当前位置:网站首页>SIGMOD’22 HiEngine论文解读
SIGMOD’22 HiEngine论文解读
2022-07-04 16:32:00 【华为云】
导读
华为云数据库创新Lab在一作论文《HiEngine: How to Architect a Cloud-Native Memory-Optimized Database Engine》中提出了华为自研的、的以内存为中心的云原生内存数据库引擎HiEngine。SIGMOD,即Special Interest Group on Management Of Data数据管理国际会议,会议是是由美国计算机协会(ACM)数据管理专业委员会(SIGMOD组织的、数据库领域的的最顶级国际学术会议。HiEngine是云数据库创新LAB在云原生内存数据库领域取得的关键技术成果之一。
摘要
高性能内存数据库引擎已成为许多系统和应用程序中必不可少的基本构件,然而大多数现有系统是基于本地内存存储设计的,并不能充分发挥云计算环境的优势。现有的云原生数据库系统大多遵循以外存存储为中心的设计。HiEngine的关键特性包括:1)除了采用存算分离架构外,在计算侧利用云基础设施的可靠性内存服务来实现快速持久性和可靠性;2)实现跟主内存数据库引擎同等的性能;3) 以及向后兼容现有的云原生数据库系统。
HiEngine与华为GaussDB(for MySQL)集成,将内存数据库引擎的优势带到云端,并与基于磁盘的引擎共存。HiEngine的性能比传统的以存储为中心的解决方案高出7.5倍。
研究背景
1. Memory-centric计算架构
以内存为中心的计算已经成为学术界和工业界的研究热点。持久性内存提供了DRAM级的性能和Flash闪存级的容量,基于持久性内存的池式内存的研究和应用已经逐渐成为探索的新方向。学术界研究原型系统有HydraDB、RAM Cloud、NAM-DB、Hotpot、DDC及Infiniswap,工业界系统如FaRM、SAP HANA、SRSS SCM、WSCs、及DAOS等。
同时,内存数据库的客户将应用程序迁移到云,供应商提供云原生的内存优化的OLTP解决方案成为一种趋势。
2. OLTP数据库生态

现有的云本地数据库系统大多是磁盘驻留数据库,遵循以存储为中心的设计,如Aurora、PolarDB、GaussDB(for 用于MySQL)等。它们有以下特点:基于页面块的IO、,面向页面的布局和缓冲池。此外
特别地,它们拥有内存中数据库所没有的缓冲池,这直接影响了云平台中如何构建引擎和充分利用内存设备的硬件性能。当前,大多数内存数据库都是基于本地部署解决方案设计的,不能直接在云中工作。尽管部分存算分离的内存数据库(如NAM-DB)可以提供云原生特性,但它们在整个网络上的访问延迟很昂贵大。
.png)
3. 华为云基础设施
华为云存储基础设施服务具有如下特点:
.png)
- 硬件趋势和挑战:1)存算分离架构中引入持久内存,尤其在计算侧配置持久内存能够提供高速的事务日志缓存等功能,但是这与计算节点的Stateless特性相违背。2)基于ARM的多核处理器具有更好的性价比和理想的能耗,但是也带来Cross-NUMA的多核扩展挑战。
- SRSS:作为华为云新一代分布式存储服务,它使用RDMA建立在现代SSD/NVM硬件之上,采用日志结构型的追加存储。
- SRSS在云中提供了必要的持久性内存原语。SRSS支持内存语义和计算端持久存储,定制化的mmapMMAP内核驱动程序API支持从本地或远程持久存储层一致性的读取数据,SRSS通过内存映射提供除了打开、/关闭、/追加、/读取等接口外,还提供内存语义操作。数据在计算侧和存储侧三副本存储,采用具有低延迟存储网络。这允许计算节点可以在计算侧本地持久化和存储侧远端持久化,似的存储层之间关键路径上没有往返网络开销。
HiEngine架构
本文提出了一种云原生的内存优化的内存数据库引擎HiEngine来解决这些挑战。HiEngine在架构上呈现的特征包括:
1)将持久化状态引入到计算层,以支持快速持久化和低延迟事务。
2)日志即数据。
3)在计算层SRSS利用持久内存(如Intel Optane内存)在三个计算节点中同步存储副本日志,同时异步持久化到远端存储。
4)HiEngine系统有表现为三层物理结构和三层逻辑结构,其中逻辑的日志层与计算层位于同一物理位置。
.png)
1. 以日志为中心的Log-centric MVCC存储引擎概览
.png)
HiEngine是围绕“日志就是数据库”的理念构建的,并使用了一些关键技术如无锁索引、MVCC事务模型、tuple-level元组级的内存布局。它使用SRSS实现数据持久化和快速恢复。HiEngine通过rRowmap实现数据访问,rowmap它是HiEngine的核心数据结构,支持MVCC、高效的检查点和并行恢复。
2. Tuple-level内存布局
HiEngine使用MVCC事务模型,这充分挖掘了SRSS的性能和功能特性。在内存布局层面,它采用lock-free的ARTree索引、使用Row Map来映射rowid行ID到具体的数据版本version数据。
.png)
Tuple-level内存布局特性包括:
1)一个版本包含许多关键字段,如[tmin, tmax, nextver, loffset…]字段;
2)Index的叶节点是一个rowid行ID;
3)二级索引的键由用户自定义键和当前行IDrowid组成;
4)对版本链采用基于Epoch的空间管理机制和基于Session管控的Non-blocking的垃圾回收策略。
3. 事务模型
目前HiEngine提供快照隔离级别。当事务开始时,它被分配一个读CSN和一个全局唯一的TID,并在提交时将tminTMIN和TMAXtmax字段中的TID替换为CSN。HiEngine提出了两种时间戳授权方法。逻辑时钟的时间戳分配时延为40微秒,而全局时钟在无原子时钟下时延为20微秒。
.png)
在分布式数据库中,Global Clock是高性能时间戳授时和性能高扩展的最佳选择。
4. PIA/RowMap
HiEngine以日志的形式组织数据记录,没有“页面”的概念。PIA将版本行记录ID映射到记录地址。
.png)
PIA有以下好处:
- 行更新操作不会改变索引的内部结构
- 二级索引的“键”=“用户自定义键+ RID”
- 检查点变得轻量级,因为只需要持久化PIA而不是真实数据
- 恢复只会重新构建PIA,而不是读取元组版本
5. 高可靠高扩展的Redo-Only Logging
HiEngine中,WAL有两个目的:持久化保证和、数据副本实现。WAL被同步持久化到计算侧近端SRSS SCM池 pool中,然后异步的分发到存储端的SRSS PLOG。
SRSS通过PLOG提供了一个仅追加的抽象和段结构。HiEngine在计算端使用分布式日志记录,一旦事务的日志记录持久化到计算端持久化内存中,事务就会被提交。日志被批处理并异步刷新到存储层。
.png)
PLOGPLog在物理结构上,按段组织,然后映射到Plog。每个线程维护一个打开的PLOGPLog,段按需动态分配和释放。每个段由PLOG Plog ID和PLOGPlog中的偏移量来标识。
HiEngine采用分布式logging,它采用::
- 追加写和基于mmapMMAP的读
- 更新后的版本包含一条记录的完整内容
- 使用SRSS的追加接口将日志记录写入段/ PLOGPlog
- 数据成功三副本持久化到计算侧持久性内存后提交事务
6. Dataless的检查点和并行恢复
为了加速恢复,HiEngine在后台运行检查点。检查点变得非常轻量化,只需要持久化PIA。
恢复分为加载阶段和重放阶段: 1)一旦PIA设置完成,恢复就完成了;2)之后的访问将根据需要通过mmapMMAP将数据版本带入主存。我们还设计了一个并行恢复算法:
1). 多个重放线程依次扫描日志(每个线程一个)
2). 如果日志记录操作是插入或更新操作,则将相应的PIA条目更新为日志中偏移
3). 只有当PIA条目指向旧的记录版本时,重放线程才会用新的记录地址覆盖PIA条目
同时,HiEngine定期地执行日志合并来做日志垃圾回收。合并线程获取当前最低读LSN的快照,该快照存储在本地作为truncLSN,用于部分合并。完全合并需要删除表的所有版本和记录,以便将数据聚集到新的存储空间中修复loffset。异步当完成日志合并后,HiEngine将异步修复PIA中的loffset。

7. 索引持久化和检查点
在HiEngine中,索引树的修改不会立即持久化 。索引树的检查点类似于日志结构合并树。不过存在读放大。幸的是,读放大是存在的。

索引有以下特点包括:1)1个内存中的主R/W树+持久存储的R/O森林;2)基于AR-Tree的lock-free索引树;3)通过mmapMMAP读取持久存储的索引;4)森林中的树可以是不同种类 (意味着你可以有不同种类的树(例如比如B+ -tTree);5)索引合并:将多棵树合并为一棵。
部署方式
.png)
HiEngine提出了两种部署模式:
1. 垂直整合:HiEngine与GaussDB中已有的InnoDB引擎共存(针对MySQL),在CREATE TABLE语句中使用WITH ENGINE=HiEngine参数,查询(已编译或解释)将被路由到相应的存储引擎执行。
2. 横向整合。放在数据库表前面作为一个透明的ACID缓存,部分或全部作为表前ACID缓存。
本文专注于垂直整合的部署方式,HiEngine与华为GaussDB(for MySQL)集成为单个引擎。本文主要研究垂直集成模式。HiEngine与GaussDB中已有的InnoDB引擎共存(针对MySQL)。用户只需要在CREATE TABLE语句中声明引擎类型查询将被路由到相应的存储引擎。
系统评测
本文专注于垂直整合的部署方式,HiEngine与华为GaussDB(for MySQL)集成为单个引擎。
这两个引擎共享相同的SQL层,其中除了HiEngine使用代码生成技术。我们使用Sysbench和标准TPC-C基准来比较HiEngine和其他三种工业系统。所有的评价都是在两种环境下进行的,单服务器和云SRSS。
.png)
HiEngine在两个平台上的表现都明显优于DBMS-M。 HiEngine单服务器性能高达6500万tpmC。
.png)
.png)
编译执行下的端到端性能为> 50%。我们通过设置内存分配策略和工作负载分区来评估面向armARM的优化。在所有情况下,HiEngine存储引擎的性能都比DBMS-M高出60%。通过对ARM平台上的TPC-C模型的分析,跨Socket的远程访问每增加10%,性能下降5%。优化后的RTO性能提高了10倍。
.png)
总结
本文提出了HiEngine,这是一个云原生内存优化的内存数据库引擎。它利用现代云基础设施与计算端快速持久性内存,并将主内存数据库引擎的优点带到云端,并与基于磁盘的引擎共存。此外,它提供的性能可与本地内存数据库引擎相媲美。
1. 现代云基础设施一直在快速发展,尤其在现代硬件技术的发展中不断升级。新硬件包括多核处理器特别是基于ARM的平台、大容量主内存和持久性SCM、及RDMA网络等。
2. 现有的云原生数据库引擎大多是以存储为中心的设计,这让新硬件的潜力在云原生内存数据库里在很大程度上得不到开发,同时云给内存数据库引擎带来了一些独特的挑战。
3. HiEngine提出了一个云原生的内存优化的数据库引擎,它的特性包括:1)将存算分离的高性能内存数据库在云上呈现给用户;2)采用华为的高可靠共享云存储服务,支持以日志为中心的存储和计算侧高性能持久性内存;3)优化基于ARM的多核处理器;4)保持以内存为中心的引擎与以存储为中心的引擎之间的向后兼容性、可以部署为单个引擎或另一个引擎前面的ACID缓存;5)与之前的系统相比,提供高达7倍的性能。
4. HiEngine弥合了学术原型系统和云上生产系统之间的鸿沟。
5. HiEngine是华为云下一代云原生分布式内存数据库的关键引擎。
边栏推荐
- With the stock price plummeting and the market value shrinking, Naixue launched a virtual stock, which was deeply in dispute
- celebrate! Kelan sundb and Zhongchuang software complete the compatibility adaptation of seven products
- Blue bridge: sympodial plant
- 超标量处理器设计 姚永斌 第5章 指令集体系 摘录
- I2C子系统之适配器的设备接口分析(i2c-dev.c文件分析)
- 大规模服务异常日志检索
- The money circle boss, who is richer than Li Ka Shing, has just bought a building in Saudi Arabia
- Just today, four experts from HSBC gathered to discuss the problems of bank core system transformation, migration and reconstruction
- 大厂面试总结大全二
- LD_LIBRARY_PATH 环境变量设置
猜你喜欢
I always thought that excel and PPT could only be used for making statements until I saw this set of templates (attached)

The block:usdd has strong growth momentum
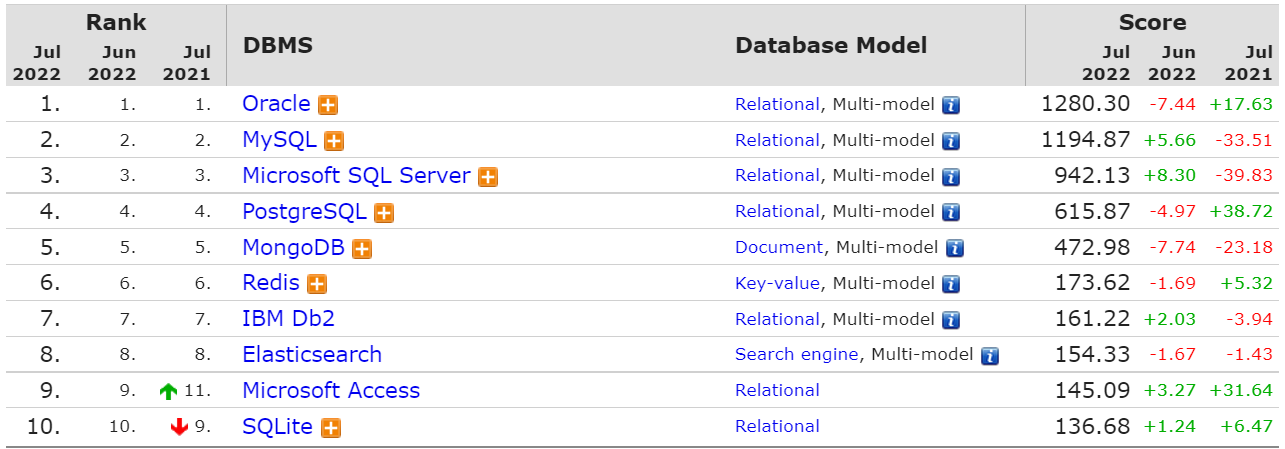
DB-Engines 2022年7月数据库排行榜:Microsoft SQL Server 大涨,Oracle 大跌
![[test development] software testing - Basics](/img/43/514016f270574fe711e0e15b581022.png)
[test development] software testing - Basics

2022年全国CMMI认证补贴政策|昌旭咨询

“在越南,钱就像躺在街上”

股价大跌、市值缩水,奈雪推出虚拟股票,深陷擦边球争议
Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing

Weima, which is going to be listed, still can't give Baidu confidence
![[HCIA continuous update] overview of WLAN workflow](/img/0a/b3986307589a9f7379fe1dd707b9f8.png)
[HCIA continuous update] overview of WLAN workflow
随机推荐
Pytorch深度学习之环境搭建
90后开始攒钱植发,又一个IPO来了
Five thousand words to clarify team self-organization construction | Liga wonderful talk
android使用SQLiteOpenHelper闪退
如何进行MDM的产品测试
I always thought that excel and PPT could only be used for making statements until I saw this set of templates (attached)
Oppo Xiaobu launched Obert, a large pre training model, and promoted to the top of kgclue
The top half and bottom half of the interrupt are introduced and the implementation method (tasklet and work queue)
Talk about seven ways to realize asynchronous programming
DB engines database ranking in July 2022: Microsoft SQL Server rose sharply, Oracle fell sharply
Interview summary of large factory Daquan II
Unity makes revolving door, sliding door, cabinet door drawer, click the effect of automatic door opening and closing, and automatically play the sound effect (with editor extension code)
Flask 轻量web框架
使用3DMAX制作一枚手雷
简单易用的地图可视化
【系统盘转回U盘】记录系统盘转回U盘的操作
The money circle boss, who is richer than Li Ka Shing, has just bought a building in Saudi Arabia
DB-Engines 2022年7月数据库排行榜:Microsoft SQL Server 大涨,Oracle 大跌
Once the "king of color TV", he sold pork before delisting
Stars open stores, return, return, return