当前位置:网站首页>Deformable convolutional dense network for enhancing compressed video quality
Deformable convolutional dense network for enhancing compressed video quality
2022-07-07 14:48:00 【mytzs123】
DEFORMABLE CONVOLUTION DENSE NETWORK FOR COMPRESSED VIDEO QUALITY
ENHANCEMENT
ABSTRACT
Different from traditional video quality enhancement , The goal of compressed video quality enhancement is to reduce the artifacts caused by video compression . The existing multi frame compressed video quality enhancement methods rely heavily on optical flow , Low efficiency , Limited performance . This paper presents a multi frame residual dense network with deformable convolution (MRDN), Improve the quality of compressed video by using high-quality frames to compensate low-quality frames . say concretely , The network is developed by motion compensation (MC) Module and quality enhancement (QE) Module composition , It is used to compensate and enhance the quality of input frames . Besides , A new edge enhancement loss is carried out on the enhanced frame , To enhance the edge structure during training . Last , The experimental results on the public benchmark show that , Our method is superior to the most advanced compressed video quality enhancement method .
1. INTRODUCTION
In order to reduce the required bandwidth and storage space , Video compression algorithms are widely used in many practical applications [1], But these algorithms also bring the problem of video quality degradation . therefore , How to improve the quality of compressed video is a common concern of the research community and the industry . As an important method to reduce compression artifacts , Compressed video quality enhancement includes the elimination of blocking effects 、 Reduce edges / Texture floating as well as noise from mosquitoes ( Uneven or rocking motion is sensed due to frame sampling ) And the technology of reconstructing video in jitter [2]. However , Because details are lost during compression , Therefore, it is a challenge to reconstruct high-quality frames from distorted frames .
lately , Many enhanced compressed images have been proposed / Video quality methods , Especially with the help of deep learning [3、4、5]. Early methods [5、6、7、8] Enhance each frame independently , These methods are simple , But the details of adjacent frames cannot be used . In order to use time information , Yang et al [9] Firstly, a multi frame strategy for compressed video quality enhancement is proposed . From then on , Guan et al [10] The method is further developed by refining key modules . However , Because the video content is compressed, artifacts are seriously distorted , The optical flow method used in most existing multi frame based methods is not reliable . therefore , Enhanced video is far from satisfactory .
Compared with predicting optical flow at the pixel level , Extracting features in the receiving field can enhance the quality of compressed video more robustly . Based on this idea , We propose a multi frame network with deformable convolution [11,12], To realize the motion compensation of multiple moving objects . say concretely , And the traditional deformable convolution network used in video tasks [13、14、15] Different , We develop a new pyramid shaped deformable structure to extract multi-scale alignment information , A new constraint is added to reduce the noise in the reference frame .
Besides , Application of residual dense network in image super-resolution task [16], We have developed a new dense connection network with residual blocks , be called MRDN, To further improve the ability of extracting more hierarchical features , So as to achieve better compressed video quality enhancement . Besides , Through the analysis of compressed video , We find that the quality degradation of compressed video usually occurs at the edge of the object in the video . therefore , An edge enhancement loss is designed , Make the network pay more attention to edge reconstruction
The main contributions of this paper are as follows :(1) A new compressed video quality enhancement method is proposed . This method develops a new pyramid deformation structure with effective motion compensation constraints , And use the remaining dense network to improve the quality ;(2) By analyzing the reasons for the decline of compressed video quality , We have developed a new loss Algorithm to improve the performance of edge reconstruction ;(3) We evaluate this method on the compressed video quality enhancement benchmark database , And achieve the most advanced performance .
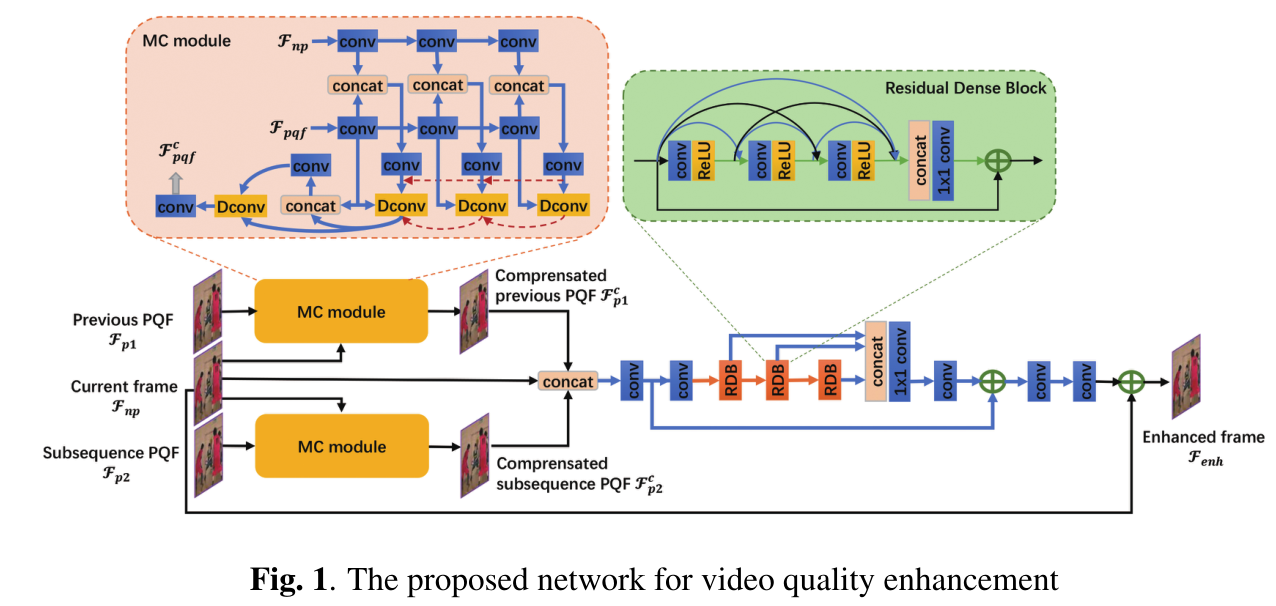
2. THE PROPOSED SYSTEM
2.1. Overview
Different from traditional video quality enhancement , The goal of compressed video enhancement is to reduce or eliminate artifacts and blurring caused by video compression . So , suffer [9] Inspired by the , We propose a method that can utilize peak quality frames (PQF) Multi frame network ∗ therefore , To compensate for low quality frames , Improve the quality of compressed video . Pictured 1 Shown , The network was developed by MC Module and QE Module composition . set up Fnp Represents the current frame ,Fp1 and Fp2 They are the latest previous and subsequent PQF. With PQF(Fp1 or Fp2) Is the reference frame , Based on deformable convolution MC Module to predict time movement , And input frame Fnp Make more detailed compensation . And then , Concatenate the compensated frames into QE Module input , The development of this module aims to further improve the quality of frames . Last , A new edge enhancement loss is carried out on the enhanced frame , To enhance the edge structure during training . Our new MC、QE And edge enhancement loss are described in the following chapters .
2.2. MC module
For the traditional deformable convolutional network in video related tasks , Most learn the offset on the reference frame δ, Then deformable convolution is used to extract the alignment features on the current frame . Obtained with N Pixel alignment feature Fa Defined as :

among F Is the feature of the current frame , In this article, it is defined as Fnp.pi yes F No i A place ,K It's the size of the convolution kernel ,wk It's No K Weight of positions ,pk It's No k Pre specified offset of positions . for example ,pk∈ (−1.−1), (−1, 0), . . . , (1,1) about K=3.
Considering that there are usually multiple moving objects on the frame at the same time , We construct a pyramid structure from multiple deformable convolutions , To extract multi-scale alignment features , And enhance information interaction through cascading . say concretely , The deformable structures of pyramids are 3 layer , Each layer extracts aligned features from the input at different resolutions . The deeper the layer is , The smaller the input resolution . meanwhile , By cascading , The first l Layer offset  And alignment features
And alignment features  And the next level
And the next level  and
and  Merge . Alignment features can be defined as :
Merge . Alignment features can be defined as :

f、 g and h Is to use ReLU Active nonlinear transformation layer , and (·)↑s By factor s Up sampling . In this paper s by 2. Last , Use another convolution layer to predict the compensation frame on the alignment feature .
2.3. QE module
After receiving compensation PQFs( and
and  ) after , need QE The module fuses the information between the compensation frame and the current frame , Further improve the quality of the current frame . In order to improve the QE Long term memory ability of the module , We use parameters
) after , need QE The module fuses the information between the compensation frame and the current frame , Further improve the quality of the current frame . In order to improve the QE Long term memory ability of the module , We use parameters  To extract more hierarchical features . The QE The module concatenates the compensation frame and the current frame as input , Then output the residue
To extract more hierarchical features . The QE The module concatenates the compensation frame and the current frame as input , Then output the residue  . By adding this residual to the current frame , Higher quality frames can be generated
. By adding this residual to the current frame , Higher quality frames can be generated  :
:
![]()
2.4. Loss functions
Edge enhancement loss: In compressed video quality enhancement , Mean square error (MSE) Widely used . However ,MSE Loss can not guide the network to improve the quality of the edge of the object . In order to make the network pay more attention to edge reconstruction , We propose an edge enhancement loss . Given contains N Enhanced frame of pixels And its corresponding original frame  , The edge enhancement loss between them is defined as :
, The edge enhancement loss between them is defined as :
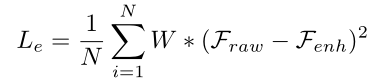

Total Loss:
Different from other video tasks , Compressed video quality enhancement tasks are very sensitive to noise . therefore , We not only optimized qe Parameters of the module θqe, Also on the mc Parameters of the module θmc Added constraints . say concretely , about MC modular , The compensation frame not only needs to provide the alignment result , It should also be preserved with the original frame Fraw Similar quality . about QE modular , Enhanced frame Fenh The quality requirements are as high as the original frame . therefore , The total loss is defined as :
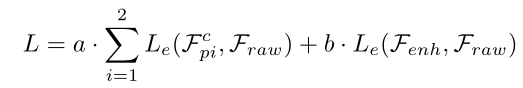
3. EXPERIMENT
3.1. Datasets
In order to train the proposed model , Take advantage of Guan Etc [10]. The database is from Xiph.org Selected in the dataset 160 Composed of uncompressed videos .VGEG And video coding team (JCT-VC)[17], among 106 A video for training . For testing , The proposed model is 18 A standard test video [18] Assessment was carried out on , These videos are collected from JCT-VC, Widely used in video quality evaluation . The above videos are HM 16.5 stay LDP Compress in mode , use 4 Different species QP, namely 22、27、32、37.
3.2. Implementation Details
In the process of training , We use compressed frames and their previous and subsequent PQF As input frame , Then these frames are randomly cropped into 64x64 block . then , Use Adam Optimizer [19] Optimization model , The initial learning rate is 1e-4, The batch size is set to 16. Besides , During training , The loss weights of the motion compensation module and the mass enhancement module are set to 1 and 0.001. stay 100000 After iterations , The weight loss of these two modules will be changed to 0.001 and 1. Be careful , We are QP 22、27、32 and 37 Trained four models . Besides , In order to compare the experimental results more clearly , According to the incremental peak signal-to-noise ratio ( PSNR) And structural similarity (SSIM) Evaluated our method of comparison , These methods measure the difference between the enhanced frame and the original frame PSNR and SSIM Bad .
PSNR) And structural similarity (SSIM) Evaluated our method of comparison , These methods measure the difference between the enhanced frame and the original frame PSNR and SSIM Bad .
3.3. Comparison with state of the art
Quantitative comparison . We compare the proposed method with five most advanced methods ,4PSSNR and 4SSIM Results such as table 1 Shown . In the method of comparison ,ARCNN[5]、DnCNN[6] and RNAN[7] It is a method for quality enhancement of compressed images , They enhance each frame independently , And the performance is limited .MFQE 1.0[9] Put forward a new strategy , That is, search near the current frame PQF, And extract more information from multiple frames . stay MFQE 1.0 On the basis of ,MFQE 2.0[10] By using better PQF Detector and QE modular , Further improved performance . In our work , An effective pyramid shaped deformable structure and residual dense network are developed for multi frame strategy . It can be seen that , Compared with the other five methods , This method achieves better PSNR and SSIM. what's more , about QP 37, We are relative to MFQE 2.0 The improvement is MFQE 2.0 be relative to to MFQE 1.0 Twice as many .
Qualitative comparison:
chart 2 Shows 5 Qualitative comparison of two methods , Obviously , The proposed method can provide higher quality enhanced frames . In an effort to 2 Ball in 、 Take umbrellas and mouths for example , Our method restores clearer object edges and more details . It turns out that , For fast moving objects in video ( Like a ball ), Our pyramid deformation structure can compensate motion more accurately , And in effect QE Under the guidance of module and edge enhancement loss , This model has better performance in object edge reconstruction and detail supplement .


3.4. Effects of the proposed module
Effects of MC module
MC Module is the key part of multi frame strategy , In order to better understand the MC Module and proposed based on deformable convolution MC Differences between modules , We compared the effects of these two modules . We use the optical flow method and the proposed pyramid deformation convolution to train the two models , Results such as table 2 Shown . In the same training strategy and QE Under module , Use our MC The results of the module model have higher quality , It shows that pyramid deformation convolution is more reliable .
Effects of QE module:
QE The module extracts information from its input , Further enrich the details of compressed frames , Its output determines the performance of the whole model . We use universal CNN( be used for MFQE 1.0) And the proposed MRDN Train two models respectively , These models use the same settings and the same MC modular . surface 2 The evaluation results are provided . It can be seen that ,MRDN stay PSNR and SSIM The results obtained on are better than average CNN Higher . It means MRDN The residual dense connection used in makes effective use of feature information , And more than average CNN The super large receiver field used in has better performance .
4. CONCLUSION
In this paper , We propose a new multi frame network for compressed video quality enhancement , The network uses a pyramid shaped deformable structure to compensate for motion , And improve the quality of compressed frames through multi frame residual dense network . Besides , An edge enhancement loss is also designed , For powerful edge reconstruction . The model achieves the most advanced performance on the benchmark database , Model size is 1.32M, Smaller than most comparison methods . The focus of future work is to further reduce the computational complexity .
边栏推荐
猜你喜欢
OAuth 2.0 + JWT protect API security

Data connection mode in low code platform (Part 2)

Internal sort - insert sort
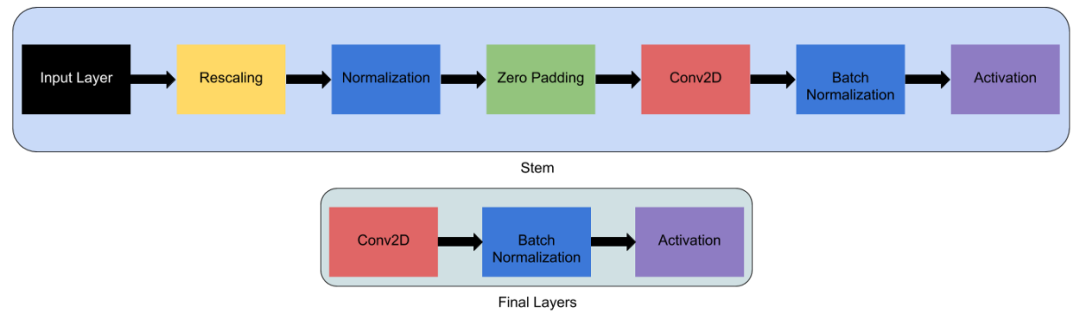
Full details of efficientnet model
Substance Painter笔记:多显示器且多分辨率显示器时的设置
JS get the current time, month, day, year, and the uniapp location applet opens the map to select the location
Wechat applet - Advanced chapter component packaging - Implementation of icon component (I)
用于增强压缩视频质量的可变形卷积密集网络
Substance Painter筆記:多顯示器且多分辨率顯示器時的設置

KITTI数据集简介与使用
随机推荐
解析PHP跳出循环的方法以及continue、break、exit的区别介绍
PyTorch模型训练实战技巧,突破速度瓶颈
在软件工程领域,搞科研的这十年!
Five pain points for big companies to open source
EfficientNet模型的完整细节
Internal sort - insert sort
Leetcode——剑指 Offer 05. 替换空格
AWS learning notes (III)
Today's sleep quality record 78 points
Analysis of arouter
Introduction and use of Kitti dataset
Mrs offline data analysis: process OBS data through Flink job
什么是云原生?这回终于能搞明白了!
设备故障预测机床故障提前预警机械设备振动监测机床故障预警CNC震动无线监控设备异常提前预警
数据湖(九):Iceberg特点详述和数据类型
The method of parsing PHP to jump out of the loop and the difference between continue, break and exit
Ascend 910 realizes tensorflow1.15 to realize the Minist handwritten digit recognition of lenet network
GAN发明者Ian Goodfellow正式加入DeepMind,任Research Scientist
缓冲区溢出保护
Data connection mode in low code platform (Part 2)