当前位置:网站首页>【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
2022-07-02 07:39:00 【bryant_ meng】

arXiv-2018
List of articles
1 Background and Motivation
CV Most communities focus on designing better network structures ,Less attention has been paid to finding better data augmentation methods that incorporate more invariances(teach a model about invariances in the data domain)
The author aims to automate(Reinforcement Learning) the process of finding an effective data augmentation policy for a target dataset
2 Related Work
A little
3 Advantages / Contributions
automate Data augmentation , We have achieved SOTA, And can generalize well across different models and datasets( Data distribution still needs to have a certain correlation , The augmentation strategy proposed earlier can shield the model , Across datasets )
Despite the observed transferability, we find that policies learned on data distributions closest to the target yield the best performance

4 Method
Reinforcement learning (Proximal Policy Optimization algorithm) Search data expansion strategy ,
The search space is
https://pillow.readthedocs.io/en/stable/reference/ImageOps.html(PIL Realization )
ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout, Sample Pairing
invert According to the given probability value, the pixel values of some or all channels are changed from v Set to 255-v
Equalize Histogram equalization
Solarize Within the specified threshold , Invert all pixels ( Above the threshold , be 255-v).
from PIL import Image, ImageOps # creating a image1 object im1 = Image.open("1.jpg") im2 = ImageOps.solarize(im1, threshold = 130) im2.show()Posterize: Retain Image The height of the pixel value of each channel bits position
from PIL import Image, ImageOps im1 = Image.open("1.jpg") im2 = ImageOps.posterize(im1, bits=2) im2.show()128-64-32-16-8-4-2-1
bits=1, The maximum value of each channel of the image is 128
bits=2, The maximum value of each channel of the image is 128+64 = 192By analogy bits 1~8 The maximum value of the corresponding image 128-192-224-240-248-252-254-255

16 Kind of data augmentation Method ( Different probabilities probability——11 individual values uniform spacing, Different parameter configurations magnitude——10 Level uniform spacing), Some augmentation methods do not magnitude,eg:invert
Every sub-policies Two data augmentation methods (16 choose 2) Serial combination ——each sub-policy consisting of two image operations to be applied in sequence
A total of 5 Kind of sub-policies, The search space is roughly ( ( 16 × 11 × 10 ) 2 ) 5 = ( 16 × 11 × 10 ) 10 = 2.9 × 1 0 32 ((16 \times 11 \times 10)^2)^5 = (16 \times 11 \times 10)^{10} = 2.9 \times 10^{32} ((16×11×10)2)5=(16×11×10)10=2.9×1032
Augmented form
During training ,a sub-policie is randomly chosen(5 choose 1) for each image in each mini-batch
Reward mechanism ,child model(a neural network trained as part of the search process) Of acc
5 Experiments
5.1 Datasets
- CIFAR-10,5W,reduced CIFAR-10(which consists of 4,000 randomly chosen examples, to save time for training child models during the augmentation search process)
- CIFAR-100
- SVHN,reduced SVHN dataset of 1,000 examples sampled randomly from the core training set.
- ImageNet,reduced ImageNet,with 120 classes (randomly chosen) and 6,000 samples
- Stanford Cars
- FGVC Aircraft
5.2 Experiments and Results
1)CIFAR-10 and CIFAR-100 Results
The more selected augmentation methods are Equalize, AutoContrast, Color, and Brightness, and ShearX/Y Less
Let's see the results
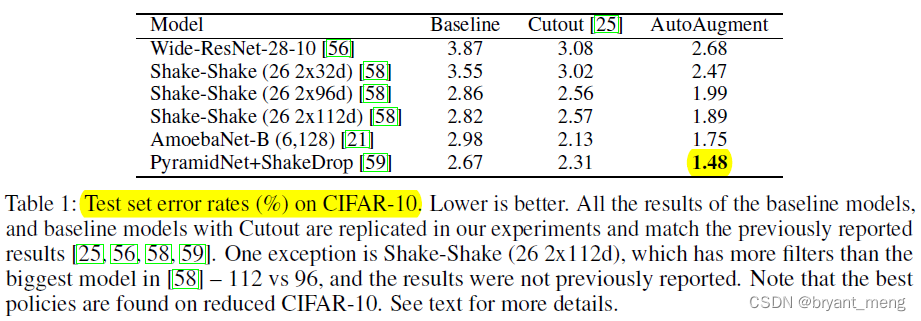
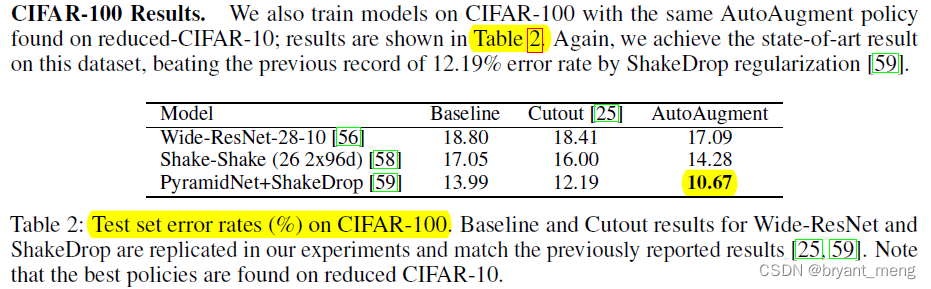
Let's look at the comparison with semi supervised methods 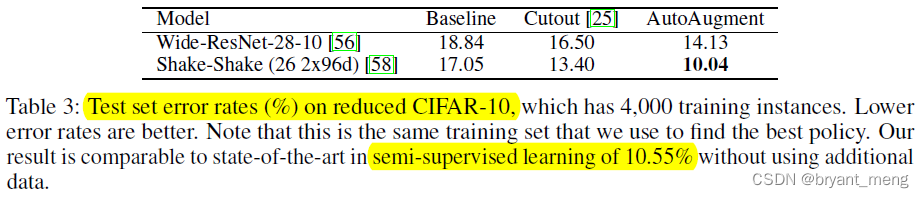
The author only used 4000 Zhang labeled samples, Semi supervised method use an additional 46,000 unlabeled samples in their training
The effect of the author is better
2)SVHN Results
Invert, Equalize, ShearX/Y, and Rotate More people were selected
the specific color of numbers is not as important as the relative color of the number and its background.
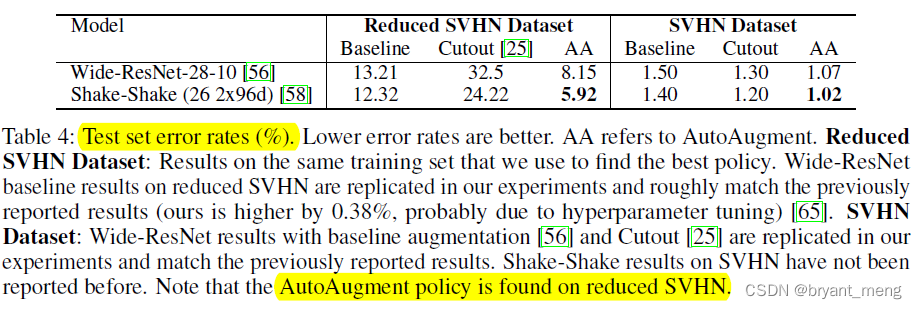
AutoAugment leads to more significant improvements on the reduced dataset than the full dataset( Ha ha ha , Data itself is king , Data expansion is also to increase the diversity of data )
3)ImageNet Results
focusing on color-based transformations + rotation

4)Fine Grained Visual Classification Datasets
use table 4 Expansion strategy 
The gain effect is obvious ,Stanford Cars Up or SOTA
5)Importance of Diversity in AutoAugment Policies

20 Basically the best
6 Conclusion(own) / Future work
Data to enhance : Elastic deformation (Elastic Distortion)
CUDA Accelerate elastic deformation and other image widening ( Medical images )
《Data Augmentation by Pairing Samples for Images Classification》(arXiv-2018)

We find that for a fixed amount of training time, it is more useful to allow child models to train for more epochs rather than train for fewer epochs with more training data.
Code [CVPR2019]AutoAugment: Based on the NAS Method's data enhancement strategy

边栏推荐
- 常见的机器学习相关评价指标
- A slide with two tables will help you quickly understand the target detection
- 华为机试题-20190417
- Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
- Tencent machine test questions
- Using compose to realize visible scrollbar
- parser.parse_args 布尔值类型将False解析为True
- [introduction to information retrieval] Chapter 6 term weight and vector space model
- Installation and use of image data crawling tool Image Downloader
- Illustration of etcd access in kubernetes
猜你喜欢
![[paper introduction] r-drop: regulated dropout for neural networks](/img/09/4755e094b789b560c6b10323ebd5c1.png)
[paper introduction] r-drop: regulated dropout for neural networks
基于onnxruntime的YOLOv5单张图片检测实现
![[introduction to information retrieval] Chapter 1 Boolean retrieval](/img/78/df4bcefd3307d7cdd25a9ee345f244.png)
[introduction to information retrieval] Chapter 1 Boolean retrieval

Implementation of yolov5 single image detection based on pytorch
SSM second hand trading website
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
使用百度网盘上传数据到服务器上

一份Slide两张表格带你快速了解目标检测

超时停靠视频生成
Point cloud data understanding (step 3 of pointnet Implementation)
随机推荐
A summary of a middle-aged programmer's study of modern Chinese history
Installation and use of image data crawling tool Image Downloader
基于pytorch的YOLOv5单张图片检测实现
[in depth learning series (8)]: principles of transform and actual combat
Using compose to realize visible scrollbar
Alpha Beta Pruning in Adversarial Search
MySQL composite index with or without ID
allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
SSM laboratory equipment management
Get the uppercase initials of Chinese Pinyin in PHP
Sorting out dialectics of nature
实现接口 Interface Iterable<T>
[introduction to information retrieval] Chapter 7 scoring calculation in search system
Delete the contents under the specified folder in PHP
mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作
传统目标检测笔记1__ Viola Jones
Practice and thinking of offline data warehouse and Bi development
Optimization method: meaning of common mathematical symbols
Classloader and parental delegation mechanism
ABM论文翻译