当前位置:网站首页>【论文阅读|深读】 GraphSAGE:Inductive Representation Learning on Large Graphs
【论文阅读|深读】 GraphSAGE:Inductive Representation Learning on Large Graphs
2022-07-06 18:36:00 【海轰Pro】
目录

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力
知其然 知其所以然!
本文仅记录自己感兴趣的内容
简介
原文链接:https://dl.acm.org/doi/abs/10.5555/3294771.3294869
会议:NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems (CCF A类)
年度:2017/06/07
Abstract
大型图中节点的低维嵌入已被证明在从内容推荐到识别蛋白质功能的各种预测任务中非常有用
然而,大多数现有的方法要求图中的所有节点在嵌入的训练过程中都存在
这些以前的方法本质上是传导性的,不能自然地推广到看不见的节点
在这里,我们提出了GraphSAGE,这是一个通用的归纳框架,它利用节点特征信息(例如,文本属性)来有效地为以前未见的数据生成节点嵌入
我们不是为每个节点训练单独的嵌入,而是学习一个函数,该函数通过采样和聚合节点的局部邻域中的特征来生成嵌入
1 Introduction
事实证明,大型图形中节点的低维向量嵌入对于各种预测和图形分析任务非常有用[5,11,28,35,36]
节点嵌入方法的基本思想是使用降维技术将关于节点图邻域的高维信息提取到密集的向量嵌入中
这些节点嵌入然后可以被馈送到下游机器学习系统,并帮助执行诸如节点分类、聚类和链接预测之类的任务
然而,以前的工作主要集中在从单个固定的图中嵌入节点,并且许多现实世界的应用程序需要快速地为看不见的节点或全新的(子)图生成嵌入
这种归纳能力对于高通量产生式机器学习系统至关重要,这些系统在不断演变的图表上运行,不断遇到看不见的节点(例如,Reddit上的帖子、YouTube上的用户和视频)
一种生成节点嵌入的归纳方法也促进了具有相同特征形式的图的泛化:
- 例如,可以训练来自模型生物体的蛋白质-蛋白质相互作用图的嵌入生成器,然后使用训练的模型容易地为收集到的新生物体上的数据产生节点嵌入。
与换能式设置相比,归纳节点嵌入问题尤其困难
因为要泛化到看不见的节点,需要将新观察到的子图与算法已经优化过的节点嵌入“对齐”
归纳框架必须学会识别节点邻域的结构属性,这些属性既揭示了节点在图中的局部角色,也揭示了节点的全局位置
大多数现有的生成节点嵌入的方法都是固有的传导性的
这些方法中的大多数使用基于矩阵分解的目标直接优化每个节点的嵌入,并不自然地推广到不可见的数据
因为它们对单个固定图中的节点进行预测
这些方法可以修改为在归纳设置(例如,[28])中操作,但这些修改往往计算昂贵,需要额外的几轮梯度下降才能做出新的预测
最近也有使用卷积运算符学习图结构的方法,它们提供了作为嵌入方法的希望
到目前为止,图形卷积网络(GCNS)只应用于图固定的换能式环境[17,18]
在这项工作中,我们将GCNS扩展到归纳无监督学习任务,并提出了一个框架,该框架推广了GCN方法来使用可训练的聚集函数(不限于简单的卷积)。
我们提出了一个通用的归纳节点嵌入框架,称为GraphSAGE(Sample And Aggregate)
- 与基于矩阵分解的嵌入方法不同,我们利用节点特征(例如,文本属性、节点轮廓信息、节点度)来学习概括到不可见节点的嵌入函数
- 通过在学习算法中加入节点特征,我们同时学习到每个节点邻域的拓扑结构以及节点特征在邻域中的分布
虽然我们专注于特征丰富的图表(例如,具有文本属性的引文数据,具有功能/分子标记的生物数据)
但我们的方法也可以利用所有图表中存在的结构特征(例如,节点度)
因此,我们的算法也可以应用于无节点特征的图
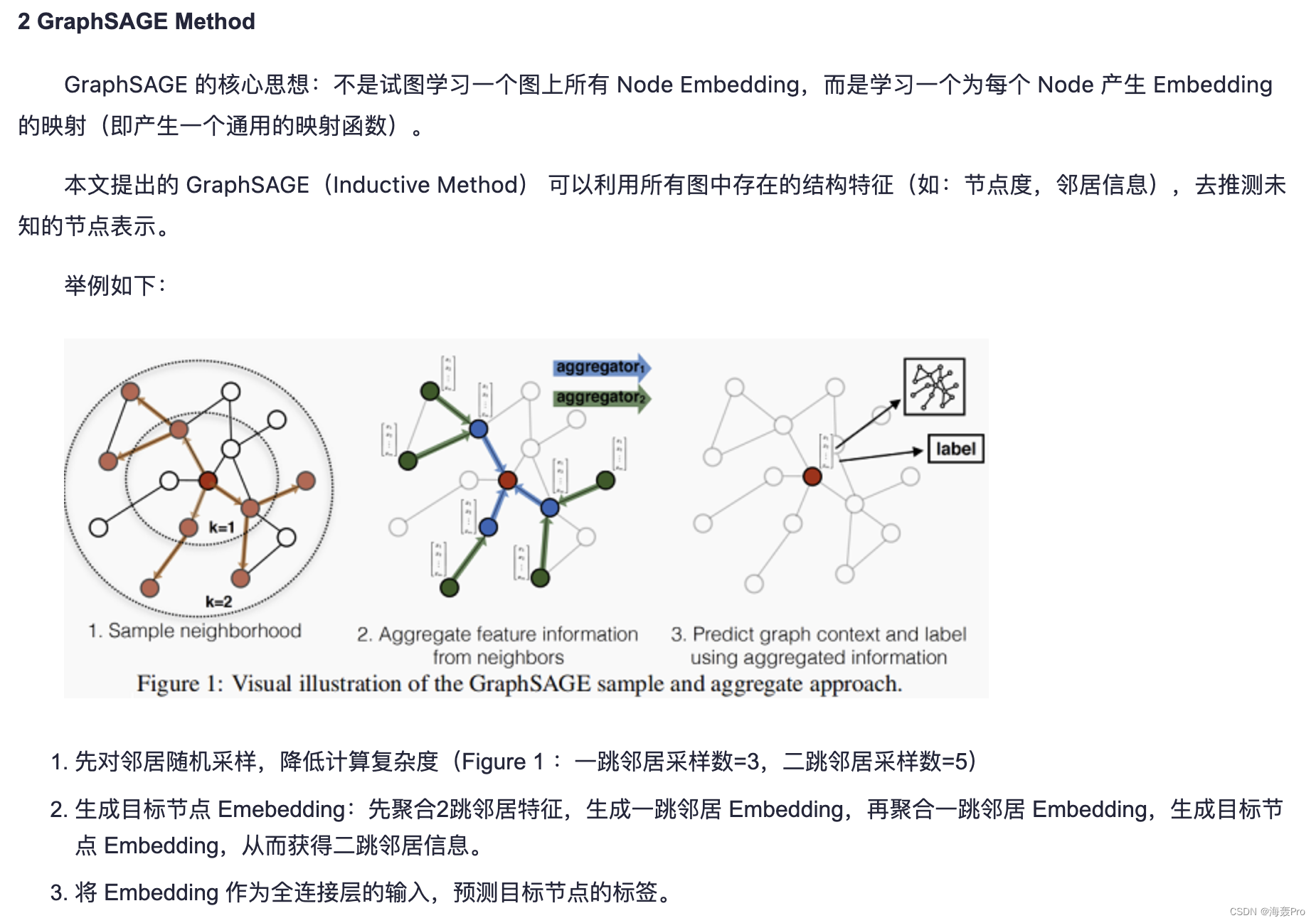
我们没有为每个节点训练不同的嵌入向量,而是训练了一组聚合器函数,这些函数学习从节点的局部邻域聚集特征信息(图1)
每个聚合器功能从远离给定节点的不同跳数或搜索深度聚集信息
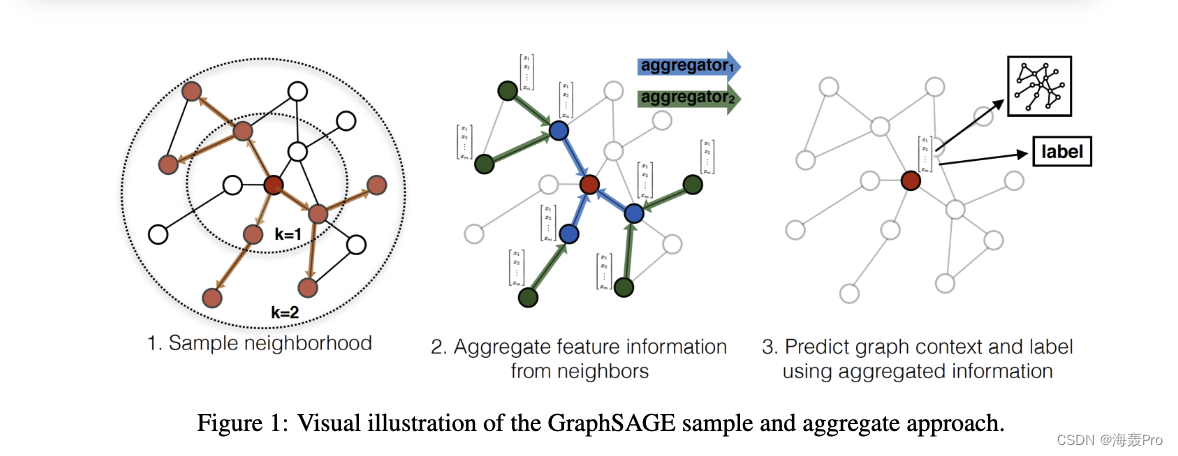
在测试或推理时,我们使用我们训练的系统通过应用学习的聚合函数来生成完全不可见的节点的嵌入
在之前关于生成节点嵌入的工作的基础上,我们设计了一个无监督损失函数
该函数允许在没有特定任务监督的情况下对GraphSAGE进行训练
我们还表明,GraphSAGE可以在完全监督的方式下进行训练
2 Related work
我们的算法在概念上与以前的节点嵌入方法、在图上学习的一般有监督方法以及在将卷积神经网络应用于图结构数据方面的最新进展有关
基于因式分解的嵌入方法
最近有许多节点嵌入方法使用随机游走统计和基于矩阵分解的学习目标来学习低维嵌入[5,11,28,35,36]
这些方法还与更经典的谱聚类[23]、多维缩放[19]以及PageRank算法[25]有着密切的关系
由于这些嵌入算法直接训练各个节点的节点嵌入,因此它们本质上是传导性的,并且至少需要昂贵的附加训练(例如,经由随机梯度下降)来对新节点进行预测
此外,对于这些方法中的许多方法(例如,[11,28,35,36]),目标函数对于嵌入的正交变换是不变的,这意味着嵌入空间不会在图之间自然泛化,并且可能在重新训练期间漂移
这一趋势的一个明显例外是由Yang等人介绍的Planetid-I算法。[40]这是一种基于归纳、嵌入的半监督学习方法
然而,Planetid-I在推理过程中不使用任何图形结构信息;相反,它在训练期间使用图形结构作为正则化形式
与以前的方法不同,我们利用特征信息来训练模型,以便为看不见的节点生成嵌入
图上的有监督学习
除了节点嵌入方法,还有大量关于图结构数据上的监督学习的文献
这包括各种各样的基于核的方法,其中图的特征向量从各种图核中派生(参见[32]及其参考文献)
最近也有一些神经网络方法在图结构上进行监督学习[7,10,21,31]
我们的方法在概念上受到了许多这样的算法的启发
然而,尽管这些以前的方法试图对整个图(或子图)进行分类,但这项工作的重点是为单个节点生成有用的表示
图卷积网络
近年来,已经提出了几种用于图上学习的卷积神经网络结构(例如,[4,9,8,17,24])
这些方法中的大多数不适用于大型图或设计用于全图分类(或两者兼有)[4、9、8、24]
然而,我们的方法与Kipf等人提出的图卷积网络(GCN)密切相关[17,18]
最初的GCN算法[17]是为换能式环境下的半监督学习而设计的,而精确的算法要求在训练过程中知道完整的图拉普拉斯
我们算法的一个简单变体可以被视为GCN框架到归纳环境的扩展,我们在3.3节中重新讨论了这一点。
3 Proposed method: GraphSAGE
我们方法背后的关键思想是:学习如何从节点的局部邻域中聚合特征信息(例如,附近节点的度数或文本属性)
- 首先描述GraphSAGE嵌入生成(即前向传播)算法,该算法在假设已经学习了GraphSAGE模型参数的情况下为节点生成嵌入(3.1节)
- 然后,我们描述如何使用标准随机梯度下降和反向传播技术来学习GraphSAGE模型参数(第3.2节)。
3.1 Embedding generation (i.e., forward propagation) algorithm
在本节中,我们描述嵌入生成或前向传播算法(算法1),它假设模型已经被训练并且参数是固定的

具体地说,我们假设我们已经学习了 K K K个聚集器函数的参数
记为 A G G R E G A T E k , ∀ k ∈ 1 , . . . , K AGGREGATE_k,∀k∈{1,...,K} AGGREGATEk,∀k∈1,...,K
它们聚集了来自节点邻居的信息,以及一组权重矩阵 W k , ∀ k ∈ 1 , . . . , K W^k,∀k∈{1,...,K} Wk,∀k∈1,...,K
它们被用来在模型的不同层之间或“搜索深度”之间传播信息
第3.2节描述了如何训练这些参数
算法1背后的直觉是,在每次迭代或搜索深度时,节点从它们的本地邻居那里收集信息
并且随着这个过程的迭代,节点从图的更远的范围逐渐获得越来越多的信息
算法1描述了在提供整个图 G = ( V , E ) G=(V,E) G=(V,E)和所有节点的特征 X v X_v Xv、 ∀ v ∈ V ∀v∈V ∀v∈V作为输入的情况下的嵌入生成过程
我们将描述如何将其推广到下面的小型批处理设置
算法1的外环中的每个步骤如下进行,其中
- k k k表示外环中的当前步骤(或搜索深度)
- h k h^k hk表示该步骤中的节点表示
首先,每个节点 v ∈ V v∈V v∈V聚集其直接邻域中的节点的表示, h u k − 1 , ∀ u ∈ N ( v ) {h^{k-1}_u,∀u∈N(v)} huk−1,∀u∈N(v),转化成单个载体 h N ( v ) k − 1 h^{k-1}_{N(v)} hN(v)k−1
注意,该聚集步骤依赖于在外部循环的前一迭代处生成的表示(即, k − 1 k−1 k−1),并且 k = 0 k=0 k=0(基本情况)表示被定义为输入节点特征
在聚合相邻特征向量后,GraphSAGE然后将节点的当前表示 h v k − 1 h^{k-1}_v hvk−1与聚合的邻域向量 h N ( v ) k − 1 h^{k-1}_{N(v)} hN(v)k−1连接
并且该连接的向量通过具有非线性激活函数 σ σ σ的全连通层馈送,其转换将在算法的下一步使用的表示(即, h v k , ∀ v ∈ V h^k_v,∀v∈V hvk,∀v∈V)
为了符号方便,我们将深度 K K K处输出的最终表示表示为 z v ≡ h v k , ∀ v ∈ V z_v≡ h^k_v,∀v∈V zv≡hvk,∀v∈V
邻居表示的聚集可以通过各种聚集器架构(由算法1中的AGGREGATE占位符表示)来完成
我们将在下面的第3.3节中讨论不同的架构选择
为了将算法1扩展到小批量设置
给定一组输入节点,我们首先对所需的邻域集(直到深度 K K K)进行前向采样
然后运行内循环(算法1中的第3行),但我们不是迭代所有节点,而是仅计算在每个深度满足递归所需的表示(附录A包含完整的小批量伪代码)
Relation to the Weisfeiler-Lehman Isomorphism Test
GraphSAGE算法的概念灵感来自于测试图同构的经典算法
如果在算法1中
- (i)设置 K = ∣ V ∣ K=|V| K=∣V∣
- (Ii)设置权重矩阵为单位
- (iii)使用适当的散列函数作为聚集器(没有非线性)
则算法1是Weisfeler-Lehman(WL)同构测试的一个实例,也称为“朴素顶点求精”[32]
如果算法1为两个子图输出的表示集 { z v , ∀ v ∈ V } \{z_v,∀v∈V\} { zv,∀v∈V}相同,则WL测试宣布这两个子图同构
众所周知,这个测试在某些情况下会失败,但对大类图是有效的[32]
GraphSAGE是WL测试的连续近似,在WL测试中,我们用可训练的神经网络聚集器替换哈希函数
当然,我们使用GraphSAGE来生成有用的节点表示–而不是测试图形同构
然而,GraphSAGE和经典的WL测试之间的联系为我们的算法设计学习节点邻域的拓扑结构提供了理论背景
Neighborhood definition
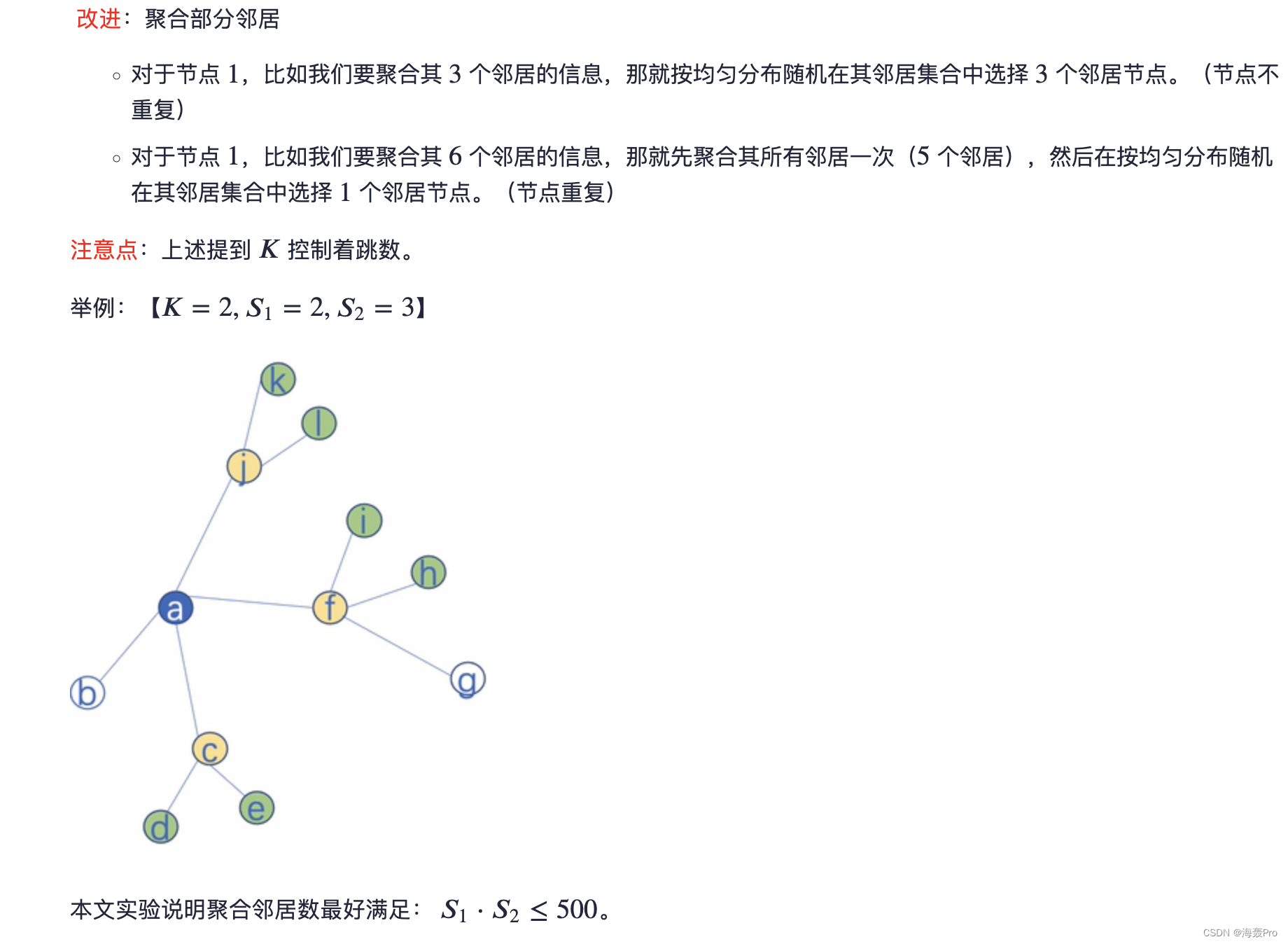
在这项工作中,我们对固定大小的邻域集进行均匀采样,而不是使用算法1中的完整邻域集,以保持每批的计算空间固定
也就是说,使用重载记法,我们将 N ( v ) N(v) N(v)定义为从集合 u ∈ V : ( U , v ) ∈ E {u∈V:(U,v)∈E} u∈V:(U,v)∈E中的固定大小的均匀抽取,并且在算法1中的每次迭代 k k k处抽取不同的均匀样本
如果没有这个采样,单个批处理的内存和预期运行时间是不可预测的,在最坏的情况下是 O ( ∣ V ∣ ) O(|V|) O(∣V∣)
相反,GraphSAGE的每批空间和时间复杂度固定为 O ( ∏ i = 1 K S i ) O(∏^K_{i=1}S_i) O(∏i=1KSi),其中 S i , i ∈ 1 , . . . , K S_i,i∈{1,...,K} Si,i∈1,...,K和 K K K是用户指定的常量
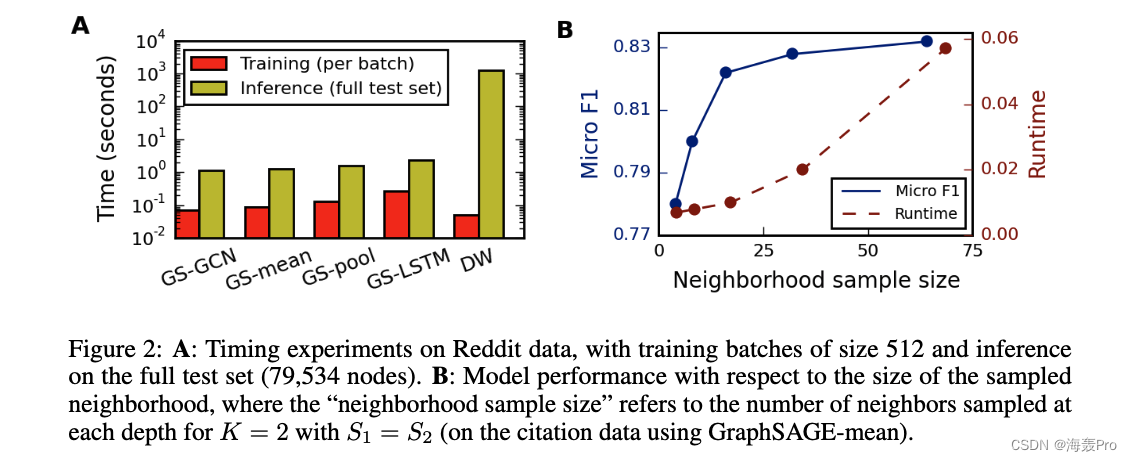
实际上,我们发现我们的方法可以在 K = 2 K=2 K=2和 S 1 ⋅ S 2 ≤ 500 S1·S2≤500 S1⋅S2≤500时获得高性能(有关详细信息,请参见第4.4节)。
3.2 Learning the parameters of GraphSAGE
为了在完全无监督的环境中学习有用的预测表示
我们将基于图的损失函数应用于输出表示 z u , ∀ u ∈ V z_u,∀u∈V zu,∀u∈V,并通过随机梯度下降来调整权重矩阵 W k , ∀ k ∈ 1 , . . . , K W^k,∀k∈{1,...,K} Wk,∀k∈1,...,K和聚集器函数的参数
基于图的损失函数鼓励附近节点具有相似的表示,同时强制不同节点的表示高度不同:
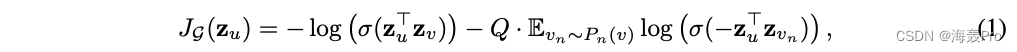
其中
- v v v是在定长随机游走上在 u u u附近共同出现的节点
- σ σ σ是Sigmoid函数
- P n P_n Pn是负采样分布
- Q Q Q定义了负采样的数量
重要的是,与以前的嵌入方法不同,我们馈送到该损失函数的表示 z u z_u zu是从节点的局部邻域中包含的特征生成的,而不是(通过嵌入查找)为每个节点训练唯一的嵌入
此无监督设置模拟将节点功能作为服务或在静态存储库中提供给下游机器学习应用程序的情况
在表示仅用于特定下游任务的情况下,可以简单地用特定于任务的目标(例如,交叉熵损失)来替换或增加非监督损失(公式1)
3.3 Aggregator Architectures
与N-D网格(例如,句子、图像或3-D体积)上的机器学习不同,节点的邻居没有自然的顺序
因此,算法1中的聚集器函数必须在一组无序的向量上操作
理想情况下,聚合器函数应该是对称的(即,不随其输入的排列而变化),同时仍然是可训练的,并保持高的表示能力
聚集函数的对称性保证了我们的神经网络模型可以训练并应用于任意排序的节点邻域特征集
我们研究了三个候选聚合器函数:
Mean aggregator
我们的第一个候选聚集器函数是平均值运算符,其中我们只取 { h u k − 1 , ∀ u ∈ N ( v ) } \{h^{k-1}_u,∀u∈N(v)\} { huk−1,∀u∈N(v)}中向量的元素平均值
平均聚集器几乎等同于在传导GCN框架中使用的卷积传播规则[17]
具体地说,我们可以通过将算法1中的第4行和第5行替换为以下内容来导出GCN方法的归纳变体:
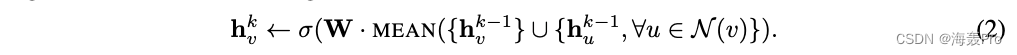
我们称这种修正的基于均值的聚集器为卷积,因为它是局部谱卷积的粗略的线性近似[17]
该卷积聚集器与我们提出的其他聚集器之间的一个重要区别是,它不执行算法1第5行中的级联操作
即,卷积聚集器确实将节点的先前层表示 h v k − 1 h^{k-1}_v hvk−1与聚集的邻域向量 h N ( v ) k h^k_{N(v)} hN(v)k级联
这种串联可以被视为GraphSAGE算法的不同“搜索深度”或“层”之间的“跳过连接”[13]的简单形式,并且它导致显著的性能提升(第4节)
LSTM aggregator
我们还研究了一个基于LSTM架构的更复杂的聚合器[14]
与均值聚集器相比,LSTM具有表达能力更强的优势
然而,重要的是要注意,LSTM本身并不对称(即,它们不是排列不变的),因为它们以顺序的方式处理它们的输入
通过简单地将LSTM应用于节点邻居的随机排列,我们使LSTM适应于在无序集合上操作
Pooling aggregator
我们研究的最终聚合器既是对称的,也是可训练的
在这种池化方法中,每个邻居的向量通过完全连接的神经网络独立馈送
在此转换之后,应用基本的最大池化操作来聚合邻居集合中的信息:
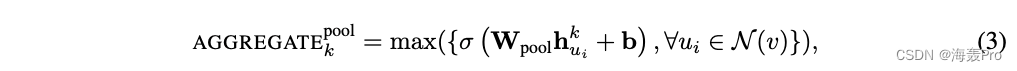
其中
- max表示基于元素的max算子
- 而σ表示非线性激活函数
原则上,在最大值合并之前应用的函数可以是任意深度的多层感知器,但在本文中我们主要关注简单的单层体系结构
这种方法的灵感来自于最近在应用神经网络结构来学习一般点集方面的进步[29]
直观地说,多层感知器可以被认为是为邻居集中的每个节点表示计算特征的一组函数
通过将最大池化算子应用于每个计算的特征,该模型有效地捕获了邻域集合的不同方面
还要注意,原则上,可以使用任何对称向量函数来代替最大运算符(例如,元素式平均值)
我们在开发测试中没有发现最大池化和平均池化之间的显着差异,因此在我们其余的实验中专注于最大池化
4 Experiments
4.1 Inductive learning on evolving graphs: Citation and Reddit data && 4.2 Generalizing across graphs: Protein-protein interactions
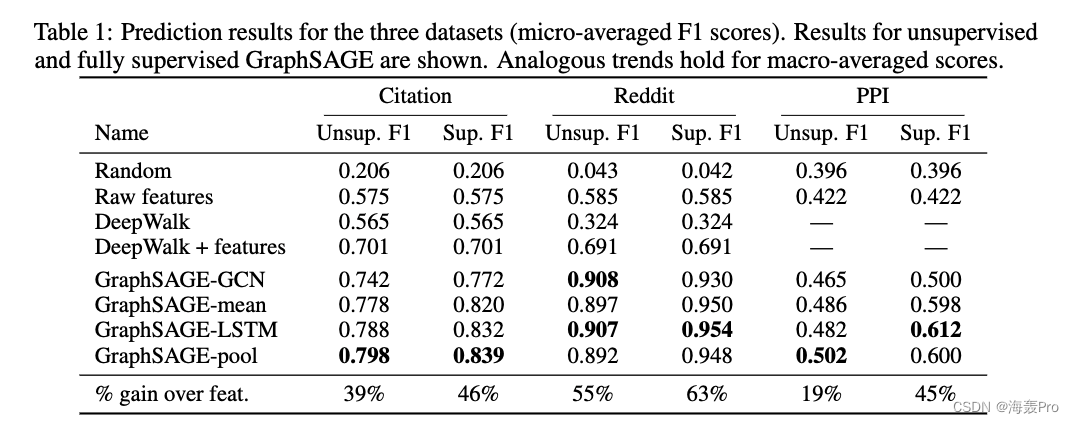
4.3 Runtime and parameter sensitivity
5 Theoretical analysis
略
6 Conclusion
我们介绍了一种新的方法,可以有效地为看不见的节点生成嵌入
GraphSAGE始终优于最先进的基准,通过采样节点邻居有效地权衡了性能和运行时间,我们的理论分析为我们的方法如何了解本地图结构提供了洞察
许多扩展和潜在的改进是可能的,例如扩展GraphSAGE以合并有向图或多模式图
未来工作的一个特别有趣的方向是探索非均匀邻域采样函数,甚至可能将这些函数作为GraphSAGE优化的一部分进行学习
读后总结
下午读了这篇文章 老实说
没有咋看懂 哈哈
还得再认真读读!
借助别人的博客想想
- 来源:https://www.cnblogs.com/BlairGrowing/p/15439876.html





看完后有点懂了
细节方面还是不太懂…
哎 再花些时间再读一遍
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

边栏推荐
- BigDecimal 的正确使用方式
- ROS学习(23)action通信机制
- 张平安:加快云上数字创新,共建产业智慧生态
- Blackfly S USB3工业相机:缓冲区处理
- Processing image files uploaded by streamlit Library
- Mongodb checks whether the table is imported successfully
- centos8 用yum 安装MySQL 8.0.x
- Golang foundation - data type
- How can I code for 8 hours without getting tired.
- 组合导航:中海达iNAV2产品描述及接口描述
猜你喜欢

Dall-E Mini的Mega版本模型发布,已开放下载
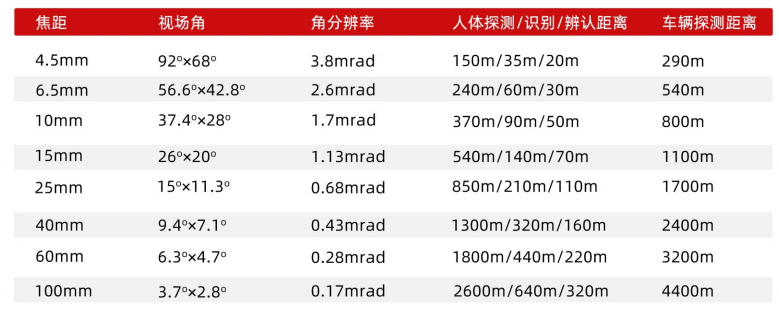
红外相机:巨哥红外MAG32产品介绍
ROS learning (26) dynamic parameter configuration

【唯一】的“万字配图“ | 讲透【链式存储结构】是什么?
ROS学习(25)rviz plugin插件
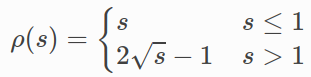
Several classes and functions that must be clarified when using Ceres to slam
Schedulx v1.4.0 and SaaS versions are released, and you can experience the advanced functions of cost reduction and efficiency increase for free!
Batch delete data in SQL - set in entity

【服务器数据恢复】raid损坏导致戴尔某型号服务器崩溃的数据恢复案例

FLIR blackfly s industrial camera: synchronous shooting of multiple cameras through external trigger
随机推荐
Shell script quickly counts the number of lines of project code
Seconds understand the delay and timing function of wechat applet
MetaForce原力元宇宙开发搭建丨佛萨奇2.0系统开发
云原生混部最后一道防线:节点水位线设计
红外相机:巨哥红外MAG32产品介绍
一片叶子两三万?植物消费爆火背后的“阳谋”
Related programming problems of string
Schedulx v1.4.0 and SaaS versions are released, and you can experience the advanced functions of cost reduction and efficiency increase for free!
Metaforce force meta universe development and construction - fossage 2.0 system development
Curl command
蓝桥杯2022年第十三届省赛真题-积木画
Web开发小妙招:巧用ThreadLocal规避层层传值
Redis tool class redisutil (tool class III)
Ros Learning (23) Action Communication Mechanism
Command injection of cisp-pte
机器人队伍学习方法,实现8.8倍的人力回报
Treadpoolconfig thread pool configuration in real projects
Flir Blackfly S 工业相机:配置多个摄像头进行同步拍摄
ROS学习(21)机器人SLAM功能包——orbslam的安装与测试
Chang'an chain learning notes - certificate model of certificate research