( One ) Mission ( Homework ) Dispatch
Task scheduling related 3 A concept :job、stage、task.
- Job: According to what is used spark Logical tasks . With action Method as the boundary , Meet a action Method , Then trigger a job.
- Stage:stage yes job Subset . With wide dependence (shuffle) As a boundary . Met a shuffle, Make a division .
- Task:task yes stage Subset . In parallel degree ( Partition number ) To distinguish . How many partitions , Just how many task.
Spark Task scheduling . On the whole, it is divided into two ways .Stage Level scheduling and task Level of scheduling . The description is as follows .
1. Dispatch
Driver initialization sparkContext In the process of , Will the initialization DAG Scheduler、Task Scheduler、Scheduler BackEnd,HeatBeatReceiver. And start the SchedulerBackEnd and heatBeatReceiver.
SchedulerBackEnd Responsible for passing AM towards RM Application resources , And constantly from Task Scheduler take Task. Distribute to executor perform .
heatBeatReceiver Responsible for receiving Executor The heart of . monitor executor And inform Task Scheduler.
(1) Spark adopt transformation Methods form RDD The blood relationship of . That is to build DAG(stage Directed acyclic graph of ).
(2) from DAG Scheduler Responsible for scheduling DAG Medium stage. Each one stage Pack it up task Set aggregate . hand Task Scheduler be responsible for Task The scheduling .
(3) Task Scheduler take DAG Scheduler Handed over Task set According to the scheduling strategy , Distributed to the stay driver Registered executor On the implementation .
2. Stage Level scheduling
DAG Call method stack
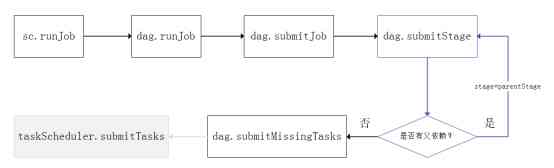
(1) establish DAG:SparkContext take Job hand DAG Scheduler perform .DAG Scheduler take Job Cut into stage. formation stage Directed acyclic graph of DAG.
Cut according to : Wide dependence . Final RDD Judge the father by backtracking RDD Is there a shuffle. Narrowly dependent RDD Go to the same one stage in , Based on wide dependence , Split into two different stage.
Stage Classification and distinction : Divided into two .Result Stage and shuffle Stage .
Shuffle Stage The completion flag is that the calculation result is written to disk .
Result Stage The completion of means a job Completion .
(2) perform DAG:DAG Scheduler Submit according to the submission policy stage. Will need to be submitted stage Pack it up task set . call Task Scheduler perform Task Set.
Stage Submit strategy : One stage Submit or not , Judge father stage Whether to carry out . Only the father stage Only after the execution of the current stage. If one stage No father stage, From the present stage Start execution .
3. task Level scheduling
Task Scheduling method stack of
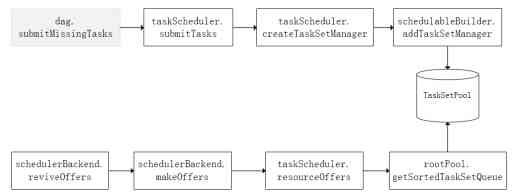
Scheduler Back End function : be responsible for Task Specific implementation of . He manages executor Resources for .Task When it comes to execution , Need to call scheduler Back End , Access to resources . And distribute tasks to execute .
Task Scheduling strategy :
- FIFO: fifo . Default scheduling policy .
- FIAR:( Fair scheduling strategy )
(1) encapsulation Task Manger:Task Scheduler take DAG Scheduler Delivered Task Set Encapsulated into Task Manger. Join the scheduling queue .
(2) Dispatch Task Manger:Task Manger call schedulerBackEnd, Get active executor , Distribute the task to executor To perform .
( Two )SHUFFLE analysis
(1) Shuffle Key points
- Shuffle The number of tasks
Shuffle It is divided into map Phase and reduce Stage . Or call it shuffle read Phase and shuffle write Stage . from spark UI You can see clearly on the .
- Map The number of partitions on the end is the number of partitions in the original file . namely split The number of .
(2) Hash shuffle
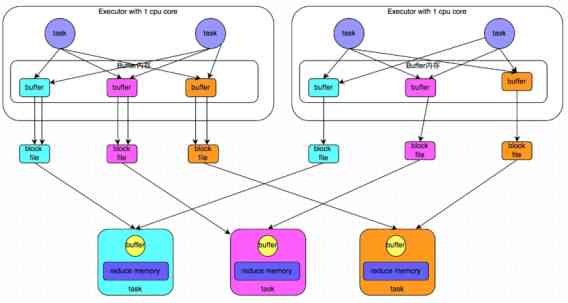
A. Unoptimized hash Shuffle
Suppose once shuffle There are stages M individual Map and N individual reduce form . This example is 4 individual nap and 3 individual reduce. Shuffle read Stage . Every map Will produce N File .Shuffle It will produce M*N File .
Shuffle write Stage .N individual reduce Will go to every map Function to get their own corresponding file . Load into memory reduce.
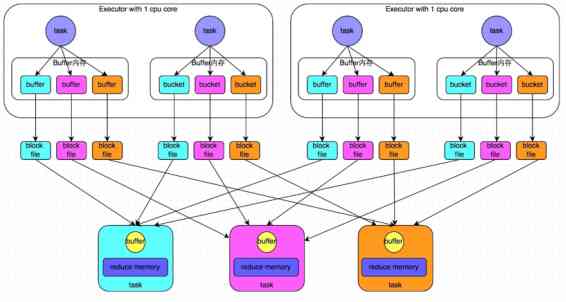
B. The optimized hash Shuffle
Suppose once shuffle There are stages M individual Map and N individual reduce form . This example is 4 individual nap and 3 individual reduce. The current assumption is that every executor It's a single core . The same executor Allocate two map Of task.
The optimized hash shuffle The principle is : No matter one executor How many map function . Not every map produce N File . It's the same core A batch of map Of task Generate N File . therefore . One executor The number of files generated is .( Single executor Of core Count )*N . It's also the current implementation map Of executor Of core Count *N.
Compare : There is the original M*N The change has become core*N. generally .Core It's a certain amount , Not too big . comparison M It's bigger .
The optimized hash shuffle Schematic diagram is as follows .
(3) Sort shuffle
current shuffle Of Manager The default is sort shuffle.shuffle read task Less than or equal to spark.shuffle.sort. bypassMergeThreshold The value of the parameter ( The default is 200), It will activate bypass Mechanism .
A. Common mechanisms
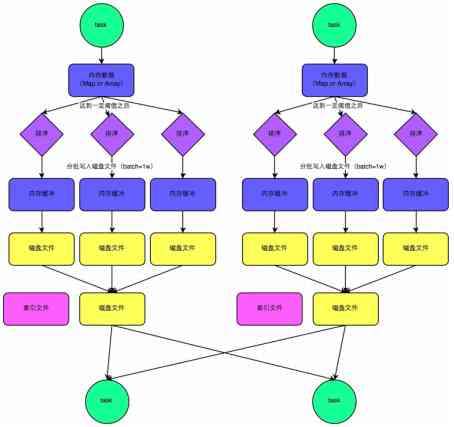
The front part of the common mechanism and the non optimized hash shuffle type . Put the cache first . When writing over , according to key Assign to different reduce In the corresponding cache . Sort before entering the cache . When the respective cache is full, the corresponding disk file is overflowed M*N An intermediate file .
When it's finished , Every map Corresponding N Files for merge. because N individual reduce You need to access the current file . So we need an index file , Point out that reduce The location of the data in the current file 【start offset 、end offset】
B. ByPass Mechanism
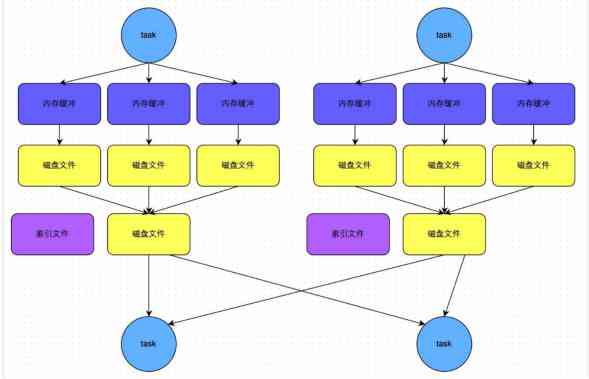
ByPass Pattern and common sort shuffle The difference is :map After processing , Directly generate N Cache , Overflow when threshold is reached N A disk . Missing a common cache in the middle . There is also a lack of sort Sort .