当前位置:网站首页>mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作
mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作
2022-07-02 06:26:00 【chenf0】
前期配置及遇到的乱七八糟的问题等见:https://blog.csdn.net/chenfang0529/article/details/115094036
一、导出
使用mmdetection训练自己的数据集,数据集使用VCAT进行标注,标注的文件是视频文件,将图像帧及标注文件导出为COCO格式。常用的还有PASCAL VOC
导出后包括两个文件
images和annotations
images中包含图像帧
annotations包含标注文件,我们只需要对第三个文件进行修改。
二、相关代码
1.批量修改图片名
import os
class BatchRename():
def rename(self):
path="D:\\achenf\data\\taxi\\test\\task_2_9_car_test-2021_04_13_13_25_24-coco\images"
filelist=os.listdir(path)
total_num = len(filelist)
i=595
for item in filelist:
if item.endswith('.jpg'):
src=os.path.join(os.path.abspath(path),item)
dst=os.path.join(os.path.abspath(path),''+str(i)+'.jpg') #可根据自己需求选择格式
# dst=os.path.join(os.path.abspath(path),'00000'+format(str(i))+'.jpg') #可根据自己需求选择格式,自定义图片名字
try:
os.rename(src,dst) #src:原名称 dst新名称d
i+=1
except:
continue
print ('total %d to rename & converted %d png'%(total_num,i))
if __name__=='__main__':
demo = BatchRename()
demo.rename()
2.批量修改json文件内容
json中id等需要和图片进行对应。
需要的json中包含五部分,info,categories,licenses,annotations,images
我们只需要修改annotations和images两部分。
import json
import os
path = 'D:\\achenf\data\\taxi\\train\\task_2_8_car_test-2021_04_13_13_25_07-coco\\annotations\\test'
dirs = os.listdir(path)
num_flag = 0
for file in dirs: # 循环读取路径下的文件并筛选输出
if os.path.splitext(file)[1] == ".json": # 筛选csv文件
num_flag = num_flag +1
print("path ===== ",file)
print(os.path.join(path,file))
with open(os.path.join(path,file),'r') as load_f:
load_dict = json.load(load_f)
# print(load_dict)
# n=len(load_dict["image_id"])
# print(type(load_dict))
# for i in load_dict:
# print(i)
for i in load_dict['annotations']:
i['image_id'] = i['image_id'] + 595
i['id']=i['id']+2032
# if i['image_id']>=595:
# i['id']=i['id']+3015
for i in load_dict['images']:
i['id'] = i['id'] + 595
i['file_name'] = ""+str(i['id'])+".jpg"
with open(os.path.join(path,file),'w') as dump_f:
json.dump(load_dict, dump_f)
if(num_flag == 0):
print('所选文件夹不存在json文件,请重新确认要选择的文件夹')
else:
print('共{}个json文件'.format(num_flag))
最后将各个对应的部分进行合并
三、其他
1.解析xml文件,查看文件中标注个数
import os
import xml.dom.minidom
res=0
AnnoPath = r'./file_xml/0512/'
Annolist = os.listdir(AnnoPath)
for annotation in Annolist:
filename =AnnoPath + annotation
dom = xml.dom.minidom.parse(filename) # 打开XML文件
collection = dom.documentElement # 获取元素对象
objectlist = collection.getElementsByTagName('box') # s
count = objectlist.length
res =res+count
print("文件名:", filename,"标注数:", count)
print("一共标注:", res)
结果: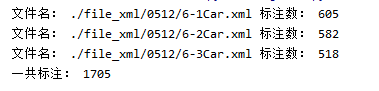
边栏推荐
猜你喜欢

Error in running test pyspark in idea2020

第一个快应用(quickapp)demo
MySQL无order by的排序规则因素
![[introduction to information retrieval] Chapter 7 scoring calculation in search system](/img/cc/a5437cd36956e4c239889114b783c4.png)
[introduction to information retrieval] Chapter 7 scoring calculation in search system

Classloader and parental delegation mechanism

Faster-ILOD、maskrcnn_benchmark安装过程及遇到问题

sparksql数据倾斜那些事儿

【信息检索导论】第三章 容错式检索
![[introduction to information retrieval] Chapter 6 term weight and vector space model](/img/42/bc54da40a878198118648291e2e762.png)
[introduction to information retrieval] Chapter 6 term weight and vector space model
离线数仓和bi开发的实践和思考
随机推荐
Oracle EBs and apex integrated login and principle analysis
使用 Compose 实现可见 ScrollBar
SSM实验室设备管理
JSP intelligent community property management system
【深度学习系列(八)】:Transoform原理及实战之原理篇
使用MAME32K进行联机游戏
Pyspark build temporary report error
CSRF attack
Faster-ILOD、maskrcnn_benchmark安装过程及遇到问题
Implement interface Iterable & lt; T>
ssm人事管理系统
Typeerror in allenlp: object of type tensor is not JSON serializable error
腾讯机试题
Three principles of architecture design
Convert timestamp into milliseconds and format time in PHP
Module not found: Error: Can't resolve './$$_gendir/app/app.module.ngfactory'
读《敏捷整洁之道:回归本源》后感
Generate random 6-bit invitation code in PHP
PHP returns the abbreviation of the month according to the numerical month
[tricks] whiteningbert: an easy unsupervised sentence embedding approach