当前位置:网站首页>变量、流程控制与游标(MySQL)
变量、流程控制与游标(MySQL)
2022-07-06 19:55:00 【JiaXingNashishua】
目录
一:变量
在MySQL数据库的存储过程和函数中,可以使用变量来存储查询或计算的中间结果数据,或者输出最终的结果数据。
在 MySQL 数据库中,变量分为 系统变量 以及 用户自定义变量 。
1.1 系统变量
1.1.1 系统变量分类
变量由系统定义,不是用户定义,属于 服务器 层面。启动MySQL服务,生成MySQL服务实例期间,MySQL将为MySQL服务器内存中的系统变量赋值,这些系统变量定义了当前MySQL服务实例的属性、特征。这些系统变量的值要么是 编译MySQL时参数 的默认值,要么是 配置文件 (例如my.ini等)中的参数值。
系统变量分为全局系统变量(需要添加 global 关键字)以及会话系统变量(需要添加 session 关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。如果不写,默认会话级别。静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
每一个MySQL客户机成功连接MySQL服务器后,都会产生与之对应的会话。会话期间,MySQL服务实例会在MySQL服务器内存中生成与该会话对应的会话系统变量,这些会话系统变量的初始值是全局系统变量值的复制。如下图:
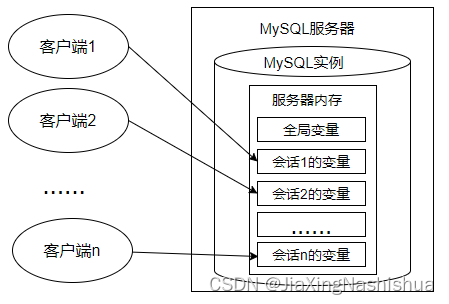
- 全局系统变量针对于所有会话(连接)有效,但 不能跨重启
- 会话系统变量仅针对于当前会话(连接)有效。会话期间,当前会话对某个会话系统变量值的修改,不会影响其他会话同一个会话系统变量的值。
- 会话1对某个全局系统变量值的修改会导致会话2中同一个全局系统变量值的修改。
在MySQL中有些系统变量只能是全局的,例如 max_connections 用于限制服务器的最大连接数;有些系统变量作用域既可以是全局又可以是会话,例如 character_set_client 用于设置客户端的字符集;有些系统变量的作用域只能是当前会话,例如 pseudo_thread_id 用于标记当前会话的 MySQL 连接 ID。
1.1.2 查看系统变量
查看所有或部分系统变量
#查看所有全局变量
SHOW GLOBAL VARIABLES;
#查看所有会话变量
SHOW SESSION VARIABLES;
或
SHOW VARIABLES;
#查看满足条件的部分系统变量。
SHOW GLOBAL VARIABLES LIKE '%标识符%';
#查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%标识符%';
举例:
SHOW GLOBAL VARIABLES LIKE 'admin_%';
查看指定系统变量
作为 MySQL 编码规范,MySQL 中的系统变量以 两个“@” 开头,其中“@@global”仅用于标记全局系统变量,“@@session”仅用于标记会话系统变量。“@@”首先标记会话系统变量,如果会话系统变量不存在,则标记全局系统变量。
#查看指定的系统变量的值
SELECT @@global.变量名;
#查看指定的会话变量的值
SELECT @@session.变量名;
#或者
SELECT @@变量名;修改系统变量的值
有些时候,数据库管理员需要修改系统变量的默认值,以便修改当前会话或者MySQL服务实例的属性、特征。具体方法:
方式1:修改MySQL 配置文件 ,继而修改MySQL系统变量的值(该方法需要重启MySQL服务)
方式2:在MySQL服务运行期间,使用“set”命令重新设置系统变量的值
#为某个系统变量赋值
#方式1:
SET @@global.变量名=变量值;
#方式2:
SET GLOBAL 变量名=变量值;
#针对于当前的数据库实例是有效的,一旦重启mysql服务,就失效了。
#为某个会话变量赋值
#方式1:
SET @@session.变量名=变量值;
#方式2:
SET SESSION 变量名=变量值;
举例:
SELECT @@global.autocommit;
SET GLOBAL autocommit=0;
SELECT @@session.tx_isolation;
SET @@session.tx_isolation='read-uncommitted';
SET GLOBAL max_connections = 1000;
SELECT @@global.max_connections;
1.2 用户变量
1.2.1 用户变量分类
用户变量是用户自己定义的,作为 MySQL 编码规范,MySQL 中的用户变量以 一个“@” 开头。根据作用范围不同,又分为 会话用户变量 和 局部变量 。
- 会话用户变量:作用域和会话变量一样,只对 当前连接 会话有效。
- 局部变量:只在 BEGIN 和 END 语句块中有效。局部变量只能在 存储过程和函数 中使用。
1.2.2 会话用户变量
变量的定义
#方式1:“=”或“:=”
SET @用户变量 = 值;
SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];
查看用户变量的值 (查看、比较、运算等)
SELECT @用户变量举例
SET @a = 1;
SELECT @a;
SELECT @num := COUNT(*) FROM employees;
SELECT @num;
SELECT AVG(salary) INTO @avgsalary FROM employees;
SELECT @avgsalary;
SELECT @big; #查看某个未声明的变量时,将得到NULL值
1.2.3 局部变量
定义:可以使用 DECLARE 语句定义一个局部变量
作用域:仅仅在定义它的 BEGIN ... END 中有效
位置:只能放在 BEGIN ... END 中,而且只能放在第一句
BEGIN
#声明局部变量
DECLARE 变量名1 变量数据类型 [DEFAULT 变量默认值];
DECLARE 变量名2,变量名3,... 变量数据类型 [DEFAULT 变量默认值];
#为局部变量赋值
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句];
#查看局部变量的值
SELECT 变量1,变量2,变量3;
END
1.定义变量
DECLARE 变量名 类型 [default 值]; # 如果没有DEFAULT子句,初始值为NULL
2.变量赋值
方式1:一般用于赋简单的值
SET 变量名=值;
SET 变量名:=值;
方式2:一般用于赋表中的字段值
SELECT 字段名或表达式 INTO 变量名 FROM 表;
3.使用变量(查看、比较、运算等)
SELECT 局部变量名;举例1:声明局部变量,并分别赋值为employees表中employee_id为102的last_name和salary
DELIMITER //
CREATE PROCEDURE set_value()
BEGIN
DECLARE emp_name VARCHAR(25);
DECLARE sal DOUBLE(10,2);
SELECT last_name,salary INTO emp_name,sal
FROM employees
WHERE employee_id = 102;
SELECT emp_name,sal;
END //
DELIMITER ;
举例2:声明两个变量,求和并打印 (分别使用会话用户变量、局部变量的方式实现)
#方式1:使用用户变量
SET @m=1;
SET @n=1;
SET @[email protected][email protected];
SELECT @sum;
#方式2:使用局部变量
DELIMITER //
CREATE PROCEDURE add_value()
BEGIN
#局部变量
DECLARE m INT DEFAULT 1;
DECLARE n INT DEFAULT 3;
DECLARE SUM INT;
SET SUM = m+n;
SELECT SUM;
END //
DELIMITER ;
举例3:创建存储过程“different_salary”查询某员工和他领导的薪资差距,并用IN参数emp_id接收员工id,用OUT参数dif_salary输出薪资差距结果。
#声明
DELIMITER //
CREATE PROCEDURE different_salary(IN emp_id INT,OUT dif_salary DOUBLE)
BEGIN
#声明局部变量
DECLARE emp_sal,mgr_sal DOUBLE DEFAULT 0.0;
DECLARE mgr_id INT;
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id;
SELECT manager_id INTO mgr_id FROM employees WHERE employee_id = emp_id;
SELECT salary INTO mgr_sal FROM employees WHERE employee_id = mgr_id;
SET dif_salary = mgr_sal - emp_sal;
END //
DELIMITER ;
#调用
SET @emp_id = 102;
CALL different_salary(@emp_id,@diff_sal);
#查看
SELECT @diff_sal;
1.2.4 对比会话用户变量与局部变量

二: 定义条件与处理程序
定义条件 是事先定义程序执行过程中可能遇到的问题, 处理程序定义了在遇到问题时应当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。这样可以增强存储程序处理问题的能力,避免程序异常停止运行。
说明:定义条件和处理程序在存储过程、存储函数中都是支持的。
2.1 案例分析
案例分析:创建一个名称为“UpdateDataNoCondition”的存储过程。代码如下:
DELIMITER //
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END //
DELIMITER ;调用存储过程:
mysql> CALL UpdateDataNoCondition();
ERROR 1048 (23000): Column 'email' cannot be null
mysql> SELECT @x;
+------+
| @x |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
可以看到,此时@x变量的值为1。结合创建存储过程的SQL语句代码可以得出:在存储过程中未定义条件和处理程序,且当存储过程中执行的SQL语句报错时,MySQL数据库会抛出错误,并退出当前SQL逻辑,不再向下继续执行。
2.2 定义条件
定义条件就是给MySQL中的错误码命名,这有助于存储的程序代码更清晰。它将一个 错误名字 和 指定的错误条件 关联起来。这个名字可以随后被用在定义处理程序的 DECLARE HANDLER 语句中。
定义条件使用DECLARE语句,语法格式如下:
DECLARE 错误名称 CONDITION FOR 错误码(或错误条件)
错误码的说明:
- MySQL_error_code 和 sqlstate_value 都可以表示MySQL的错误。
- MySQL_error_code是数值类型错误代码。
- sqlstate_value是长度为5的字符串类型错误代码。
- 例如,在ERROR 1418 (HY000)中,1418是MySQL_error_code,'HY000'是sqlstate_value。
- 例如,在ERROR 1142(42000)中,1142是MySQL_error_code,'42000'是sqlstate_value。
举例1:定义“Field_Not_Be_NULL”错误名与MySQL中违反非空约束的错误类型是“ERROR 1048 (23000)”对应。
#使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1048;
#使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE '23000';
举例2:定义"ERROR 1148(42000)"错误,名称为command_not_allowed。
#使用MySQL_error_code
DECLARE command_not_allowed CONDITION FOR 1148;
#使用sqlstate_value
DECLARE command_not_allowed CONDITION FOR SQLSTATE '42000';2.3 定义处理程序
可以为SQL执行过程中发生的某种类型的错误定义特殊的处理程序。定义处理程序时,使用DECLARE语句的语法如下:
DECLARE 处理方式 HANDLER FOR 错误类型 处理语句
处理方式:处理方式有3个取值:CONTINUE、EXIT、UNDO。
- CONTINUE :表示遇到错误不处理,继续执行。
- EXIT :表示遇到错误马上退出。
- UNDO :表示遇到错误后撤回之前的操作。MySQL中暂时不支持这样的操作。
错误类型(即条件)可以有如下取值:
- SQLSTATE '字符串错误码' :表示长度为5的sqlstate_value类型的错误代码;
- MySQL_error_code :匹配数值类型错误代码;
- 错误名称 :表示DECLARE ... CONDITION定义的错误条件名称。
- SQLWARNING :匹配所有以01开头的SQLSTATE错误代码;
- NOT FOUND :匹配所有以02开头的SQLSTATE错误代码;
- SQLEXCEPTION :匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码;
处理语句:如果出现上述条件之一,则采用对应的处理方式,并执行指定的处理语句。语句可以是
像“ SET 变量 = 值 ”这样的简单语句,也可以是使用 BEGIN ... END 编写的复合语句。
定义处理程序的几种方式,代码如下:
#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';2.4 案例解决
在存储过程中,定义处理程序,捕获sqlstate_value值,当遇到MySQL_error_code值为1048时,执行CONTINUE操作,并且将@proc_value的值设置为-1。
DELIMITER //
CREATE PROCEDURE UpdateDataNoCondition()
BEGIN
#定义处理程序
DECLARE CONTINUE HANDLER FOR 1048 SET @proc_value = -1;
SET @x = 1;
UPDATE employees SET email = NULL WHERE last_name = 'Abel';
SET @x = 2;
UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel';
SET @x = 3;
END //
DELIMITER ;
#调用
mysql> CALL UpdateDataWithCondition();
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT @x,@proc_value;
+------+-------------+
| @x | @proc_value |
+------+-------------+
| 3 | -1 |
+------+-------------+
1 row in set (0.00 sec)
三:流程控制
解决复杂问题不可能通过一个 SQL 语句完成,我们需要执行多个 SQL 操作。流程控制语句的作用就是控制存储过程中 SQL 语句的执行顺序,是我们完成复杂操作必不可少的一部分。只要是执行的程序,流程就分为三大类:
- 顺序结构 :程序从上往下依次执行
- 分支结构 :程序按条件进行选择执行,从两条或多条路径中选择一条执行
- 循环结构 :程序满足一定条件下,重复执行一组语句
针对于MySQL 的流程控制语句主要有 3 类。注意:只能用于存储程序。
- 条件判断语句 :IF 语句和 CASE 语句
- 循环语句 :LOOP、WHILE 和 REPEAT 语句
- 跳转语句 :ITERATE 和 LEAVE 语句
3.1 分支结构之 IF
IF 语句的语法结构是:
IF 表达式1 THEN 操作1
[ELSEIF 表达式2 THEN 操作2]……
[ELSE 操作N]
END IF
根据表达式的结果为TRUE或FALSE执行相应的语句。这里“[]”中的内容是可选的。
特点:① 不同的表达式对应不同的操作 ② 使用在begin end中
举例1:
IF val IS NULL
THEN SELECT 'val is null';
ELSE SELECT 'val is not null';
END IF;
举例2:
声明存储过程“update_salary_by_eid1”,定义IN参数emp_id,输入员工编号。判断该员工
薪资如果低于8000元并且入职时间超过5年,就涨薪500元;否则就不变。
DELIMITER //
CREATE PROCEDURE update_salary_by_eid1(IN emp_id INT)
BEGIN
DECLARE emp_salary DOUBLE;
DECLARE hire_year DOUBLE;
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
SELECT DATEDIFF(CURDATE(),hire_date)/365 INTO hire_year
FROM employees WHERE employee_id = emp_id;
IF emp_salary < 8000 AND hire_year > 5
THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id;
END IF;
END //
DELIMITER ;
3.2 分支结构之 CASE
CASE 语句的语法结构1:
#情况一:类似于switch
CASE 表达式
WHEN 值1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 值2 THEN 结果2或语句2(如果是语句,需要加分号)
...
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
CASE 语句的语法结构2:
#情况二:类似于多重if
CASE
WHEN 条件1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 条件2 THEN 结果2或语句2(如果是语句,需要加分号)
...
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
举例1:
使用CASE流程控制语句的第1种格式,判断val值等于1、等于2,或者两者都不等。
CASE val
WHEN 1 THEN SELECT 'val is 1';
WHEN 2 THEN SELECT 'val is 2';
ELSE SELECT 'val is not 1 or 2';
END CASE;
举例2:
使用CASE流程控制语句的第2种格式,判断val是否为空、小于0、大于0或者等于0。
CASE
WHEN val IS NULL THEN SELECT 'val is null';
WHEN val < 0 THEN SELECT 'val is less than 0';
WHEN val > 0 THEN SELECT 'val is greater than 0';
ELSE SELECT 'val is 0';
END CASE;
3.3 循环结构之LOOP
LOOP循环语句用来重复执行某些语句。LOOP内的语句一直重复执行直到循环被退出(使用LEAVE子句),跳出循环过程。
LOOP语句的基本格式如下:
loop_label:] LOOP
循环执行的语句
END LOOP [loop_label]其中,loop_label表示LOOP语句的标注名称,该参数可以省略。
举例1:
使用LOOP语句进行循环操作,id值小于10时将重复执行循环过程。
DECLARE id INT DEFAULT 0;
add_loop:LOOP
SET id = id +1;
IF id >= 10 THEN LEAVE add_loop;
END IF;
END LOOP add_loop;
3.4 循环结构之WHILE
WHILE语句创建一个带条件判断的循环过程。WHILE在执行语句执行时,先对指定的表达式进行判断,如果为真,就执行循环内的语句,否则退出循环。WHILE语句的基本格式如下:
while_label:] WHILE 循环条件 DO
循环体
END WHILE [while_label];while_label为WHILE语句的标注名称;如果循环条件结果为真,WHILE语句内的语句或语句群被执行,直至循环条件为假,退出循环。
举例:
WHILE语句示例,i值小于10时,将重复执行循环过程,代码如下:
DELIMITER //
CREATE PROCEDURE test_while()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 10 DO
SET i = i + 1;
END WHILE;
SELECT i;
END //
DELIMITER ;
#调用
CALL test_while();
3.5 循环结构之REPEAT
REPEAT语句创建一个带条件判断的循环过程。与WHILE循环不同的是,REPEAT 循环首先会执行一次循环,然后在 UNTIL 中进行表达式的判断,如果满足条件就退出,即 END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条件为止。
REPEAT语句的基本格式如下:
[repeat_label:] REPEAT
循环体的语句
UNTIL 结束循环的条件表达式
END REPEAT [repeat_label]
repeat_label为REPEAT语句的标注名称,该参数可以省略;REPEAT语句内的语句或语句群被重复,直至expr_condition为真。
举例:
DELIMITER //
CREATE PROCEDURE test_repeat()
BEGIN
DECLARE i INT DEFAULT 0;
REPEAT
SET i = i + 1;
UNTIL i >= 10
END REPEAT;
SELECT i;
END //
DELIMITER ;
3.6对比三种循环结构:
1、这三种循环都可以省略名称,但如果循环中添加了循环控制语句(LEAVE或ITERATE)则必须添加名称。
2、 LOOP:一般用于实现简单的"死"循环
WHILE:先判断后执行
REPEAT:先执行后判断,无条件至少执行一次
3.7 跳转语句之LEAVE语句
LEAVE语句:可以用在循环语句内,或者以 BEGIN 和 END 包裹起来的程序体内,表示跳出循环或者跳出程序体的操作。如果你有面向过程的编程语言的使用经验,你可以把 LEAVE 理解为 break。
基本格式如下:
LEAVE 标记名
其中,label参数表示循环的标志。LEAVE和BEGIN ... END或循环一起被使用。
举例:创建存储过程 “leave_begin()”,声明INT类型的IN参数num。给BEGIN...END加标记名,并在
BEGIN...END中使用IF语句判断num参数的值。
如果num<=0,则使用LEAVE语句退出BEGIN...END;
如果num=1,则查询“employees”表的平均薪资;
如果num=2,则查询“employees”表的最低薪资;
如果num>2,则查询“employees”表的最高薪资。
IF语句结束后查询“employees”表的总人数。
DELIMITER //
CREATE PROCEDURE leave_begin(IN num INT)
begin_label: BEGIN
IF num<=0
THEN LEAVE begin_label;
ELSEIF num=1
THEN SELECT AVG(salary) FROM employees;
ELSEIF num=2
THEN SELECT MIN(salary) FROM employees;
ELSE
SELECT MAX(salary) FROM employees;
END IF;
SELECT COUNT(*) FROM employees;
END //
DELIMITER ;
3.8 跳转语句之ITERATE语句
ITERATE语句:只能用在循环语句(LOOP、REPEAT和WHILE语句)内,表示重新开始循环,将执行顺序转到语句段开头处。如果你有面向过程的编程语言的使用经验,你可以把 ITERATE 理解为 continue,意思为“再次循环”。
语句基本格式如下:
ITERATE label
label参数表示循环的标志。ITERATE语句必须跟在循环标志前面。
举例: 定义局部变量num,初始值为0。循环结构中执行num + 1操作。
如果num < 10,则继续执行循环;
如果num > 15,则退出循环结构;
DELIMITER //
CREATE PROCEDURE test_iterate()
BEGIN
DECLARE num INT DEFAULT 0;
my_loop:LOOP
SET num = num + 1;
IF num < 10
THEN ITERATE my_loop;
ELSEIF num > 15
THEN LEAVE my_loop;
END IF;
SELECT '尚硅谷:让天下没有难学的技术';
END LOOP my_loop;
END //
DELIMITER ;
四:游标
4.1 什么是游标(或光标)
虽然我们也可以通过筛选条件 WHERE 和 HAVING,或者是限定返回记录的关键字 LIMIT 返回一条记录,但是,却无法在结果集中像指针一样,向前定位一条记录、向后定位一条记录,或者是 随意定位到某一条记录 ,并对记录的数据进行处理。
这个时候,就可以用到游标。游标,提供了一种灵活的操作方式,让我们能够对结果集中的每一条记录进行定位,并对指向的记录中的数据进行操作的数据结构。游标让 SQL 这种面向集合的语言有了面向过程开发的能力。
在 SQL 中,游标是一种临时的数据库对象,可以指向存储在数据库表中的数据行指针。这里游标 充当了指针的作用 ,我们可以通过操作游标来对数据行进行操作。
MySQL中游标可以在存储过程和函数中使用。
比如,我们查询了 employees 数据表中工资高于15000的员工都有哪些:
SELECT employee_id,last_name,salary FROM employees
WHERE salary > 15000;
这里我们就可以通过游标来操作数据行,如图所示此时游标所在的行是“108”的记录,我们也可以在结果集上滚动游标,指向结果集中的任意一行。
4.2 使用游标步骤
游标必须在声明处理程序之前被声明,并且变量和条件还必须在声明游标或处理程序之前被声明。
如果我们想要使用游标,一般需要经历四个步骤。不同的 DBMS 中,使用游标的语法可能略有不同。
第一步,声明游标
在MySQL中,使用DECLARE关键字来声明游标,其语法的基本形式如下:
DECLARE cursor_name CURSOR FOR select_statement;
这个语法适用于 MySQL,SQL Server,DB2 和 MariaDB。如果是用 Oracle 或者 PostgreSQL,需要写成:
DECLARE cursor_name CURSOR IS select_statement;
要使用 SELECT 语句来获取数据结果集,而此时还没有开始遍历数据,这里 select_statement 代表的是SELECT 语句,返回一个用于创建游标的结果集。
比如:
DECLARE cur_emp CURSOR FOR
SELECT employee_id,salary FROM employees;
第二步,打开游标
打开游标的语法如下:
OPEN cursor_name
当我们定义好游标之后,如果想要使用游标,必须先打开游标。打开游标的时候 SELECT 语句的查询结果集就会送到游标工作区,为后面游标的 逐条读取 结果集中的记录做准备。
OPEN cur_emp ;
第三步,使用游标(从游标中取得数据)
语法如下:
FETCH cursor_name INTO var_name [, var_name] ...
这句的作用是使用 cursor_name 这个游标来读取当前行,并且将数据保存到 var_name 这个变量中,游标指针指到下一行。如果游标读取的数据行有多个列名,则在 INTO 关键字后面赋值给多个变量名即可。
注意:var_name必须在声明游标之前就定义好。
FETCH cur_emp INTO emp_id, emp_sal ;
注意:游标的查询结果集中的字段数,必须跟 INTO 后面的变量数一致,否则,在存储过程执行的时候,MySQL 会提示错误。
第四步,关闭游标
CLOSE cursor_name有 OPEN 就会有 CLOSE,也就是打开和关闭游标。当我们使用完游标后需要关闭掉该游标。因为游标会占用系统资源 ,如果不及时关闭,游标会一直保持到存储过程结束,影响系统运行的效率。而关闭游标的操作,会释放游标占用的系统资源。
关闭游标之后,我们就不能再检索查询结果中的数据行,如果需要检索只能再次打开游标。
CLOSE cur_emp;
边栏推荐
- Detailed explanation of 19 dimensional integrated navigation module sinsgps in psins (filtering part)
- centerX: 用中国特色社会主义的方式打开centernet
- 杰理之在非蓝牙模式下,手机连接蓝牙不要跳回蓝牙模式处理方法【篇】
- Room rate system - login optimization
- Unity使用MaskableGraphic画一条带箭头的线
- leetcode
- How to find file accessed / created just feed minutes ago
- The version control of 2021 version is missing. Handling method
- Centerx: open centernet in the way of socialism with Chinese characteristics
- [tools] basic concept of database and MySQL installation
猜你喜欢
leetcode

Detailed explanation of 19 dimensional integrated navigation module sinsgps in psins (time synchronization part)
掘金量化:通过history方法获取数据,和新浪财经,雪球同用等比复权因子。不同于同花顺
知识图谱构建全流程
Django database (SQLite) basic introductory tutorial
![[cpk-ra6m4 development board environment construction based on RT thread studio]](/img/08/9a847c73d6da6fc74d84af56897752.png)
[cpk-ra6m4 development board environment construction based on RT thread studio]

The first symposium on "quantum computing + application of financial technology" was successfully held in Beijing
The whole process of knowledge map construction
OC, OD, push-pull explanation of hardware

How-PIL-to-Tensor
随机推荐
Hazel engine learning (V)
Codeforces round 264 (Div. 2) C gargari and Bishop [violence]
Redis getting started complete tutorial: replication configuration
C language string sorting
Don't you know the relationship between JSP and servlet?
PSINS中19维组合导航模块sinsgps详解(滤波部分)
Codeforces Round #264 (Div. 2) C Gargari and Bishops 【暴力】
Unity使用MaskableGraphic画一条带箭头的线
你知道电子招标最突出的5大好处有哪些吗?
input_ delay
HDU ACM 4578 Transformation-&gt;段树-间隔的变化
SQL Tuning Advisor一个错误ORA-00600: internal error code, arguments: [kesqsMakeBindValue:obj]
制作(转换)ico图标
Leetcode 77: combination
c语言字符串排序
上个厕所的功夫,就把定时任务的三种调度策略说得明明白白
The first symposium on "quantum computing + application of financial technology" was successfully held in Beijing
Uniapp adaptation problem
How to find file accessed / created just feed minutes ago
2022 information security engineer examination outline