels , First from 44 Extracted from different photovoltaic modules , among 18 Components are of single crystal type ,26 One is polycrystalline .
The image of the photovoltaic module used to extract a single solar cell sample is taken in the manufacturing environment . This controlled condition can control the quality of the imaging panel to a certain extent , And allows minimizing negative effects on image quality , For example, overexposure . Because the background radiation can dominate EL radiation , Therefore, control conditions are also needed . Since the photovoltaic module only emits light when collecting in the dark room , Therefore, it can ensure that the image is evenly illuminated . This is contrary to image acquisition in general structural health monitoring , The latter introduces additional degrees of freedom , The image may be affected by shadows or spotlights (Cha wait forsomeone ,2017 year ). However , An important problem in electroluminescence imaging is , Due to improper focusing of lens , The electroluminescence image is blurred ( Namely out of focus ), Sometimes difficult to achieve . therefore , We ensure that such images are included in the proposed data set ( for example , See chart 1).A
Solar cells exhibit inherent and extrinsic defects commonly found in single crystal and polycrystalline solar modules . especially , Data sets include microcracks and batteries with electrically separated and degraded parts 、 Short circuit the battery 、 Open circuit interconnection and welding failure . as everyone knows , These battery defects will affect the efficiency of solar cell modules 、 Negative impact on reliability and durability . The power loss caused by such defects is usually negligible , Therefore, finger interruption is not included .
Power attenuation measurements cannot be provided ground-truth. contrary , The extracted cells are presented to the familiar in random order EL Recognized experts in the complex details of different defects in images .Köntges wait forsomeone (2014) The criteria for such failures are summarized . In fault classification , Experts are particularly concerned that the known power loss exceeds the initial power output 3% The defects of . The expert answered the question (2) Whether the cell function is normal or defective ?(2) Do you have confidence in your assessment ? The evaluation of function and defective cells by confident raters is directly used as a label . Both functional and non self-confidence assessments of defective cells were marked as defective . To reflect the uncertainty of the rater , Assign a lower weight to these assessments , That is, the non confidence evaluation weight of functional cells is 33%, The non confidence evaluation weight of defective cells is 67%. surface 2 In conclusion , On the left is the rater's assessment , On the right are the relevant classification labels and weights . surface 3 Shows ground-truth Distribution of solar cell labels , Separate according to the type of source PV module .


We use 25% Labeled cells (656 Cells ) To test , rest 75%(1968 Cells ) Training . Stratified sampling is used to randomly segment samples , At the same time, the distribution of samples in different categories in the training set and the test set is preserved . To further balance the training set , We use from King and Zeng(2001) Inverse heuristic weighting class :

among S Is the total number of training samples ,nj It's a function (=j 0) Or defect (=j 1) Number of samples .
4.2 Dense sampling
In this experiment , We evaluated the use for subdividing individual ×300 Different grid sizes of pixel cell images . The number of grid points per cell is 5×5 To 75 ×75 Changes between points . At each grid point , Calculation SIFT、SURF and VGG The descriptor . The remaining two descriptors PHOW and HOG Omitted in this experiment , Because they do not allow you to arbitrarily specify the location of descriptor calculation . Be careful , stay 75×75 On the grid of points , The distance between two grid points is only 4 Pixel , This results in significant overlap between adjacent descriptors . therefore , Further improving the mesh resolution can not significantly improve the classification results .
The goal of this experiment is to find the best combination of grid size and classifier . We trained linear support vector machine and support vector machine with radial basis kernel . For each classifier , We also studied two additional options , That is, add sample weight w( See table 2) Or mask the background area ( See also 3.1.1 section ) Whether the classifier can be improved .
Use F1 Scores measure performance ,F1 The score is the harmonic average of precision and recall . chart 6 Shows each category F1 Average score F1 fraction . From left to right , These scores are shown as SURF The descriptor ( chart 6(a))、SIFT The descriptor ( chart 6(b)) and VGG The descriptor ( chart 6(c)). here ,VGG Descriptors use Weighted and masked Linear support vector machine in the size of ×65 65 Get the highest score on the grid .SIFT Is the second best descriptor , When using weighted linear support vector machine ×60 60 Best performance on grid , But there is no cover .SURF The lowest score , Use weighted RBF Support vector machine in ×70-70 A peak appears at the grid , But there is no cover . It turns out that , The more grid points , The better .SURF The classification accuracy of grows slowly , The saturation rate is about 70%.SIFT and VGG Benefit more from denser grids . in the majority of cases , The weight w The use of will lead to higher scores , Because the classifier can rely more on the more confident samples of expert labeling . Masking is also improved VGG The characteristics of the F1 fraction . However , Compared with the overall performance change of the configuration , almost 2% The improvement is small . so to speak , In view of the high density of feature points and the degree of overlap between image regions evaluated by the feature extractor , Cell structure is not important for distinguishing different types of cell defects .

4.3. Dense sampling and key point detection
This experiment aims to compare the classification performance of features based on dense grids and features based on key points . So , The best performance of each descriptor in the previous experiment is compared with the combination of key detector and feature descriptor .
chart 7 Shows the evaluated single crystal cells 、 Polycrystalline battery and detector and extractor combination of both . Most detectors / The extractor combination consists of a forward slash ( detector / The descriptor ) Appoint . Entries without forward slashes , namely KAZE、HOG and PHOW, Indicates that the features of the detector and descriptor have been included . The three best performing methods on dense meshes are represented as dense SIFT×60、 dense SURF×70 And dense VGG×65. Unless otherwise specified , Otherwise, use sample weighting 、 No masking and linear support vector machine for feature training .

Use ROC The curve shows the performance , This curve shows the performance of binary classifier under various false positive rates (Fawcett,2006). Besides , The graph shows the front 4 Characteristic AUC fraction , The highest AUC Emphasize in bold . In all three cases ,KAZE \/VGG Better than other feature combinations , Of all modules AUC by 88.51%, The second is KAZE \/SIFT,AUC by 87.22%. As an exception , Just AUC for , The second best feature combination of polycrystalline solar cells is PHOW. The gray dotted line represents the baseline of the random classifier . in general , Using keys has better performance than dense sampling .
4.4. Support vector machines and transfer learning using deep regression Networks
chart 8 And CNN Classifiers compare , Shows the strongest support vector machine variant KAZE \/VGG Performance of . chart 8(a) Left side ROC The curve contains the results of single crystal photovoltaic modules . chart 8(b) It provides the classification performance of polycrystalline photovoltaic modules . Last , The overall classification performance of the two models is shown in the right figure 8(c) Shown .

It is worth noting that , The classification performance of support vector machine and neural network for single crystal photovoltaic modules is very similar .CNN The average performance of is only slightly better than SVM. When the false positive rate is lower than 1% Left and right ,CNN A higher true positive rate was obtained . However , At about 1% To 10% The false positive rate of , Support vector machines perform better . This shows that KAZE \/VGG The ability to capture anomalies on a uniform surface is almost as good as training directly on image pixels CNN Just as accurate .
For polycrystalline photovoltaic modules , stay AUC aspect ,CNN Be able to compare SVM More accurate prediction of defective solar cells is almost 11%. Because there are many kinds of textures in solar cells , This is obviously a more difficult test .
in general ,CNN be better than SVM. However , The overall performance difference between the two classifiers is only 6% about . therefore , Support vector machine classifiers can also be used when they are not available CNN Fast in the case of dedicated hardware 、 On site evaluation of photovoltaic modules .
4.5. Model performance for each defect category
ad locum , We report in detail the proposed model in the single solar cell category according to the confusion matrix ( Defects and functions ) Performance of . The two-dimensional confusion matrix stores the correctly identified cell proportion ( True false sex and true positive ) In each category on its main diagonal . The secondary diagonal provides a false identification of solar cells relative to other categories ( False negative and false positive ) The proportion of .
chart 9 Shows the confusion matrix of the proposed model . The confusion matrix of each solar chip and its combination is given . The vertical axis of the confusion matrix specifies the expectation ( That is, the ground is real ) label , The horizontal axis specifies the label of the corresponding model prediction . ad locum ,CNN The prediction threshold of is 50%, To produce two types of functions (0%) And defects (100%) Solar cell .
About single crystal photovoltaic modules , chart 9(a) and (d) The confusion matrix in emphasizes that the two models provide comparable classification results . However , And CNN comparison , Linear support vector machine can correctly identify more defective cells , But the cost is that functional cells are recognized as defects ( false negative ). So , Linear support vector machine is used to identify defective solar cells as complete ( False positives ) There will also be minor errors .
In the figure 9(b) and (e) Given the polycrystalline case ,CNN In each class, it is obviously superior to linear support vector machine . This has also led to CNN The overall performance is better in both cases , Pictured 9(c) and (f) Shown .

chart 9 notes : The confusion matrix of the proposed classification model . Each row of the confusion matrix stores the relative frequency of instances in the expected defect likelihood category . On the other hand , These columns contain the relative frequencies of the prediction instances made by the classification model . Ideally , Only the diagonal of the confusion matrix will contain non-zero terms , This corresponds to the perfect consistency between the basic truth value and the classification model in all categories .CNN Usually based on KAZE/VGG Feature trained support vector machines produce less prediction error .
4.6. The influence of training data set size on model performance
To train linear support vector machines and CNN, A relatively small unique solar cell image data set is used . Considering that the daily output of a typical photovoltaic module production line is 1500 A component , Contains about 90000 A solar cell , It is expected that the model will greatly benefit from additional training data . To test if more training samples are used , How to improve the proposed model , We evaluated their performance on the subset of original training samples , Because no additional training samples are available .
To infer performance trends , We evaluated the model on three subsets of different sizes of the original training sample . We used 25%、50% and 75% The original training sample . In order to avoid deviation in the obtained indicators , We not only randomly sample subsets , And for each subset 50 Sub sampling , To obtain samples for training models . Besides , We also use stratified sampling to preserve the distribution of labels in the original training sample set . To evaluate performance , We use the original test sample , And provide the results of three indicators :F1 fraction 、ROC AUC And accuracy .
chart 10 The distribution of evaluation scores on all samples of three training sample subsets of different sizes used to train the proposed model is shown . Each of the three subsets has 50 The distribution of points is summarized in the box diagram . The results clearly show that the performance of the proposed model increases logarithmically with respect to the number of training samples commonly observed in visual tasks (Sun wait forsomeone ,2017).

4.7. CNN Feature space analysis
ad locum , We use t- Distributed random neighborhood embedding (t-SNE) analysis CNN Characteristics of learning (van der Maaten and Hinton,2008), This is a manifold learning technique for dimensionality reduction . The purpose is to test the separation standards of different solar cells . So , We use t-SNE Barnes' cabin variant (van der Maaten,2014), Its speed is much faster than the standard implementation . To calculate embedding , We will tSNE The confusion parameter of is fixed as 35. Because our test data set is small , We avoid using PCA Initial dimensionality reduction of features , Instead, use embedded random initialization .
all 656 The results of test images are shown in Figure 11 Shown . Each point corresponds to from 2048 dimension CNN The last layer is projected onto the two-dimensional eigenvector . The projection feature vectors extracted from single crystal and polycrystalline modules are encoded in red and blue respectively . The defect probability is encoded by saturation . The two-dimensional representation retains the structure of the high-dimensional feature space , And show that in most cases , Similar defect probabilities coexist in the feature space . This makes CNN The classifier can distinguish between defective solar cells and functional solar cells EL Images .

An important observation is , This kind is absolutely flawed (100%) The batteries form a single slender cluster ( The lower left corner ), Including batteries , It has nothing to do with the type of source photovoltaic module . On the contrary , Functional cells (0%) Divided into different clusters , This depends on the type of source PV module . The overall appearance of the battery ( That is, the number of welded joints 、 Texture, etc ) In single crystal clusters ( On the right side ) There are also several branches in . These branches include samples grouped by the number of bus welded joints in the unit . here , Due to the uniformity of silicon wafer ( No texture ) The surface of the , Branching ratio functional polysilicon unit cluster ( Upper right corner ) The separation in is more obvious .
There may be defects (33%) And may be defective (67%) Clustering of cells is mixed . The high degree of confusion between these samples stems from the size of the remaining two types of high confidence samples in our data set , The size of the corresponding category is relatively small ( See table 3). Besides , The samples of these two categories are at the boundary between defects and non defects that can be clearly distinguished , May stimulate fuzzy decisions .
4.8. Qualitative results
chart 12 Qualitative results are provided for the selection of single crystal and polycrystalline solar cells , And by the proposed CNN Infer the corresponding defect possibility . To facilitate comparison with the ground truth label , By rounding the probability to the nearest category , take CNN The defect probability is quantified into four categories corresponding to the original label . This selection includes solar cells that are correctly classified and incorrectly classified , There are minimum and maximum square distances between the prediction probability and the ground truth labels respectively .
In order to highlight the class specific distinguishing areas in the solar cell image , You can use class activation diagrams (CAM)(Zhou wait forsomeone ,2016;Selvaraju wait forsomeone ,2017;Chattopadhay wait forsomeone ,2018). However , Because of its coarse resolution ,CAM It is not directly applicable to the accurate segmentation of defect areas .CAM Can still provide clues , Explain why convolution networks infer the probability of a particular defect . So , chart 12 The solar cell in is improved from VGG-19 The last convolution block of the network (×18 18 512) Extracted CAM Additional coverage , And use Chattopadhay wait forsomeone (2018) Method to enlarge it to the original resolution 300 X 300 Solar cell image .

Interestingly , Even if CNN Incorrectly classify defective solar cells as functional ( See chart 12(b) The last column in ),CAM You can still highlight the image area of potential defects . therefore ,CAM It can supplement the fully automatic evaluation process , And provide decision support in complex situations during visual examination . A special problem that can be seen from the cam inspection is , Finger breaks are not always clearly discernible from actual defects . However , This can be trained by including corresponding samples CNN To achieve .

In the figure 13 in , We showed CNN Prediction of complete polycrystalline solar modules . The ground live label is represented by a red shaded circle in the upper right corner of each solar cell . Again , Solar cells are CAM Cover , And weighted by network prediction , To reduce the amount of visual confusion . clear through CAM, Can be observed CNN The focus is on the special defects in solar cells , These defects are more difficult to identify than those more obvious in the same battery , For example, degraded or electrically insulated battery components ( Display as dark areas ).
4.9 Runtime evaluation
ad locum , We evaluated every step of the support vector machine pipeline and CNN Time spent during training and testing . The runtime is running Intel i7-3770K CPU Evaluate on the system ,CPU The clock is 3.50GHz, Memory is 32GB. The result is shown in Fig. 14 Shown .

It is as expected , The training of both models took most of the time . Although training support vector machines requires 30 About minutes . elaboration CNN The speed of is almost the same 10 times , need 5 Hour or so . however , Use CNN The reasoning speed of is much faster than that of the support vector machine pipeline , In support vector machine 8 In less than minutes 20 second . However , It should be noted that , The duration of support vector machine pipeline reasoning is CPU Performed on , And faster CNN Reasoning lasts only GPU Get on . Besides , Only a part of the support vector machine pipeline executes processing in parallel . When in CPU Run highly parallel CNN Inference time , The test time increased significantly to 12 Minutes or more . therefore , stay CPU Training CNN It becomes difficult , Therefore, we avoid measuring the corresponding runtime .
Considering the relative contribution of a single support vector machine pipeline step , Feature extraction is the most time-consuming , Secondly, local feature coding and clustering ( See chart 15). Feature preprocessing and hyperparametric optimization require the least .

In applications that require not only low resource consumption but also fast running , Can pass SIFT or PHOW Replace VGG Feature descriptor to reduce the total execution time of support vector machine pipeline . These two feature descriptors are maintained with VGG Descriptor similar classification performance at the same time , The feature extraction time during reasoning is changed from the initial 8 Minutes are reduced to 23 The second and 12 About seconds .
4.10. Discuss
Several conclusions can be drawn from the evaluation results . First , If the spatial distribution of key points is quite sparse , Then masking may be very useful . However , in the majority of cases , Masking does not improve classification accuracy . secondly , Weighting samples proportionally according to the confidence degree of defect possibility in the unit does improve the generalization ability of the learning classifier .
Using linear support vector machine training KAZE/VGG Feature is the best performance support vector machine pipeline variant , Accuracy rate is 82.44%,F1 The score is 82.52%.CNN Even more accurate . It distinguishes between functioning and defective solar cells , Accuracy rate is 88.42%. Corresponding F1 The score is 88.39%. adopt t-SNE Yes CNN The two-dimensional visualization of feature distribution emphasizes that the network learns the actual structure of the task at hand .
One limitation of this method is that each solar cell is inspected independently . especially , Some types of surface abnormalities that do not affect the efficiency of the module can occur in a repeated pattern between cells . The precise classification of this large-scale effect needs to consider context , It depends on the future work .
Instead of predicting the likelihood of defects , It is better to predict specific defect types . Give training data beyond the quota , Given additional training data with appropriate labels , Without major changes ( for example , By fine tuning the new defect category ) Apply the method proposed in this work . However , Fine tune the network to multiple defect categories , To predict the type of defect rather than its probability , It usually affects the choice of loss function , Thus affecting the number of neurons in the last activated layer . The common choice of loss function for such tasks is ( classification ) Cross entropy loss and softmax Activate (Goodfello wait forsomeone ,2016).
5. summary
We propose a general framework for training support vector machines and Neural Networks , It can be used to identify high resolution EL Defective solar cells in the image . The processing pipeline of support vector machine classifier is carefully designed . In a series of experiments , The pipeline with the best performance is determined as one of the linear support vector machines based on sample training KAZE/VGG features , This sample considers the confidence of the labeling machine .CNN The network is based on VGG-19 Fine tune the return network , Train on enhanced cell images , Label confidence is also considered .
On single crystal solar modules , The performance of these two classifiers is similar , about CNN On average, there is only one advantage . However , On more heterogeneous polycrystalline cells ,CNN Classifier ratio SVM The accuracy of the classifier is about 6%. It also makes CNN The average accuracy is better in all cells , by 88.42%, and SVM by 82.44%. High accuracy makes both classifiers suitable for visual inspection . If the application scenario allows GPU And higher processing time , The more expensive one is preferred CNN. otherwise , For applications that require low resource consumption , Support vector machine classifier is a feasible alternative .
// This article is only for future review , There is no other use .
边栏推荐
猜你喜欢
SQL注入报错注入函数图文详解

Problems encountered in installing mysql8 for Ubuntu and the detailed installation process

Ten thousand word summary data storage, three knowledge points

Using enumeration to realize English to braille
Usage of MySQL subquery keywords (exists)
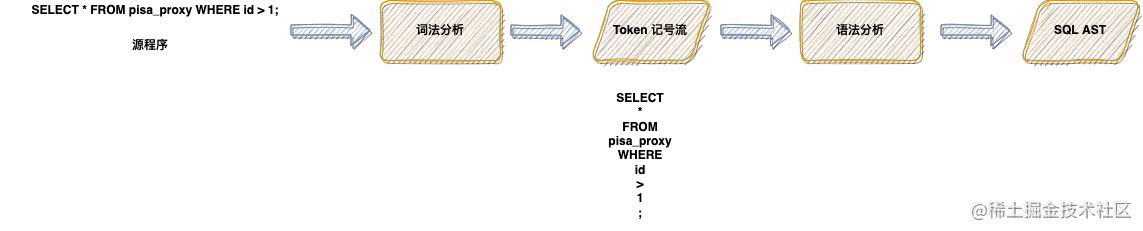
Lex & yacc of Pisa proxy SQL parsing
C语言多角度帮助你深入理解指针(1. 字符指针2. 数组指针和 指针数组 、数组传参和指针传参3. 函数指针4. 函数指针数组5. 指向函数指针数组的指针6. 回调函数)

How does codesonar help UAVs find software defects?

Goal: do not exclude yaml syntax. Try to get started quickly
恶魔奶爸 B3 少量泛读,完成两万词汇量+

随机推荐
恶魔奶爸 A0 英文零基础的自我提升路
How to meet the dual needs of security and confidentiality of medical devices?
Static analysis of software defects codesonar 5.2 release
死锁的产生条件和预防处理[通俗易懂]
Lex & yacc of Pisa proxy SQL parsing
私募基金在中国合法吗?安全吗?
Codesonar Webinar
Codeforces Round #275 (Div. 2) C – Diverse Permutation (构造)[通俗易懂]
Goal: do not exclude yaml syntax. Try to get started quickly
现在网上开户安全么?想知道我现在在南宁,到哪里开户比较好?
阿洛的烦恼
Usage of MySQL subquery keywords (exists)
开户还得用身份证银行卡安全吗,我是小白不懂
The difference between NPM uninstall and RM direct deletion
I wrote a markdown command line gadget, hoping to improve the efficiency of sending documents by garden friends!
How can big state-owned banks break the anti fraud dilemma?
[function recursion] do you know all five classic examples of simple recursion?
Alibaba cloud award winning experience: how to mount NAS file system through ECS
POJ 3140 Contestants Division「建议收藏」
201215-03-19—cocos2dx内存管理–具体解释「建议收藏」