当前位置:网站首页>Redis 排查大 key 的4种方法,优化必备
Redis 排查大 key 的4种方法,优化必备
2022-07-05 04:49:00 【Java知音_】
点击关注公众号,实用技术文章及时了解
摘要:在日常Redis的使用中,难免遇到因为 key 存储了过大的数据而造成请求缓慢甚至阻塞的情况,这个时候就需要排查 Redis 的大key去优化业务了,下面提供一些排查方案总结,仅供参考。
一、多大的 key 算大呢?
Redis 实践总结(仅供参考):
合理的 Key 中 Value 的字节大小,推荐小于 10 KB。
过大的 Value 会引发数据倾斜、热点Key、实例流量或 CPU 性能被占满等问题,应从设计源头上避免此类问题带来的性能影响。
那么 value Bytes > 10 kb 可以作为判断 大 key 的一个参考值。
二、排查大 key 的方法
1、使用命令 --bigkeys
--bigkeys 是 redis 自带的命令,对整个 Key 进行扫描,统计 string,list,set,zset,hash 这几个常见数据类型中每种类型里的最大的 key。
string 类型统计的是 value 的字节数;另外 4 种复杂结构的类型统计的是元素个数,不能直观的看出 value 占用字节数,所以 --bigkeys 对分析 string 类型的大 key 是有用的,而复杂结构的类型还需要一些第三方工具。
注:元素个数少,不一定 value 不大;元素个数多,也不一定 value 就大
redis-cli -h 127.0.0.1 -p 6379 -a "password" --bigkeys--bigkeys 是以 scan 延迟计算的方式扫描所有 key,因此执行过程中不会阻塞 redis,但实例存在大量的 keys 时,命令执行的时间会很长,这种情况建议在 slave 上扫描。
–-bigkeys 其实就是找出类型中最大的 key,最大的 key 不一定是大 key,最大的 key 都不超过 10kb 的话,说明不存在大 key。
但某种类型如果存在较多的大key (>10kb),只会统计 top1 的那个 key,如果要统计所有大于 10kb 的 key,需要用第三方工具扫描 rdb 持久化文件。
2、使用 memory 命令查看 key 的大小(仅支持 Redis 4.0 以后的版本)
redis-cli -h 127.0.0.1 -p 6379 -a password
MEMORY USAGE keyname1
(integer) 157481
MEMORY USAGE keyname2
(integer) 3125833、使用 Rdbtools 工具包
Rdbtools 是 python写的 一个第三方开源工具,用来解析 Redis 快照文件。除了解析 rdb 文件,还提供了统计单个 key 大小的工具。
1、安装
git clone https://github.com/sripathikrishnan/redis-rdb-tools
cd redis-rdb-tools sudo && python setup.py install2、使用
从 dump.rdb 快照文件统计, 将所有 > 10kb 的 key 输出到一个 csv 文件
rdb dump.rdb -c memory --bytes 10240 -f live_redis.csv4、使用 go-redis-bigkv
go-redis-bigkv 是本人开发的一个小工具。主要是 基于 memory 命令,扫描 redis 中所有的 key,并将结果按照 内存大小进行排序,并将排序后的 结果输出到 txt 文件中。因为是 以 scan 延迟计算的方式扫描所有 key,因此执行过程中不会阻塞 redis,但实例存在大量的 keys 时,命令执行的时间会很长。
项目地址:
https://github.com/th3ee9ine/go-redis-bigk
推荐
PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
边栏推荐
- 2021 higher education social cup mathematical modeling national tournament ABCD questions - problem solving ideas - Mathematical Modeling
- Cookie learning diary 1
- [Business Research Report] Research Report on male consumption trends in other economic times -- with download link
- Label exchange experiment
- Flink集群配置
- Function template
- Pointer function (basic)
- Is there a sudden failure on the line? How to make emergency diagnosis, troubleshooting and recovery
- AutoCAD - isometric annotation
- [groovy] closure (Introduction to closure class closure | this, owner, delegate member assignment and source code analysis)
猜你喜欢
![[groovy] closure (closure call | closure default parameter it | code example)](/img/61/754cee9a940fd4ecd446b38c2f413d.jpg)
[groovy] closure (closure call | closure default parameter it | code example)
Flutter 小技巧之 ListView 和 PageView 的各种花式嵌套

2022 American College Students' mathematical modeling ABCDEF problem thinking /2022 American match ABCDEF problem analysis

【Leetcode】1352. 最后 K 个数的乘积
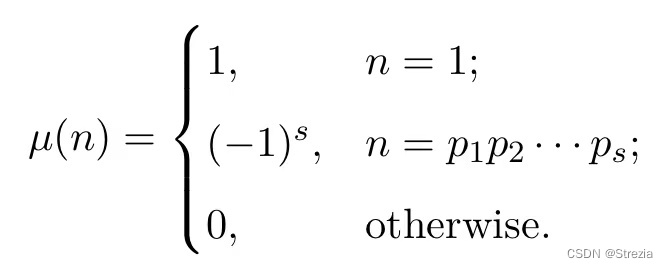
Number theoretic function and its summation to be updated
AutoCAD -- dimension break

10 programming habits that web developers should develop

Special information | real estate and office buildings - 22.1.9

The remainder operation is a hash function
Emlog blog theme template source code simple good-looking responsive
随机推荐
【acwing】836. Merge sets
MD5绕过
Minor spanning tree
AutoCAD - command repetition, undo and redo
中国聚氨酯硬泡市场调研与投资预测报告(2022版)
Neural networks and deep learning Chapter 2: machine learning overview reading questions
【acwing】837. Number of connected block points
自动语音识别(ASR)研究综述
An article takes you to thoroughly understand descriptors
Solutions and answers for the 2021 Shenzhen cup
次小生成树
[groovy] closure (Introduction to closure class closure | this, owner, delegate member assignment and source code analysis)
2022-2028 global and Chinese FPGA prototype system Market Research Report
Managed service network: application architecture evolution in the cloud native Era
[ideas] 2021 may day mathematical modeling competition / May Day mathematical modeling ideas + references + codes
AutoCAD - scaling
Introduction to JVM principle and process
English topic assignment (27)
计组笔记(1)——校验码、原补码乘除计算、浮点数计算
History of web page requests