当前位置:网站首页>Transparent i/o model from beginning to end
Transparent i/o model from beginning to end
2022-07-07 22:52:00 【Yes' level training strategy】
Hello , I am a yes.
We have understood the previous article socket Inside Communications , Also understand the network I/O There will be many blocking points , Blocking I/O As the number of users increases, more requests can only be processed by adding threads , Threads not only occupy memory resources, but also too many thread competitions will lead to frequent context switching and huge overhead .
therefore , Blocking I/O Can't meet the demand any more , So the big guys in the back continue to optimize and evolve , Put forward a variety of I/O Model .
stay UNIX Under the system , There are five kinds I/O Model , Today we'll have a plate of it !
But in the introduction I/O Before the model , We need to understand the pre knowledge first .
Kernel state and user state
Our computers may run a lot of programs at the same time , These programs come from different companies .
No one knows whether a program running on a computer will go crazy and do some strange operations , Such as clearing the memory regularly .
therefore CPU It is divided into non privileged instructions and privileged instructions , Done permission control , Some dangerous instructions are not open to ordinary programs , It will only be open to privileged programs such as the operating system .
You can understand that our code can't call those that may produce “ dangerous ” operation , The kernel code of the operating system can call .
these “ dangerous ” Operation finger : Memory allocation recycling , Disk file read / write , Network data reading and writing, etc .
If we want to perform these operations , You can only call the... Opened by the operating system API , Also called system call .
It's like we go to the administration hall , Those sensitive operations are handled by official personnel for us ( system call ), So the reason is the same , The purpose is to prevent us from ( Ordinary procedure ) fuck around .
Here are two more nouns :
- User space
- Kernel space .
The code of our ordinary program runs in user space , The operating system code runs in kernel space , User space cannot directly access kernel space . When a process runs in user space, it is in user state , Running in kernel space is in kernel state .
When a program in user space makes a system call , That is, call the information provided by the operating system kernel API when , The context will be switched , Switch to kernel mode , It is also often called falling into kernel state .
Then why introduce this knowledge at the beginning ?
Because when the program requests network data , Need to go through two copies :
- The program needs to wait for the data to be copied from the network card to the kernel space .
- Because the user program cannot access kernel space , So the kernel has to copy the data to user space , In this way, programs in user space can access this data .
Introducing so much is to let you understand why there are two copies , And system calls have overhead , So it's best not to call... Frequently .
Then what we said today I/O The gap between the models is that the implementation of this copy is different !
Today we are going to use read call , That is, read network data as an example to expand I/O Model .
Start !
Synchronous blocking I/O
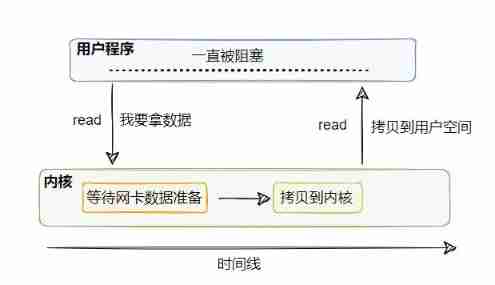
When the thread of the user program calls read When getting network data , First of all, the data must have , That is, the network card must first receive the data from the client , Then the data needs to be copied to the kernel , Then it is copied to user space , This whole process, the user thread is blocked .
Suppose no client sends data , Then the user thread will be blocked and waiting , Until there's data . Even if there's data , Then the process of two copies has to be blocked .
So this is called synchronous blocking I/O Model .
Its advantages are obvious , Simple . call read After that, it doesn't matter , Until the data comes and is ready for processing .
The disadvantages are obvious , One thread corresponds to one connection , Has been occupied , Even if the network card has no data , Also synchronous blocking waiting .
We all know that threads are heavy resources , It's a bit of a waste .
So we don't want it to wait like this .
So there is synchronous non blocking I/O.
Synchronous nonblocking I/O
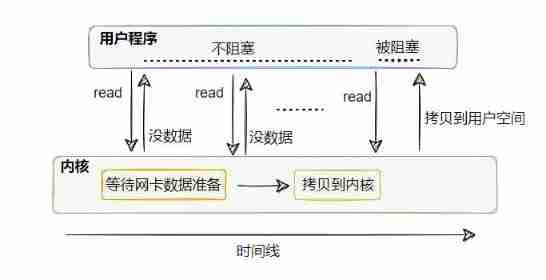
We can clearly see from the picture , Synchronous nonblocking I/O Based on synchronous blocking I/O optimized :
When there is no data, you can no longer wait foolishly , It's a direct return of the error , Inform that there is no ready data !
Pay attention here , Copy from kernel to user space , The user thread will still be blocked .
This model is compared to synchronous blocking I/O Relatively flexible in terms of , For example, call read If there is no data , Then the thread can do other things first , Then continue to call read See if there's any data .
But if your thread just fetches data and processes it , No other logic , Then there is something wrong with this model .
It means you keep making system calls , If your server needs to handle a large number of connections , Then you need a large number of threads to call , Frequent context switching ,CPU Will also be busy , Do useless work and die busy .
What to do with that ?
So there was I/O Multiplexing .
I/O Multiplexing
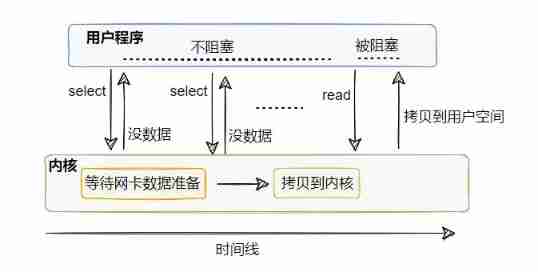
From the picture , It seems to be synchronized with the above non blocking I/O Almost , It's actually different , The threading model is different .
Since synchronization is non blocking I/O It's too wasteful to call frequently under too many connections , Then hire a specialist .
The job of this specialist is to manage multiple connections , Help check whether data on the connection is ready .
in other words , You can use only one thread to see if data is ready for multiple connections .
Specific to the code , This commissioner is select , We can go to select Register the connection that needs to be monitored , from select To monitor whether data is ready for the connection it manages , If you have, Sure Notify other threads to read Reading data , This read Same as before , It will still block the user thread .
So you can Use a small number of threads to monitor multiple connections , Reduce the number of threads , The memory consumption is reduced and the number of context switches is reduced , Very comfortable .
You must have understood what is I/O Multiplexing .
The so-called multi-channel refers to multiple connections , Reuse means that so many connections can be monitored with one thread .
See this , Think again , What else can be optimized ?
Signal driven I/O
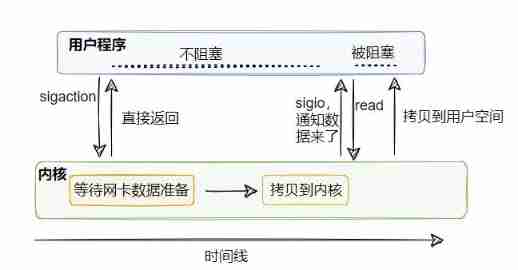
above select Although it's not blocked , But he has to always check to see if any data is ready , Can the kernel tell us that the data has arrived instead of polling ?
Signal driven I/O You can do this , The kernel tells you that the data is ready , Then the user thread goes read( It's still blocking ).
Does it sound better than I/O Multiplexing is good ? Then why do you seem to hear little signal drive I/O?
Why are they all used in the market I/O Multiplexing instead of signal driving ?
Because our applications usually use TCP agreement , and TCP Agreed socket There are seven events that can generate signals .
In other words, it is not only when the data is ready that the signal will be sent , Other events also signal , And this signal is the same signal , So our application has no way to distinguish what events produce this signal .
Then it's numb !
So our applications can't be driven by signals I/O, But if your application uses UDP agreement , That's OK , because UDP Not so many events .
therefore , In this way, for us, signal driven I/O Not really .
asynchronous I/O
Signal driven I/O Although the TCP Not very friendly , But the idea is right : To develop asynchronously , But it's not completely asynchronous , Because the back part read It will still block the user thread , So it's semi asynchronous .
therefore , We have to figure out how to make it fully asynchronous , That is the read That step also saves .
In fact, the idea is very clear : Let the kernel copy the data directly to the user space, and then tell the user thread , To achieve true non blocking I/O!
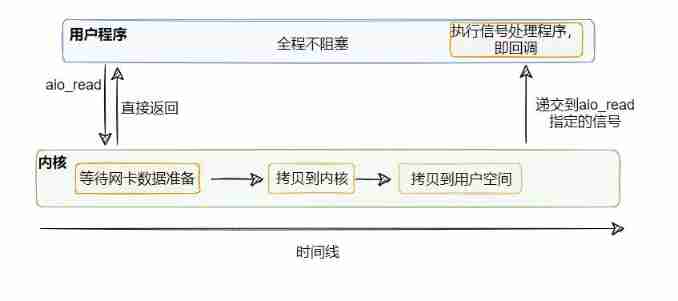
So asynchronous I/O In fact, it is called by the user thread aio_read , Then it includes the step of copying data from the kernel to user space , All operations are done by the kernel , When the kernel operation is complete , Call the callback set before , At this point, the user thread can continue to perform subsequent operations with the data that has been copied to the user control .
In the whole process , The user thread does not have any blocking points , This is the real non blocking I/O.
So here comes the question :
Why do you still use I/O Multiplexing , Not asynchronously I/O?
because Linux For asynchronous I/O Insufficient support for , You can think that it has not been fully realized , So you can't use asynchronous I/O.
Someone here may be wrong , image Tomcat It's all done AIO Implementation class of , In fact, components like these or some class libraries you use seem to support AIO( asynchronous I/O), In fact, the underlying implementation uses epoll Simulated Implementation .
and Windows Is the realization of real AIO, However, our servers are generally deployed in Linux Upper , So the mainstream is still I/O Multiplexing .
Last
thus , You must have known five I/O How the model evolved .
The next part , I'll talk about the Internet I/O Several confusing concepts often accompany : Sync 、 asynchronous 、 Blocking 、 Non blocking .
Reference resources :
- https://time.geekbang.org/column/article/100307
- https://zhuanlan.zhihu.com/p/266950886
I am a yes, From a little bit to a billion , See you next time ~
边栏推荐
- Time convolution Network + soft threshold + attention mechanism to realize residual life prediction of mechanical equipment
- Visual design form QT designer design gui single form program
- Details of the open source framework of microservice architecture
- Aspose. Word operation word document (I)
- JS number is insufficient, and 0 is added
- Revit secondary development - shielding warning prompt window
- LeetCode144. Preorder traversal of binary tree
- Redis集群安装
- Unity technical notes (I) inspector extension
- Remember that a development is encountered in the pit of origin string sorting
猜你喜欢
不夸张地说,这是我见过最通俗易懂的,pytest入门基础教程
Line test - graphic reasoning - 2 - black and white lattice class

PHP method of obtaining image information
Amesim2016 and matlab2017b joint simulation environment construction
「开源摘星计划」Loki实现Harbor日志的高效管理

How to choose the appropriate automated testing tools?
![VTOL in Px4_ att_ Control source code analysis [supplement]](/img/7a/4ce0c939b9259faf59c52da2587693.jpg)
VTOL in Px4_ att_ Control source code analysis [supplement]
Micro service remote debug, nocalhost + rainbow micro service development second bullet
Firefox browser installation impression notes clipping

GBU1510-ASEMI电源专用15A整流桥GBU1510
随机推荐
C development - interprocess communication - named pipeline
Debezium系列之:引入对 LATERAL 运算符的支持
Xcode modifies the default background image of launchscreen and still displays the original image
LeetCode144. Preorder traversal of binary tree
Loki, the "open source star picking program", realizes the efficient management of harbor logs
Form组件常用校验规则-2(持续更新中~)
Ni9185 and ni9234 hardware settings in Ni Max
OpeGL personal notes - lights
Line test - graphic reasoning - 6 - similar graphic classes
GBU1510-ASEMI电源专用15A整流桥GBU1510
Debezium series: source code reading snapshot reader
Robot autonomous exploration series papers environment code
Revit secondary development - Hide occlusion elements
[interview arrangement] 0211 game engine server
Leetcode1984. Minimum difference in student scores
行测-图形推理-8-图群类
Aspose. Word operation word document (I)
Microservice Remote debug, nocalhost + rainbond microservice Development second Bomb
Welcome to CSDN markdown editor
Matplotlib快速入门