当前位置:网站首页>Redis introduction complete tutorial: replication principle
Redis introduction complete tutorial: replication principle
2022-07-07 02:49:00 【Gu Ge academic】
6.3.1 The copying process
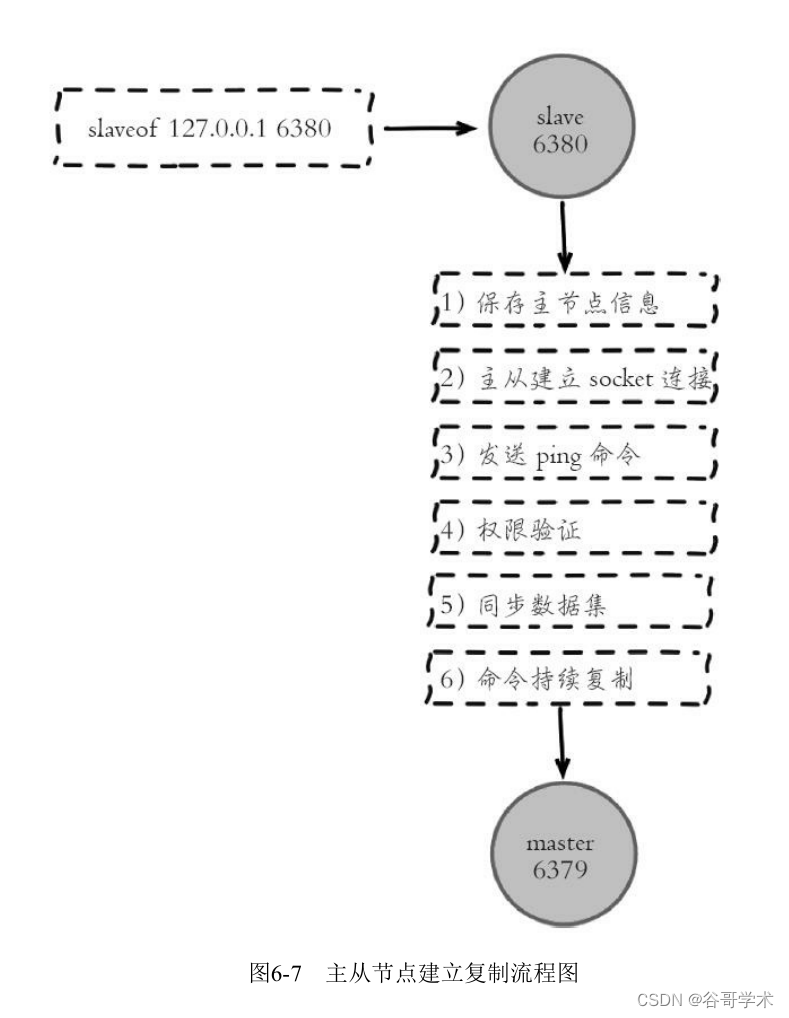
Execute from node slaveof After the command , The replication process starts , The following describes the establishment of
The whole process of copying , Pictured 6-7 Shown .
It can be seen from the figure that the replication process is roughly divided into 6 A process :
1) Save master (master) Information .
perform slaveof After that, the slave node only saves the address information of the master node and returns directly , At this time, the complex is established
The manufacturing process has not started yet , At the slave node 6380 perform info replication You can see the following information :
master_host:127.0.0.1
master_port:6379
master_link_status:down
It can be seen from the statistics that , The master node ip and port To be preserved , But the connection of the master node
Grounding state (master_link_status) It's offline . perform slaveof after Redis The following date will be printed
Records :
SLAVE OF 127.0.0.1:6379 enabled (user request from 'id=65 addr=127.0.0.1:58090
fd=5 name= age=11 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=
32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')
This log can help the operation and maintenance personnel locate and send messages slaveof The client of the command , Easy to track
And find problems .
2) From the node (slave) Internal maintenance of replication related logic through scheduled tasks running per second ,
When the scheduled task finds that there is a new master node , Will attempt to establish a network connection with this node , Pictured 6-
8 Shown .
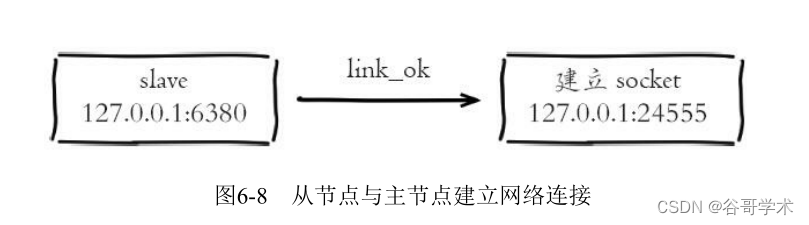
The slave node will create a socket Socket , For example, figure 6-8 A port is established in the slave node
24555 Socket , Dedicated to receiving replication commands sent by the primary node . After the slave node is successfully connected
Print the following log :
* Connecting to MASTER 127.0.0.1:6379
* MASTER <-> SLAVE sync started
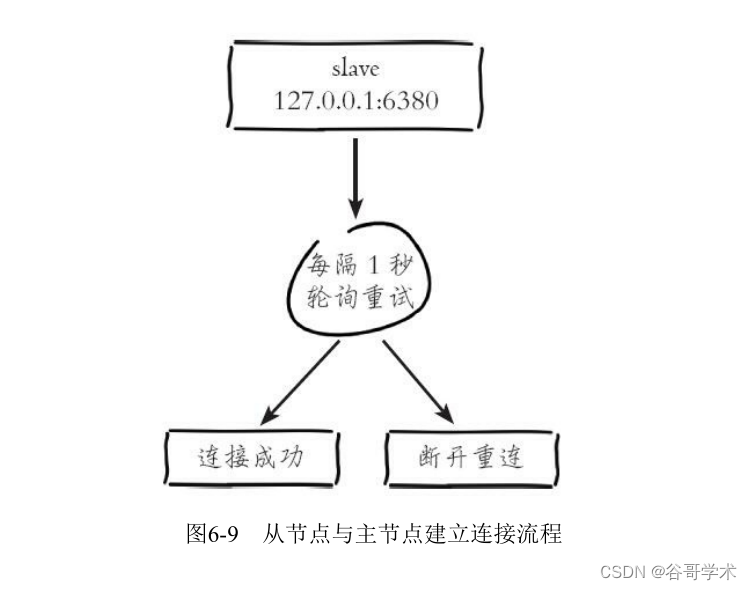
If the slave cannot establish a connection , Scheduled tasks will be retried indefinitely until the connection is successful or executed
slaveof no one Cancel copy , Pictured 6-9 Shown .
About connection failure , Can be executed from node info replication see
master_link_down_since_seconds indicators , It records when the system fails to connect to the master node
between . When the slave node fails to connect to the master node, the following logs will also be printed every second , It is convenient for the operation and maintenance personnel to find and ask
topic :
# Error condition on socket for SYNC: {socket_error_reason}
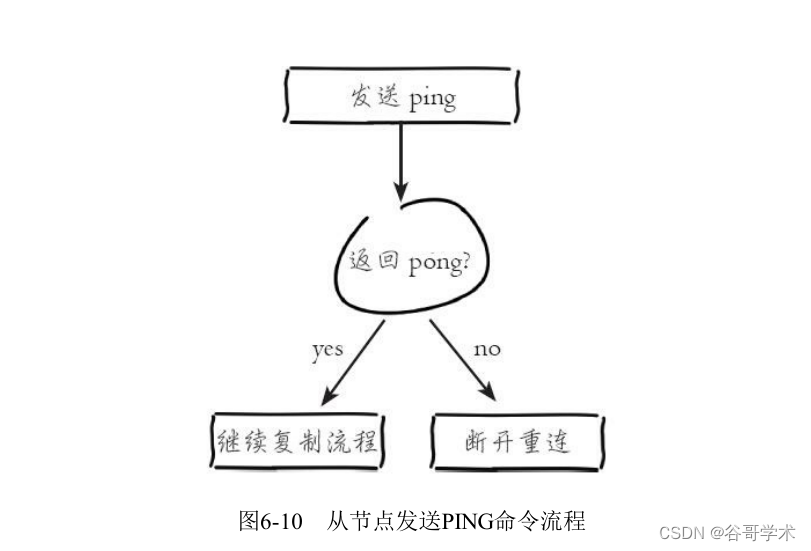
3) send out ping command .
Send from node after successful connection establishment ping Request for first communication ,ping The main purpose of the request
as follows :
· Check whether the network socket between master and slave is available .
· Check whether the master node currently accepts processing commands .
If sent ping After the command , The slave node does not receive the master node's pong Reply or timeout , Than
For example, the network times out or the master node is blocking and cannot respond to commands , Disconnect replication from node , Next
The next scheduled task will initiate reconnection , Pictured 6-10 Shown .
Sent from node ping Command returned successfully ,Redis Print the following log , And continue the subsequent replication
technological process :
Master replied to PING, replication can continue...
4) Authority verification . If the master node is set requirepass Parameters , Password authentication is required ,
Slave node must be configured masterauth The parameters ensure that the same password as the master node can pass the verification ; Such as
If the verification fails, the replication will be terminated , Reinitiate replication process from node .
5) Synchronize datasets . After the master-slave replication connection is in normal communication , For the first replication farm
view , The master node will send all the data held to the slave node , This part of the operation is the longest step
Abrupt .Redis stay 2.8 A new copy command will be used after version psync Data synchronization , The original sync life
I still support , Ensure compatibility between old and new versions . The synchronization of the new version is divided into two cases : Full synchronization and
Partial synchronization , The next section will focus on .
6) Command continuous replication . When the master node synchronizes the current data to the slave node , And it's done
The establishment process of replication . Next, the master node continuously sends the write command to the slave node , Make sure that the master and the slave
Data consistency .
6.3.2 Data synchronization
Redis stay 2.8 And above psync Command to complete master-slave data synchronization , The synchronization process is divided into
by : Full and partial replication .
· Copy in full : Generally used in the first replication scenario ,Redis In the early days, only full replication was supported
Quantity replication , It will send all the data of the master node to the slave node at one time , When the amount of data is large , Meeting
It causes great overhead to the master-slave node and network .
· Partial reproduction : Used to deal with data loss caused by network flash in master-slave replication
scene , When the slave node is connected to the master node again , If conditions permit , The master node will reissue the lost data
Give the slave node . Because the data reissued is far less than the total data , It can effectively avoid full replication
High cost .
Partial replication is a major optimization of the old version , It effectively avoids unnecessary full copy operations
do . Therefore, when using the copy function , Use as far as possible 2.8 Previous versions of Redis.
psync The following components are required to run the command :
· The master and slave nodes copy the offsets respectively .
· The primary node copies the backlog buffer .
· Master node operation id.
1. Copy offset
Master and slave nodes participating in replication maintain their own replication offset . Master node (master) I'm here
After processing the write command , The byte length of the command will be recorded as an accumulation , The statistics are in info
relication Medium master_repl_offset In the index :
127.0.0.1:6379> info replication
# Replication
role:master
...
master_repl_offset:1055130
From the node (slave) Report its own copy offset to the master every second , So the master node
The copy offset from the node is also saved , The statistical indicators are as follows :
127.0.0.1:6379> info replication
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=1055214,lag=1
...
The slave node receives the command sent by the master node , It also accumulates the offset of the record itself . system
The meter information is in info relication Medium slave_repl_offset In the index :
127.0.0.1:6380> info replication
# Replication
role:slave
...
slave_repl_offset:1055214
The maintenance of copy offset is shown in the figure 6-11 Shown .
By comparing the copy offset of the master and slave nodes , You can judge whether the master and slave node data are consistent .
Operation and maintenance tips
You can use the statistics of the master node , To calculate the master_repl_offset-slave_offset byte
The amount , Judge the amount of data copied by the master and slave nodes , Based on this difference, the health of the current replication is determined
degree . If the master-slave copy offset differs greatly , It may be caused by network delay or command blocking
Caused by .
2. Copy backlog buffer
The replication backlog buffer is a fixed length queue stored on the primary node , The default size is
1MB, When the master node has connected slave nodes (slave) Is created when , At this time, the master node (master)
In response to a write command , Not only will the command be sent to the slave node , It also writes to the replication backlog buffer , Such as
chart 6-12 Shown .
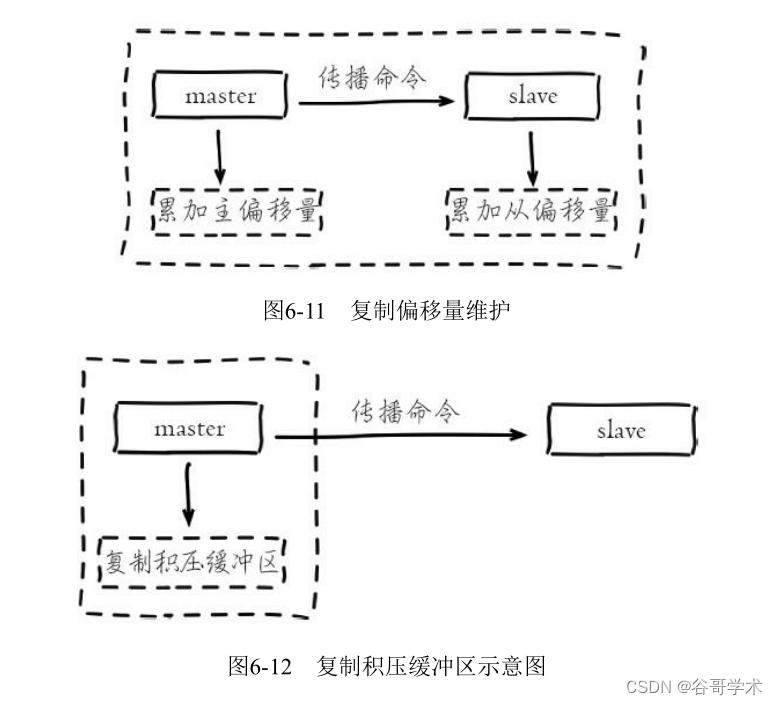
Because the buffer is essentially a first in first out fixed length queue , So it can save the recently copied
The function of data , For partial replication and data recovery of lost replication commands . Copy buffer Correlation
The calculation information is saved in the info replication in :
127.0.0.1:6379> info replication
# Replication
role:master
...
repl_backlog_active:1 // Turn on the copy buffer
repl_backlog_size:1048576 // Maximum buffer length
repl_backlog_first_byte_offset:7479 // Starting offset , Calculate the current buffer free range
repl_backlog_histlen:1048576 // The effective length of the saved data . According to statistical indicators , The available offset range in the copy backlog buffer can be calculated :
[repl_backlog_first_byte_offset,
repl_backlog_first_byte_offset+repl_backlog_histlen]. More details about the copy buffer
see 6.3.4 section “ Partial reproduction ”.
3. Master node operation ID
Every Redis After the node is started, it will dynamically allocate a 40 The hexadecimal string of bits is used as the carrier
That's ok ID. function ID Its main function is to uniquely identify Redis node , For example, save the main section from the node
Point of operation ID Identify which master node you are replicating . If only ip+port The way to know
Don't the master node , Then the master node restarts and changes the overall data set ( Replace RDB/AOF file ),
It is not safe to copy data from the node based on the offset , So when running ID After the change, the slave node will
Make a full copy . Can run info server Command to view the operation of the current node ID:
127.0.0.1:6379> info server
# Server
redis_version:3.0.7
...
run_id:545f7c76183d0798a327591395b030000ee6def9
It should be noted that Redis After shutdown and restart , function ID Will change with it , For example, execute the following
command :
# redis-cli -p 6379 info server | grep run_id
run_id:545f7c76183d0798a327591395b030000ee6def9
# redis-cli -p shutdown
# redis-server redis-6379.conf
# redis-cli -p 6379 info server | grep run_id
run_id:2b2ec5f49f752f35c2b2da4d05775b5b3aaa57ca How to run without changing ID Restart in case of ?
When you need to tune some memory related configurations , for example :hash-max-ziplist-value etc. , These go with
We need to Redis Reload to optimize existing data , You can use debug reload life
Make reload RDB And keep it running ID unchanged , So as to effectively avoid unnecessary full replication . command
as follows :
# redis-cli -p 6379 info server | grep run_id
run_id:2b2ec5f49f752f35c2b2da4d05775b5b3aaa57ca
# redis-cli debug reload
OK
# redis-cli -p 6379 info server | grep run_id
run_id:2b2ec5f49f752f35c2b2da4d05775b5b3aaa57ca
Operation and maintenance tips
debug reload The command will block the current Redis Node main thread , Local messages are generated during blocking
RDB Snapshot and empty the data before loading RDB file . Therefore, for a large amount of primary nodes and non primary nodes
Application scenarios where blocking is tolerated , Use caution .
4.psync command
Use from node psync The command completes the functions of partial replication and full replication , Command format :
psync{runId}{offset}, The meaning of parameters is as follows :
·runId: The operation of the primary node copied from the node id.
·offset: Current data offset copied from node .
psync The command operation process is shown in the figure 6-13 Shown .
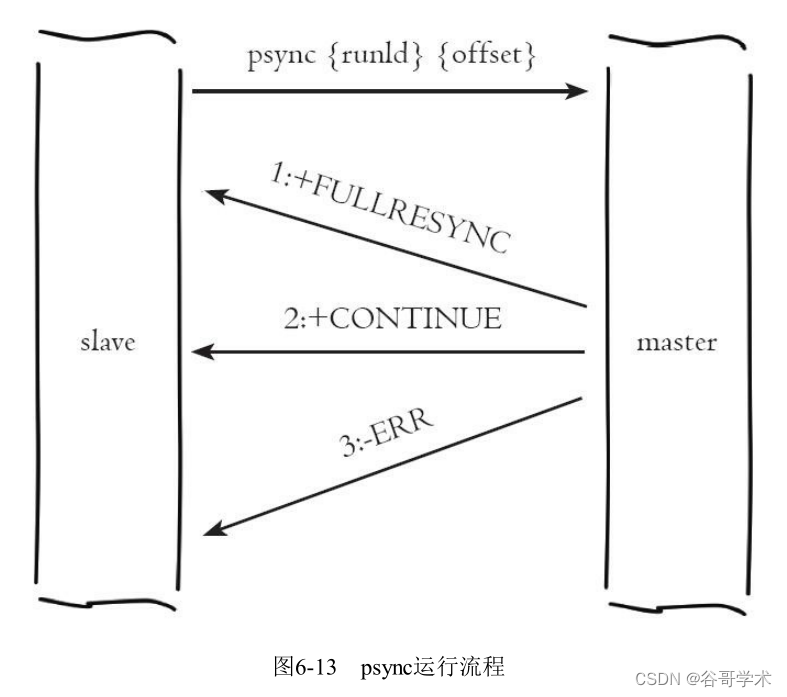
Process description :
1) From the node (slave) send out psync Command to master , Parameters runId Is the current slave node
The stored master node runs ID, If not, the default is , Parameters offset Is currently saved from the node
Copy offset , If it is the first time to participate in replication, the default value is -1.
2) Master node (master) according to psync Parameters and their own data determine the response result :
· If reply +FULLRESYNC{runId}{offset}, Then the slave node will trigger full replication
technological process .
· If reply +CONTINUE, The slave node will trigger a partial replication process .
· If reply +ERR, Indicates that the master node version is lower than Redis2.8, Can't recognize psync command ,
The slave node will send the old version of sync The command triggers the full copy process .
6.3.3 Copy in full
Full volume replication is Redis The earliest supported replication method , It is also necessary for the master and slave to establish replication for the first time
Stages to go through . The command to trigger full replication is sync and psync, Their corresponding versions are shown in the figure 6-
14 Shown .

Here we mainly introduce psync Full replication process , It is associated with 2.8 Former sync Full replication mechanism
This is consistent with . The complete operation process of full replication is shown in the figure 6-15 Shown .
Process description :
1) send out psync Command to synchronize data , Because it's the first time to replicate , There is no from node
Copy the offset and the operation of the master node ID, So send psync-1.
2) The master node is based on psync-1 It is resolved that the current copy is full , reply +FULLRESYNC ring
Should be .
3) Receive the response data of the master node from the node to save and run ID And offset offset, Execute until
In the previous step, print the following log from the node :
Partial resynchronization not possible (no cached master)
Full resync from master: 92d1cb14ff7ba97816216f7beb839efe036775b2:216789
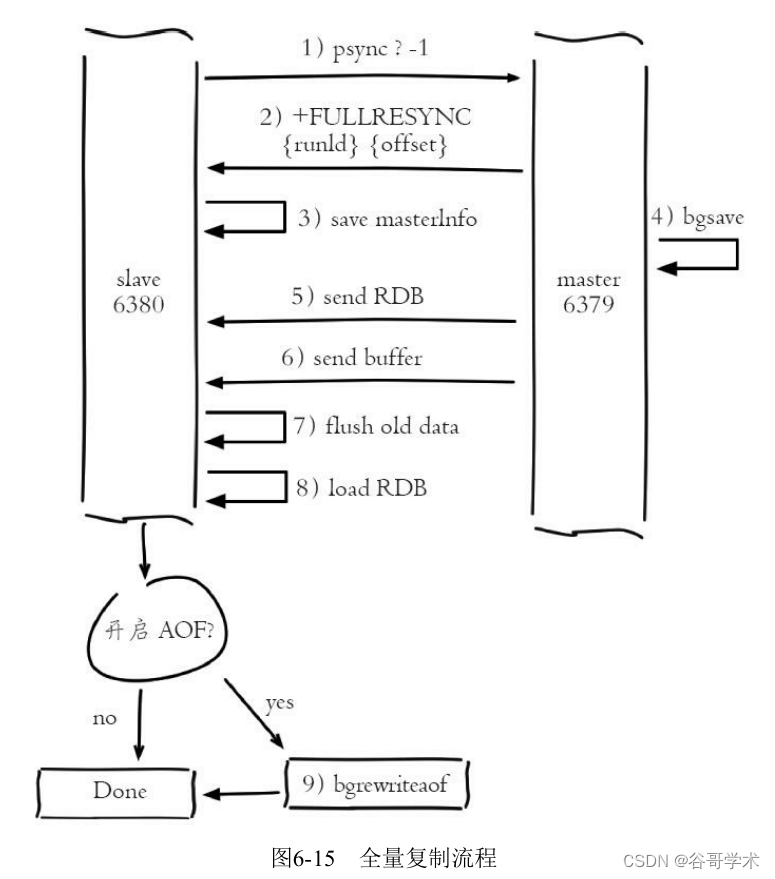
4) Master node execution bgsave preservation RDB File to local ,bgsave See
5.1 section . Master node bgsave The relevant logs are as follows :
M * Full resync requested by slave 127.0.0.1:6380
M * Starting BGSAVE for SYNC with target: disk
C * Background saving started by pid 32618
C * RDB: 0 MB of memory used by copy-on-write
M * Background saving terminated with success
Operation and maintenance tips
Redis3.0 Then there will be at the beginning of the output log M、S、C Equal sign , The corresponding meaning is :
M= The current master node log ,S= It is currently a slave node log ,C= Child process log , We can root
Quickly identify the role information of each log line according to the log ID .
5) The master node sends RDB File to slave , Receive from the node RDB The document is kept in this
And directly as the data file of the slave node , After receiving RDB Then print the related logs from the node , Sure
View the amount of data sent by the master node in the log :
16:24:03.057 * MASTER <-> SLAVE sync: receiving 24777842 bytes from master
We need to pay attention to , For the main node with large amount of data , For example, generated RDB The document exceeds 6GB With
Be extra careful when you go up . The step of transferring files is very time-consuming , The speed depends on the distance between the master and slave nodes
network bandwidth , Through careful analysis Full resync and MASTER<->SLAVE The time of these two lines of logs
Bad , You can work out RDB Total time taken from file creation to transfer completion . If the total time exceeds
repl-timeout Configured value ( Default 60 second ), The slave node will give up accepting RDB File and clean up
Downloaded temporary files , Cause full replication failure , At this time, the following log is printed from the node :
M 27 May 12:10:31.169 # Timeout receiving bulk data from MASTER... If the problem
persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.
For nodes with large amount of data , It is suggested to increase repl-timeout Parameter to prevent full synchronization
According to the timeout . For example, for machines with Gigabit network cards , The theoretical peak bandwidth of the network card is about per second
100MB, Regardless of the bandwidth consumed by other processes ,6GB Of RDB File needs at least 60
Second transmission time , Under default configuration , It is very easy for master-slave data synchronization timeout .
About diskless replication : In order to reduce the disk overhead of the primary node ,Redis Supports diskless replication , Generate
Of RDB The file is not saved to the hard disk, but sent directly to the slave node through the network , adopt repl-
diskless-sync Parameter control , Off by default . Diskless replication is applicable to the disk security of the machine where the primary node is located
It can be used in scenarios with poor but abundant network bandwidth . Note that diskless replication is still in the experimental stage , Line
It needs to be fully tested for use on .
6) For receiving from the node RDB From snapshot to receiving completion , The master node still responds to read
Write orders , Therefore, the master node will save the write command data during this period in the copy client buffer , When
Load from node RDB After the document , The master node then sends the data in the buffer to the slave node , Guarantee
Data consistency between master and slave . If the master node is created and transferred RDB Too long , For high flow
Writing to the scenario is very easy to cause the master node to copy the client buffer overflow . Default configuration is client-
output-buffer-limit slave256MB64MB60, If 60 Buffer consumption continues to be greater than
64MB Or directly surpass 256MB when , The main node will directly close the replication client connection , Cause all
Volume synchronization failed . The corresponding logs are as follows :
M 27 May 12:13:33.669 # Client id=2 addr=127.0.0.1:24555 age=1 idle=1 flags=S
qbuf=0 qbuf-free=0 obl=18824 oll=21382 omem=268442640 events=r cmd=psync
scheduled to be closed ASAP for overcoming of output buffer limits.
therefore , The operation and maintenance personnel need to adjust according to the data volume of the master node and the concurrency of write commands client-
output-buffer-limit slave To configure , Avoid client buffer overflow during full replication .
For the master node , When all the data is sent, it is considered that the full copy is completed , Print success date
Records :Synchronization with slave127.0.0.1:6380succeeded, But for all slave nodes
Volume replication is still not complete , There are still next steps to deal with .
7) After receiving all the data from the master node, the slave node will clear its old data , This step
The step corresponds to the following log :
16:24:02.234 * MASTER <-> SLAVE sync: Flushing old data
8) Start loading after clearing the data from the node RDB file , For the larger RDB file , this
The first step is still time-consuming , Load can be judged by calculating the time difference between logs RDB Total
Time consuming , The corresponding logs are as follows :
16:24:03.578 * MASTER <-> SLAVE sync: Loading DB in memory
16:24:06.756 * MASTER <-> SLAVE sync: Finished with success
For the scenario of online read-write separation , The slave node is also responsible for responding to read commands . If you start from section
The point is in the full replication phase or replication is interrupted , Then the slave node may have received... In response to the read command
Period or wrong data . For this scenario ,Redis Replication provides slave-serve-stale-data ginseng
Count , Default on state . If enabled, the slave node still responds to all commands . For intolerable intolerance
Consistent application scenarios can be set no To turn off command execution , At this point, the slave node is divided into info and slaveof
All commands except commands return only “SYNC with master in progress” Information .
9) Successfully loaded from node RDB after , If the current node is enabled AOF Persistence function ,
It will do it immediately bgrewriteaof operation , In order to ensure that after full replication AOF Persistent files are immediately available
use .AOF See 5.2 section “AOF”.
By analyzing all the processes of full replication , Readers will find that full replication is a very time-consuming and expensive
Operation of force . Its time cost mainly includes :
· Master node bgsave Time .
·RDB File network transfer time .
· Clear data time from node .
· Load from node RDB Time for .
· Possible AOF Rewrite time .
For example, our online data volume is 6G Left and right master nodes , The total cost of initiating full replication from the node
At the time 2 About minutes . So when the amount of data reaches a certain scale , Because the full copy process will
Perform multiple persistence related operations and network data transmission , During this period, a large amount of energy will be consumed where the master and slave nodes are located
Server's CPU、 Memory and network resources . Therefore, except for the first replication, full replication is used in the
Inevitably , For other scenarios, full copy should be avoided . Because of the cost of full replication
problem ,Redis Some replication functions are realized .
6.3.4 Partial reproduction
Part of the replication is mainly Redis An optimization measure for the high cost of full replication ,
Use psync{runId}{offset} Command implementation . When the slave node (slave) Copying master
(master) when , If there is an abnormal situation such as network flash or command loss , The slave node will move to
The master node requests to reissue the lost command data , If the copy backlog buffer of the master node exists
The sub data is sent directly to the slave node , In this way, you can maintain the consistency of the master-slave node replication . Replacement
This part of the data is generally much smaller than the full data , So the cost is very small . The process of partial replication is shown in the figure
6-16 Shown .
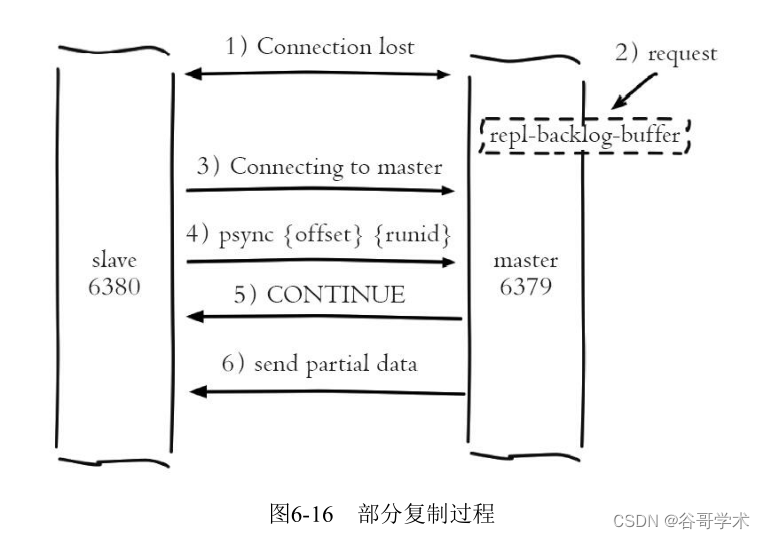
Process description :
1) When the network between the master and slave nodes is interrupted , If exceeded repl-timeout Time , Main section
The point will think that the slave node fails and the replication connection is interrupted , Print the following log :
M # Disconnecting timedout slave: 127.0.0.1:6380
M # Connection with slave 127.0.0.1:6380 lost.
If the slave node is not down at this time , The log of loss of connection with the master node will also be printed :
S # Connection with master lost.
S * Caching the disconnected master state.
2) The master node still responds to the command when the master-slave connection is interrupted , However, due to the interruption of replication connection, the command has no
Method to send to the slave node , However, there is a replication backlog buffer inside the primary node , You can still save the most
Recent write command data , Default Max cache 1MB.
3) When the master-slave network is restored , The slave node will connect to the master node again , Print the following day
Records :
S * Connecting to MASTER 127.0.0.1:6379
S * MASTER <-> SLAVE sync started
S * Non blocking connect for SYNC fired the event.
S * Master replied to PING, replication can continue...
4) When the master-slave connection is restored , Because you saved the copied offset and offset from the node
The operation of the master node ID. So I think of them as psync Parameters are sent to the master node , The Department is required to
Sub copy operation . This behavior corresponds to the slave node log as follows :
S * Trying a partial resynchronization (request 2b2ec5f49f752f35c2b2da4d05775b5
b3aaa57ca:49768480).
5) The master node receives psync After the command, first check the parameters runId Is it consistent with itself , If one
Cause , Note that the current primary node is copied before ; Then according to the parameters offset Copy the backlog in itself
Punch search , If the data after the offset exists in the buffer , Then send... To the slave node
+CONTINUE Respond to , Indicates partial replication is possible . After receiving the reply from the node, print the following days
Records :
S * Successful partial resynchronization with master.
S * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization.
6) The master node sends the data in the replication backlog buffer to the slave node according to the offset , Guarantee
Master slave replication enters normal state . The amount of data sent can be obtained from the log of the master node , As follows
in :
M * Slave 127.0.0.1:6380 asks for synchronization
M * Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 78
bytes of backlog starting from offset 49769216.
It can be found from the log that this partial replication is only synchronized 78 byte , The data transmitted is far less than
Full data .
6.3.5 heartbeat
After the master and slave nodes establish replication , They maintain a long connection and send heartbeat commands to each other ,
Pictured 6-17 Shown
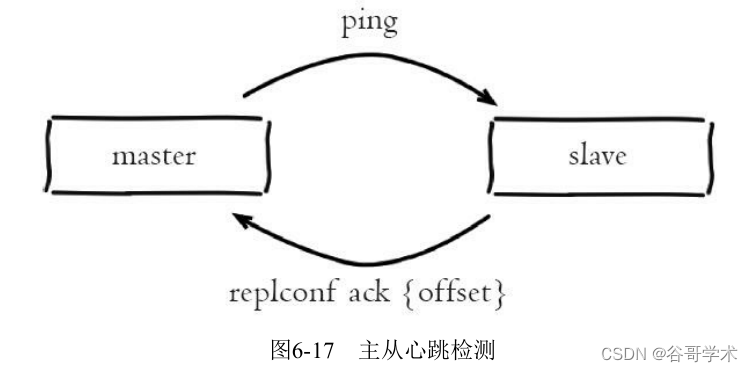
Master slave heartbeat judgment mechanism :
1) The master and slave nodes have heartbeat detection mechanism for each other , Simulate each other's clients to communicate
Letter , adopt client list Command to view replication related client information , The connection status of the master node is
flags=M, The slave node connection state is flags=S.
2) The primary node defaults to every 10 Second pair sent from node ping command , Judge the viability of the slave node
And connection status . You can use the parameters repl-ping-slave-period Control the transmission frequency .
3) The slave node is in the main thread every 1 Seconds to send replconf ack{offset} command , To the master node
Report your current copy offset .replconf The main functions of the command are as follows :
· Real time monitoring of master-slave node network status .
· Report its own copy offset , Check whether the copied data is lost , If the data from the slave node is lost
loss , Then pull the lost data from the replication buffer of the master node .
· Realize the function of ensuring the number and latency of slave nodes , adopt min-slaves-to-write、min-
slaves-max-lag Parameter configuration definition .
The master node is based on replconf The command judges the timeout of slave node , Embodied in info replication system
In the plan lag In information ,lag Represents the number of seconds delayed by the last communication with the slave node , The normal delay shall be
Should be in 0 and 1 Between . If exceeded repl-timeout The value of the configuration ( Default 60 second ), Then it is determined that the slave node
Go offline and disconnect the replication client . Even if the master node decides that the slave node is offline , If the slave node is heavy
New recovery , The heartbeat test will continue .
Operation and maintenance tips
In order to reduce the master-slave delay , Generally put Redis The master and slave nodes are deployed in the same machine room / City plane
room , Avoid network delay and heartbeat interruption caused by network partition .
6.3.6 Asynchronous replication
The master node is not only responsible for data reading and writing , It is also responsible for synchronizing write commands to slave nodes . Write the command to send
The sending process is completed asynchronously , That is to say, after the master node handles the write command itself, it directly returns it to the client
End , Does not wait for replication from node to complete , Pictured 6-18 Shown .
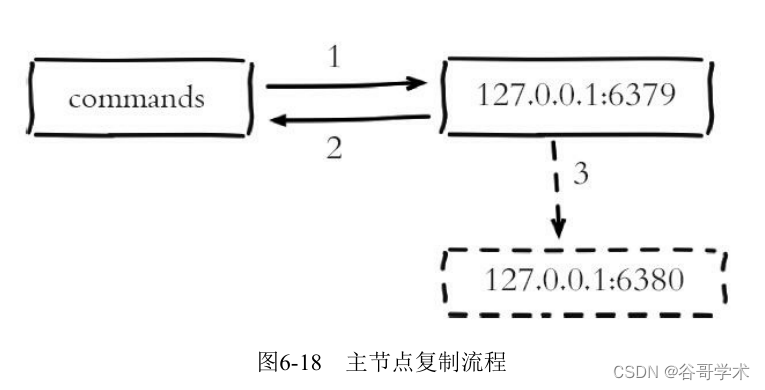
Master node replication process :
1) Master node 6379 Receive processing command .
2) After the command is processed, the response result is returned .
3) The modification command is sent asynchronously to 6380 From the node , The slave node performs replication in the main thread
The order of .
Because the master-slave replication process is asynchronous , This will cause the data of the slave node to be delayed relative to the master node
late . How many bytes are delayed , We can perform... At the master node info replication Command view phase
Relevant indicators are obtained . as follows :
slave0:ip=127.0.0.1,port=6380,state=online,offset=841,lag=1
master_repl_offset:841
You can see the slave node in the statistics slave0 Information , The data of slave nodes are recorded respectively ip and
port, From the state of the node ,offset Represents the copy offset of the current slave node ,
master_repl_offset Represents the copy offset of the current master node , The difference between the two is the current slave node
Point replication latency .Redis The replication speed of depends on the network environment between master and slave ,repl-disable-
tcp-nodelay, Command processing speed, etc . Under normal circumstances , Delay in 1 Within seconds .
边栏推荐
猜你喜欢




![[Mori city] random talk on GIS data (II)](/img/5a/dfa04e3edee5aa6afa56dfe614d59f.jpg)
随机推荐
[software test] the most complete interview questions and answers. I'm familiar with the full text. If I don't win the offer, I'll lose
Qpushbutton- "function refinement"
一本揭秘字节万台节点ClickHouse背后技术实现的白皮书来了!
普通测试年薪15w,测试开发年薪30w+,二者差距在哪?
Unity custom webgl packaging template
[node learning notes] the chokidar module realizes file monitoring
The 8 element positioning methods of selenium that you have to know are simple and practical
用全连接+softmax对图片的feature进行分类
Safety delivery engineer
LeetCode 77:组合
Cloud Mail .NET Edition
Detailed explanation of 19 dimensional integrated navigation module sinsgps in psins (initial assignment part)
Pioneer of Web3: virtual human
Increase 900w+ playback in 1 month! Summarize 2 new trends of top flow qiafan in station B
Static proxy of proxy mode
AWS学习笔记(一)
unity webgl自适应网页尺寸
QT常见概念-1
AWS learning notes (I)
Compress JS code with terser