当前位置:网站首页>FAQs and answers to the imitation Niuke technology blog project (III)
FAQs and answers to the imitation Niuke technology blog project (III)
2022-07-06 13:37:00 【Li bohuan】
Take the book back : FAQs and answers of the imitation Niuke technology blog project ( Two )_ Li bohuan's blog -CSDN Blog
13 In the project kafka How does it work ?
kafka introduction
Apache Kafka It's a distributed streaming platform . A distributed streaming platform should include 3 Key capabilities :
- Publish and subscribe streams data streams , Similar to message queue or enterprise messaging system
- Store data streams in a fault-tolerant and persistent manner
- Process data flow
- application : The messaging system 、 Log collection 、 User behavior tracking 、 Streaming
·kafka characteristic
- High throughput : Handle TB Massive data
- Message persistence : Persistence , Store data on hard disk , Not just stored in memory , Persistent messages , The reading speed stored in the hard disk is much lower than that of the memory , The efficiency of reading and writing hard disk depends on the way of reading hard disk , The efficiency of sequential reading and writing of hard disk is very high ,kafka Ensure that the reading and writing of hard disk messages are sequential ;
- high reliability :kafka It's distributed deployment , A server hangs up , There's something else , There's a fault tolerance mechanism
- High expansibility : When there are not enough servers in the cluster , You can expand the server , Just a simple configuration
·kafka The term
-Broker: Kafka's server , Each server in Kafka cluster is called a Broker
-Zookeeper: Software for managing clusters , When using Kafka, it can be installed separately zookeeper Or built-in zookeeper
Implementation of message queue :
Point to point implementation :BlockingQueue, The producer puts the message on the queue , Consumer takes data out of the queue , Every message will only be consumed by one consumer ;
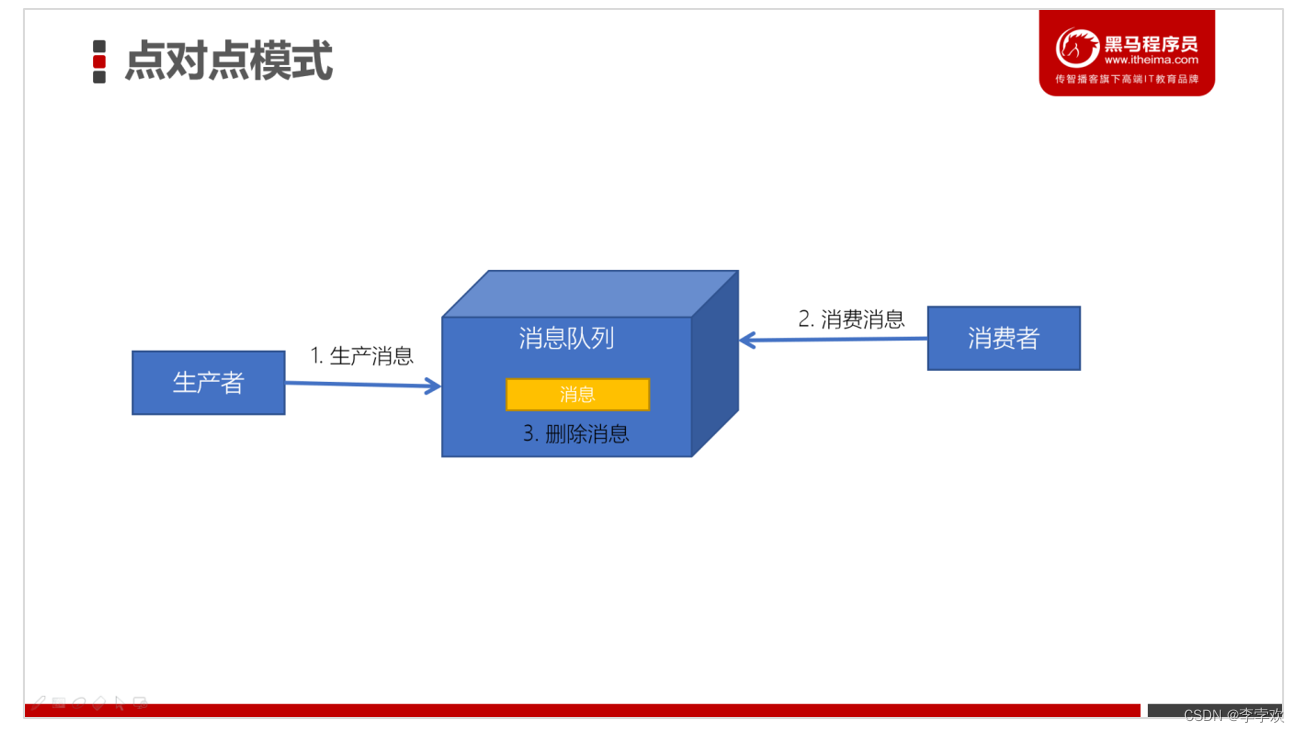
The message sender sends the production message to the message queue , Then the message receiver takes the message from the message queue and consumes the message . After the news was consumed , There is no more storage in the message queue , So it's impossible for the message receiver to consume the consumed message .

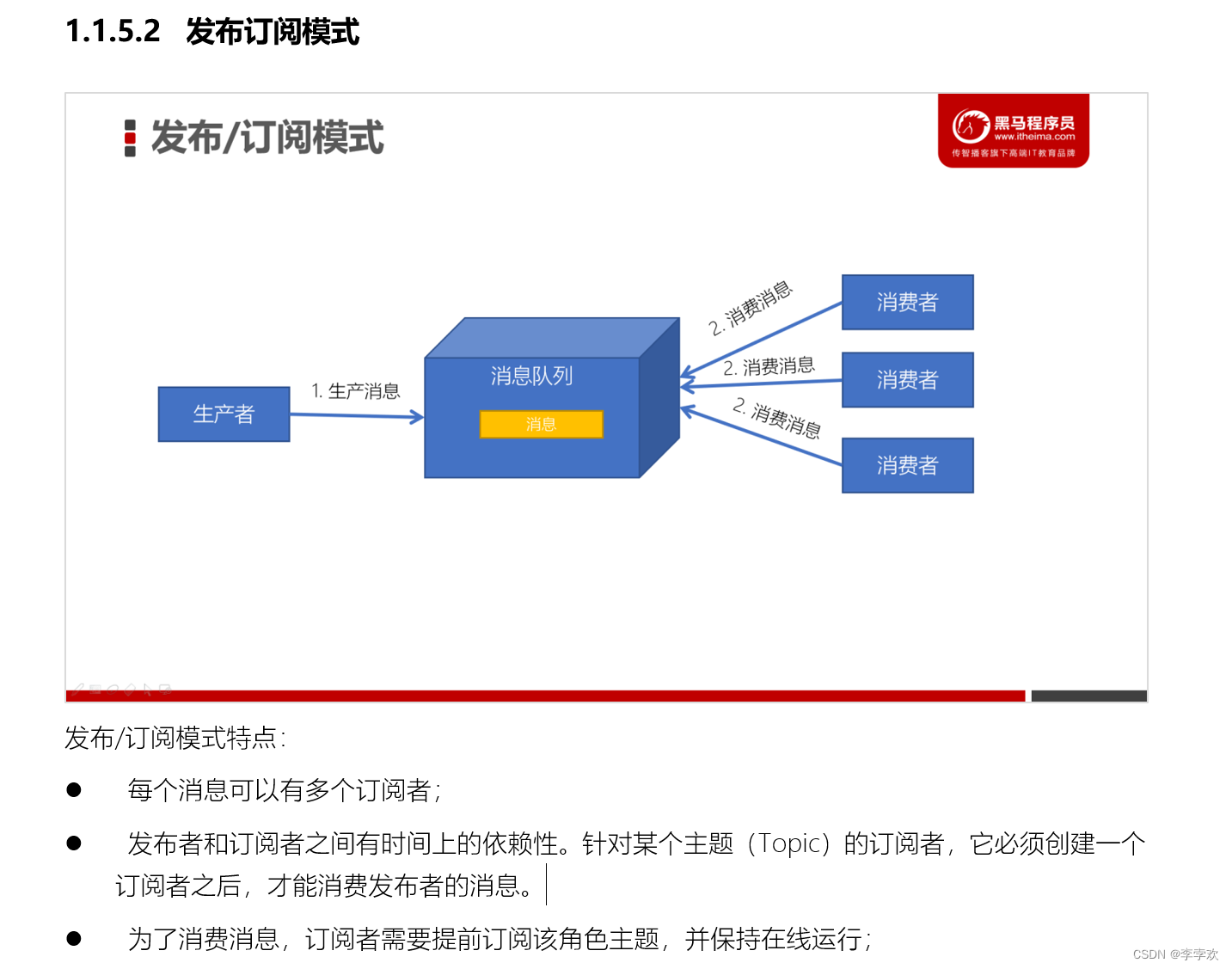
Publish subscribe mode : Producers publish messages to a certain location , Multiple consumers can subscribe to this location at the same time , This message can be read by multiple consumers ,
Kafka uses publish subscribe mode : The area where producers publish messages is called topic, Can be understood as a folder
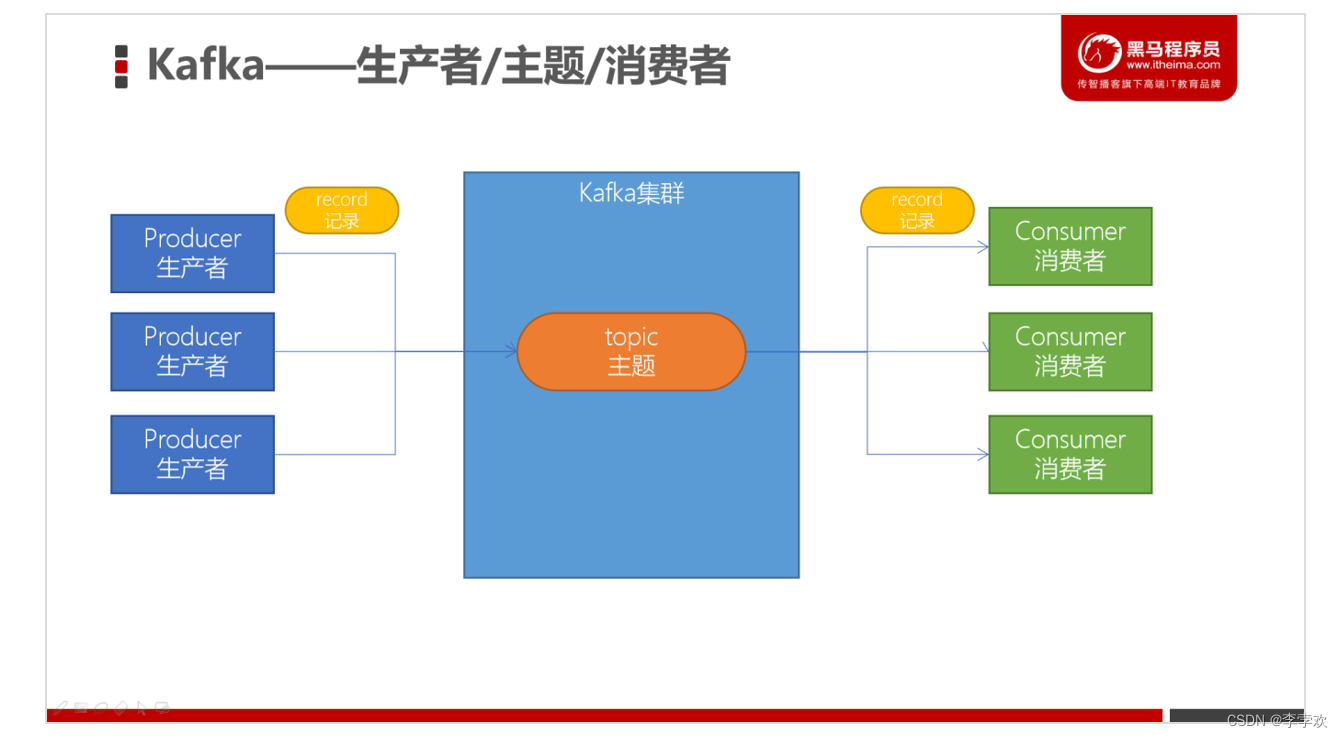
-Partition: Partition the theme
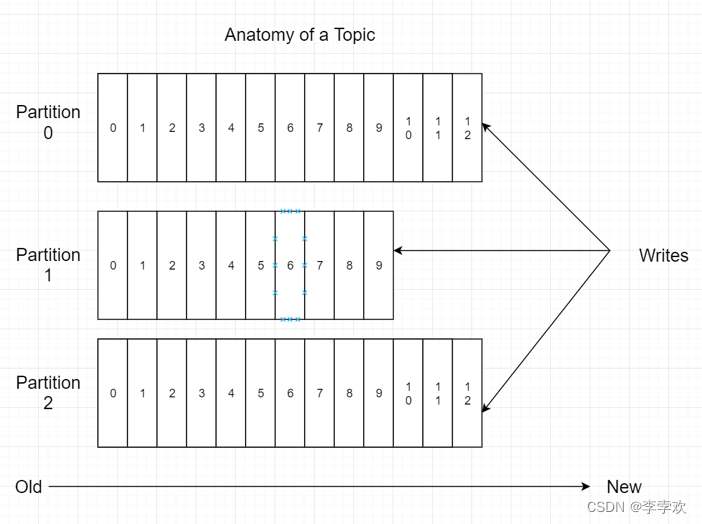
-Offset: The index of the message in the partition
-Leader Replica: copy , Kafka is distributed , Therefore, multiple copies of the partition will be repeated
Master copy : Can handle requests to get messages
-Follower Replica: Just back up the data from the copy , No response , When the primary copy hangs , Distributed will choose one of all the secondary replicas as the new primary replica
Send system notifications : --- It's very frequent , There are many user groups , Performance issues need to be considered
· Triggering event
Define three different themes , Wrap different trigger events into different messages , Publish to the corresponding topic , In this way, the producer thread can continue to publish messages ,
At this point, the consumer thread can read messages concurrently , For storage
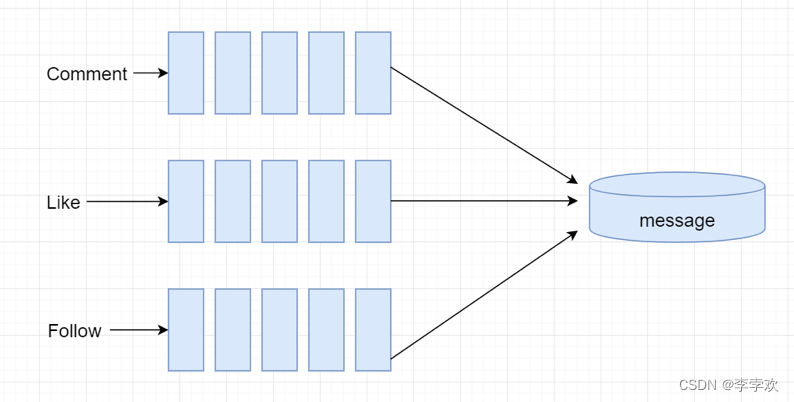
- After comments , Issue notice
- After likes , Issue notice
- After attention , Issue notice
· Handling events
- Encapsulating event objects
- Producer of development events
- Consumers of development events
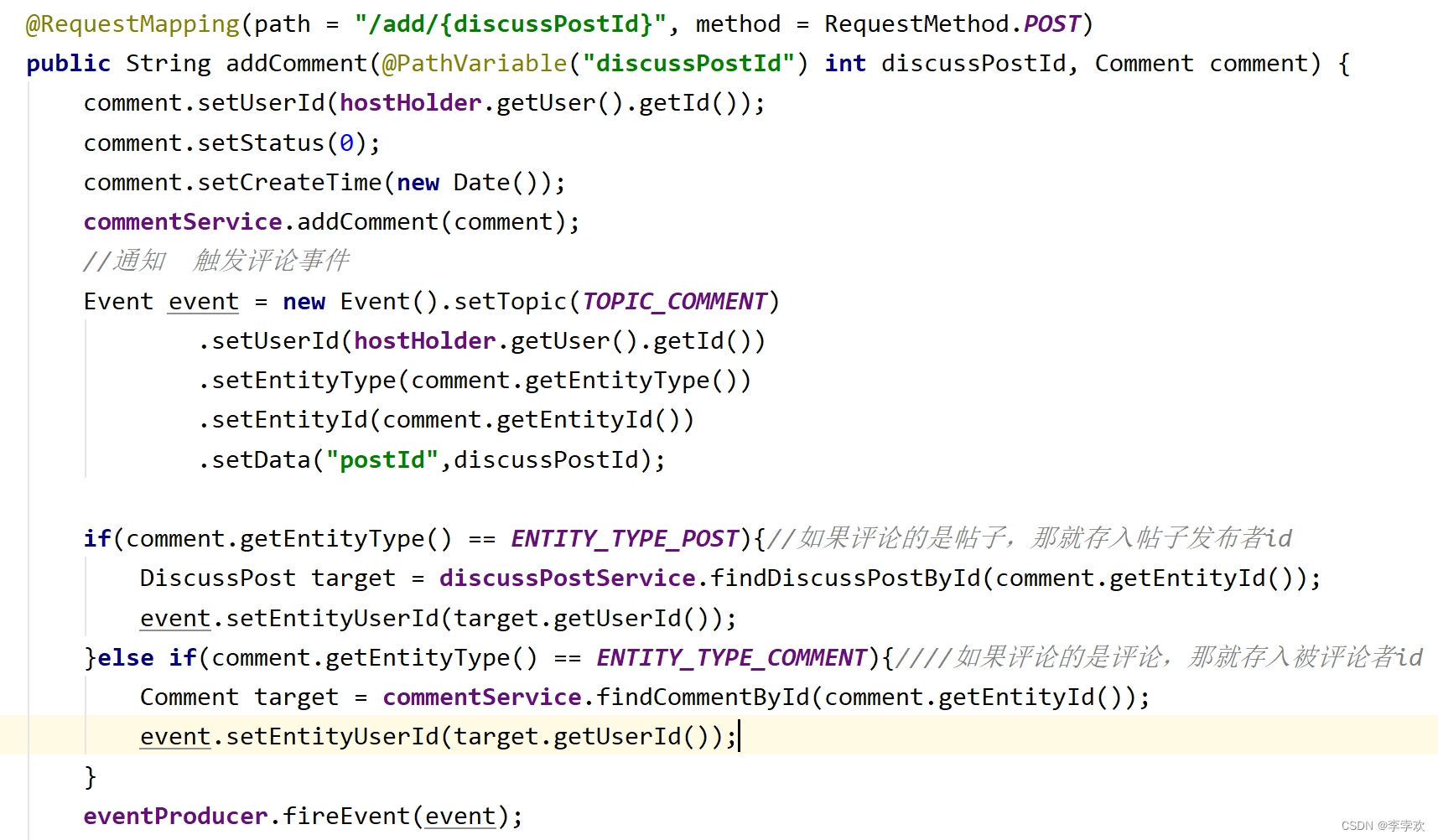
producer : Trigger Event, Encapsulates the Topic as well as userId、Entity Etc , call sendMsg when , Extract event.Topic and JSONObject.toJSONString(Event) With content Send as , Call ; ( Active trigger , Adding comments 、 Triggered when you follow and like )
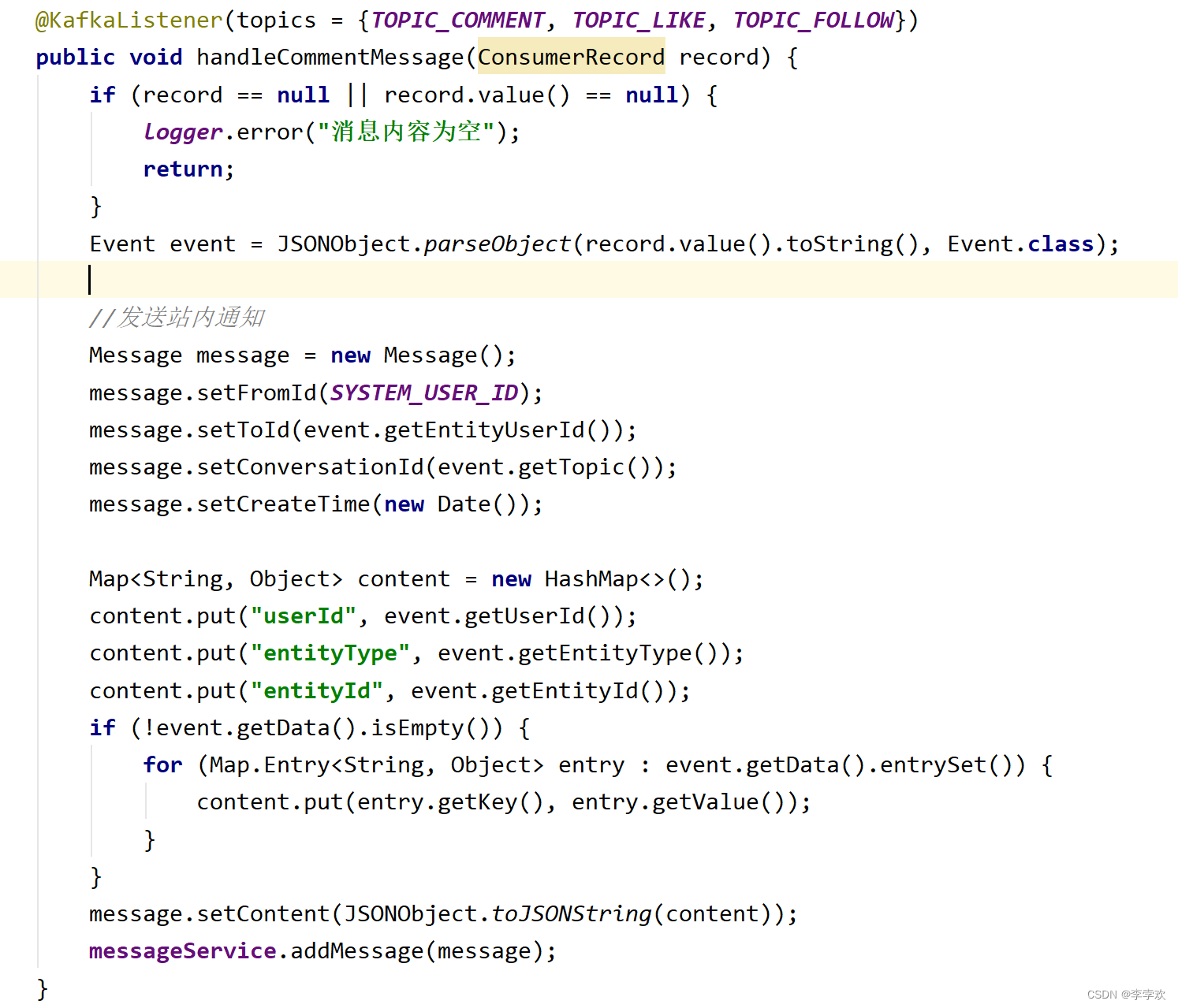
consumer : monitor Topic, If there's new news , Just read ,record What we get from it is event Inside json strand , And then return to event that will do JSONObject.paresObject(record.value().toString,Event.class); Then put the relevant attributes , Encapsulated into message The form of private messages , Save to the database , Supply the front-end page to call and display .( The consumption here is to store data from the message queue into the database , Passive trigger ,kafka Listening topic , Automatically consume when there is news )
14 Do message queues go to memory or disk ? Why is the disk so fast ?
Kafka The messages are stored or cached on disk , Generally speaking, reading and writing data on disk will degrade performance , Because addressing takes time , But actually ,Kafka One of the features of is high throughput .
Analyze from two aspects of data writing and reading , Why? Kafka So fast
Write data : How fast the disk reads and writes depends on how you use it , That is, sequential reading and writing or random reading and writing . In the case of sequential reading and writing , The sequential read and write speed of the disk is the same as that of the memory . Because the hard disk is a mechanical structure , Every read and write will address -> write in , Where addressing is a “ Mechanical action ”, It's the most time consuming . So hard drives hate random I/O, Favorite order I/O. In order to improve the speed of reading and writing hard disk ,Kafka It's the order of use I/O.
Even writing to the hard disk in sequence , Hard disk access speed is still impossible to catch up with memory . therefore Kafka The data is not written to the hard disk in real time , It makes full use of paging storage of modern operating system to improve memory I/O efficiency .
Reading data : Zero copy
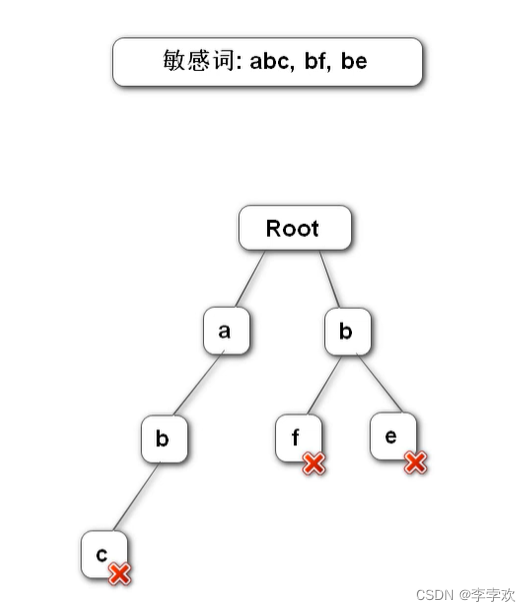
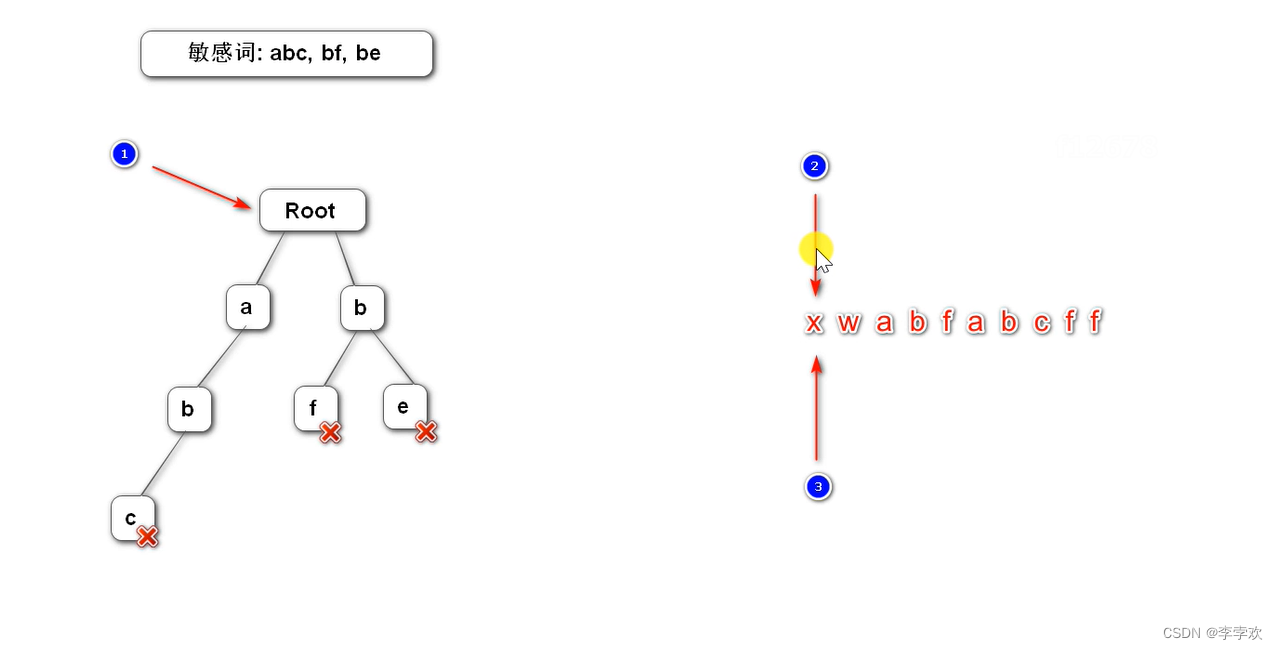
15 TrieTree Prefix tree introduction
Prefix tree It is a tree data structure of multi tree , It is used to filter sensitive words in the project .
Construct a prefix tree : The first layer stores the first character of all sensitive words
Prefix tree features :1. The root node does not contain any information Each node except the root node contains only one character ,2. The path from the root node to a node , The string connected by the character is the string corresponding to this node 3. All child nodes of each node contain different characters
Here's the picture :

Filter sensitive words algorithm :
Three pointers , One points to the root (node), The other two pointers (begin and position), All point to the beginning of the text , One of them keeps moving backwards (begin), The other follows , Discovery is not a sensitive word , It means that begin The first character cannot form a sensitive word , Deposit it in StringBuilder,begin Move backward , Then go back to begin. If it's a sensitive word , The replacement , And the other two pointers move back , The tree pointer points to the root node .
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return null;
}
// The pointer 1
TrieNode tempNode = rootNode;
// The pointer 2
int begin = 0;
// The pointer 3
int position = 0;
// result
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// Skip symbols
if (isSymbol(c)) {
// If pointer 1 At the root node , Count this symbol into the result , Let the pointer 2 Take a step down
if (tempNode == rootNode) {
sb.append(c);
begin++;
}
// Whether the symbol is at the beginning or in the middle , The pointer 3 Take a step down
position++;
continue;
}
// Check the child nodes
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// With begin The first string is not a sensitive word
sb.append(text.charAt(begin));
// Go to the next position
position = ++begin;
// Point back to the root node
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// Find sensitive words , take begin~position Replace the string with
sb.append(REPLACEMENT);
// Go to the next position
begin = ++position;
// Point back to the root node
tempNode = rootNode;
} else {
// Check the next character
position++;
}
}
// Count the last batch of characters into the result
sb.append(text.substring(begin));
return sb.toString();
}
边栏推荐
猜你喜欢

9.指针(上)

Summary of multiple choice questions in the 2022 database of tyut Taiyuan University of Technology
3.输入和输出函数(printf、scanf、getchar和putchar)
Pit avoidance Guide: Thirteen characteristics of garbage NFT project
hashCode()与equals()之间的关系
The latest tank battle 2022 - Notes on the whole development -2
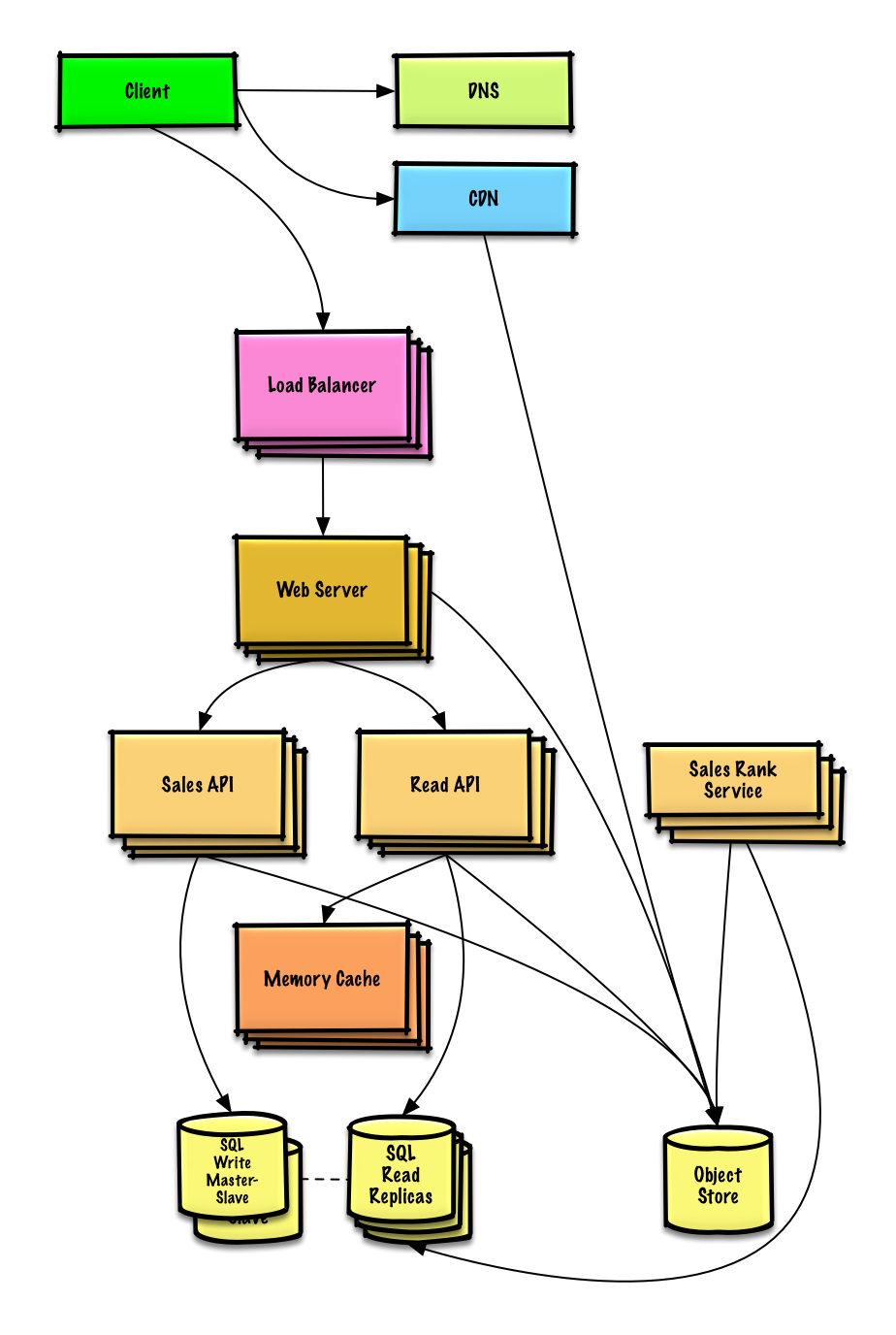
System design learning (III) design Amazon's sales rank by category feature

arduino+水位传感器+led显示+蜂鸣器报警
arduino+DS18B20温度传感器(蜂鸣器报警)+LCD1602显示(IIC驱动)

2.初识C语言(2)
随机推荐
Aurora system model of learning database
6. Function recursion
[中国近代史] 第九章测验
Database operation of tyut Taiyuan University of technology 2022 database
MySQL中count(*)的实现方式
3.猜数字游戏
用栈实现队列
(ultra detailed onenet TCP protocol access) arduino+esp8266-01s access to the Internet of things platform, upload real-time data collection /tcp transparent transmission (and how to obtain and write L
MySQL limit x, -1 doesn't work, -1 does not work, and an error is reported
2.C语言矩阵乘法
Atomic and nonatomic
受检异常和非受检异常的区别和理解
抽象类和接口的区别
System design learning (III) design Amazon's sales rank by category feature
仿牛客技术博客项目常见问题及解答(一)
The latest tank battle 2022 - Notes on the whole development -2
甲、乙机之间采用方式 1 双向串行通信,具体要求如下: (1)甲机的 k1 按键可通过串行口控制乙机的 LEDI 点亮、LED2 灭,甲机的 k2 按键控制 乙机的 LED1
(super detailed II) detailed visualization of onenet data, how to plot with intercepted data flow
C language Getting Started Guide
[the Nine Yang Manual] 2018 Fudan University Applied Statistics real problem + analysis