当前位置:网站首页>Explain it in simple terms. CNN convolutional neural network
Explain it in simple terms. CNN convolutional neural network
2022-07-07 17:42:00 【SmartBrain】
First , Introduce the source of convolution : It is often used in signal processing , It is used to calculate the delay accumulation of the signal . Suppose a signal generator every moment t Generate a signal xt , The decay rate of information is wk , That is to say k−1 After a time step , The information is original wk times , hypothesis w1 = 1,w2 = 1/2,w3 = 1/4. moment t The signal received yt It is the superposition of the information generated at the current time and the delay information of the previous time .
then , Introduce the birth idea of convolution : stay 80 years ,Fukushima Based on the concept of receptive field, the concept of neurocognitive machine is proposed , It can be seen as The first implementation of convolutional neural network , Neurocognitive machines decompose a visual pattern into many sub patterns ( features ), Then it enters the feature plane connected in a hierarchical manner for processing , It attempts to model the visual system , So that it can be used even when the object has displacement or slight deformation , Can also complete the identification .
Convolutional neural networks (Convolutional Neural Networks, CNN) It's a multilayer sensor (MLP) Variants . Developed by biologists Huber and Wiesel in their early research on the cat visual cortex . There is a complex structure in the cells of the visual cortex . These cells are very sensitive to sub regions of visual input space , We call it receptive field , Tile the whole field of view in this way . These cells can be divided into two basic types , Simple cells and complex cells . Simple cells respond to limbic stimulation patterns within the receptive field to the greatest extent . Complex cells have larger receptive domains , It is locally invariant to stimuli from exact locations .
Usually, neurocognitive machines contain two types of neurons , That is, the sampling element that undertakes feature extraction and the anti deformation convolution element , Two important parameters are involved in the sampling element , Receptive field and threshold parameter , The former determines the number of input connections , The latter controls the degree of response to the characteristic sub pattern . Convolutional neural network can be regarded as a generalization of neurocognitive machine , Neurocognitive machine is a special case of convolutional neural network .
CNN From New York University Yann LeCun On 1998 in .CNN It is essentially a multi-layer perceptron , The key to its success lies in the 【 Sparse connection 】( Local perception ) and 【 Weight sharing 】 The way , On the one hand, the number of weights is reduced, which makes the network easy to optimize , On the other hand, it reduces the risk of over fitting .
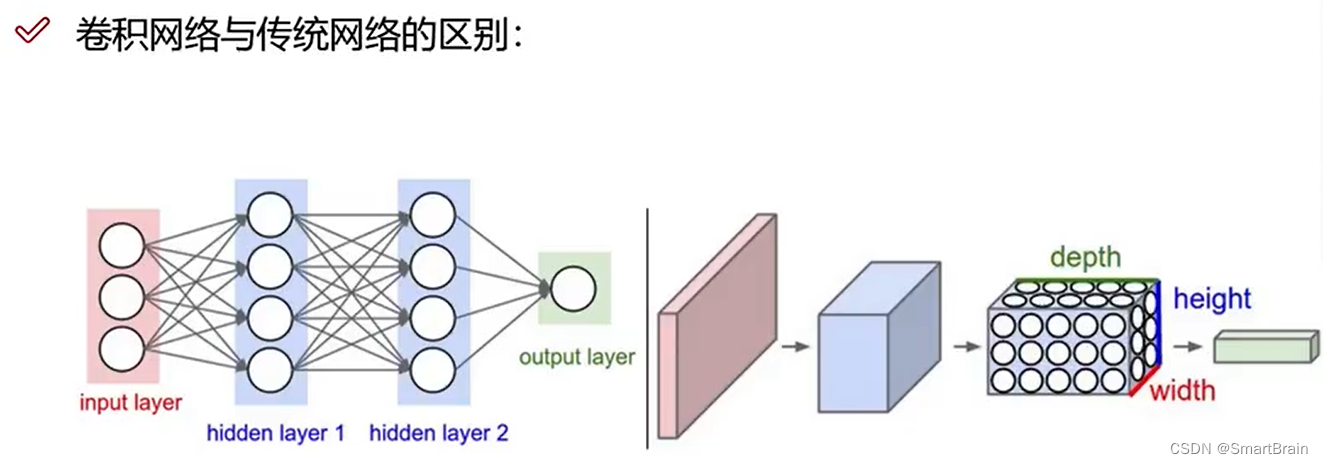
DNN and CNN The differences are shown below : On the left is a 3 Layer of neural network . On the right is a convolutional neural network , In the legend, the network arranges its neurons into 3 Dimensions ( wide 、 Height and depth ). Each layer of convolutional neural network will 3D The input data changes into neurons 3D And output . In this case , The red input layer contains images , So its width and height are the width and height of the image , Its depth is 3( Represents red 、 green 、 blue 3 Color channel ). Convolutional neural network is composed of layers . Each floor has a simple API: Use some derivable functions with or without parameters , Will input 3D The data is transformed into 3D Output data of .
for example :CIFAR-10 The structure of convolutional neural network for image data classification , Its implementation details are as follows :
1. Input [32x32x3] Store the original pixel value of the image , In this example, the width and height of the image are 32, Yes 3 A color channel .
2. In the convolution layer , Neurons are connected to a local area in the input layer , Each neuron calculates the inner product of its own small area connected to the input layer and its own weight . The convolution layer calculates the output of all neurons . If we use 12 A filter ( Also called nuclear ), The dimension of the resulting output data body is [32x32x12].ReLU The layer will activate the function element by element , For example, use to 0 As the activation function of the threshold . This layer does not change the data size , still [32x32x12].
3. The convergence layer is in the spatial dimension ( Width and height ) Downsampling on (downsampling) operation , The data size becomes [16x16x12].
4. The full connection layer will calculate the classification score , The data size becomes [1x1x10], among 10 A number corresponds to CIFAR-10 in 10 Classification score value of categories . As its name suggests , The full connection layer is the same as the conventional neural network , Each of these neurons is connected to all neurons in the previous layer .
Why use three-dimensional convolutional neural network to solve the problem of two-dimensional image feature extraction ?
Convolutional neural networks (Convolutional Neural Network,CNN) Is a method with local connection 、 Deep feedforward neural network with weight sharing and other characteristics . Convolutional neural network was first mainly used to process image information . If we use the traditional fully connected feedforward network When processing images , There are two problems :
(1) Too many parameters : If the input image size is 100 × 100 × 3( That is, the image height is 100, Width is 100,3 A color channel :RGB). In a fully connected feedforward network , Each neuron in the first hidden layer has... To the input layer 100 × 100 × 3 = 30, 000 Two independent connections , Each connection corresponds to a weight parameter . With the increase of the number of neurons in the hidden layer , The size of the parameters will also increase dramatically . This will cause the training efficiency of the whole neural network to be very low , It's also easy to have fitting .
(2) Local invariance feature : All objects in natural images have local invariance , For example Scaling 、 translation 、 Operations such as rotation do not affect its semantic information . However, the fully connected feedforward network is difficult to extract These locally invariant features , Data enhancement is generally required to improve performance . Convolutional neural network is proposed by the mechanism of biological receptive field . Feel the field (Receptive Field) Mainly refers to hearing 、 The properties of some neurons in the nervous system, such as vision , That is, neurons only accept their branches The signal in the matched stimulation area . In the visual nervous system , The output of nerve cells in the visual cortex depends on It depends on photoreceptors in the retina . When photoreceptors on the retina are stimulated , Send nerve impulses The number is transmitted to the visual cortex , But not all neurons in the visual cortex will receive these signals . The receptive field of a neuron is a specific area of the retina , Only stimulation in this area can activate the neuron .
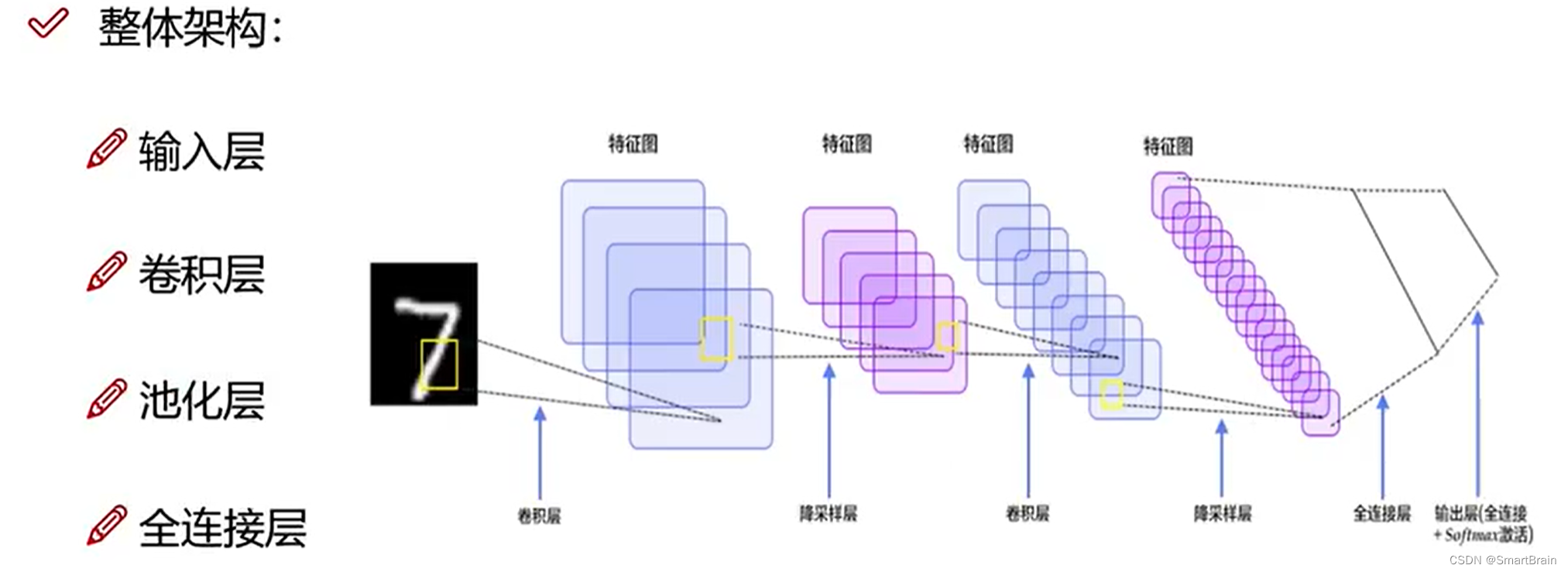
At present, convolutional neural networks are generally composed of convolutional layers 、 The convergence layer and the full connection layer are cross stacked Feedforward neural networks , Use the back propagation algorithm to train . Convolutional neural networks have three structural characteristics sex : Local connection , Weight sharing and aggregation . These characteristics make convolutional neural network have a certain degree Translation of 、 Scale and rotation invariance . Compared with feedforward neural networks , Convolutional neural network has fewer parameters . Convolutional neural networks are mainly used in various tasks of image and video analysis , Like image classification 、 people Face recognition 、 Object recognition 、 Image segmentation, etc , Its accuracy is generally far beyond that of other neural networks Model .
The convolution layer ?
Originally, it is to separate the features in the input and turn them into new feature map, Each output channel is a feature extracted by a convolution operation . In the process ReLU Activation acts as a filter , Remove the negative correlation feature points , Leave the positive correlation . The more channels output, the more features are processed , But there may also be repetitive features , After all, it is a probability problem . The overall framework : Four layer treatment , Convolution feature extraction , Pooled compression feature .
We often see that the number of channels in convolutional neural networks increases , such as 227*227*3 Color image of , After a layer of convolution, the output data size becomes 55*55*96, The number of channels increases . This is because the input data is 96 A dimension for 11*11*3, In steps of 4 Different convolution kernels perform convolution operations , Each dimension of input data is 11*11*3, In steps of 4 Convolution kernel , There will be a 55*55*1 The data of , When passing by 96 After convolution , The number of channels becomes 96, The number of channels increases .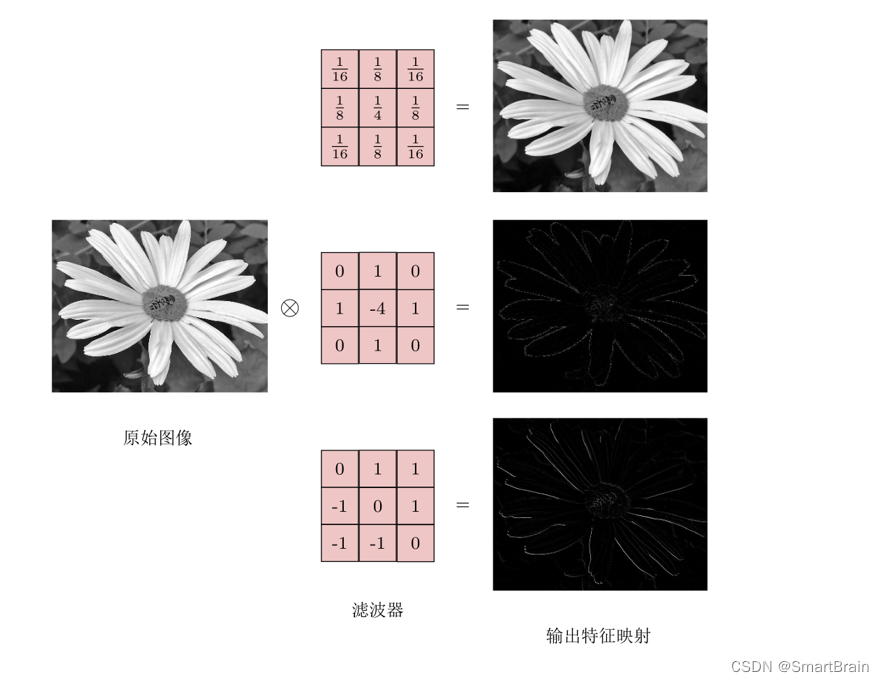
Convolution is actually three-dimensional . We have to raise this idea to another dimension . Our data now is not a column , It's not a vector , Not a feature , But a cuboid , It is a rectangular matrix , It is a three-dimensional . So next we have to deal with the data , It is a three-dimensional ,H ride W Take one C Of .

What is a convolution ?
Convolution is the lifting feature , Pooling is a compression feature .CNN The number of convolution kernel channels = The number of channels in the convolution input layer ;CNN The number of convolution output layer channels ( depth )= The number of convolution kernels
In the calculation of convolution , Suppose the input is H x W x C, C Is the depth entered ( The number of channels ), So convolution kernel ( filter ) The number of channels must be the same as the number of input channels , So also for C, Suppose that the size of the convolution kernel is K x K, A convolution kernel is K x K x C, The corresponding channel of convolution kernel shall be applied to the corresponding channel of input during calculation , When such a convolution kernel is applied to the input, a channel of the output is obtained . Suppose there is P individual K x K x C Convolution kernel , In this way, each convolution kernel applied to the input will get a channel , So the output has P Channels .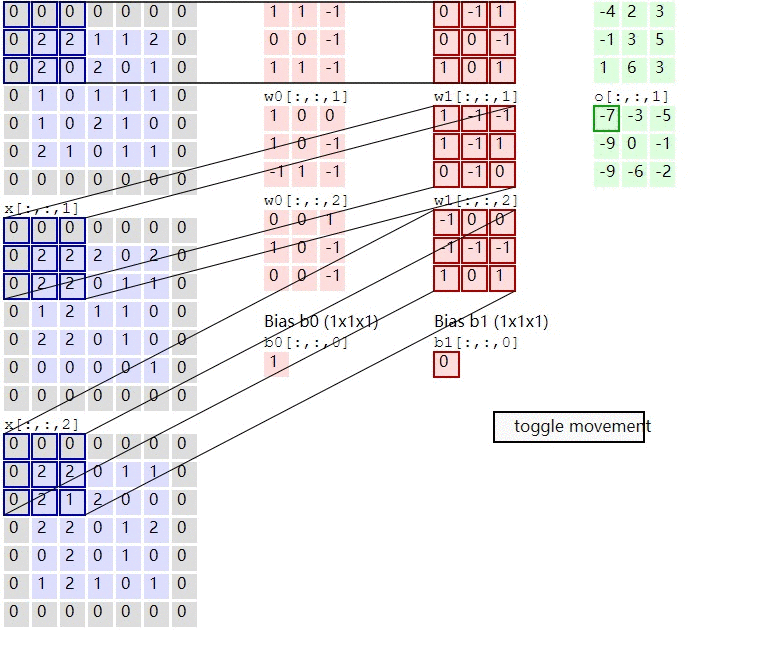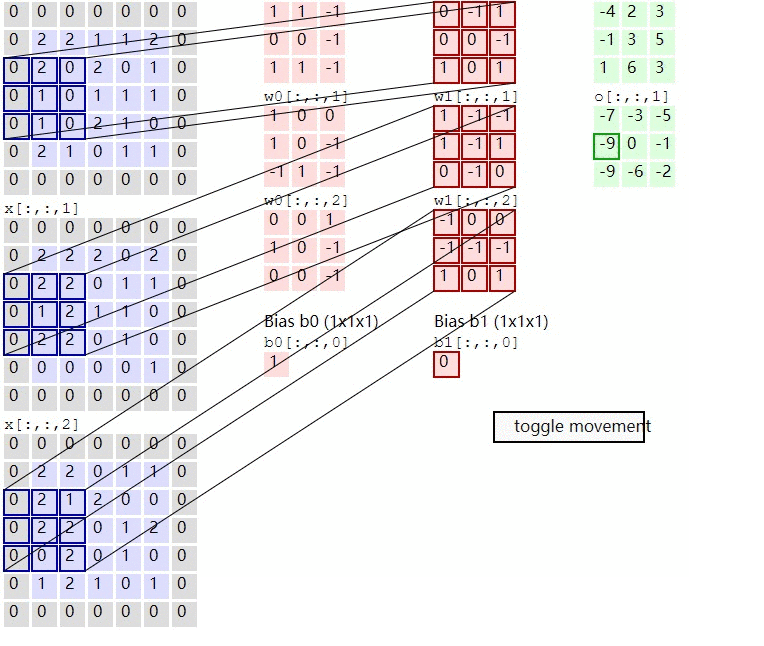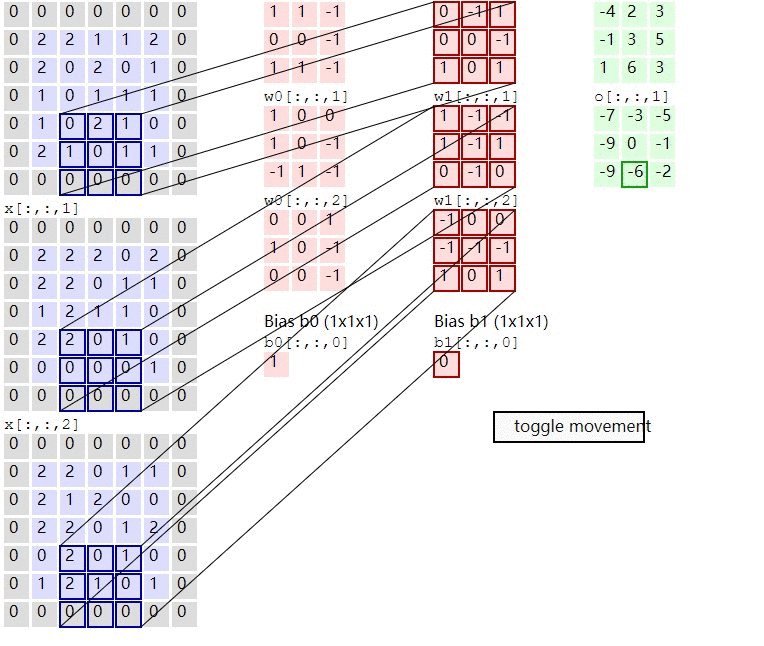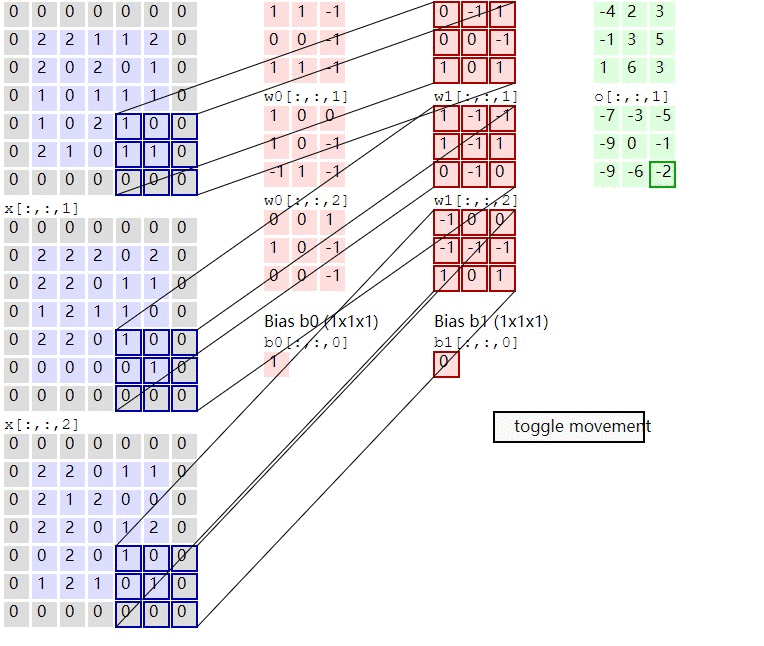
Convolution definition is explained with images : To image ( Different data window data ) And filter matrix ( A set of fixed weights : Because multiple weights of each neuron are fixed , So it can be seen as a constant filter filter) do Inner product ( Multiply and sum one by one ) The operation of is called 『 Convolution 』 operation , It's also the name of convolutional neural network .
Not strictly speaking , The part in the red frame in the figure below can be understood as a filter , That is, neurons with a set of fixed weights . Multiple filters are added to form a convolution layer . In the convolution layer, the weight of each neuron connection data window is fixed , Each neuron focuses on only one characteristic . Neurons are filters in image processing , For example, special for edge detection Sobel filter , That is, each filter in the convolution layer will have an image feature of its own concern , Like the vertical edge , The level of the edge , Color , Texture and so on , All these neurons add up to a feature extractor set of the whole image .
This is the most complicated situation , Almost many practical applications can correspond to this problem , Are doing such a thing
1) The input corresponds to rgb picture
2) Once the number of input characteristic graphs is multiple , This time each group filter It should be multiple , And here are two groups filter
3) The input is three characteristic graphs , Output as two characteristic graphs , So let's also look at how each characteristic graph is calculated .
LeNet-5
It is a very successful neural network model . be based on LeNet-5 Handwritten numeral recognition system in 90 It was used by many American banks in the s , Used to identify handwritten digits on checks .LeNet-5 share 7 layer .
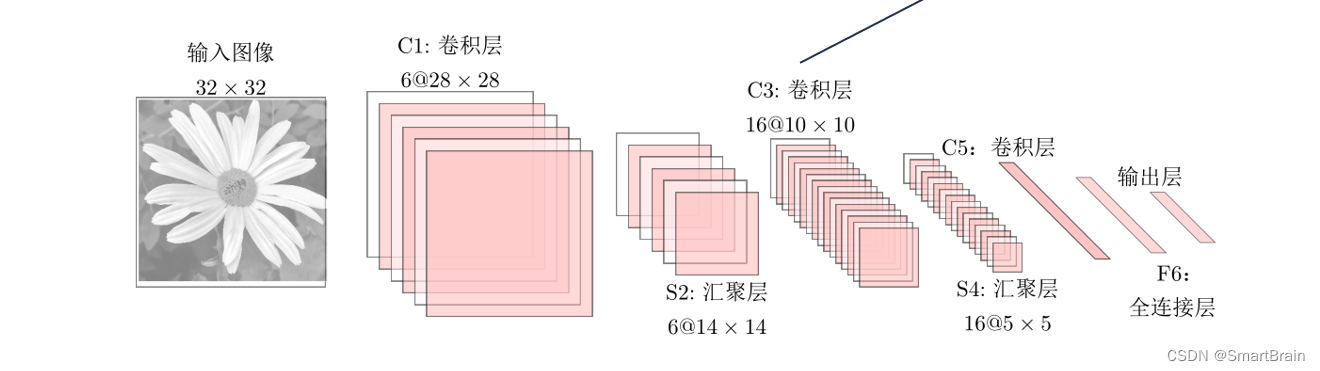
Input layer : The input image size is 32 × 32 = 1024.
C1 layer : This layer is the convolution layer . The size of the filter is 5×5 = 25, share 6 A filter . obtain 6 The group size is 28 × 28 = 784 Feature mapping of . therefore ,C1 The number of neurons in the layer is 6 × 784 = 4,704. The number of trainable parameters is 6 × 25 + 6 = 156. The number of connections is 156 × 784 = 122,304( Including offset , The same below ).
S2 layer : This layer is the sub sampling layer . from C1 Layer in each set of feature mapping 2 × 2 The sub sampling of neighborhood points is 1 A little bit , That is to say 4 The average number of .
AlexNet
It is the first modern deep convolution network model , For the first time, many techniques and methods of modern deep convolution networks are used
Use GPU Train in parallel , Adopted ReLU As a nonlinear activation function , Use Dropout Prevent over fitting , Usage data enhancement 5 Convolution layers 、3 Convergence layer and 3 All connection layers , The results are as follows :
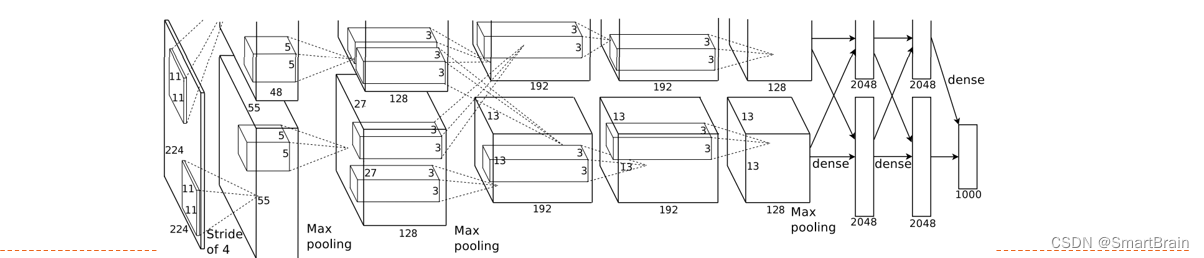
Summarized below :
Convolution network is composed of convolution layer 、 Convergence layer 、 The whole connection layer is cross stacked . Tends to be small convolution 、 Big depth , Tends to be fully convoluted
The typical structure is as follows :

A convolution block is continuous M Convolutions and b A convergence layer (M Usually set to 2 ∼ 5,b by 0 or 1). A convolution network can be stacked N A continuous convolution block , And then K All connection layers (N The value range of is relatively large , such as 1 ∼ 100 Or bigger ;K It's usually 0 ∼ 2).
边栏推荐
猜你喜欢
Functions and usage of viewswitch
Self made dataset in pytoch for dataset rewriting
运行yolo v5-5.0版本报错找不到SPPF错误,进行解决
Function and usage of numberpick

【TPM2.0原理及应用指南】 16、17、18章

【OKR目标管理】案例分析
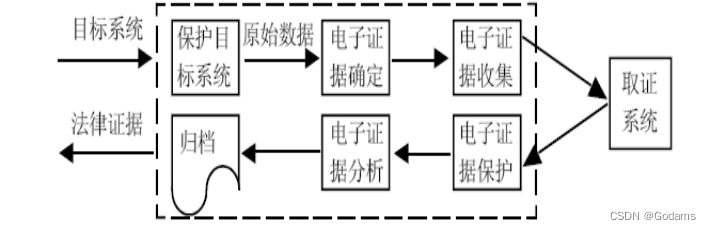
【信息安全法律法規】複習篇
textSwitch文本切换器的功能和用法
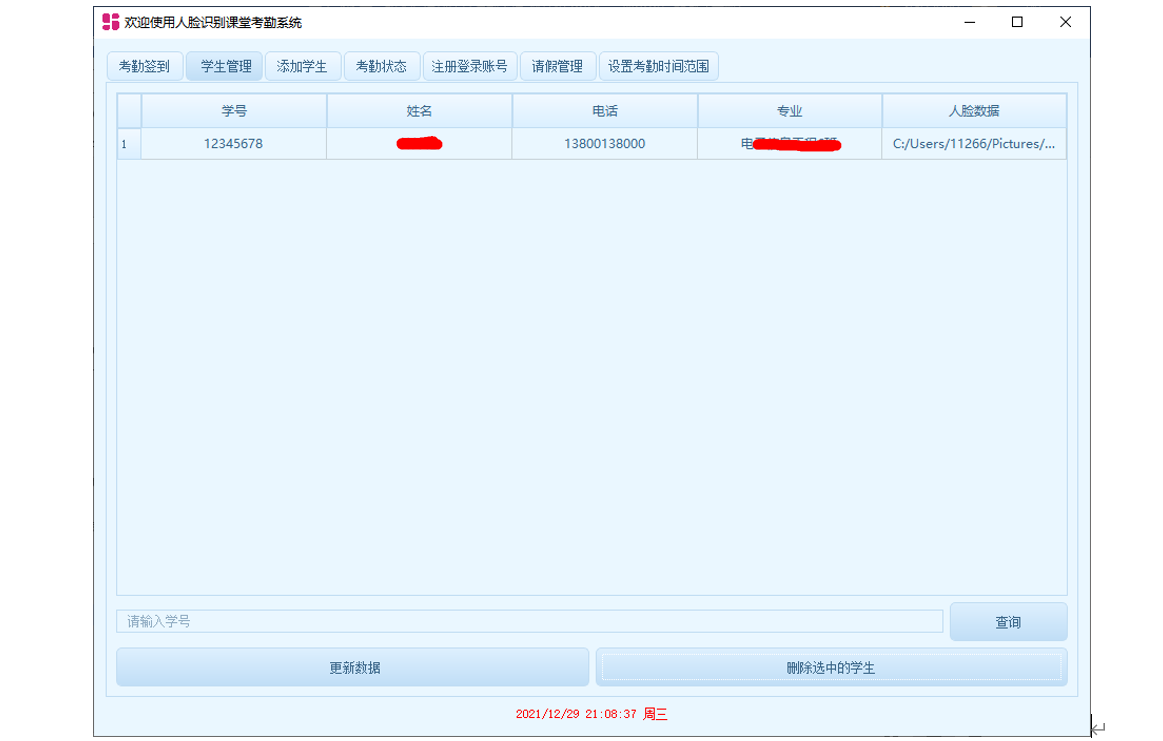
Face recognition attendance system based on Baidu flying plasma platform (easydl)
2021-06-28
随机推荐
Mysql 索引命中级别分析
Notification is the notification displayed in the status bar of the phone
TabHOST 选项卡的功能和用法
swiper左右切换滑块插件
Function and usage of calendar view component
阿富汗临时政府安全部队对极端组织“伊斯兰国”一处藏匿点展开军事行动
在窗口上面显示进度条
【分布式理论】(二)分布式存储
命令模式 - Unity
做软件测试 掌握哪些技术才能算作 “ 测试高手 ”?
基于百度飞浆平台(EasyDL)设计的人脸识别考勤系统
Please insert the disk into "U disk (H)" & unable to access the disk structure is damaged and cannot be read
Devops' operational and commercial benefits Guide
数值 - number(Lua)
简单的loading动画
【深度学习】3分钟入门
Pro2:修改div块的颜色
深入浅出【机器学习之线性回归】
机器人工程终身学习和工作计划-2022-
手机app外卖订餐个人中心页面