当前位置:网站首页>【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
2022-07-02 06:26:00 【bryant_meng】

ICRA-2018
文章目录
1 Background and Motivation
深度感知和深度估计在 robotics, autonomous driving, augmented reality (AR) and 3D mapping 等工程应用中至关重要!
然而现有的深度估计手段在落地时或多或少有着它的局限性:
1)3D LiDARs are cost-prohibitive
2)Structured-light-based depth sensors (e.g. Kinect) are sunlight-sensitive and power-consuming
3)stereo cameras require a large baseline and careful calibration for accurate triangulation, and usually fails at featureless regions
单目摄像头由于其体积小,成本低,节能,在消费电子产品中无处不在等特点,单目深度估计方法也成为了人们探索的兴趣点!
然而,the accuracy and reliability of such methods is still far from being practical(尽管这些年有了显著的提升)
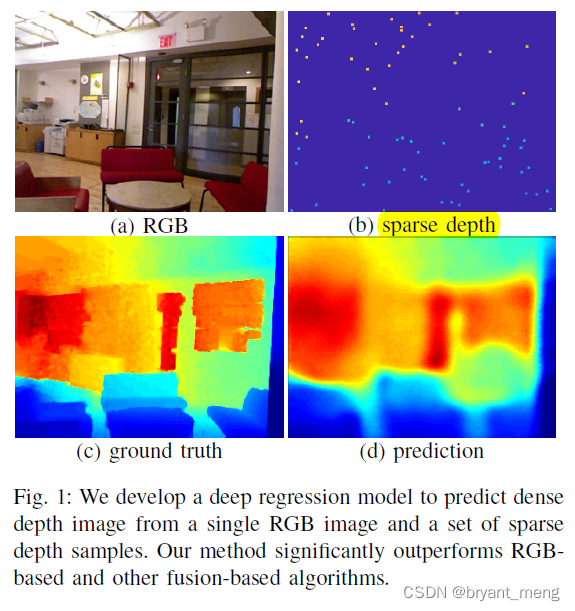
作者在 rgb 图像的基础上,配合 sparse depth measurements,来进行深度估计,a few sparse depth samples drastically improves depth reconstruction performance
2 Related Work
- RGB-based depth prediction
- hand-crafted features
- probabilistic graphical models
- Non-parametric approaches
- Semi-supervised learning
- unsupervised learning
- Depth reconstruction from sparse samples
- Sensor fusion
3 Advantages / Contributions
rgb + sparse depth 进行单目深度预测
ps:网络结构没啥创新,sparse depth 这种多模态也是借鉴别人的思想(当然,采样方式不一样)
4 Method
整体结构
采用的是 encoder 和 decoder 的形式
UpProj 的形式如下: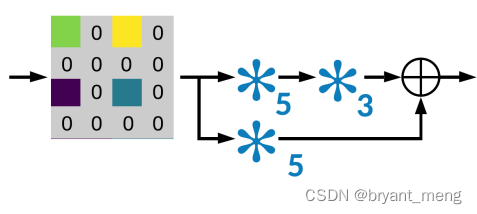
2)Depth Sampling
根据 Bernoulli probability 采样(eg:抛硬币,每次结果不相关), p = m n p = \frac{m}{n} p=nm
伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验,或称为伯努利概型。

D ∗ D* D∗ 完整的深度图,dense depth map
D D D sparse depth map
3)Data Augmentation
Scale / Rotation / Color Jitter / Color Normalization / Flips
scale 和 rotation 的时候采用的是 Nearest neighbor interpolation 以避免 creating spurious sparse depth points
4)loss function
- l1
- l2:sensitive to outliers,over-smooth boundaries instead of sharp transitions
- berHu
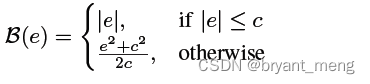
berHu 综合了 l1 和 l2
作者”事实说话”采用的是 l1
5 Experiments
5.1 Datasets
NYU-Depth-v2
464 different indoor scenes,249 Train + 215 test
the small labeled test dataset with 654 images is used for evaluating the final performance
KITTI Odometry Dataset
The KITTI dataset is more challenging for depth prediction, since the maximum distance is 100 meters as opposed to only 10 meters in the NYU-Depth-v2 dataset.
评价指标
RMSE: root mean squared error

REL: mean absolute relative error

δ i \delta_i δi:
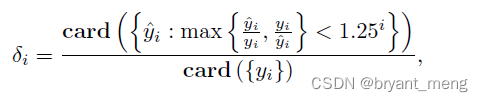
其中
- card:is the cardinality of a set(可简单理解为对元素个数计数)
- y ^ \hat{y} y^:prediction
- y y y:GT
更多相关评价指标参考 单目深度估计指标:SILog, SqRel, AbsRel, RMSE, RMSE(log)
5.2 RESULTS
1)Architecture Evaluation
DeConv3 比 DeConv2 好,
UpProj 比 DeConv3 好(even larger receptive field of 4x4, the UpProj module outperforms the others)
2)Comparison with the State-of-the-Art
NYU-Depth-v2 Dataset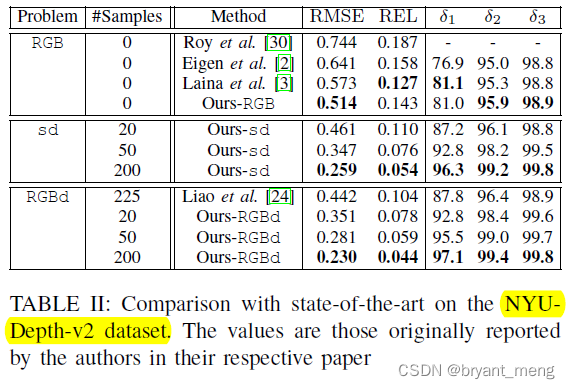
sd 是 sparse-depth 的缩写,也即输入没有 rgb
看看可视化的效果
KITTI Dataset
3)On Number of Depth Samples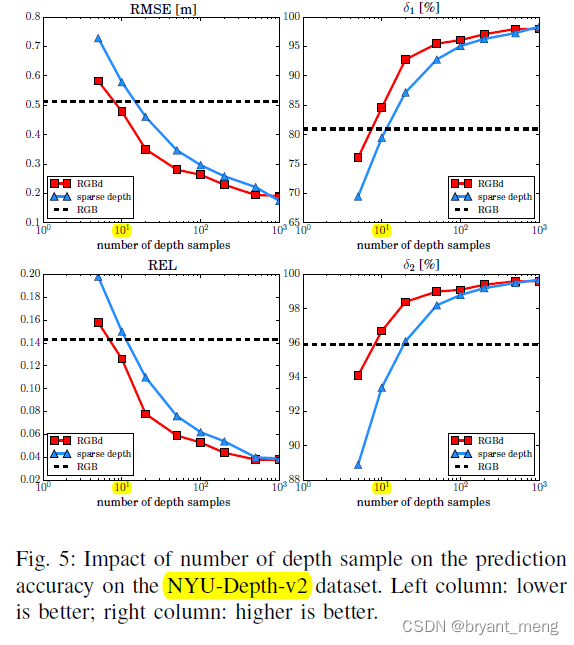
sparse 1 0 1 10^1 101 这个数量级就可以和 rgb 媲美, 1 0 2 10^2 102 飞跃,
采样越多,和 rgb 关系就不大了(performance gap between RGBd and sd shrinks as the sample size increases),哈哈哈
This observation indicates that the information extracted from the sparse sample set dominates the prediction when the sample size is sufficiently large, and in this case the color cue becomes almost irrelevant. (全采样,怎么输入我就怎么给你输出出来,别说跟 rgb 关系不大,跟神经网络关系也不大了,哈哈哈)
再看看 KITTI 上的影响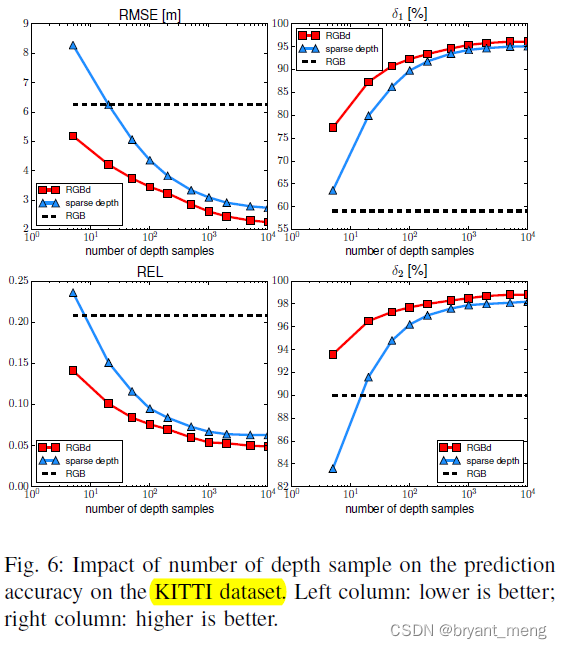
大同小异
4)Application: Dense Map from Visual Odometry Features

5)Application: LiDAR Super-Resolution
6 Conclusion(own) / Future work
presentation
https://www.bilibili.com/video/av66343637/
下面看看另外一些多模态的单目深度预测方法
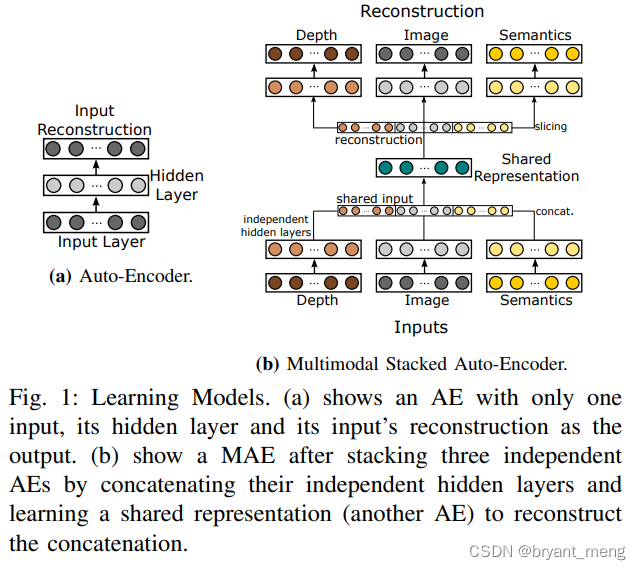
《Multi-modal Auto-Encoders as Joint Estimators for Robotics Scene Understanding》
Robotics: Science and Systems-2016
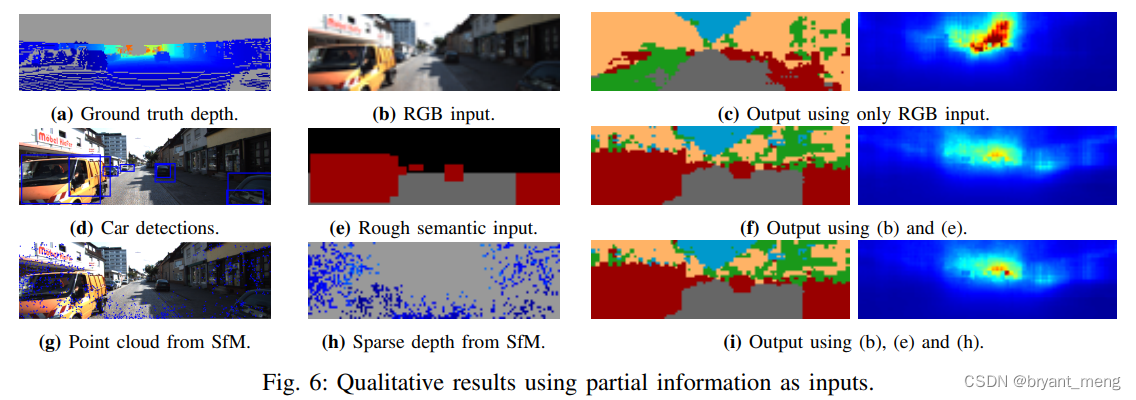
《Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation》
ICRA-2017

感觉这个落地成本比作者的更小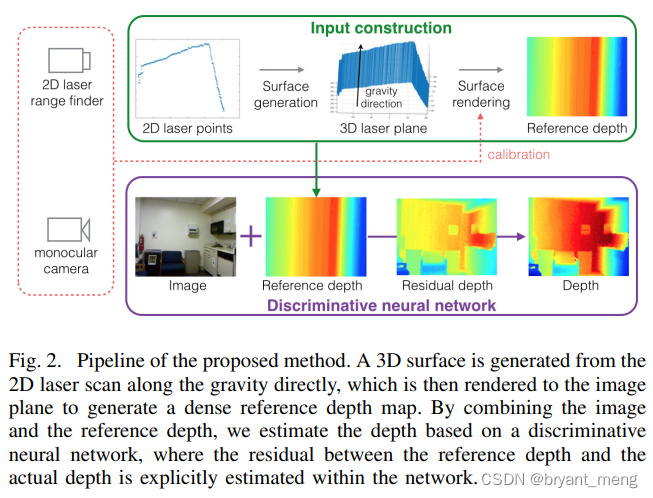

边栏推荐
- [introduction to information retrieval] Chapter 6 term weight and vector space model
- CPU的寄存器
- SSM student achievement information management system
- Proof and understanding of pointnet principle
- Classloader and parental delegation mechanism
- TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
- [introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table
- PHP returns the abbreviation of the month according to the numerical month
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
- iOD及Detectron2搭建过程问题记录
猜你喜欢

The difference and understanding between generative model and discriminant model

A slide with two tables will help you quickly understand the target detection
![[introduction to information retrieval] Chapter 7 scoring calculation in search system](/img/cc/a5437cd36956e4c239889114b783c4.png)
[introduction to information retrieval] Chapter 7 scoring calculation in search system
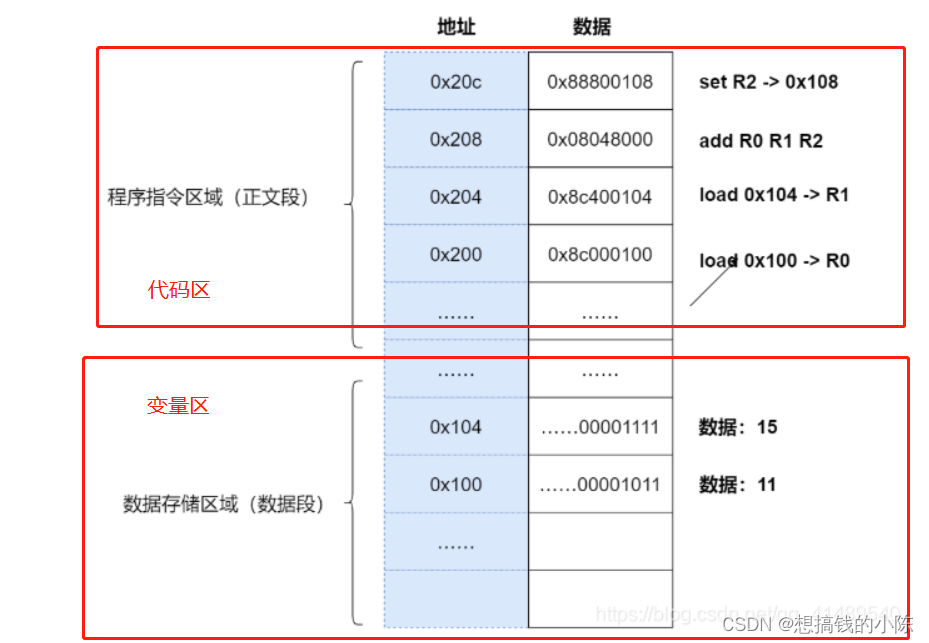
程序的执行
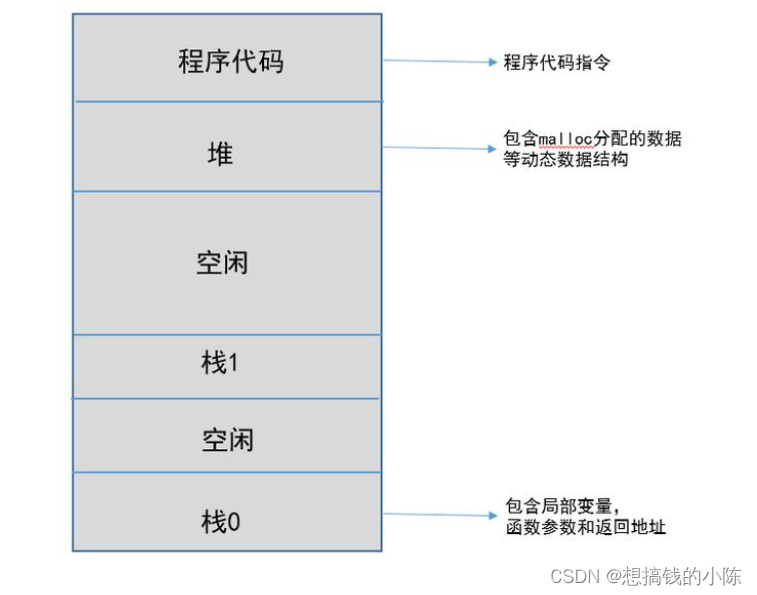
程序的内存模型
SSM laboratory equipment management

Interpretation of ernie1.0 and ernie2.0 papers

Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered

超时停靠视频生成

Regular expressions in MySQL
随机推荐
SSM laboratory equipment management
MySQL composite index with or without ID
Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
Calculate the total in the tree structure data in PHP
论文tips
[torch] some ideas to solve the problem that the tensor parameters have gradients and the weight is not updated
MySQL has no collation factor of order by
自然辩证辨析题整理
使用MAME32K进行联机游戏
Common CNN network innovations
使用Matlab实现:Jacobi、Gauss-Seidel迭代
Drawing mechanism of view (I)
Classloader and parental delegation mechanism
Practice and thinking of offline data warehouse and Bi development
win10解决IE浏览器安装不上的问题
Machine learning theory learning: perceptron
聊天中文语料库对比(附上各资源链接)
解决latex图片浮动的问题
Conda 创建,复制,分享虚拟环境
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization