当前位置:网站首页>Programmers should know the URI, a comprehensive understanding of the article
Programmers should know the URI, a comprehensive understanding of the article
2020-11-08 20:18:00 【Tal technologies】
URI It's a concept that every programmer should understand , At the same time, there is also URL, URN And so on . Understand these concepts , It can help us better explore the World Wide Web (WWW) The design of the , At the same time, it can also help us to effectively solve problems with URI Questions about related concepts , Better understand encode,decode working principle , Better help network programming !
1.URI
URI(Uniform Resource Identifier) , Uniform resource identifier , It provides a simple and extensible way to identify resources .
1.1 URI The past and this life
Why is there URI?
With the development of the World Wide Web , There need to be a variety of different types of resources to be found and transmitted on the network . therefore , You need a unique logo that can be spread on the world wide web , Such a uniform resource identifier is called URI. Of course , Resources are a general concept here , Or abstract concepts , Can be used to refer to entities that can be identified , It's like a web page , a copy e-book, One copy pdf wait , As long as it needs to be presented or transmitted , Can be called a resource .
The founder of the World Wide Web Tim Berners-Lee About hypertext (hypertext) The idea of identifying hyperlinks is indirectly put forward in the proposal of –URL(Uniform Resource Locator). therefore ,URL It was first used to represent addresses that can be accessed on the network . With HTTP, HTML And the gradual development of browsers , There is a growing need to separate the two ways of identifying the accessible address of a resource and single naming to represent the resource , Therefore, it is proposed that URN(Uniform Resource Name), And used to express the latter .

IETF( Network engineering task force ) Mainly responsible for URI Relevant standards are formulated .
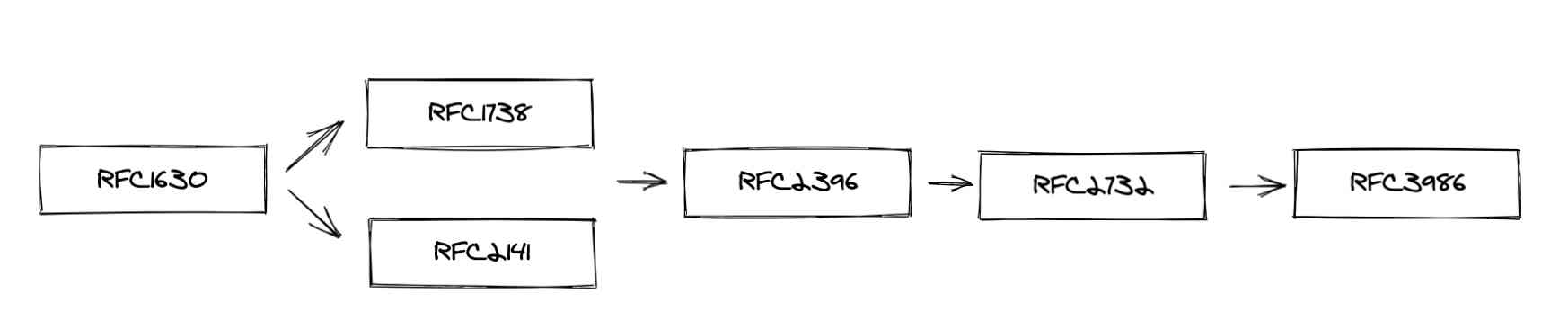
- 1994 Released in RFC1630, Pointed out URL and URN The existence of , At the same time, it defines URI The formal grammar of .
- 94 year 12 month ,RFC1738 Officially put forward absolute and relative URL, RFC2141 It added URN Related grammar and grammatical definitions .
- 1999 Year of RFC2732 allow URI Use IPv6 Address
- stay 2005 Published in RFC3986 standard , Some shortcomings of the above standards are solved , It also marks URI The general syntax is officially known as the official Internet Protocol
- RFC3305 The standard says , although URL Nouns are widely used , But it itself may be gradually abandoned , And only for some URI As a hint to indirectly provide the resource access address . It also points out that the resource identifier does not need to represent the access address of the resource through the network , Or there's no need to imply that the resource is Web-based .( It's quite contradictory here , Actually URL It has been widely used as a folk fact standard , It's not that standards can be overturned immediately if they want to be overturned - -)
1.2 URI and URL,URN Compare
come to know URI and URL,URN The whole history , You can see that the earliest URI and URL It's actually a pulse source . Later, in order to be compatible, we simply identified a resource by name or name ( It is not directly accessible by the network or contains network access address ) The situation of , Put forward URN standard . thus it can be seen , All three names can indicate the location identification of a resource . The interesting question is , In normal work communication , How to distinguish between , And in what kind of scene should we use which name ?

1.2.1 Basic concepts
First, understand the basic concept of each name :
1.URI
Uniform resource identifiers .
Used to represent a specific resource . Designed to carry out any entity or non entity identification , But now it is often used to identify the content that can be transmitted over the network .URI Is a string of characters from a specific character set , And by the IETF The standard defines a set of grammatical rules , It is used to ensure the uniform and unique identification of a resource .
2.URL
Uniform resource locator .
It can also be called a network address . On the World Wide Web , Each resource can have a unique address to the resource , meanwhile , Through this address, you can read and write resources , Such address identification is called URL.URL Contains the current network common format , Include web Site address http, File transfer protocol ftp, emal Address protocol mailto And database access address JDBC etc. .
3.URN
Unified resource name .
URN Used to identify a resource in a specific namespace by name , At the same time, we hope to provide resources with a more durable , A representation independent of location and access .URN It doesn't matter whether the resource location is implied in the representation name , Or how to get it , It doesn't necessarily mean that the resource must be available .
for instance , stay ISBN(Internal Standard Book Number) In the system , A number ( similar 9971-5-0210-0) Represents a book resource , The number is in URN It can be expressed as urn:isbn:9971-5-0210-0, But the number doesn't give information on where or how to find the book , It only uniquely identifies the book .
1.2.1 The relationship between the three
Let's start with the picture above URI,URL and URN The relationship between .
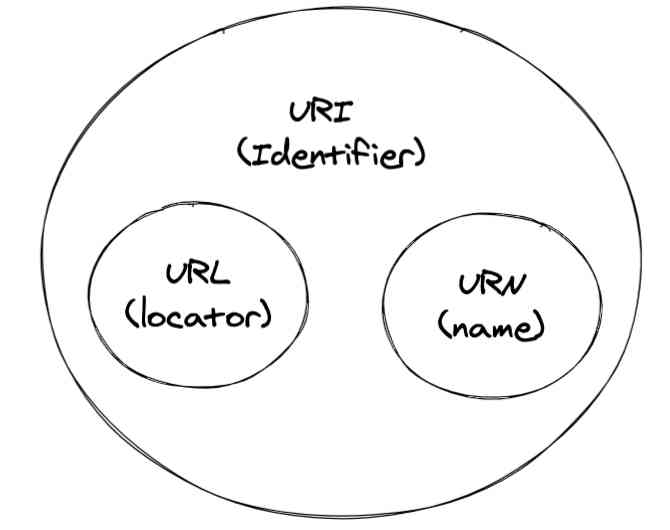
URI It can be thought of as an abstract concept , be-all URL as well as URN All are URI.RFC3986 There's a paragraph in the standard :
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”).
rfc 3986, section 1.1.3
URI Can be classified as locator Or the corresponding name means , That's including URL and URN The concept of . therefore , Usually we are talking about URL When , It can also be called URI.
Again , Here's a very interesting question ,URN In fact, it's better to distinguish , When using a unique identifier resource name, you can use , however URI and URL How to distinguish which scene to use ?
This problem is actually related to RFC3986 The standard definition is not clear enough , Please look at the following paragraph again :
The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI.
rfc 3986, section 1.2.2
URI Access to this resource is not guaranteed , Or implicitly guarantee the existence of the resource ( In fact, the meaning is to URI It's a name that means ), But it was stated in the last paragraph that URI Will be classified as name perhaps locator, Express URI It should contain locator This way of access . Let's look at the next paragraph :
Each URI begins with a scheme name, as defined in Section 3.1, that refers to a specification for assigning identifiers within that scheme.
rfc 3986, section 1.1.1
Every URI All need to contain the beginning scheme name . such as :https://www.example.com, Such a string can be called URI, But it clearly identifies how the resource should be accessed , And it's also URL, because URL Is used to tell the receiver how to obtain the resource .
IETF stay RFC3986 There is also a paragraph about URI and URL Instructions for how to use :
Future specifications and related documentation should use the general term “URI” rather than the more restrictive terms “URL” and “URN”
rfc 3986, section 1.1.3
So it looks like , As if IETF More support the use of URI Instead of URL This is the name . But considering that URL At present, it has become the factual name used to describe the location of resources on the network , and RFC3986 Has been born more than 15 Years. ( Some items do not keep up with the times ), So in the positioning of Internet resources ( Network address ) When ,URL It could be a more appropriate name . Of course , If the other person talks to you about URI wait , That's fine , because URI It's a superclass , And it can also represent the resource .
Here is the conclusion of this question :
- URI It's a marker
- URL It is a kind of marker that can tell you how to access or get the resource
- When describing the network resource address , No problem with either , It's important to be clear that it's best to use the same address as your receiver , Easy to understand
- If it's not easy to handle, it belongs to URL perhaps URN, Then you can use it directly URI describe
2.URI Character set
2.1 URI Design point of
URI Need to provide a simple , Extensible way to uniquely identify resources . meanwhile , We also need to consider the representation of communication in different media . therefore ,URI The following points need to be considered in the design :
- URI Need to be portable .
Different systems , Or between different receivers URI Protocol to identify resources .URI It can be expressed in many forms , Like strings written on paper , Or pixels on the screen , Or a series of encoded binary streams, etc .URI The resolution of is only related to the strings associated with these renderings , And with the concrete way of expression , Carrier independent .
in consideration of URI More needs to be transmitted in the network scene , therefore :
- URI It's a sequence of characters
- URI It may migrate from non network environment to network environment , But the input of network environment is generally restricted by the keyboard , Mouse and other input carriers , Therefore, it is better to present by characters that can be easily input by these physical carriers
- URI It usually needs to be remembered and used by people , So it's better that these characters are something that people often use and are familiar with
Based on the above considerations ,URI A string of restricted characters , And select US-ASCII As a character set .US-ASCII The character set is basically supported by all systems , And it's compatible , Able to support URI The portability needed .
- URI You need to separate the logo from the action
This layer of thinking actually needs to separate expression from expression .URI Focus only on the identity of a resource , If access to this resource is not guaranteed in any way . Resource related actions , Quote, etc , It's given to the implementation at design time URI Next scheme To make an agreement on , for example ,http The agreement will be specifically concerned with the use of ’http’ scheme How to represent the resource ’get’, ‘update’,'delete’ Wait for a series of operations, etc .
This ensures URI The relative stability of the agreement , And better scalability
- Level identification
Because resources are often hierarchical , Like in one example.com There may be multiple resources hanging under the site , Or there will be a directory below ’dir’, This directory will contain multiple resources , That means URI There needs to be a hierarchical organization .
This type of resource organization is also considered in the design , allow URI Organize... By hierarchy , And split the components on the string from left to right .
Similar to the file system of common operating system ,URI It can be used to restore the organizational structure of a hierarchical resource system .
2.2 URI Selected character set
As above ,URI choice adopt US-ASCII Character set to represent , And limit the use of some of the characters selected from them , Numbers and symbols . and , Because of the need to support hierarchies , as well as URI It contains different parts , Therefore, some characters should be reserved to separate the semantic parts .
Note: Because of the need to describe the character set or syntax , All of the following are used IETF General description system used ABNF(Augmented Backus-Naur form), That is to strengthen the Bakos paradigm .
The grammatical structure defined by the enhanced Bakos paradigm is generally as follows :
rule = definition / definition; comment CR LF
rule = <a>*<b>element
Represents a set of rules described by a definition consisting of a series of strings , The first group rule adopt ’/‘ To express in the definition ’ perhaps ’ The relationship between . If the rule needs to be annotated , Then it needs to pass ’;' To mark the beginning of a comment
The second group rule Repeat rules , among a Identify the minimum number of repetitions ,b Mark the maximum number of repetitions . for example ,2*3element identification element At least twice , Three times at most
For the specific content of the enhanced Bakos paradigm, please refer to :
https://en.wikipedia.org/wiki/Augmented_Backus%E2%80%93Naur_form
2.2.1 Percent-Encoding
because URI Only part of the agreement is selected ASCII character , Numbers and symbols , So when you need to represent symbols that are not in this range , character , Or the character is in URI When used for special purposes such as separators , You need to do this character % code . Percent code can also be called URLEncode, Its general format is :
pct-encoded = "%" HEXDIG HEXDIG
Convert characters that cannot be used directly to byte stream representation ( It's usually utf-8 code , We need to see the following and URI scheme The agreement was made ), Then each byte is converted to % Add two hexadecimal characters to indicate . for example :
“00101011” The byte needs to be encoded as “%2B” , stay ASCII In the code table, it is expressed as "+" Number
Note: Percent code doesn't care about case , But for unity and consistency , It's better to use uppercase characters
2.2.2 Reserved Characters
URI Preserve the character set .
URI Self definition includes components as well as subcomponents, So these different components It needs to be identified by a separator . The characters used to represent the separation are called reserved character sets , These character sets may be used as ( Or it will be used in the future )URI Separators for different parts .
The following is a reserved character The character set involved represents :
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
gen-delims The character set is used to represent URI component Separator between , in consideration of component There will be different subcomponents form , Therefore need sub-delims Character set to define subcomponents Separator between .
Note: These characters are in URI In general, it has special semantics , So it can't be encoded . meanwhile , If there are two URI When comparing equality , If one of them is in agreement with component Some reserved characters that cannot be encoded are encoded , Even after decoding the last two URI Same character , It would also be considered two different URI
2.2.3 Unreserved Characters
Allow to appear in URI in , And the character set that will not be used as a reserved character set becomes Unreserved Characters. The characters involved ABNF Expressed as :
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
ALPHA = a-z / A-Z
DIGIT = 0-9
These characters are non reserved characters , stay URI There is no need to code in the process of use .
Note: If in URI These characters are included in the comparison , Then the character itself or its encoding format should be considered equal , That is, if these characters are not encoded, the equality will not be affected . in addition , It's better not to encode these characters in use , Even if it's encoded , Then in the use of these characters should also be decoded .
2.2.4 summary
A picture is used to show that in URI Reserved and non reserved characters involved in , It should be noted that reserved characters need to be encoded when they are not used as separators or have special meanings .

3.URI Component
URI Grammar rules consist of a series of component form , And in the design, we need to consider the scalability and compatibility of various resource location types , So at the beginning, there will be a scheme The head specifically identifies this URI The resource type identifier defined . in addition ,URI Because it is a superset of all resource types ( It will be subdivided into URL and URN), therefore URI The definitions involved are basic definitions that need to be followed .
URI component It is generally composed of the following component form ( Use ABNF describe ):
URI = scheme ":" [ //authority ] path [ "?" query ] [ "#" fragment ]
authority = [ userinfo@ ] host [ :port ]
Note:
schme and path by required
With the above definition of grammatical rules , Let me give you an example URI The next two different identifiers define each of component part
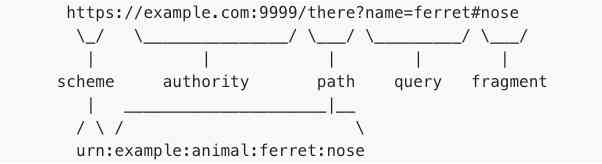
The following is a detailed description of each component part , And the corresponding grammar rules .
3.1 URI component
3.1.1 Scheme
| component | scheme |
|---|---|
| Allow character set | a-z A-Z 0-9 + . - |
| whether case-sensitive | no |
| component End identifier | : |
Note:
- The character set in the table is for clarity , Therefore, the regular is separated by unnecessary spaces , And table or relation
- The end identifier indicates that the syntax should be resolved component Parse Terminator
scheme Used to identify URI The corresponding specific agreement . Every URI All must be with scheme start .URI The rules of grammar are as follows ( Use ABNF describe ):
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
As mentioned above ,URI Define general grammar rules ,scheme The specific protocol identified will define specific syntax rules in addition to the general rules . for example , With geo by scheme The agreement URI, Represents a specific geographic location , The grammatical rules are as follows :
geo:<lat>,<lon>[<alt>][u=<uncertainty>]
Reference from RFC 5870
URI scheme The official registration information of is currently provided by IANA(Internet Assigned Numbers Authority) Organize to add and maintain , At present, it contains about 335 Different protocols scheme, For details, please refer to https://www.iana.org/assignments/uri-schemes/uri-schemes.xhtml
3.1.2 Authority
| component | Authority |
|---|---|
| component Start identifier | // |
| component End identifier | / ? # |
authority component The purpose of the design is to set a namespace , And identify which organization the namespace is managed by , for example baidu.com, google.com wait .authority Generally, it consists of three parts , Includes optional userinfo, port And the required host part .
About why Authority Some will choose // As a starting sign ,Tim Berners-Lee I have answered :
- You need to choose a naming system to name resources hierarchically ,/ As unix System common separator can be in URI In the design of , Therefore use / As a relative URI The delimiter
- There needs to be a sign that will host part ( similar www.example.com) Same as URI The other parts of , This part of the design refers to Apollo domain system ( Its use //computername/file/path Name it ) Design method of
- Now let's look at , He thinks the grammar is redundant , Prefer to go directly through : To separate domain names , for example http://www.example.com/foo/bar Transcribe as http:www.example.com/foo/bar, Writing in this way can also identify server And it's simpler
thus it can be seen , Standard design also needs to be iterated and experimented with again and again :)
3.1.2.1 Userinfo
| component | Userinfo |
|---|---|
| Allow character set | pct-encode Character set unreserved Character set sub-delims Character set : |
| whether case-sensitive | yes |
| component End identifier | @ |
userinfo Contains user related information ( It's usually the name , Old format user:password It has been abandoned because of the safety risks involved ), At the same time, it needs to pass @ Conform to and host separation .Userinfo Some of the grammar rules are as follows ( Use ABNF describe ):
userinfo = *( unreserved / pct-encoded / sub-delims / ":" )
3.1.2.2 Host
| component | Host |
|---|---|
| Allow character set | pct-encode Character set unreserved Character set sub-delims Character set |
| whether case-sensitive | no |
| component End identifier | / : |
Service providers through host To provide services , At the same time, it is based on dns Domain name resolution , server and host It can not be one-to-one correspondence between them .host Parts can be represented in three ways ,IPv6, IPv4 perhaps registered name.registered name host The rules of grammar are as follows ( adopt ABNF describe ):
host = IPv6address / IPv4address / reg-name
IPv6address = [ HEXDIG *( :: HEXDIG ) ]
IPv4address = DIGIT "." DIGIT "." DIGIT "." DIGIT
reg-name = *( unreserved / pct-encoded / sub-delims )
3.1.2.2 Port
| component | Port |
|---|---|
| Allow character set | 0-9 |
| component End identifier | / |
port For optional , At the same time expressed in decimal system . stay URI In the syntax ,port Need to follow : after .port The rules of grammar are as follows ( Use ABNF describe ):
port = *DIGIT
Each of these scheme A default port is usually defined . for example , http Definition 80 Default port ,https Definition 443 Default port, etc .
3.1.3 Path
| component | Path |
|---|---|
| Allow character set | pct-encode Character set unreserved Character set sub-delims Character set @ : |
| component End identifier | ? # EOF |
path Marked host Under the specific resource path , Contains a series of passes through / separated segments. It should be noted that , If URI Already included authority part , that path Partially or empty , Or you need to use / Let's start with . in addition ,URI It also allows relative-path How to use , In this way, the first paragraph path segment Can not contain :( If you include , Will be parser Think it's authority part ). The following is a simplified path Rule of grammar ( Use ABNF describe ):
path = path-abempty / path-relative
path-abempty = *( "/" segment )
path-relative = segment-nocolon *( "/" segment )
segment = *pchar
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
segment-nocolon = unreserved / pct-encoded / sub-delims / "@"
3.1.4 Query
| component | Query |
|---|---|
| Allow character set | pct-encode Character set unreserved Character set sub-delims Character set @ : |
| component Start identifier | ? |
| component End identifier | # EOF |
query Some of them provide auxiliary information for locating resources ,query Its internal grammar is not clearly defined , But generally by name-value A string of key value pairs , In the middle by a separator & separation . for example :name1=value1&name2=value2.query The rules of grammar are as follows ( Use ABNF describe ):
query = *( pchar / "/" / "?" )
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
3.1.5 Fragment
| component | Query |
|---|---|
| Allow character set | pct-encode Character set unreserved Character set sub-delims Character set @ : / ? |
| component Start identifier | # |
| component End identifier | EOF |
fragment Is the paragraph identifier , Usually used to identify a resource A specific part of ( A subset or part of a resource , Or some other resources described by this resource ). fragment With # As the starting identifier , The grammatical rules are as follows ( adopt ABNF describe ):
fragment = *( pchar / "/" / "?" )
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
3.1.6 Summary
each component The allowed character set part is something we need to pay special attention to , Attention should be paid to the five component Allow to use between gen-delims Character set , At every component Inside ( That is, between the components ) Allow to use sub-delims Character set .
3.2 analysis URI
How to analyze through the program URI, And get the URI each component?
In the previous section ABNF Grammar rules describe ,URI Satisfy context free grammar . therefore , We can present the whole through the grammar diagram URI The rules of parsing , as follows :

With the image above , Use recursive descent , Parsed pseudo code is very easy to write :
/** * Read the next character **/ function next() { skip space; read next char and return; } /** * Pre scan , Check the corresponding input Whether the string contains special_char, * And its location **/ function contains(input, special_char) { start = input.start, end = input.end; while (start < end) then if special_char equals start then return; end return start } /** * Yes uri Analytic function of * Specific analysis component Method is parse_*, To match the character set and syntax rules, please refer to the above ABNF **/ function parse(string uri) { parse_scheme; skip next ';' ; if next() == "//" then if contains(substring_uri(// until path), '@') then parse_userinfo; end parse_host; if next() == ':' then parse_port; end end parse_path; if next() == '?' then parse_query; end if next() == '#' then parse_fragment; end }
5. Further discussion Encode and Decode
When should I encode perhaps decode?
First say URI Design purpose of ,URI Designed and widely distributed on the World Wide Web , So for each subsystem , The most important thing is media compatibility , So it was designed and used widely ASCII Code to carry .
therefore , It's generating URI In the process , We should finish each one first componet Part of the code , And then in Union gen-delimiter Stitching into URI. Because of the various scheme The specific agreement is different , So only in generating URI In the process of , Only then can we know exactly which delimiter Will need to be coded , Or be used as real delimiter. once URI Be generated , The URI It should be maintained when it is transmitted Percent sign encode The format of .
When the percent sign encodes URI When decoding , It should be passed first gen-delimiter as well as sub-delimiter Will all component To separate , And then to each component Decode separately . This ensures that the generated URI Decoded completely .
in addition , It should be noted that ,2.2.3 Mentioned in unreserved Character sets can be encoded and decoded at any time , But recommendations are generating URI Do not encode these character sets when , At the same time, the percentage encoding format of these character sets should be decoded first .
Note: You shouldn't treat the same URI Repeat encoding or decoding , And that leads to URI The semantics represented by is invalid . for example , For those that have been coded with a percent sign URI When you code again , The percent sign will be re coded again , Which leads to URI In decoding, the meaning is wrong .
5.1 Realization encode and decode
According to the above ,encode It needs to be based on the corresponding component It doesn't need to be done escape( That is, there is no need to code ) The rules of characters , Then the judgment and coding are carried out one by one , After that, we will encode component Splicing is called URI( Of course , If all delimiter No need to encode , That can be directly to the whole URI Encoding , Unwanted escape The character set contains these directly delimiter character ). decode It is necessary to set the component according to delimiter To break up , And then to each of them component Decode under the rules of characters to be decoded .
Note: In the sign ASCII Other than character set , General is to use Unicode Character set , The encoding method is UTF-8.
therefore , In the process of encoding and decoding , If the programming language level uses UTF-16 Code the characters ( Be similar to Java and JavaScript), So we need to turn it into UTF-8 code , At the same time, it needs to be targeted at UTF-16 It brings surrogate pair Carry out additional processing .
About surrogate pair describe , You can refer to
https://stackoverflow.com/questions/5903008/what-is-a-surrogate-pair-in-java#:~:text=The%20term%20%22surrogate%20pair%22%20refers,values%20between%200x0%20and%200x10FFFF.&text=This%20is%20done%20using%20pairs%20of%20code%20units%20known%20as%20surrogates.
5.1.1 encode
encode The implementation of the need to pay attention to is the need to code the byte % code , The pseudocode is as follows :
/** * For a certain paragraph string s Conduct URI encode code * Pass in s And character sets that don't need to be encoded dontNeedEncodingSet, return URI encode After string * * dontNeedEncodingSet Character sets need to be based on 3.1 Medium component Describe , for example Path Does not need to encode the character set * It's usually unreserved Character set sub-delims Character set @ :(sub-delims Character set and @ : If it needs to appear in * component It's not used to separate semantics , So it also needs to be done encode), In addition, different language implementations do not need to encode character sets * There may be different choices on **/ function encode(s, dontNeedEncodingSet) { // Statement R For the result string def R, index = 0, strLen = s.length(); while index < strLen then def c by s stay index The character below indicates ; if c Included in dontNeedEncodingSet in then R += c; else def Interim results out; /** * Here we need to consider if it's utf-16 Character encoding , So it needs to be judged surrogate pair **/ if c stay surrogate pair Within the range represented by the first character in then def c2 by ++index Position character ; take c c2 Two characters make up utf-16 And carry on utf-8 code ; Assign the above results to out; else If c by utf-16 code , Need to change to utf-8 code ; out = c; end // Core percent sign encode take out Every byte in out_byte; R += '%' + ((out_byte >> 4) & 0xF) To 16 Base case means + ((out_byte) & 0xF) To 16 Base case means ; end ++index; end return R; }
5.1.2 decode
decode We need to pay attention to meet % Read the following characters to decode , At the same time, if the language implementation uses utf-16 Coding then needs to be on surrogate pair To restore ( This part of the language itself generally provides methods for utf-8 convert ), The pseudocode is as follows :
/** * Yes s decode , Return decoded string **/ function decode(s) { // Statement R As a result string def R, index = 0, lenStr = s.length(); while index < lenStr then def c by s stay index The character below indicates ; if c == '%' then def Interim results out; while c == '%' && index + 2 < lenStr then Read index+1, index+2 character c1, c2; // The core decode out += ( The character is converted to hex Express (c1)) << 4 | ( The character is converted to hex Express (c2)); index += 3; end // Abnormal situation report error if c == '%' && index < lenStr then Throw an error ; // Be careful : If the language implementation needs to utf-16 code , Well, we need to put out To utf-16 code R += out; else R += c; ++index; end end return R; }
5.1.3 Summary
I believe that you have already been right about URI With a relatively comprehensive understanding , In practical use , It also depends on the correspondence provided by the language encode,decode Method document to further understand its encoding and decoding definition of component Special characters are reserved , This will provide the language used with encode/decode Have a deeper understanding :)
**
Enjoy your coding trip~
author : Wang Yang ( Good future Java Development experts )
版权声明
本文为[Tal technologies]所创,转载请带上原文链接,感谢
边栏推荐
- 学会了volatile,你变心了,我看到了
- [cloud service] there are so many ECS instances on alicloud server, how to select the type? Best practice note
- Regular backup of WordPress website program and database to qiniu cloud
- 趣文分享:C 语言和 C++、C# 的区别在什么地方?
- Solution to cross domain problem of front end separation
- Is parameter passing in go language transfer value or reference?
- 【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
- Learn volatile, you change your mind, I see
- Flink series (0) -- Preparation (basic stream processing)
- WordPress网站程序和数据库定时备份到七牛云图文教程
猜你喜欢
学会了volatile,你变心了,我看到了

Chapter 2 programming exercises
Introduction to latex
Function classification big PK! How to use sigmoid and softmax respectively?
Simple process of reading pictures by QT program developed by Python
Swagger介绍和应用
VirtualBox安装centos7
![[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!](/img/dd/498ac0036c87037ea91debe72c1883.jpg)
[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!
Countdownlatch explodes instantly! Based on AQS, why can cyclicbarrier be so popular?

在Python中创建文字云或标签云
随机推荐
如何将PyTorch Lightning模型部署到生产中
选择排序
Dynamic relu: Microsoft's refreshing device may be the best relu improvement | ECCV 2020
Countdownlatch explodes instantly! Based on AQS, why can cyclicbarrier be so popular?
Proficient in high concurrency and multithreading, but can't use ThreadLocal?
Simulink中封装子系统
【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
接口测试工具Eolinker进行post请求
Newbe.ObjectVisitor 样例 1
PAT_ Grade A_ 1056 Mice and Rice
Django之简易用户系统(3)
Learn volatile, you change your mind, I see
Server side resolution of lengthfieldbasedframedecoder of GetBytes
Using fastai to develop and deploy image classifier application
Not a programmer, code can't be too ugly! The official writing standard of Python: pep8 everyone should know
MongoDB增删改查操作
Experiment 1 assignment
Creating a text cloud or label cloud in Python
go语言参数传递到底是传值还是传引用?
实验一作业