当前位置:网站首页>Summer Challenge database Xueba notes (Part 2)~
Summer Challenge database Xueba notes (Part 2)~
2022-07-07 02:24:00 【51CTO】
This article is participating in the starlight project 3.0– Summer Challenge
View / stored procedure / trigger View
View is a virtual table , Unlike tables that contain data , Views only contain queries that retrieve data dynamically when in use , It is mainly used to query . Why use views
Be careful :
Rules and restrictions for views
View creation
Update of view
Whether the view can be updated , It depends on the situation .
Usually the view can be updated , You can do insert,update and delete. Updating a view is updating its base table ( The view itself has no data ). If you add or delete rows to a view , In fact, it is to add or delete rows to the base table .
however , If MySQL Can't determine the updated base table data correctly , Update is not allowed ( Include insert and delete ), This means that the view cannot be updated if the following operations exist in the view :(1) grouping ( Use group by and having );(2) coupling ;(3) Subquery ;(4) and ;(5) Aggregation function ;(6)dictinct;(7) export ( Calculation ) Column .
stored procedure
A stored procedure is one or more stored procedures for later use MySQL Collection of statements . It can be regarded as a batch document , Although their role is not limited to batch processing . Why use the storage process ?
1. By encapsulating the processing in an easy-to-use unit , Simplify complex operations ;
2. Since it is not required to repeatedly establish a series of processing steps , Data integrity guaranteed . If all developers and applications use the same ( Experiments and tests ) stored procedure , The code used is the same . The extension of this is to prevent mistakes . The more steps you need to take , The more likely it is to make a mistake , Error prevention ensures data consistency .
3. Simplify management of change , If table name . Column name or business logic changes , Just change the code of the stored procedure . People who use it don't even need to know about these changes . This extension is security , Limiting access to base data through stored procedures reduces the chance of data corruption .
4. Improve performance . Because using stored procedures is better than using separate sql Faster sentences .
5. There are some that can only be used for a single request MySQL Elements and properties , Stored procedures can use them to write more powerful and flexible code
Sum up :
Three main benefits : Simple 、 Security 、 High performance .
Two flaws :
1、 The writing of stored procedures is more complicated , Need more skills, more experience .
2、 You may not have security access to create stored procedures . Many database administrators restrict stored procedures Create permissions , Allow to use , Creation of . Execute stored procedures
Call keyword :Call Accept the name of the stored procedure and any parameters that need to be passed to it . Stored procedures can display results , You can also not show the results .
CREATE PROCEDURE productpricing()
Create a productpricing The storage process of . If parameters need to be passed in the stored procedure , Then list them in brackets . Brackets must have .BEGIN and END The keyword is used to restrict the stored procedure body . The stored procedure body itself is a simple select sentence . Note that it's just to create the stored procedure without calling .
Use of storage process :
Call productpring();
Stored procedure using parameters
General stored procedures do not show results , Instead, return the result to the variable you specified .
Variable : A specific location in memory , Used to temporarily store data .
explain :
This stored procedure accepts 3 Parameters ,pl Lowest price for storage products ,ph The highest price of storage products ,pa Average price of storage products . Each parameter must specify the type , The decimal system is used , keyword OUT Indicates that the corresponding parameter is used to transfer a value from the stored procedure ( Back to the caller ).
MySQL Support in( Pass to stored procedure )、out( Out of stored procedure , Used here ) and inout( Pass in and out of stored procedures ) Parameters of type . The code for the stored procedure is located in begin and end Statement within . They are a series of select sentence , Used to retrieve values . Then save to the corresponding variable ( adopt INTO keyword ).
Parameters of stored procedures allow the same data types as those used in tables . Note that recordsets are not allowed types , therefore , Cannot return more than one row and column with one parameter , That's why it's used 3 Parameters and 3 strip select The reason for the statement .
call : To call this stored procedure , Must specify 3 Variable names . As shown above .3 Parameters are stored in the stored procedure 3 The names of variables . Invocation time , Statement does not display any data , It returns variables that can be displayed later ( Or in other processes ).
Be careful : be-all MySQL Variables are all based on @ start .
Stored procedures with control statements
We used... In the stored procedure DECLARE sentence , They define two local variables ,DECLARE Requires variable name and data type to be specified . It also supports optional defaults (taxrate Default 6%), Because later we have to decide whether to increase taxes , therefore , We put SELECT The results of the query are stored in local variables total in , And then in IF and THEN With the help of , Check taxable Is it true , And then in the real case , We use the other one SELECT Statement to increase business tax to local variable total in , Then we use SELECT Statement will total( The result of increasing or not increasing taxes ) Save to the general ototal in .
COMMENT keyword above COMMENT Can give or not give , If given , Will be in SHOW PROCEDURE STATUS The results show that .
trigger
Automatically process certain statements when a table changes , This is the trigger .
The trigger is MySQL Respond to delete 、update 、insert 、 be located begin and end An automatic execution of a set of statements between statements MySQL sentence . Other statements do not support triggers . Create trigger
When creating triggers , Need to give 4 statement ( The rules ):
- Unique trigger name ;
- Trigger associated table ;
- Trigger should respond to the activity ;
- When the trigger executes ( Before or after handling )
Create trigger Sentence creation trigger
CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added' INTO @info;
CREATE TRIGGER Used to create a file named newproduct New trigger for . Triggers can be executed before or after an operation , here AFTER INSERT This trigger is in INSERT Statement executed after successful execution . This trigger also specifies FOR EACH ROW , So the code will execute on every insert line . Text Product added Will show once for each inserted row .
Be careful :
1、 Triggers are only supported by tables , View , Triggers are not supported for temporary tables .
2、 Triggers are defined each time for each event in each table , Only one trigger per event per table is allowed at a time , therefore , Each table supports up to six triggers (insert,update,delete Of before and after).
3、 A single trigger cannot be associated with multiple events or tables , therefore , You need a right insert and update Trigger for operation execution , You should define two triggers .
4、 Trigger failed : If before Trigger failed , be MySQL The requested operation will not be performed , Besides , If before Trigger or statement itself failed ,MySQL Will not execute after trigger . Trigger category
INSERT trigger
Is in insert Trigger executed before or after statement execution .
1、 stay insert Trigger code , One can be introduced called new The virtual table of , Access the inserted row ;
2、 stay before insert Trigger ,new Values in can also be updated ( Allow changes to inserted values );
3、 about auto_increment Column ,new stay insert Include... Before execution 0, stay insert Include new auto generated values after execution
CREATE TRIGGER neworder AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num;
Create a file called neworder The trigger of , according to AFTER INSERT ON orders perform . Insert a new order into orders Table time ,MySQL Generate a new order number and save it to order_num in . Trigger from NEW.order_num Take this value and return it . This trigger must follow AFTER INSERT perform , Because in BEFORE INSERT Before statement execution , new order_num Not yet generated . about orders This trigger always returns a new order number for each insert of .
DELETE trigger
Delete Trigger in delete Statement before or after execution .
1、 stay delete Trigger code inside , You can quote a name as OLD The virtual table of , To access the deleted row .
2、OLD The values in are all read-only , Can't update .
This trigger will be executed before any order is deleted , It uses a INSERT Statement will OLD The value in ( Order to be deleted ) Save to a file named archive_orders In the archive form of ( For practical use of this example , We need to use with orders The same column is created with the name archive_orders Table of )
Use BEFORE DELETE Advantages of triggers ( be relative to AFTER DELETE The trigger says ) by , If for some reason , Orders cannot be filed ,delete Itself will be abandoned .
We used... In this trigger BEGIN and END Statement tag trigger body . This is not necessary in this example , Just to illustrate the use of BEGIN END The advantage of blocks is that triggers can hold multiple SQL sentence ( stay BEGIN END One by one in the block ).
UPDATE trigger
stay update Statement before or after execution
1、 stay update Trigger code inside , You can quote a name as OLD The virtual table of , Used to visit before (UPDATE The statement before ) Value , Quote a name as NEW Virtual table access new updated values .
2、 stay BEFORE UPDATE Trigger ,NEW The values in may also be used to update ( Allow changes to be used for UPDATE Value in statement )
3、OLD The values in are all read-only , Can't update .
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors FOR EACH ROW SET NEW.vend_state = Upper(NEW.vemd_state);
Make sure that state abbreviations are always capitalized ( No matter UPFATE Is capitalization given in the statement ), Every time a line is updated ,NEW.vend_state The value in ( Will be used to update the value of the table row ) Use both Upper(NEW.vend_state) Replace . summary
1、 Usually before For data validation and purification ( To ensure that the data inserted into the table is really the data needed ) Can also be applied to update trigger .
2、 And others DBMS comparison ,MySQL 5 The triggers supported in are fairly rudimentary , In the future MySQL It is estimated that there will be some improved and enhanced trigger support in the version .
3、 Creating triggers may require special security access , But the trigger executes automatically , If insert,update, perhaps delete Statement can execute , Then the relevant trigger can also execute .
4、 Use triggers to ensure data consistency ( Case write , Format, etc. ). The advantage of doing this type of processing in a trigger is that it always does it , And transparently , Nothing to do with client applications .
5、 A very meaningful use of triggers is to create audit trails . Use triggers , Change ( if necessary , Even before and after ) It's very easy to record to another table .
6、MySQL Trigger does not support call sentence , Cannot call stored procedure from within trigger .
Database recovery implementation technique
Data dump
Dump means DBA The process of copying the entire database to other storage media and saving it , Backup data is called a backup copy or backup copy
Static dump :
1) Definition : Dump operation when no transaction is running in the system . The database is in one at the beginning of the dump Sexual state , Dump does not allow any access to the database 、 To amend . Static dump must be a consistent copy of the data .
2) advantage : Implement a simple
3) shortcoming : Reduced database availability
The dump must wait for the end of a running user transaction to proceed ; New transactions must wait for the end of the dump to execute
Dynamic dump :
Mass dump :
Incremental dump :
Log files
1、 What is a log file
Log files (log) It is used to record the update operation of transaction to database 2、 Format of log file
1) In records :
The contents to be registered in the log file include :
What each log records :
2) In blocks
The log records include :
Transaction ID ( Indicate which business )
Updated data block 3、 The role of log files
1) Log files must be used for transaction recovery and system recovery
2) Log files must be created in dynamic dump mode , Only by combining backup copy with log files can the database be recovered effectively
3) Log files can also be created in static dump mode ( Reload backup copy , Then use the log file to redo the completed transaction , Undo outstanding transactions )
4、 Register log files :
Why write a log file first ?
1) Writing a database and a log file are two different operations , There may be a fault between these two operations
2) If the database modification is written first , This change is not registered in the log file , Then we can't restore this modification later
3) If you write a log first , But it didn't change the database , It is unnecessary to perform the log file recovery only once more UNDO operation , It doesn't affect the correctness of the database
Recovery strategy
Recovery of transaction failure
- Reverse scan file log , Find the update operation of the transaction .
- Reverse the update operation of the transaction . Is about to log “ Value before update ” Write to database .
The insert , “ Value before update ” It's empty , It is equivalent to deleting Delete operation ,“ Updated value ” It's empty , It's equivalent to inserting If it's a modification , It is equivalent to replacing the modified value with the pre modified value - Continue reverse scanning log files , Find other update operations for this transaction , And do the same thing .
- Deal with it like this , Until you read the start tag of this transaction , Transaction recovery is complete . Recovery of system failure
The reason of database inconsistency caused by system failure Incomplete transaction update to database written to database The update of the committed transaction to the database is still left in the buffer before it can be written to the database Recovery method Undo Unfinished transactions at the time of failure Redo Completed transactions The recovery of system failure is automatically completed when the system is restarted , No user intervention is required Recovery steps for system failure - Forward scanning log files
- To revoke (Undo) Queue transactions to undo (UNDO) Handle
- To redo (Redo) Queue transactions redo (REDO) Handle
Recovery of media failure
Recovery steps
Reload the database
Load a copy of the log file in question , Redo what has been done .
checkpoint
Periodically do the following : Set up checkpoints , Save database state .
The specific steps are :
1. Write all the log records in the current log buffer to the log file on disk
2. Write a checkpoint record in the log file
3. Write all data records of the current data buffer to the database of the disk
4. Write the address of the checkpoint recorded in the log file to a restart file
Using checkpoint methods can improve recovery efficiency
When a transaction T Submit... Before a checkpoint :
Use checkpoint recovery steps
1. Find the address of the last checkpoint recorded in the log file... From the restart file , This address finds the last checkpoint record in the log file
2. The checkpoint records the list of all transactions being executed at the checkpoint establishment time ACTIVE-LIST
3. Scan log files forward from checkpoint , Until the end of the log file
4. Yes UNDO-LIST Each transaction in performs UNDO operation
Mirror image
In order to avoid hard disk media failure affecting the availability of the database , many DBMS Database image provided (mirror) Function for database recovery .
Copy the entire database or critical data from it to another disk , Whenever the primary database is updated ,DBMS Automatically copy the updated data , from DBMS Automatically ensure the consistency between the image data and the primary database . In case of media failure , It can be used by the mirror disk , meanwhile DBMS Automatic use of disk data for database recovery , There is no need to shut down the system and reinstall the database copy .
When there is no failure , Database mirroring can also be used for concurrent operations , That is, when a user adds an exclusive lock to the database to modify data , Other users can read the data on the mirror database , Instead of waiting for the user to release the lock .
Because database mirroring is achieved by copying data , Assigning data frequently will naturally reduce the efficiency of the system . Therefore, in practical applications, users often only choose to mirror key data and log files .
Summary :
Common recovery techniques
Recovery of transaction failure
Recovery of system failure
Recovery of media failure
Technology to improve recovery efficiency
Checkpoint Technology
mirror technique
concurrency control
Multi user database : Databases that allow multiple users to use at the same time ( Booking system )
Different multi transaction execution methods :
In a single processor system , The concurrent execution of transactions is actually the cross running of the parallel operations of these parallel transactions ( It's not really concurrency , But it improves the efficiency of the system )
3. Concurrent mode :
In a multiprocessor system , Each processor can run a transaction , Multiple processors can run multiple transactions at the same time , Realize the real parallel operation of multiple transactions
Problems caused by concurrent execution :
summary
Data inconsistencies caused by concurrent operations include
mark :W(x) Writing data x R(x) Reading data x
The task of concurrency control mechanism :
The main technology of concurrency control
The blockade
The blockade : Blockade is business T On a data object ( Such as table 、 Records, etc. ) Before the operation , Make a request to the system first , Lock it . After lock transaction T It has certain control over the data object , In the transaction T Before releasing its lock , Other transactions cannot update this data object
The exact control depends on the type of blockade
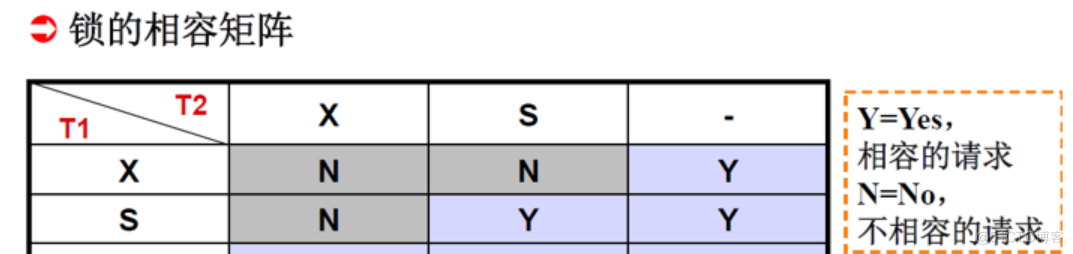
There are two basic types of blockade : Exclusive lock (X lock ,exclusive locks)、 Shared lock (S lock ,share locks)
Exclusive lock is also called write lock , Yes A With the lock on it , Nothing else can be right A Add Any type of lock ( Repel reading and writing )
Shared lock is also called read lock , Yes A After adding the shared lock , Other things can only be done to A Add S lock , Cannot add X lock ( Write only )
( Very important )
Blocking agreement
Using X Lock and S When locking data objects , Some rules need to be agreed : Blocking agreement (Locking Protocol)
When to apply for X Lock or S lock 、 Holding time 、 When to release
Make different rules about how to block , There are different kinds of blockade agreements .
Common blocking protocol : Three level blockade agreement
The three-level blocking protocol solves the concurrency problem in different degrees , It provides a guarantee for the correct scheduling of concurrent operations .
1、 First level blockade protocol
Business T Modifying data R Before , It must be added first X lock , Until the end of the transaction (commit/rollback) To release .
The first level blocking protocol can prevent the loss of modification
If it's reading data , It doesn't need to be locked , So it's not guaranteed to be repeatable or unreadable “ dirty ” data .
2、 Secondary blockade protocol
The second level blocking protocol can prevent the loss of modification , It also prevents reading dirty data
Because the data is released after reading S lock , There's no guarantee that it's not repeatable
3、 Three level blockade agreement :
The three-level blocking protocol can prevent the loss of modification and reading of dirty data , It also prevents non repeatable reading
The main difference of the three-level blocking protocol is what operation needs to apply for a lock , When to release the lock . The higher the blockade , The more consistent .
hunger
hunger : Business T1 Blocked data R, Business T2 And ask for a blockade R, therefore T2 wait for .T3 And ask for a blockade R, When T1 The release of the R After the blockade on , The system first approved T3 Request ,T2 Still waiting . T4 And ask for a blockade R, When T3 The release of the R After the blockade, the system approved T4 Request ……T2 It's possible to wait forever , This is the case of hunger
The way to avoid hunger : First come, first served
When multiple transaction requests block the same data object , These transactions are queued in the order in which they are requested to be blocked
Once the lock on the data object is released , First approve the first transaction in the application queue to obtain the lock .
Deadlock
Deadlock : Business T1 Blocked data R1, T2 Blocked data R2. T1 And ask for a blockade R2, because T2 It's blocked R2, therefore T1 wait for T2 Release R2 The lock on the . next T2 And apply for a blockade R1, because T1 It's blocked R1,T2 Only
wait for T1 Release R1 The lock on the . such T1 Waiting for the T2, and T2 Waiting again T1,T1 and T2 Two things can never end , Formation of a deadlock .
The solution to deadlock : The prevention of 、 Diagnosis and removal
1、 Deadlock prevention
The cause of deadlock is that two or more transactions have blocked some data objects , Then they all request to lock data objects that have been blocked by other transactions , So there's a dead wait .
To prevent deadlock is to destroy the condition of deadlock
Method
1) One time blockade :
2) Sequential blockade :
Maintenance cost : There are many blocked objects in the database system , And it's changing
Difficult to achieve : It's hard to determine which objects to block for each transaction
DBMS A common method of diagnosing and unlocking
2、 Diagnosis and removal of deadlock
Waiting graph is a directed graph G=(T,U),T For the set of nodes , Each node represents a running transaction , U A collection of sides , Each side represents the transaction waiting . if T1 wait for T2, be T1、T2 Draw a directed edge between , from T1 Point to T2.
The concurrency control subsystem periodically ( For example, every few seconds ) Generate transaction wait graph , Detect transactions . If a circuit is found in the diagram , It means there is a deadlock in the system .
Deadlock Relieving : The concurrency control subsystem chooses a transaction with the least deadlock cost , Withdraw it .
Release all locks held by the transaction , Enable other transactions to continue .
Serial scheduling
What kind of scheduling is right ? Serial scheduling is correct .
( It is also true that the execution result is equivalent to serial scheduling , Such scheduling is called serializable scheduling .) Serializable scheduling
Definition : Concurrent execution of multiple transactions is correct , If and only if the result is the same as when these transactions are executed serially in a certain order , This scheduling strategy is called serializable scheduling (serializable).
Serializability is the criterion for the correct scheduling of concurrent transactions . According to this rule , A given concurrent schedule , If and only if it is serializable , I think it's the right scheduling .
Conflicts can be scheduled serially
Determine the sufficient conditions for serializable scheduling
Conflicting operations : Different transactions read and write the same data .
Conflicting operations of different transactions and two operations of the same transaction cannot be exchanged .
Ri(x) and Wj(x) Not exchangeable ,Wi(x) and Wj(x) Not exchangeable
Conflicts can be scheduled serially :
A dispatch Sc In the case of keeping the order of conflicting operations unchanged , Get another schedule by exchanging the order of two non conflicting transactions Sc’, If Sc’ It's serial , Call scheduling Sc Serializable scheduling for conflicts .
Two stage lock protocol
DBMS The concurrency control mechanism must provide some means to ensure that the scheduling is serializable . at present DBMS Two stage lock protocol is widely used (TwoPhase Locking, abbreviation 2PL) To show the serializability of concurrent scheduling .
Two phase locking protocol means that all transactions must be locked and unlocked in two phases .
“ Two paragraphs ” The meaning of lock : The transaction is divided into two stages
The first stage is to get the blockade , Also known as the extension phase
A transaction can request any type of lock on any data object , But you can't release any locks
The second stage is to release the blockade , Also known as the contraction phase
A transaction can release any type of lock on any data object , But you can't apply for any more locks
It is a sufficient condition for serializable scheduling that transactions obey two-stage locking protocol , It's not necessary .
If both concurrent transactions follow the two-stage locking protocol , Any concurrent scheduling strategy for these transactions is serializable
If a schedule of concurrent transactions is serializable , Not all transactions are subject to the two-stage locking protocol
Two stage locking protocol and one-time blocking method to prevent deadlock
One time blocking requires every transaction to lock all data to be used at one time , Otherwise, we can't carry on , Therefore, the one-time blocking law abides by the two-stage locking agreement
However, the two-stage locking protocol does not require the transaction to lock all data to be used at one time , Therefore, transactions complying with the two-stage locking protocol may deadlock
The granularity of the blockade
The size of the blocking object is called blocking granularity (granularity).
The blocked object can be a logical unit ( Property value 、 Property value set 、 Tuples 、 Relationship 、 Index entry 、 database ), It can also be a physical unit ( page 、 Physical records ).
Choose the principle of blocking granularity :
The smaller it is ;
The smaller the size of the blockade , High concurrency , But the more overhead there is
Intent locks
Intent locks : If an intention lock is applied to a node , The lower level node of the node is being locked ; When locking any node , You must first add intention lock to its upper node .
for example , When locking any tuple , You must first add an intentional lock to the database and relationship it is in .
Three kinds of common intention locks : Intention sharing lock (Intent Share Lock,IS lock ); Intention exclusive lock (Intent Exclusive Lock,IX lock ); Sharing intention exclusive lock (Share Intent Exclusive Lock,SIX lock ).
1、IS lock
If you add... To a data object IS lock , Indicates that its child nodes are to be added S lock .
for example : Business T1 Right R1 Add... To a tuple in S lock , First of all, the relationship R1 And database plus IS lock
2、IX lock
If you add... To a data object IX lock , Indicates that its child nodes are to be added X lock .
for example : Business T1 Right R1 Add... To a tuple in X lock , First of all, the relationship R1 And database plus IX lock
3、SIX lock
If you add... To a data object SIX lock , To add to it S lock , add IX lock , namely SIX = S + IX.
for example : Add... To a watch SIX lock , It means that the transaction needs to read the whole table ( So add S lock ), Same as
Will update individual tuples ( So add IX lock )
Intention lock strength : The strength of a lock is its rejection of other locks . It is safe for a transaction to replace weak lock with strong lock when applying for blocking , Otherwise .
Multi granularity blocking method with intention lock
When applying for a blockade, it should be done in a top-down order
The release of the blockade should be done in a bottom-up order
advantage :
In practice DBMS Widely used in products .
Other concurrency controls
Besides blocking technology, the method of concurrency control , And the time stamp method 、 Optimistic control and multi version concurrent control .
Timestamp method : Put a time mark on each transaction , That is, the time when the transaction starts . Each transaction has a unique timestamp , And according to this timestamp to solve the conflict operation of the transaction . In case of conflicting operations , Roll back to a transaction with an earlier timestamp , To ensure the normal execution of other affairs , The transaction being rolled back is given a new timestamp and executed from the beginning .
Optimistic control law holds that there are few conflicts in transaction execution , So there's no special control over things , It's about letting it go , Check the correctness of the transaction before committing . If after checking, it is found that there are conflicts in the execution of the transaction and the serializability is affected , Then reject the commit and roll back the transaction . Also known as verification method
Multi version control is a strategy to achieve high efficiency and concurrency by maintaining multiple version information of data objects in database .
summary :
Xueba notes ( Next ) I hope it helped you , Update tomorrow …… Let's hope together ~
边栏推荐
- Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
- Unicode string converted to Chinese character decodeunicode utils (tool class II)
- 【论文阅读|深读】 GraphSAGE:Inductive Representation Learning on Large Graphs
- 纽约大学 CITIES 研究中心招聘理学硕士和博士后
- Detailed explanation of line segment tree (including tested code implementation)
- Cat recycling bin
- 3D laser slam: time synchronization of livox lidar hardware
- 解密函数计算异步任务能力之「任务的状态及生命周期管理」
- 1500万员工轻松管理,云原生数据库GaussDB让HR办公更高效
- 【Unity】升级版·Excel数据解析,自动创建对应C#类,自动创建ScriptableObject生成类,自动序列化Asset文件
猜你喜欢
Livox激光雷达硬件时间同步---PPS方法
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析
红外相机:巨哥红外MAG32产品介绍

Stm32f4 --- PWM output
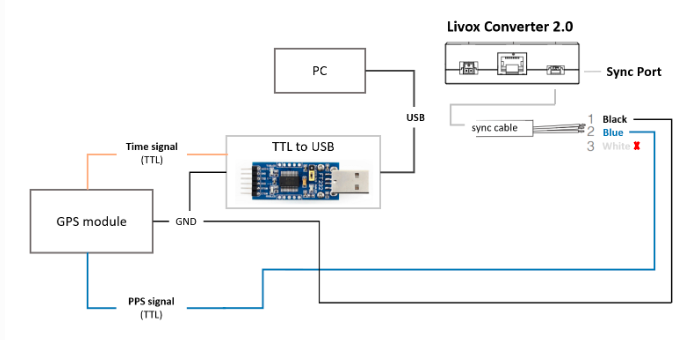
3D laser slam: time synchronization of livox lidar hardware
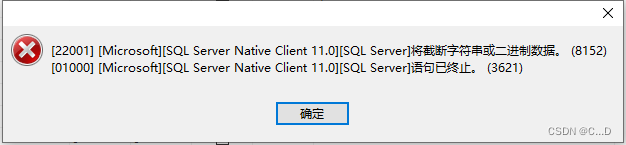
String or binary data will be truncated

一片葉子兩三萬?植物消費爆火背後的“陽謀”

Draco - glTF模型压缩利器
1个月增长900w+播放!总结B站顶流恰饭的2个新趋势
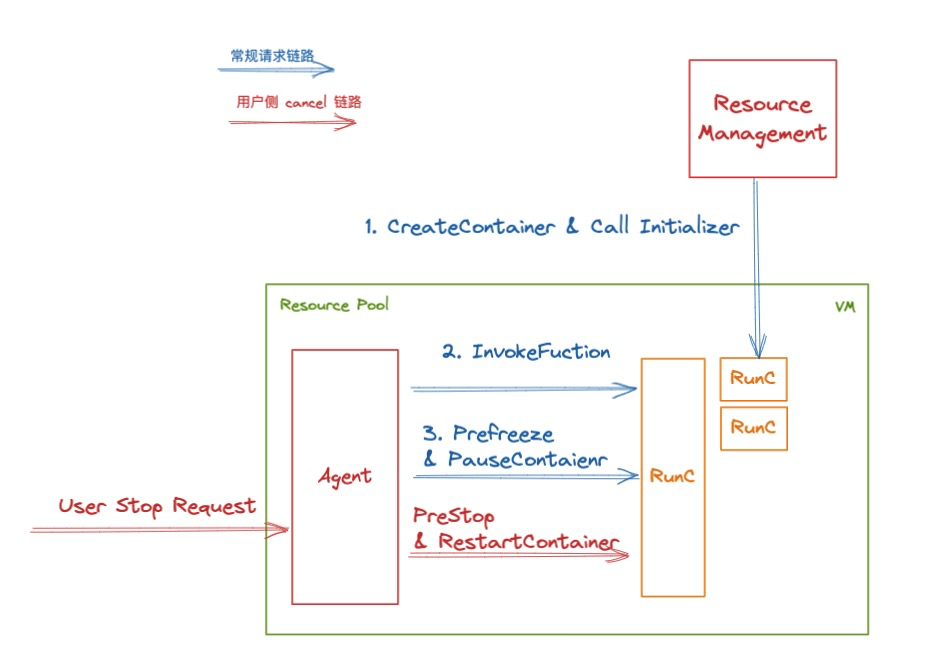
Decryption function calculates "task state and lifecycle management" of asynchronous task capability
随机推荐
ZABBIX 5.0: automatically monitor Alibaba cloud RDS through LLD
【论文阅读|深读】ANRL: Attributed Network Representation Learning via Deep Neural Networks
张平安:加快云上数字创新,共建产业智慧生态
本周 火火火火 的开源项目!
将截断字符串或二进制数据
4--新唐nuc980 挂载initramfs nfs文件系统
STM32F4---PWM输出
[paper reading | deep reading] graphsage:inductive representation learning on large graphs
投资的再思考
FLIR blackfly s industrial camera: auto exposure configuration and code
机器人队伍学习方法,实现8.8倍的人力回报
3D激光SLAM:Livox激光雷达硬件时间同步
Why am I warned that the 'CMAKE_ TOOLCHAIN_ FILE' variable is not used by the project?
MFC Windows 程序设计[147]之ODBC数据库连接(附源码)
leetcode:5. 最长回文子串【dp + 抓着超时的尾巴】
红外相机:巨哥红外MAG32产品介绍
postgresql之整體查詢大致過程
【论文阅读|深读】 GraphSAGE:Inductive Representation Learning on Large Graphs
阿里云中间件开源往事
传感器:DS1302时钟芯片及驱动代码