当前位置:网站首页>【MobileNet V3】《Searching for MobileNetV3》
【MobileNet V3】《Searching for MobileNetV3》
2022-07-02 06:26:00 【bryant_meng】

ICCV-2019
文章目录
1 Background and Motivation
【MobileNet】《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》(CVPR-2017)
【MobileNet V2】《MobileNetV2:Inverted Residuals and Linear Bottlenecks》(CVPR-2018)
deliver the next generation of high accuracy efficient neural network models to power on-device computer vision
2 Related Work
手动设计网络
reducing the number of parameters -> reducing the number of operations (MAdds) -> reducing the actual measured latencyNAS
cell level -> block levelQuantization
knowledge distillation
3 Advantages / Contributions
NAS + 手动设计组装成 mobilenet v3 backbone,提出了 hard swish 激活函数(swish 改进版),提出了 Lite R-ASPP 分割头(R-ASPP 改进版),在分类、目标检测、分割数据集上速度和精度均有提升
4 Method
1)Network Search
Platform-Aware NAS for Blockwise Search(来自 MnastNet,稍微修改了一下 reward design 的权重)
NetAdapt for Layerwise Search
search per layer for the number of filters
maximizes △ A c c △ l a t e n c y \frac{\bigtriangleup Acc}{\bigtriangleup latency} △latency△Acc
2)Network Improvements
Redesigning Expensive Layers
search 后的网络头尾比较重,进行了优化
头部
channels 32 + ReLU or swish 减小到了 channels 16 + hard swish
尾部

Nonlinearities

s w i s h ( x ) = x ⋅ σ ( x ) swish(x) = x \cdot \sigma(x) swish(x)=x⋅σ(x)
swish activation function 虽然提升了网络精度,但对硬件部署不够友好,增加了计算时间,作者采取了如下的改进(piece-wise linear)
h − s w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 h-swish(x) = x \frac{ReLU6(x+3)}{6} h−swish(x)=x6ReLU6(x+3)
比 relu 慢的
only use h-swish at the second half of the model(we find that most of the benefits swish are realized by using them only in the deeper layers)
Large squeeze-and-excite
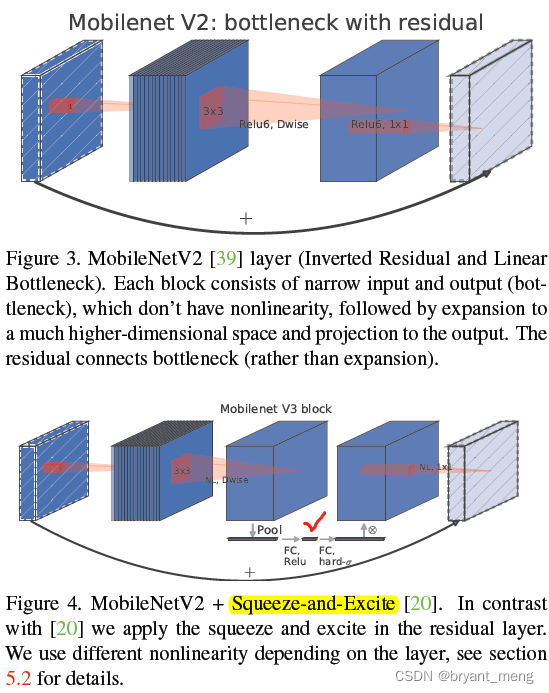
v3 相比于 v2,采用了 SE 模块,SE 里面的 sigmoid 也是采用的 hard 形式,也即 R e L U 6 ( x + 3 ) 6 \frac{ReLU6(x+3)}{6} 6ReLU6(x+3)

作者把 SE 模块中的 squeeze fc 固定成 block 中 expand 通道数的 1/4(图 4 红√ 处)
no discernible latency cost
MobileNetV3 Definitions



5 Experiments
use single-threaded large core in all our measurements
5.1 Datasets
- ImageNet
- COCO
- Cityscapes
5.2 Classification

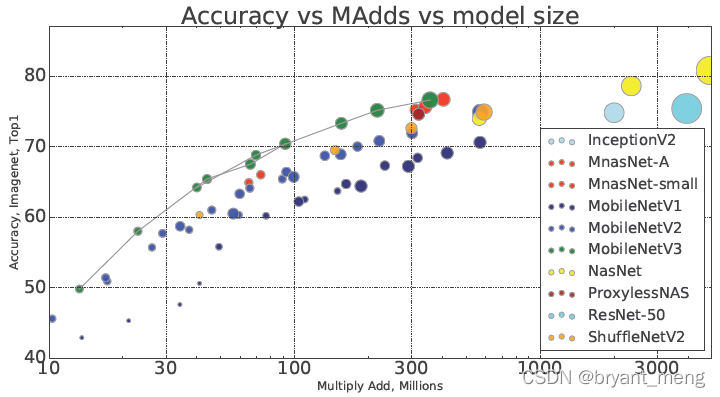
左上角最好
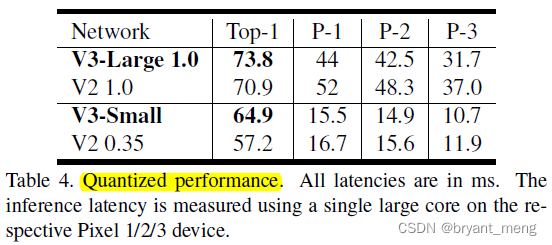
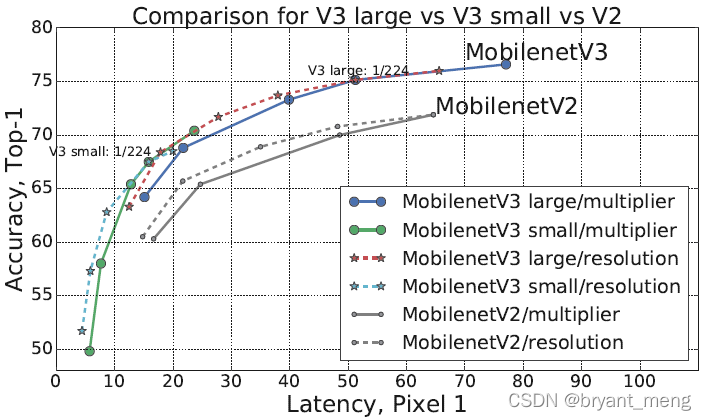

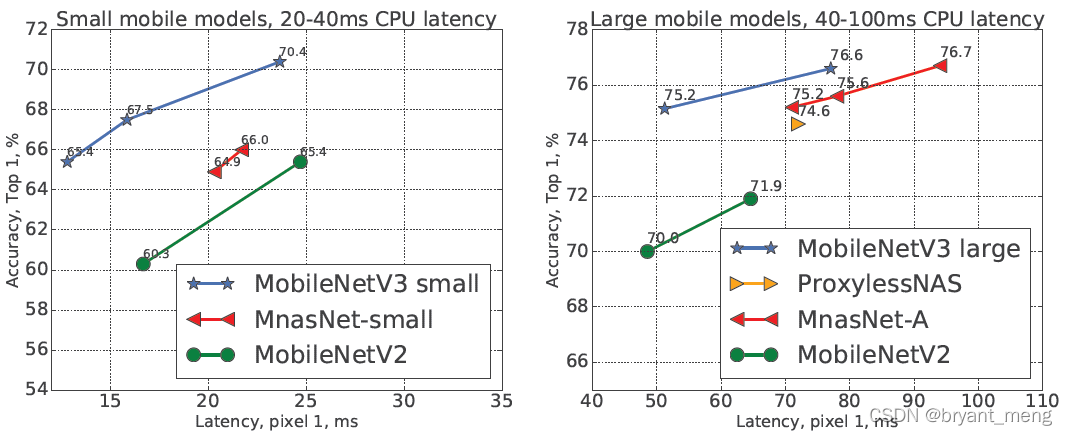
1)Impact of non-linearities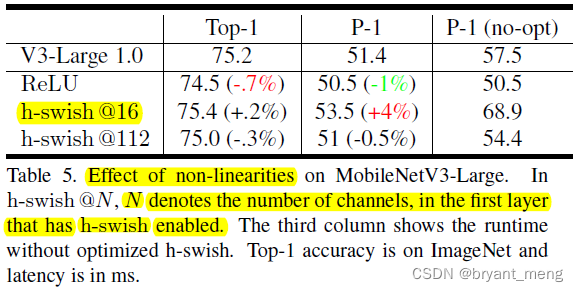
这里的 112 看的不是特别懂,N 越大按道理用的 h-swish 越多,速度要慢一些,怎么还快了
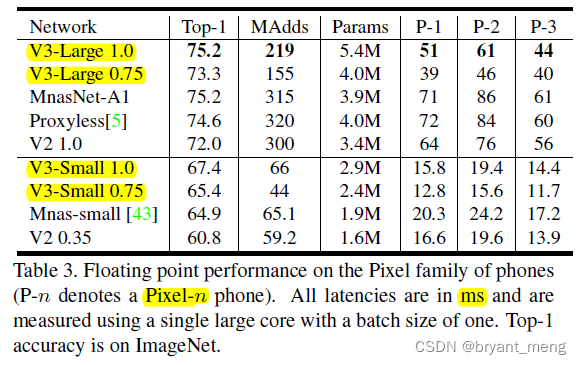
2)Impact of other components
5.3 Detection

mAP 离谱,哈哈
5.4 Segmentation
R-ASPP 基础上改进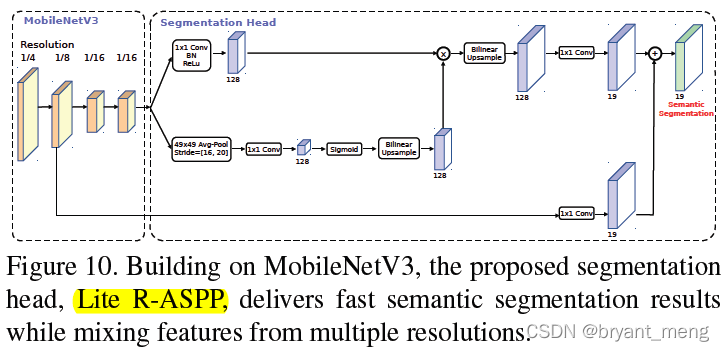


6 Conclusion(own) / Future work
Pareto-optimal,帕累托最优(来自百度百科)
帕累托最优(Pareto Optimality),也称为帕累托效率(Pareto efficiency),是指资源分配的一种理想状态,假定固有的一群人和可分配的资源,从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化。
帕累托最优状态就是不可能再有更多的帕累托改进的余地;换句话说,帕累托改进是达到帕累托最优的路径和方法。 帕累托最优是公平与效率的“理想王国”。是由帕累托提出的。MobileNet V3 = MobileNet v2 + SE + hard-swish activation + half initial layers channel & last block do global average pooling first(来自 盖肉特别慌)
边栏推荐
- Delete the contents under the specified folder in PHP
- Implement interface Iterable & lt; T>
- 机器学习理论学习:感知机
- [torch] some ideas to solve the problem that the tensor parameters have gradients and the weight is not updated
- What if a new window always pops up when opening a folder on a laptop
- SSM garbage classification management system
- 【Programming】
- 常见CNN网络创新点
- Determine whether the version number is continuous in PHP
- 【Mixup】《Mixup:Beyond Empirical Risk Minimization》
猜你喜欢
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》

半监督之mixmatch

Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered

Classloader and parental delegation mechanism
Faster-ILOD、maskrcnn_benchmark安装过程及遇到问题
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video

Proof and understanding of pointnet principle
【深度学习系列(八)】:Transoform原理及实战之原理篇
【多模态】CLIP模型
随机推荐
Interpretation of ernie1.0 and ernie2.0 papers
Ppt skills
【Random Erasing】《Random Erasing Data Augmentation》
Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
CONDA creates, replicates, and shares virtual environments
Using compose to realize visible scrollbar
【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
Implementation of purchase, sales and inventory system with ssm+mysql
【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
Execution of procedures
CONDA common commands
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
win10+vs2017+denseflow编译
PHP returns the abbreviation of the month according to the numerical month
ModuleNotFoundError: No module named ‘pytest‘
Feeling after reading "agile and tidy way: return to origin"
Handwritten call, apply, bind
[model distillation] tinybert: distilling Bert for natural language understanding
Thesis writing tip2
Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary