当前位置:网站首页>Flink实时计算topN热榜
Flink实时计算topN热榜
2022-07-02 06:36:00 【lucky乐琪】
topN的常见应用场景,最热商品购买量,最高人气作者的阅读量等等。
1. 用到的知识点
1.Flink创建kafka数据源;
2.基于 EventTime 处理,如何指定 Watermark;
3.Flink中的Window,滚动(tumbling)窗口与滑动(sliding)窗口;
4.State状态的使用;
5.ProcessFunction 实现 TopN 功能;
2. 案例介绍
通过用户访问日志,计算最近一段时间平台最活跃的几位用户topN。
1.创建kafka生产者,发送测试数据到kafka;
2.消费kafka数据,使用滑动(sliding)窗口,每隔一段时间更新一次排名;
3. 数据源
这里使用kafka api发送测试数据到kafka,代码如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class User {
private long id;
private String username;
private String password;
private long timestamp;
}
Map<String, String> config = Configuration.initConfig("commons.xml");
@Test
public void sendData() throws InterruptedException {
int cnt = 0;
while (cnt < 200){
User user = new User();
user.setId(cnt);
user.setUsername("username" + new Random().nextInt((cnt % 5) + 2));
user.setPassword("password" + cnt);
user.setTimestamp(System.currentTimeMillis());
Future<RecordMetadata> future = KafkaUtil.sendDataToKafka(config.get("kafka-topic"), String.valueOf(cnt), JSON.toJSONString(user));
while (!future.isDone()){
Thread.sleep(100);
}
try {
RecordMetadata recordMetadata = future.get();
System.out.println(recordMetadata.offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("发送消息:" + cnt + "******" + user.toString());
cnt = cnt + 1;
}
}
这里通过随机数来扰乱username,便于使用户名大小不一,让结果更加明显。KafkaUtil是自己写的一个kafka工具类,代码很简单,主要是平时做测试方便。
4. 主要程序
创建一个main程序,开始编写代码。
创建flink环境,关联kafka数据源。
Map<String, String> config = Configuration.initConfig("commons.xml");
Properties kafkaProps = new Properties();
kafkaProps.setProperty("zookeeper.connect", config.get("kafka-zookeeper"));
kafkaProps.setProperty("bootstrap.servers", config.get("kafka-ipport"));
kafkaProps.setProperty("group.id", config.get("kafka-groupid"));
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
EventTime 与 Watermark
senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
设置属性senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime),表示按照数据时间字段来处理,默认是TimeCharacteristic.ProcessingTime
/** The time characteristic that is used if none other is set. */
private static final TimeCharacteristic DEFAULT_TIME_CHARACTERISTIC = TimeCharacteristic.ProcessingTime;
这个属性必须设置,否则后面,可能窗口结束无法触发,导致结果无法输出。取值有三种:
ProcessingTime:事件被处理的时间。也就是由flink集群机器的系统时间来决定。
EventTime:事件发生的时间。一般就是数据本身携带的时间。
IngestionTime:摄入时间,数据进入flink流的时间,跟ProcessingTime还是有区别的;
指定好使用数据的实际时间来处理,接下来需要指定flink程序如何get到数据的时间字段,这里使用调用DataStream的assignTimestampsAndWatermarks方法,抽取时间和设置watermark。
senv.addSource(
new FlinkKafkaConsumer010<>(
config.get("kafka-topic"),
new SimpleStringSchema(),
kafkaProps
)
).map(x ->{
return JSON.parseObject(x, User.class);
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<User>(Time.milliseconds(1000)) {
@Override
public long extractTimestamp(User element) {
return element.getTimestamp();
}
})
前面给出的代码中可以看出,由于发送到kafka的时候,将User对象转换为json字符串了,这里使用的是fastjson,接收过来可以转化为JsonObject来处理,我这里还是将其转化为User对象JSON.parseObject(x, User.class),便于处理。
这里考虑到数据可能乱序,使用了可以处理乱序的抽象类BoundedOutOfOrdernessTimestampExtractor,并且实现了唯一的一个没有实现的方法extractTimestamp,乱序数据,会导致数据延迟,在构造方法中传入了一个Time.milliseconds(1000),表明数据可以延迟一秒钟。比如说,如果窗口长度是10s,010s的数据会在11s的时候计算,此时watermark是10,才会触发计算,也就是说引入watermark处理乱序数据,最多可以容忍0t这个窗口的数据,最晚在t+1时刻到来。
窗口统计
业务需求上,通常可能是一个小时,或者过去15分钟的数据,5分钟更新一次排名,这里为了演示效果,窗口长度取10s,每次滑动(slide)5s,即5秒钟更新一次过去10s的排名数据。
.keyBy("username")
.timeWindow(Time.seconds(10), Time.seconds(5))
.aggregate(new CountAgg(), new WindowResultFunction())
我们使用.keyBy(“username”)对用户进行分组,使用*.timeWindow(Time size, Time slide)对每个用户做滑动窗口(10s窗口,5s滑动一次)。然后我们使用 .aggregate(AggregateFunction af, WindowFunction wf) 做增量的聚合操作,它能使用AggregateFunction提前聚合掉数据,减少 state 的存储压力。较之.apply(WindowFunction wf)*会将窗口中的数据都存储下来,最后一起计算要高效地多。aggregate()方法的第一个参数用于
这里的CountAgg实现了AggregateFunction接口,功能是统计窗口中的条数,即遇到一条数据就加一。
public class CountAgg implements AggregateFunction<User, Long, Long>{
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(User value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return a + b;
}
}
.aggregate(AggregateFunction af, WindowFunction wf) 的第二个参数WindowFunction将每个 key每个窗口聚合后的结果带上其他信息进行输出。我们这里实现的WindowResultFunction将用户名,窗口,访问量封装成了UserViewCount进行输出。
private static class WindowResultFunction implements WindowFunction<Long, UserViewCount, Tuple, TimeWindow> {
@Override
public void apply(Tuple key, TimeWindow window, Iterable<Long> input, Collector<UserViewCount> out) throws Exception {
Long count = input.iterator().next();
out.collect(new UserViewCount(((Tuple1<String>)key).f0, window.getEnd(), count));
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public static class UserViewCount {
private String userName;
private long windowEnd;
private long viewCount;
}
TopN计算最活跃用户
为了统计每个窗口下活跃的用户,我们需要再次按窗口进行分组,这里根据UserViewCount中的windowEnd进行keyBy()操作。然后使用 ProcessFunction 实现一个自定义的 TopN 函数 TopNHotItems 来计算点击量排名前3名的用户,并将排名结果格式化成字符串,便于后续输出。
.keyBy("windowEnd")
.process(new TopNHotUsers(3))
.print();
ProcessFunction 是 Flink 提供的一个 low-level API,用于实现更高级的功能。它主要提供了定时器 timer 的功能(支持EventTime或ProcessingTime)。本案例中我们将利用 timer 来判断何时收齐了某个 window 下所有用户的访问数据。由于 Watermark 的进度是全局的,在 processElement 方法中,每当收到一条数据(ItemViewCount),我们就注册一个 windowEnd+1 的定时器(Flink 框架会自动忽略同一时间的重复注册)。windowEnd+1 的定时器被触发时,意味着收到了windowEnd+1的 Watermark,即收齐了该windowEnd下的所有用户窗口统计值。我们在 onTimer() 中处理将收集的所有商品及点击量进行排序,选出 TopN,并将排名信息格式化成字符串后进行输出。
这里我们还使用了 ListState 的ItemViewCount 来存储收到的每条 UserViewCount 消息,保证在发生故障时,状态数据的不丢失和一致性。ListState 是 Flink 提供的类似 Java List 接口的 State API,它集成了框架的 checkpoint 机制,自动做到了 exactly-once 的语义保证。
private static class TopNHotUsers extends KeyedProcessFunction<Tuple, UserViewCount, String> {
private int topSize;
private ListState<UserViewCount> userViewCountListState;
public TopNHotUsers(int topSize) {
this.topSize = topSize;
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
List<UserViewCount> userViewCounts = new ArrayList<>();
for(UserViewCount userViewCount : userViewCountListState.get()) {
userViewCounts.add(userViewCount);
}
userViewCountListState.clear();
userViewCounts.sort(new Comparator<UserViewCount>() {
@Override
public int compare(UserViewCount o1, UserViewCount o2) {
return (int)(o2.viewCount - o1.viewCount);
}
});
// 将排名信息格式化成 String, 便于打印
StringBuilder result = new StringBuilder();
result.append("====================================\n");
result.append("时间: ").append(new Timestamp(timestamp-1)).append("\n");
for (int i = 0; i < topSize; i++) {
UserViewCount currentItem = userViewCounts.get(i);
// No1: 商品ID=12224 浏览量=2413
result.append("No").append(i).append(":")
.append(" 用户名=").append(currentItem.userName)
.append(" 浏览量=").append(currentItem.viewCount)
.append("\n");
}
result.append("====================================\n\n");
Thread.sleep(1000);
out.collect(result.toString());
}
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
super.open(parameters);
ListStateDescriptor<UserViewCount> userViewCountListStateDescriptor = new ListStateDescriptor<>(
"user-state",
UserViewCount.class
);
userViewCountListState = getRuntimeContext().getListState(userViewCountListStateDescriptor);
}
@Override
public void processElement(UserViewCount value, Context ctx, Collector<String> out) throws Exception {
userViewCountListState.add(value);
ctx.timerService().registerEventTimeTimer(value.windowEnd + 1000);
}
}
结果输出
可以看到,每隔5秒钟更新输出一次数据。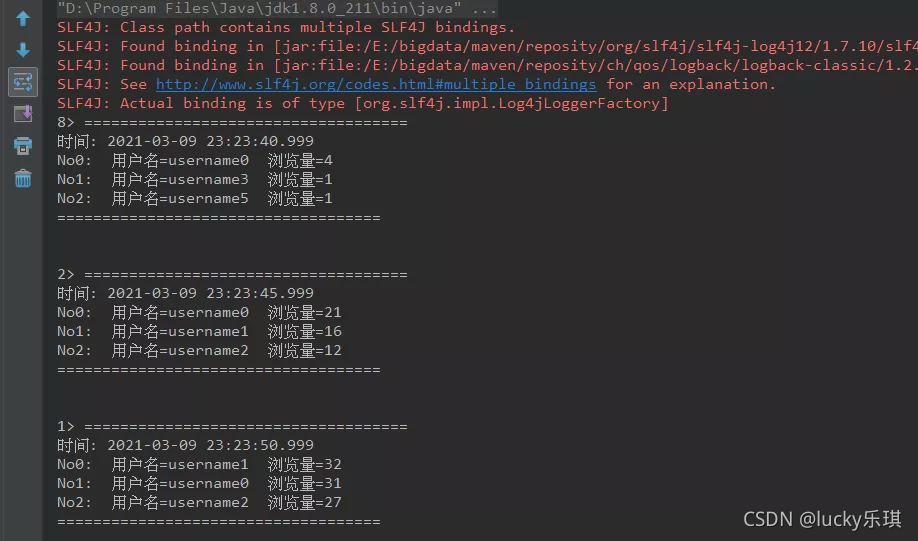
边栏推荐
猜你喜欢

【UE5】动画重定向:如何将幻塔人物导入进游戏玩耍
Blender多镜头(多机位)切换
![[Yu Yue education] University Physics (Electromagnetics) reference materials of Taizhou College of science and technology, Nanjing University of Technology](/img/a9/ffd5d8000fc811f958622901bf408d.png)
[Yu Yue education] University Physics (Electromagnetics) reference materials of Taizhou College of science and technology, Nanjing University of Technology
【JetBrain Rider】构建项目出现异常:未找到导入的项目“D:\VisualStudio2017\IDE\MSBuild\15.0\Bin\Roslyn\Microsoft.CSh
【虚幻】按键开门蓝图笔记

Blender海洋制作
UE4 night lighting notes

Skywalking theory and Practice

Postman--使用
Ue5 - ai Pursuit (Blueprint, Behavior tree)
随机推荐
[ue5] blueprint making simple mine tutorial
How to achieve the top progress bar effect in background management projects
Blender体积雾
MySQL -- time zone / connector / driver type
2021-09-12
Centos7 one click compilation and installation of PHP script
Blender石头雕刻
Brief analysis of edgedb architecture
2021-10-04
Basic usage of mock server
Ctrip starts mixed office. How can small and medium-sized enterprises achieve mixed office?
Sum the two numbers to find the target value
Beautiful and intelligent, Haval H6 supreme+ makes Yuanxiao travel safer
Remember a simple Oracle offline data migration to tidb process
Network communication learning
pytest框架实现前后置
It is the most difficult to teach AI to play iron fist frame by frame. Now arcade game lovers have something
Blender海洋制作
Blender multi lens (multi stand) switching
Determine whether there are duplicate elements in the array