当前位置:网站首页>Ut2014 learning notes
Ut2014 learning notes
2022-07-03 10:30:00 【IFI_ rccsim】
3.1 kick
Before : Imitate another agent's existing kick to learn to kick further from a known starting point .
Now? : Take the necessary steps to approach the ball and kick it reliably .
The way to improve : By learning a new Kick in mode Walking parameters .
Purpose : Stop in a small bounding box of the target point , At the same time, ensure that the agent will not exceed the target .
Kick in mode :
“ Kick in mode ” The parameter set is updated according to the following formula X and Y Target walking speed in the direction :

among :maxDecel[X,Y] and buffer The value of is to use CMAES The algorithm is optimized on a task , In this task , The robot goes up to a position where it can kick the ball out . Robots have 12 Seconds to reach the position where you can play football , In the optimization process, you will get the following rewards :

3.2 Pass the ball
Judge the condition : Whether you can kick the ball and score from its current position
Can score : Do it like this
No score : Will be with 10 Kick samples the target with degree direction increment , For all feasible kick direction goals ( Goals that don't kick the ball out of bounds or back too far ), The agent will follow the formula (1) Assign a score to each goal .
For the formula 1 The explanation of : The formula 1 Reward kicks that move the ball towards the opponent's goal , Punishment makes the ball close to the opponent's kick , Also reward kicks close to teammates landing . The formula 1 All distances are in meters . The selected kick direction is the one with the highest score in the target ball position . Contemporary theory approaches the ball (0.8 Within meters ) when , The selected kick direction is fixed , And keep 5 second , To prevent bumps between kicks .
Next : Once an agent decides on a goal, kick it , Then broadcast this goal to his teammates . then , A pair of brokers use “ Kick expectations ”, According to the expected position after the ball is kicked , They run to a position on the court that is conducive to catching the ball . The agents assigned to these expected locations are selected by the dynamic role assignment system .
advantage : Such an agent will play football in anytime Broadcast where it plans to play , Not just close to the ball , As long as you have time to play football instead of dribbling ( No opponent is within two meters of the ball , No opponent is closer to the ball than an agent considering playing ).
By extending the time the agent broadcasts before playing football , Teammates can have More time Run to the expected kicking place , In order to receive the pass from the football agent . in addition ,2014 New teammates avoid interfering with the trajectory of the ball before it is kicked , To prevent them from accidentally blocking the ball .
3.3 Line data location
Previous positioning : Use only for landmarks ( Four corner flags and two goalposts at both ends of the court ) Observation and odometer update .
shortcoming : Sometimes the robot will go out of the boundary near the center of the field , There are no landmarks , Get lost , Never return to the game .
Improvement measures : stay particle filter( Seed filter ) Added in line information( Line information )
Specific implementation : Will observe the longest K The spectral lines are compared with the known positions of all spectral lines in the site . Use the distance between endpoints 、 The acute angle between the lines and the length ratio of the lines are used to determine the similarity between the observed line and each actual line . For each observed line , The highest similarity value is expressed as a probability , And used to update seeds .
result : Because the cable completely surrounds the site , Suppose a robot stands up , It should always be able to see at least one line , If it is currently on the court . If the robot takes a long time (4 second ) Can't see a line , The robot will automatically assume that it has now lost and left the field , In this way, the robot will stop and rotate in place , Until you see a line reposition .
Besides , If the robot can't see any lines , It will broadcast to its teammates that it is not on the field . If any teammate sees a robot that reports that it has not been located , They will broadcast the current status of the unplaced robot x、y Location and (2014 New year added ) Orientation angle , So that it can use the observation of other robots to locate itself . Based on experience , We found that , After incorporating the line data into localization , Our agent is no longer lost when leaving the scene .
4. Main results and analysis
advantage :(1) The kick-off can score (2) Use kick anticipation when passing (3) Use line data
Different types of robots :(1) The legs are long 1 The type and 3 The fastest walking speed is type a (2) With toes 4 Type robot is also relatively fast , It kicks longer and more powerful than other types of robots .
Robots used :(1) Use as much as possible 4 Type a robot (2) Use 0 The type-A robot scores at the kick-off (3)3 Type a robot runs fast (4)1 The robot is used to guard the door , Because its body is bigger , It is conducive to block shooting and good long-distance shooting .
5. Technical challenges
(1) Bench challenge Also known as the task force challenge , It is a proxy team composed of different players randomly selected from the contestants to compete with each other . Each team will send two agents to participate in a reserve team , The substitute's game is 10 Than 10, No goalkeeper . An important aspect of the challenge is that the agent can adapt to the behavior of his teammates .
(2) stay Running challenge in ,7 Robots are given 10 Seconds to run forward as much as possible , Then they were rated according to their average speed and the percentage of time their feet left the ground .
(3) stay Free challenge period , Each group will give a five minute speech on research topics related to their team . then , Each team in the League will rank the top five performances .
边栏推荐
- Advantageous distinctive domain adaptation reading notes (detailed)
- Leetcode刷题---1
- Judging the connectivity of undirected graphs by the method of similar Union and set search
- 2018 y7000 upgrade hard disk + migrate and upgrade black apple
- 20220602 Mathematics: Excel table column serial number
- 20220609 other: most elements
- [LZY learning notes dive into deep learning] 3.5 image classification dataset fashion MNIST
- LeetCode - 715. Range 模块(TreeSet) *****
- Synchronous vs asynchronous
- Leetcode刷题---977
猜你喜欢

Training effects of different data sets (yolov5)

3.2 Off-Policy Monte Carlo Methods & case study: Blackjack of off-Policy Evaluation
A super cool background permission management system
Data classification: support vector machine

What did I read in order to understand the to do list

波士顿房价预测(TensorFlow2.9实践)
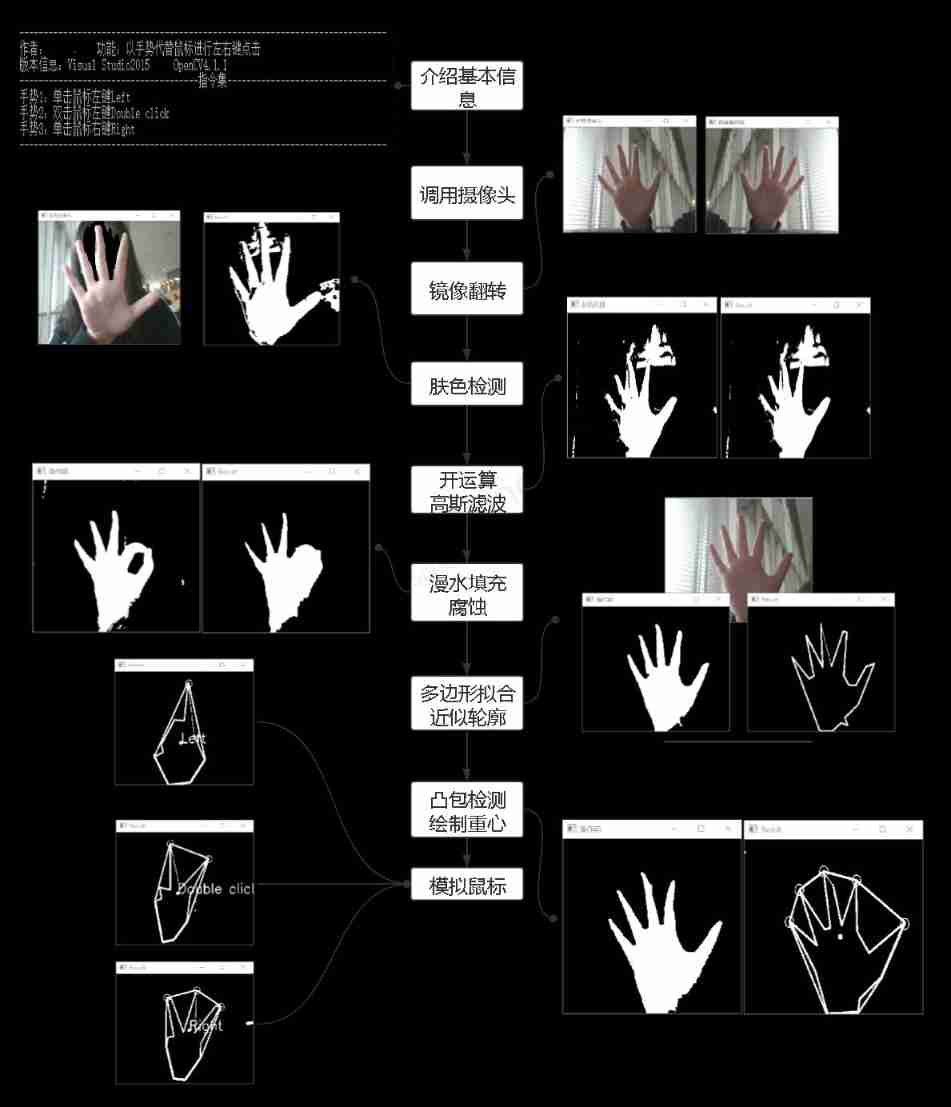
Simple real-time gesture recognition based on OpenCV (including code)

Flutter 退出当前操作二次确认怎么做才更优雅?

CV learning notes - scale invariant feature transformation (SIFT)

CV learning notes ransca & image similarity comparison hash
随机推荐
mysql5.7安装和配置教程(图文超详细版)
Leetcode刷题---283
Tensorflow—Image segmentation
Several problems encountered in installing MySQL under MAC system
3.3 Monte Carlo Methods: case study: Blackjack of Policy Improvement of on- & off-policy Evaluation
20220609 other: most elements
实战篇:Oracle 数据库标准版(SE)转换为企业版(EE)
Hands on deep learning pytorch version exercise solution - 2.4 calculus
Flutter 退出当前操作二次确认怎么做才更优雅?
20220605数学:两数相除
20220604数学:x的平方根
Hands on deep learning pytorch version exercise solution - 2.3 linear algebra
Rewrite Boston house price forecast task (using paddlepaddlepaddle)
20220609其他:多数元素
20220531数学:快乐数
Markdown latex full quantifier and existential quantifier (for all, existential)
20220608其他:逆波兰表达式求值
Tensorflow - tensorflow Foundation
熵值法求权重
LeetCode - 715. Range 模块(TreeSet) *****