当前位置:网站首页>7-10x write performance improvement: analysis of wiredtiger data page lock free and compression black Technology
7-10x write performance improvement: analysis of wiredtiger data page lock free and compression black Technology
2020-11-09 12:53:00 【osc_xu7n68ts】
7-10 Multiple write performance improvement : analyse WiredTiger Data page locking and compression black Technology
Introduction : Computer hardware is developing rapidly , The data scale is expanding rapidly , But the database still uses the architecture of ten years ago ,WiredTiger Try to break all this , Make full use of the multi-core and large memory era to redesign the database engine , achieve 7 - 10 Multiple write performance improvement . This paper is written by yuan Rongxi to 「 High availability Architecture 」 contribute , Through analysis WiredTiger Source code , Analyze the realization behind its excellent performance .
 Yuan Rongxi , Learn from Bajun Engineer ,2015 He joined xuebajun in 1987 , Responsible for the architecture design and implementation of xuebajun's network real-time transmission and distributed system , Focus on basic technology , Over the Internet 、 Database kernel 、 Knowledge of distributed systems and concurrent programming .
Yuan Rongxi , Learn from Bajun Engineer ,2015 He joined xuebajun in 1987 , Responsible for the architecture design and implementation of xuebajun's network real-time transmission and distributed system , Focus on basic technology , Over the Internet 、 Database kernel 、 Knowledge of distributed systems and concurrent programming .
stay MongoDB New storage engine WiredTiger Realization ( Affairs ) The article mentions WiredTiger( Referred to as WT) It's to adapt to the modern CPU、 Memory and disk characteristics designed for the storage engine , Its characteristic is to make full use of CPU Speed and memory capacity to make up for the lack of disk access speed .
Introducing WiredTiger Before the data organization of , Let's take a look at the data organization of traditional database engines , The general storage engine uses btree perhaps lsm tree To implement the index , But the smallest unit of an index is not K/V Record object , It's a data page , The realization of data page organization relationship is the way of data organization of storage engine .
Most of the traditional database engine is to design a disk and memory exactly the same way of data organization , This structure is a fixed size of space (innodb Of page yes 16KB), Access to it must be strictly The FIX Rules The rules :
- To modify a page Need to get the page's x-latch lock
- Visit one page Need to get the page's s-latch lock perhaps x-latch lock.
- Hold the page Of latch Until the operation of modifying or accessing the page is completed latch unlock.
WiredTiger There is no memory and disk design like the traditional database engine page Exactly the same way data is organized , It's about disks and CPU、 The characteristics of memory design a unique way of data organization .
This data organization structure is divided into two parts :
- in-memory page: Data pages in memory (page)
- disk extent: Range storage based on offset of disk file
WiredTiger In memory page It's a loose and free data structure , And on disk extent It's just a variable length block of serialized data , The purpose of this ( Design objectives ) There are the following points :
1. In memory page Loose structure can not be limited by disk storage and The FIX Rules The impact of the rules , It's free to build page Lock free multi-core concurrent structure , Give full play to CPU Multinuclear capability .
2. Can be free in memory page And disk extent Between the implementation of data compression , Improve disk storage efficiency and reduce I/O Access time .
About WiredTiger The compression efficiency of is shown in the figure below 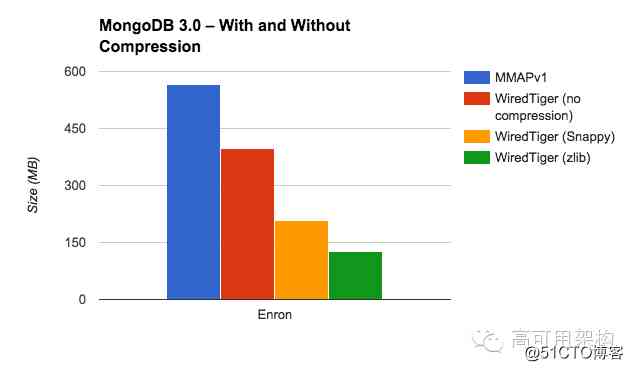
chart 1
Page stay WiredTiger The engine plays a connecting role , On the index 、 Business and LRU cache, Release the document 、 Cache and disk I/O. To understand the whole WiredTiger How the engine works , The first thing to understand is how it is organized .
In this paper, first through a set of test samples to verify WiredTiger The design goal of data organization , reanalysis WiredTiger The principle and implementation of data organization .
WiredTiger The test sample
First look at it. WiredTiger This kind of data organization related test , We're on a normal development machine WiredTiger The native API Interface test , The test environment is as follows :
CPU: i7-4710MQ CPU @ 2.50GHz,8 nucleus
Memory :4G
Hard disk :1TB SATA,5400 turn
WT Database configuration :
Cache size: 1GB, page max size:64KB, OS page cache:1GB
Key: An integer that grows from zero
Value: A length between 100 ~ 200 Random string of .
Testing process
The test program first creates a new table , use 16 Threads insert a specified number of threads into the table simultaneously ( In millions ) Of K/V Yes , Do it once after insertion checkpoint Let the inserted data be written to the disk , Count the size of the table on disk and the time taken for the process . Reuse 16 Threads randomly query in the table 20000 Different K/V And statistics of query time , From the time it takes to calculate insert and query Of TPS. The statistics of these three parameters are disk space usage 、 Write performance and read performance .
We do not compress separately extent To test and conduct ZIP Compress extent Test of .
Comparison of disk space statistics
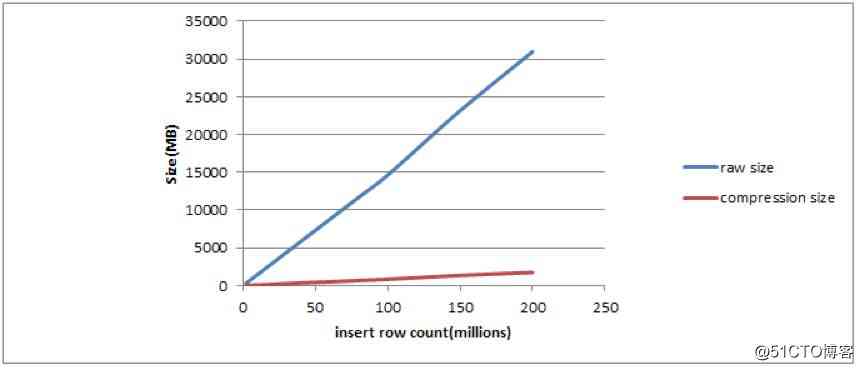
chart 2
As can be seen from the above figure 2 One hundred million records , No compressed disk space 30GB, And the compressed disk space 2GB about .
Write performance comparison
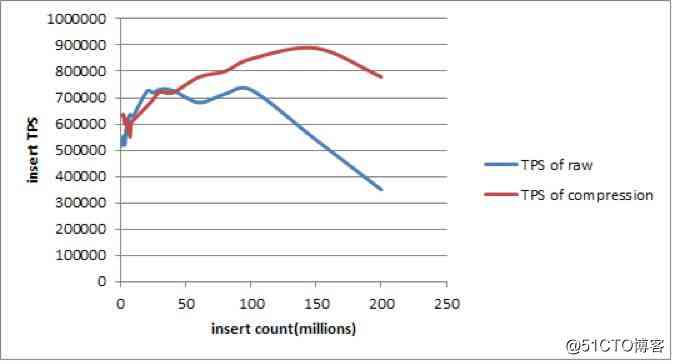
chart 3
As can be seen from the above figure , The data written is in 1 Billion bars (14GB), Compress (518K TPS) And no compression (631k TPS) The writing performance of is equivalent to .
But as the amount of data increases , A lot of data is between memory and disk swap, choice extent Compression write performance (790K TPS) Better than uncompressed write performance (351K TPS).
Read performance comparison

chart 4
From the figure above , The data size on the table space file does not exceed WiredTiger Of OS_page_cache When the limit , Read performance without compression is better than that with compression , This is because extent Buffering is in the operating system cache , Get uncompressed directly from the cache when access occurs extent In memory page, It takes only one reconstruction of the structure in memory ; And compressed extent Need to decompress and rebuild , So read performance without compression is better .
If the file data size exceeds OS_page_cache After restriction ,extent Data is to be read from disk , And there's compression extent It takes up less space , Read from disk I/O The access time is less than the uncompressed read time , The read performance with compression is better than that without compression ( I will use a separate space to analyze WT Of disks I/O Related implementation ).
Besides compression, it optimizes the reading and writing of data ,WiredTiger No lock in memory page Structure also makes read and write operations have better concurrency , So that WiredTiger It works so well on very ordinary machines .
Data pages in memory
Through the introduction above, we have already made some comments on WiredTiger Basic understanding of data organization ,WiredTiger The way data is organized is in-memory page Add block-extent. Let's start with the memory part of it in-memory page( Memory data page , Referred to as page) To do the analysis .
WiredTiger In the engine page It can be divided into the following categories :
- row internal page: Row store b-tree The index page of
- row leaf page: Row store b-tree The data page of
- column internal page: Column store b-tree The index page of
- column fix leaf page: Column store b-tree Fixed length data page of
- column var leaf page: Column store b-tree Variable length data page of
because MongoDB Mainly using row storage , So the main analysis here is row leaf page This structure and principle , Structure diagram is as follows :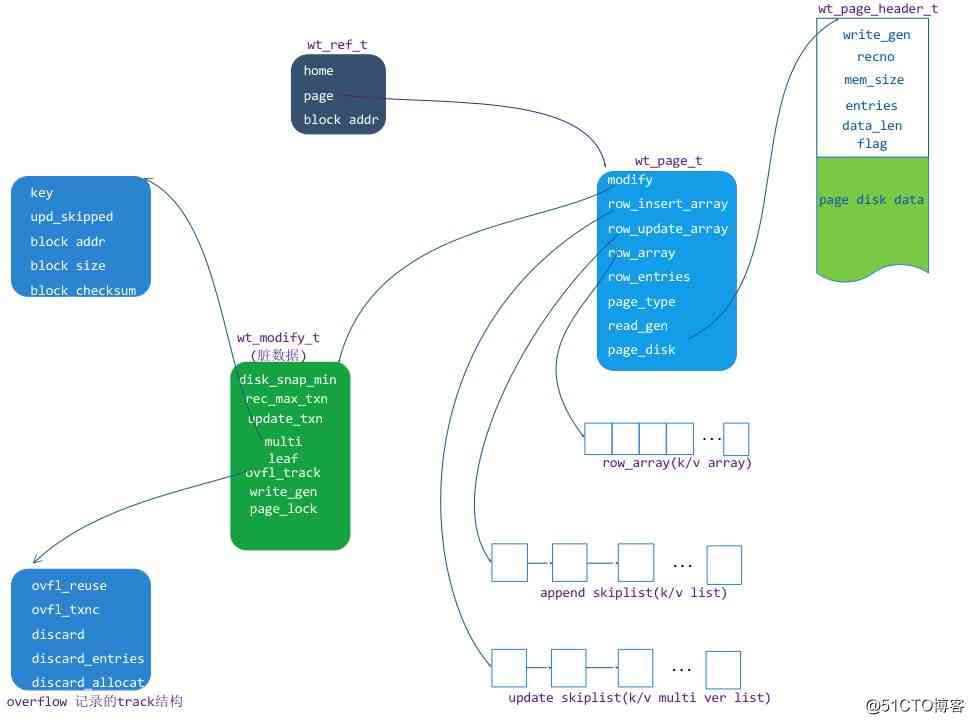
chart 5 Click on the image to zoom full screen
There are mainly the following units in the figure above :
- wt_page: In memory page The structure of the object ,page Access to .
- wt_modify:page Modification status information for , It mainly includes dirty page labels 、 Current update transaction ID and page Of insert lock etc. .
- row_array: Original on disk row Position index array of , It is mainly used for in page retrieval .
- row_insert_array: An increase kv(insert k/v) Jump table object array of
- row_update_array: In a row Update on the basis of (update k/v) Of value mvcc list For pixel groups .
- page_disk: Read from disk extent Data buffer , Contains a page_header And a data storage buffer (disk data)
- page disk data: Stored on disk page k/v cell Row set data
It lists so many structures , How do they relate to each other ?
Let's illustrate with an example , If one page Stored a [0,100] Of key Range , The line originally stored on the disk key=2, 10 ,20, 30 , 50, 80, 90, Their values are value = 102, 110, 120, 130, 150, 180, 190.
stay page After data is read from disk to memory , Respectively for key=20 Of value Two changes have been made , The two modified values are respectively 402,502. Yes key = 20 ,50 Of value Made a change , The modified value = 122, 155, There is distribution after insert New key = 3,5, 41, 99,value = 203,205,241,299.
So in memory page This is how the data is organized as shown in the figure below :
chart 6 Click on the image to zoom full screen
row_array The length of is based on page The number of rows read from the disk is determined , Each array unit (wt_row) It's stored in this kv row stay page_disk_data The location and encoding of the buffer offset ( This location and encoding is in WT It is defined as a wt_cell object , In the rear K/V cell Chapter to analyze ), Through this information, offset location information can be accessed in disk_data In buffer K/V Content value .
every last wt_row The object is row_update_array The array corresponds to a mvcc list object ,mvcc_list And wt_row It's one-to-one ,mvcc list It's stored to wt_row Modified value , The modified values include value update and value deletion , It's a one-way list without locks .
The next two wt_row It may not be continuous , New units can be inserted between them , for example row1(key = 2) and row2(key=10) You can insert 3 and 5, these two items. row There needs to be a sorted data structure between (WT use skiplist data structure ) To store the inserted K/V, You just need one skiplist An array of objects page_insert_array And row array Corresponding . Here's the thing to note chart 6 In the middle of the red box skiplist8, It's for storage row1(key=2) Before the scope insert data , chart 6 If any key =1 The data of insert, This data will be added to skiplist8 among .
that chart 6 in row And insert skiplist The corresponding relationship between :
- row1 The previous range corresponds to insert yes skiplist8
- row1 and row2 Between the corresponding insert yes skiplist1
- row2 and row3 Between the corresponding insert yes skiplist3
- …
- row7 The range after that corresponds to insert yes skiplist7
wt_row structure
From the top page According to the overall analysis of WT Of page in ,row The object is the whole row leaf page The key structure of ,row In fact, that is K/V The description value of the position (kv_pos), Its definition :
wt_row{
uint64 kv_pos;// This value is in page Read into memory according to KV Stored in page_disk The location of the
}
This kv_pos The corresponding data of has corresponding K/V Store location information ,kv_pos Express this K/V There are three ways , The structure is as follows: :
chart 7 Click on the image to zoom full screen
In the picture above wt_row The corresponding space has 2 individual bit Of flag, This flag Value :
- CELL_FLAG: 0x01, Express this row use cell Object to k/v Indicating the storage location , because key and value The value of can be very large , One page Not enough storage , This is the time to introduce cell It's just storing these super long values overflow page The index of the value (extent adress).
- K_FLAG:0x02, Express this row It's just marked k/v in key Storage location , however value The larger ,value yes CELL_FLAG Means to indicate the location of storage , because value Of CELL It's just following key After the storage location , find key You can read value Of cell And find value.
- KV_FLAG:0x03, Express this row At the same time k/v in key and value Storage location .
Cell structure
Cell It's a value key perhaps value A block of data that has been serialized ,cell The contents on disk and in memory are the same , It's based on the value (key perhaps value) Content 、 length 、 Value type serialization builds . In memory cell Is stored in the page_disk Buffer zone , On disk is stored in extent body On , In the reading cell It needs to be based on cell The data content is sent and serialized to get a cell_unpack Memory structure object , Let's follow this later cell_unpack Object to read the value (key perhaps value). Here is the structural relationship between them :
chart 8 Click on the image to zoom full screen
So in row Object CELL_FLAG row、K_FLAG row and KV_FLAG row How is the corresponding value generated ?
In fact page When reading data from disk to memory , First, the whole thing page_disk according to cell To convert a unit into cell_unpack, And according to cell_unpack Information structure in row These three formats of , The purpose of this is to make it possible to generate K_FLAG /KV_FLAG Of row There is no need to do this process transformation every time you are visited , Speed up access .
Changes in memory
In memory row The object is mainly to help page After the data is loaded from the disk into the memory, the query index is established , and page After the data is loaded into memory, in addition to query read , It will also be modified ( Additions and deletions ), For modification behavior WT Not in row Memory structure operation , It's about designing two structures , One is in response to insert Operation of the insert_skiplist, For delete operation mvcc list. About these two object structures and row The relationship between chart 6 It was described in . Here we focus on the analysis of their internal structure and operation principle .
Jump watch (skiplist)
From the previous introduction we know that page Store new in memory k/v When we use skiplist data structure , stay WiredTiger It's not just this place that uses skiplist, In other places that need quick query and addition and deletion, we basically use skiplist, understand skiplist The principle of is helpful to understand WiredTiger The implementation of the .
skiplist It's actually a multilayered list , The higher the hierarchy, the more sparse , At the bottom is a common list . 
chart 9
skiplist See the principle of https://en.wikipedia.org/wiki/Skip_list
skiplist See https://github.com/yuanrongxi/wb-skiplist
Newly added K/V structure
WiredTiger in insert_skiplist The implementation is combined with its own k/v Memory structure to achieve ,WT be based on skiplist Defined a wt_insert Of k/v Skip table cell structure , The definition is as follows :
wt_insert{
key_offset:// Storage key Buffer offset of
key_size://key The length of
value:// Storing values mvcc list The head unit of , One wt_update The structure of the object
next[]://skiplist The next cell pointer for each layer of
key_data[]:// Storage key The buffer
}
insert_skiplist The structure of :
chart 10 Click on the image to zoom full screen
WiredTiger Why choose skiplist As a data structure for new records ? There are several considerations :
- skiplist It's easy to implement , And it can be adapted to local conditions and K/V Make comparison in memory and combine .
- skiplist The complexity is O(log n), You can manage a lot of... In memory k/v The operation of adding, deleting, modifying and checking , and skiplist In memory, follow key Size sorted , You can do range lookup .
- skiplist In addition and deletion operations can not exclude read operations , In other words, a thread is reading skiplist You don't need to check skiplist Of write_lock, It's equivalent to reading without lock , This implementation adds skiplist Read concurrency of .
Modified value
WiredTiger The engine is insert One k/v when ,key Values are stored in wt_insert in , So it's value Where to store it ?
stay wt_insert There is one in the structure wt_update Type of value explain , This structure is actually used to store the modified versions in memory value Value linked list object , That is to say MVCC list Linked list . stay chart 6 Also mentioned in row When it's updated , Will send to row_update_array Corresponding mvcc list The updated value unit is added (wt_update), The definition of this structure is as follows :
wt_update{
txnid:// The transaction that generated the modification ID
next ptr:// Next on the list wt_update Cell pointer
size://value Value length
value[]:// Storage value The buffer
}
size = 0, This is a deletion k/v Modification of .
chart 11(mvcc list)
Under normal circumstances, the whole linked list will only carry out append operation , And every time append They are all at the head of the chain , The purpose of this is to read and write the entire list without lock . It's about lock free reading , As long as there is no lock append You can read without lock .mvcc list unlocked append It's using CPU Of CAS Operate to complete , The general steps are as follows :
- First we will need append Unit of (new_upd) Of next Pointer to list header The corresponding unit (header_upd), And record list_header The pointer .
- To operate with atoms CAS_SWAP take list header Set to new_upd,CAS_SET During setup, if no other thread completes the setup with it first , So this time append It's done . If there are other threads set with it first , Then this setting failed , In the first 3 Step .
- use memory barrier Read list_header The pointer to , Repeat the first 1 Step .
The first 2 Step to determine whether there are other threads with their own settings list_header The basis is CAS_SWAP when list_header The value of is not read by itself . More details about this process can be found GCC Compiler __sync_val_compare_and_swap Function function and implementation .
overflow page
WiredTiger Support is big support K/V,key and value The maximum value of can be up to 4GB( It's not 4G, Probably 4GB - 1KB, Because in addition to the data, it also needs to store page Header information ).
WiredTiger By defining a type called overflow page To store more than leaf page The maximum storage range is very large k/v. Super large k/v stay insert To leaf page Or is it stored in insert_skiplist among , Only when this leaf page When it comes to saving ,WT Will go beyond page The maximum space allowed k/v Value with a separate overflow page To store ,overflow page In the disk file has its own separate extent.
So when will it appear in memory overflow page Well ? In use overflow page Of leaf page When read from disk into memory, the corresponding overflow page Memory objects .overflow page Its structure is very simple , It's just one. page_header And a page_disk buffer .leaf page And overflow page Through between row cell Information to connect ,cell There's this in it overflow page Of extent address Information .
In order to overflow page Fast access to ,WT Defining a skiplist(extent address And overflow page Memory object mapping relationship ) To cache in memory overflow page Memory objects , Yes overflow page The reading process is as follows :
- First cell_unpack Corresponding cell, Get overflow page Of extent addr
- Use extent address stay overflow page cache skiplist lookup overflow page Whether it has been read into memory , Has been read into memory , Return the corresponding overflow page The reader , If you don't get into number one 3 Step .
- according to extent address Information will be transferred from the disk file overflow page The information is read into memory , And build a overflow page Add to skiplist among . Finally, return to the read in overflow page Object to the reader .
Mentioned here extent address Refer to the following extent addresss Structure section .
Page In page search of
WiredTiger Implement loose memory page The structure is to be able to quickly retrieve and modify , It also makes data more freely organized in memory . Whether it's reading or revising , Need to rely on page In page search of , Reading or modifying something k/v According to the corresponding value key stay page Do a search inside to locate k/v The location of , And the core reference axis of the whole page search is through row_array This array does a binary search to locate .
Here it is still with chart 6 To illustrate , Suppose you need to be in chart 6 Search for key=41 Value , Steps are as follows :
1. First, by dichotomy in row_array Positioning to storage key = 41 The object of row4
2. Locate the row4 Match first row key And search for key match , If the match , stay row4 Corresponding mvcc list(upd4) Read accessible values in . If it doesn't match , In its corresponding insert_skiplist Search for
3. use key = 41 Skipping the watch skiplist4 Search for , Locate the value = 241, return .
Because it's all row_array/insert_array/update_array Array one-to-one search , And these arrays will not change when they are modified , So there's no need to lock it ,insert_skiplist and mvcc list They all support lock free reading when modifying ( This has been explained in the analysis of these two structures ), So the whole retrieval process is lock free .
If it is to add, delete or modify (insert/delete/update) operation , It is also to use the retrieval process to find the location of the corresponding modification , Then make corresponding modification . If it is insert, Or get wt_modify Medium page_lock To serialize insert operation , If it's on a value update/delete, It's just mvcc list Lock free, add a modified value ( This process has been analyzed above ).
Disk extent structure
Page The corresponding file structure on disk is called extent. In fact, it is an area on the disk file .
stay WT In the engine , Each index corresponds to a file , According to the document page The size of the write and the space used by the current file determine the location and length of the write , Write location (offset) And the length of the write (size) It was named extent, And will extent Location information for (extent address) Record to an index space .
Extent It consists of three parts , They are
- page header: Record the status information of the current data page
- block header: extent Stored header information , It's mainly about data chucksum And length, etc .
- extent data: Stored data , It's a cell Data set .
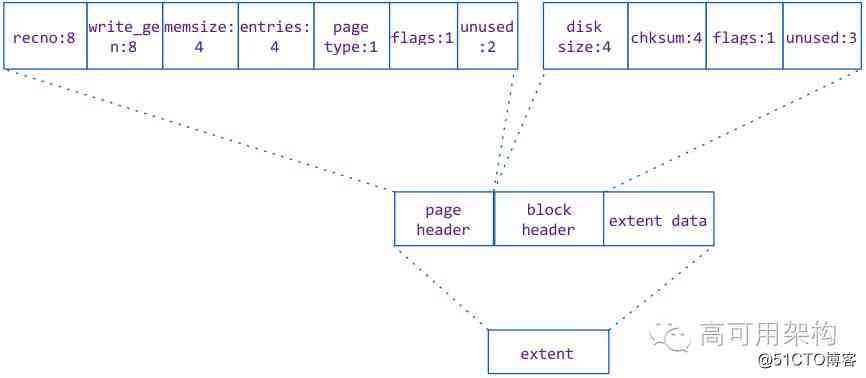
chart 12 Click on the image to zoom full screen
page header stay page In the memory object of , The corresponding is page_disk The header information section of wt_page_header, Their content is exactly the same .page header Contains the current page The number of record instances of (entries)、page type (row leaf page/internal page etc. ), stay page When data is loaded into memory, it needs to be used to build page Memory objects .
Block header Medium checksum yes extent data The data of checksum, It's also extent address Medium checksum. be used for extent Verify the validity when reading into memory .
Extent address
Extent address Used to index extent Information about , It has a special index as a data entry extent in ( About this particular index extent On subsequent disks I/O To analyze in detail ).
Here we mainly analyze its internal structure and definition ,extent address There are three values in :
- offset:extent stay btree The offset position in the file
- size:extent The length of
- chucksum:extent Of checksum, use page header/block header/extent data It's calculated as a whole checksum, Used to judge extent Legitimacy .
These three values are serialized as extent address Items stored in .
Extent data
Extent data It's real storage page Where the data is , It is page All in k/v cell Set .Page When data is saved from memory to disk , Will put each k/v pair use cell_pack The function is transformed into a key cell And a value cell In the serialization buffer . The data in this buffer is written to extent The middle is extent data, The storage structure is as follows :
chart 13
Page Read and write to disk
btree The smallest unit of index management is page, So read operations from disk to memory and write operations from memory to disk are based on page Read and write for units .
stay WT In the engine, the operation of reading a page from disk to memory is called in-memory, From memory page The operation of writing to disk is called reconcile.in-memory The process is to extent Read from a disk file and convert it to memory page , and reconcile Operation is to put the memory of page convert to extent Write to disk ,reconcile The process creates btree page Division .
The read-write sequence diagram is as follows :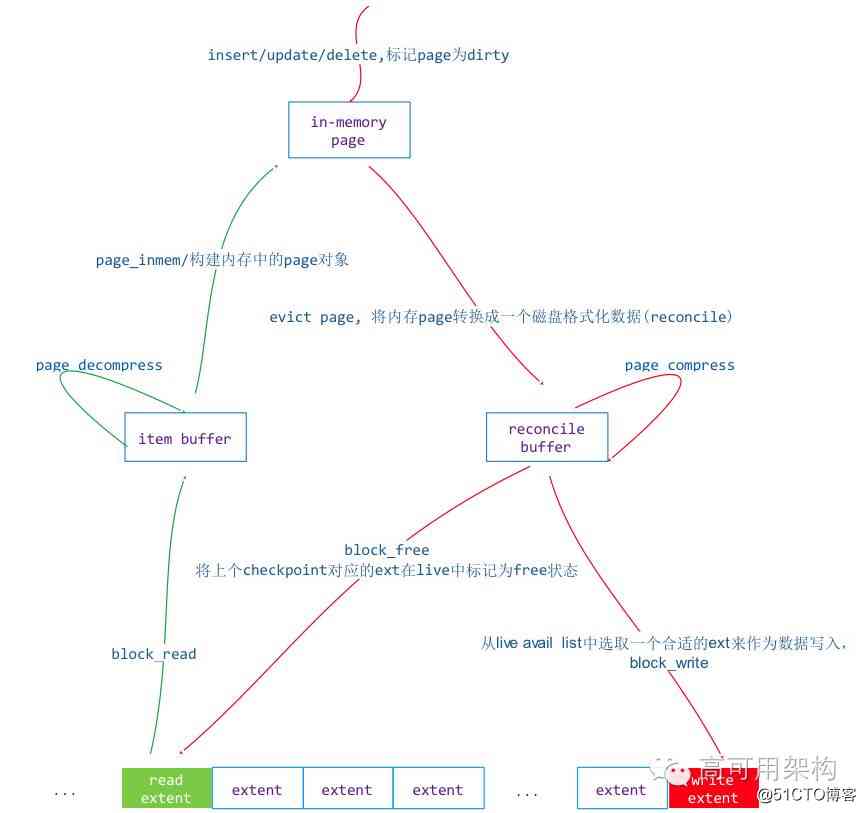
chart 14 Click on the image to zoom full screen
Reading process (in-memory)
Page The read process is the process of disk to memory , Steps are as follows :
- according to btree On the index extent address Information , from btree Read this in the corresponding file extent Into the memory buffer .
- By reading extent The data generated checksum, And with extent address Medium checksum Verify legitimacy .
- according to btree Configured meta Information to determine whether compression is on , If there is no compression, go straight to 5 Step , If there is compression, proceed to section 4 Step .
- According to the configured compression algorithm information WT Supported by compressor object , Also on extent data Do decompression .
- adopt wt_page_header Information builds in memory page object .
- adopt wt_page_header Of entries Count to the whole page_disk_data Traverse , according to cell Build line by line row_array、insert_array and update_array.
If you read in page contain olverflow page,overflow page It doesn't read into memory during this process , It is read into memory when accessing it , This process only reads overflow page Corresponding extent address As row Object content . stay overflow page One section analyzes overflow page The reading process of .
Writing process (reconcile)
The writing process is complicated ,page If page Too much memory for page do split operation , For more than page Big tolerance K/V Will generate overflow page. The whole writing process is as follows :
- according to row_array As axis , Scan the whole row_array/upate_array and insert_array, take k/v In memory value generation cell object , And put it in a buffer (rec buffer) in .
- Determine whether the buffer exceeds the configured value page_max_size, If you exceed , Conduct split operation .
- For single key perhaps value exceed page_max_size, Generate a overflow page, And will overflow page Corresponding extent address Generate cell.
- repeat 1 ~ 3 Step until all the k/v cell All written to rec buffer in .
- If btree The data compression item is configured , stay WT Search for compressed objects in the engine , And use this compressed object to rec buffer Data compression to get data buffer, If compression is not configured, skip this step (data buffe = rec buffer).
- according to page Object wt_page_header Write its corresponding information to data buffer Head position .
according to btree The offset and space state of the file produces a extent, Calculation data buffer Of checksum, And will data buffer Fill in extent data among .
according to extent Fill in the information of block_header, Will the whole externt Write to btree And return extent address.
Page Compress
adopt page Read and write process analysis of the two processes shows that if compression is configured , You need to call the compression and decompression operation .WT Compression and decompression is achieved through an external custom plug-in object , The following is the interface definition of this object
__wt_compressor{
compress_func();// Compression interface function
pre_size_func();// Precomputing compressed data length interface function
decompress_func();// Decompress the interface function
terminate_func();// Destroy compressed objects , It's kind of like a destructor
};
WT Provide LZO/ZIP/snappy These compression algorithms , Also supports custom compression algorithms , Just follow the above object interface implementation . Must let WT Support compression algorithm , Need to be in WT Startup pass wiredtiger_open Load compression algorithm module , Examples are as follows :
wiredtiger_open(db_path, NULL, “extensions=[/usr/local/lib/libwiredtiger_zlib.so]”,&connection);
And then in WT When the engine creates a table, you can configure compression and enable compression configuration , for example :
session->create(session, “mytable”, “block_compressor=zlib”);
WT Plug in compression is very flexible and convenient ,MongoDB The default support ZIP and snappy Compress , stay MongoDB establish collection Can be selected compression algorithm .
Postscript
And optimization suggestions
WiredTiger The engine uses different structures on memory and disk page Data organization of , The goal is to let the memory page The structure is more convenient in CPU The concurrent operation of adding, deleting, checking and modifying in multi-core system , Thin disk extent structure , Make the management of the table space on the disk unaffected by the memory structure . be based on extent( The offset + Data length ) In a way that makes WiredTiger The data file structure of the engine is simpler , Data compression can be easily implemented .
However, this kind of memory and disk structure is inconsistent with the design also has a bad place , Data from disk to memory or from memory to disk requires multiple copies , Additional memory is needed as a temporary buffer for both structures , In the case of insufficient physical memory, it will make swap The problem is even worse , Performance can degrade dramatically , This is reflected in the test sample . So let WiredTiger Good engine performance , Give it more physical memory to use .
MongoDB 3.2 The version has already WiredTiger As the default engine , We are using MongoDB You don't usually be right about WiredTiger Configuration , Some business scenarios may not work out WiredTiger The advantages of .MongoDB Creating collection You can be right about WiredTiger Table configuration , The format is as follows :
db.createCollection("<collectionName>", {storageEngine: {
wiredtiger: {configString:"<option>=<setting>,<option>=<setting>"}}});
Different business scenarios can be configured for different configurations .
If it is a table that reads more and writes less, we can try our best to create a table with page size The settings are relatively small , such as 16KB, If the amount of data in the table is not too large (<2G), You can even leave compression on . that createCollection Of configString You can set it like this :
"internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB,os_cache_max=1GB"
If the table with more reads and less writes has a large amount of data , You can set up a compression algorithm for it , for example :
"block_compressor=zlib, internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB"
If it's writing more and reading less , Can be leaf_page_max Set to 1MB, And turn on the compression algorithm , It can also be developed at the operating system level page cache The size of os_cache_max value , So it doesn't take up too much page cache Memory , To prevent interference with reading operations .
these MongoDB The configuration items of are and WiredTiger Configuration items related to engine data organization , In understanding WiredTiger How the data is organized in detail , It can be adjusted according to specific business scenarios collection Table configuration properties of .
The above is through analysis and testing WiredTiger Source code to get some understanding , Some details can go wrong , But it's basically how it works . Yes WiredTiger Source code interested students stamp here https://github.com/yuanrongxi/wiredtiger, I spent some time on WiredTiger-2.5.3 The source code has been analyzed and annotated .
The follow-up work is to WiredTiger The index of (btree/LSM tree) And disk I/O Related modules do in-depth analysis and testing , I will share the experience of analysis from time to time .
Reference reading

MongoDB New storage engine WiredTiger Realization ( Affairs )
MongoDB 2015 review : New milestone WiredTiger Storage engine
Yes WiredTiger And MongoDB Students interested in engine design and use , Welcome to leave a message in this article , Introduce to WiredTiger/MongoDB The use and understanding of , We will invite those who are interested in the comments, the author of this article and relevant experts in the industry to 『 High availability Architecture —WiredTiger/MongoDB』 Wechat group for communication .
Technical originality and architecture practice article , Welcome to the official account menu 「 Contact us 」 To contribute . Please indicate from highly available Architecture 「ArchNotes」 The official account of WeChat and the following two-dimensional code .
High availability Architecture
Changing the way the Internet is built

Long press QR code Focus on 「 High availability Architecture 」 official account 
版权声明
本文为[osc_xu7n68ts]所创,转载请带上原文链接,感谢
边栏推荐
- Is multithreading really faster than single threading?
- 20201107第16课,使用Apache服务部署静态网站;使用Vsftpd服务传输文件
- Navigation component of Android architecture (2)
- 外贸自建网站域名的选择— Namesilo 域名购买
- Technology and beauty are so expensive, it's better to find consultants | aalab enterprise consulting business
- As a user, you can't get rid of the portrait!
- 10款必装软件,让Windows使用效率飞起!
- Large scale project Objective-C - nsurlsession access SMS verification code application example sharing
- From coding, network transmission, architecture design, Tencent cloud high quality, high availability real-time audio and video technology practice
- Rainbow sorting | Dutch flag problem
猜你喜欢

Android studio import customized framework classess.jar As 4.0.1 version is valid for pro test
inet_ Pton () and INET_ Detailed explanation of ntop() function
Android NDK 开发实战 - 微信公众号二维码检测
从汇编的角度看pdb文件
Visual Studio (MAC) installation process notes

“开源软件供应链点亮计划 - 暑期 2020”公布结果 基于 ChubaoFS 开发的项目获得最佳质量奖
Pay attention to the request forwarding problem of. Net core

Ali, Tencent, Baidu, Netease, meituan Android interview experience sharing, got Baidu, Tencent offer
Viewing PDB files from the angle of assembly

From coding, network transmission, architecture design, Tencent cloud high quality, high availability real-time audio and video technology practice
随机推荐
A simple ability determines whether you will learn!
VisualStudio(Mac)安装过程笔记
外贸自建网站域名的选择— Namesilo 域名购买
彩虹排序 | 荷兰旗问题
多线程真的比单线程快?
Complete set of linked list operations of data structure and algorithm series (3) (go)
解密未来数据库设计:MongoDB新存储引擎WiredTiger实现(事务篇)
A simple way to realize terminal text paste board
Android check box and echo
inet_ Pton () and INET_ Detailed explanation of ntop() function
从汇编的角度看pdb文件
Explain Python input() function: get user input string
FGC online service troubleshooting, this is enough!
Open source ERP recruitment
Suning's practice of large scale alarm convergence and root cause location based on Knowledge Map
通配符SSL证书应该去哪里注册申请
“开源软件供应链点亮计划 - 暑期 2020”公布结果 基于 ChubaoFS 开发的项目获得最佳质量奖
Understanding runloop in OC
导师制Processing网课 双十一优惠进行中
利用 Python 一键下载网易云音乐 10W+ 乐库