当前位置:网站首页>Project deployment (I): selection of mobile operators
Project deployment (I): selection of mobile operators
2022-07-08 02:20:00 【pogg_】
Preface : This article was first published in GiantPandaCV, Please do not reprint without permission
This blog stems from previous discussions with friends , Deploy on the end side 、 On the board with less computing power , Generally like to use Relu and LeakyReLU Activation function , And what we often say is similar Sigmoid,Mish What does function overhead mean ? This blog will analyze from the experimental level , I learned from scratch before CV One activation function :https://zhuanlan.zhihu.com/p/380237014 Extension of .
The following are just personal opinions , If there is something wrong , Welcome the criticism that .
One 、 Activation function
For the detailed explanation of the activation function , There are too many materials on the Internet , In our daily work , Frequently seen activation functions are relu, leakyrelu, sigmoid, swish, hardswish, selu, mish wait . Give a few common examples , about YOLO series ,YOLOv3 The activation function used is LeakyReLU,YOLOv4 Through Mish Function to improve model performance , But it brings high expenses ,YOLOv5 The author uses SiLU function 1, As a balance between speed and accuracy .
It can be said that different activation functions bring different gains , But it doesn't mean that the greater the cost , The more expensive the calculation, the activation function must be the most work, Borrow one here v5s Compare the ablation maps of different activation functions :
The picture above is in v5 Of issue See a chart in which the author compares the performance of different activation functions , You can see , although Mish Functions are expensive , But for the v5s For such small models , The gain is not optimal , by comparison ,swish The effect of function recurrence is more than Mish function , meanwhile ,Swish Functions are also better than Mish Function is fast 15-20%:
Test on Nvidia A100 - From oneflow zzk
The picture above shows A100 On the video card , Different activation functions latency and Bandwidth Comparison of .
Two 、 Comparison of the underlying operators of the activation function
But this blog wants to compare the model deployment , The performance of different operators is different , We call ncnn Test the underlying operators of the forward reasoning framework .
Before comparison , In order to ensure Mat Randomness of parameter input , We use only 5 Convolutions and 3 A pooled layer model performs point multiplication on parameters , Then the output result is sent to the activation function operator for operation :
static int init_net3x3(ncnn::Net* net, int* target_size)
{
net->opt.num_threads = 4;
//Test for multi thread
int ret = 0;
const char* net_param = "5xConv3x3x128.param";
const char* net_model = "5xConv3x3x128.bin";
*target_size = 224;
ret = net->load_param(net_param);
if (ret != 0)
{
return ret;
}
ret = net->load_model(net_model);
if (ret != 0)
{
return ret;
}
return 0;
}
static ncnn::Mat forward_net3x3(const cv::Mat& bgr, int target_size, ncnn::Net* net)
{
int img_w = bgr.cols;
int img_h = bgr.rows;
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, bgr.cols, bgr.rows, target_size, target_size);
ncnn::Extractor ex = net->create_extractor();
ex.input("input.1", in);
ncnn::Mat out;
ex.extract("18", out);
return out;
}
next , We send the calculated random parameters into the bottom operator of the activation function for calculation :
static int ReLU(const ncnn::Mat& bottom_top_blob, const ncnn::Option& opt)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q = 0; q < channels; q++)
{
ncnn::Mat ptr = bottom_top_blob.channel(q);
for (int i = 0; i < size; i++)
{
// fprintf(stderr, "Tensor value: %f ms \n", ptr.channel(q)[i]);
if (bottom_top_blob.channel(q)[i] < 0)
{
ptr.channel(q)[i] = 0;
}
}
}
return 0;
}
static int Swish(const ncnn::Mat& bottom_top_blob, const ncnn::Option& opt)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q = 0; q < channels; q++)
{
ncnn::Mat ptr = bottom_top_blob.channel(q);
for (int i = 0; i < size; i++)
{
float x = ptr[i];
ptr[i] = static_cast<float>(x / (1.f + expf(-x)));
}
}
return 0;
}
/* ...The content is too long, omit the remaining 100 lines of code... */
We are Inter [email protected] For each activation function operator 10 Ten thousand times of reasoning , The input parameter quantity is 33128, Calculate a single reasoning Latency, And draw a histogram :
int main(int argc, char** argv)
{
int target_size = 224;
ncnn::Net net3x3;
int ret = init_net3x3(&net3x3, &target_size);
cv::Mat m = cv::imread("C:/Users/chen/Desktop/3dd980d7f22fd0607c80f5ebc2c1c2e.jpg", 1);
ncnn::Mat out = forward_net3x3(m, target_size, &net3x3);
ncnn::Option opt;
opt.num_threads = 1;
int forward_times = 100000;
double tanh_start = GetTickCount();
for (int i = 0; i < forward_times; i++)
Tanh(out, opt);
double tanh_end = GetTickCount();
fprintf(stderr, "Forward %d times. Tanh cost time: %.5f ms \n", forward_times, (tanh_end - tanh_start));
/* ...The content is too long, omit the remaining 100 lines of code... */
return 0;
}
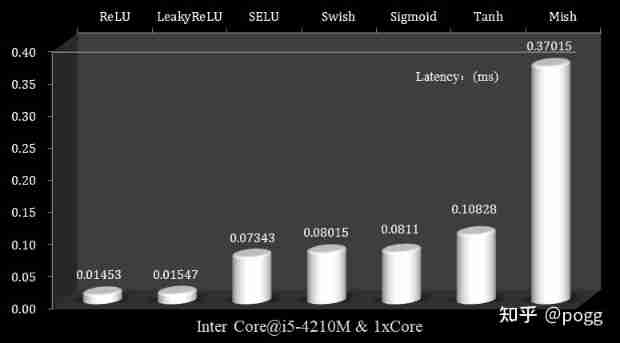
It can be seen that ,ReLU and LeakyReLU It takes the least time , and Mish Functions take the longest , And far more than other activation functions , With ReLU and LeakyReLU As a benchmark , We can see that the complexity of these two functions is constant , That is, only a single operation of addition, subtraction, multiplication and division :
ReLU Functional expression :

LeakyReLU Functional expression :
The image of two operators :
Left for ReLU, The right to LeakyReLU.
Mish Functional expression :

Function image :
More Than This , We expand the parameter quantity to the original 4 times (331024), Conduct 10 Ten thousand times forward, Get every inference Latency:
You can see , The number of Dangshen increased , The delay ratio between exponential activation function and constant activation function will be larger and larger , When the parameter quantity is 33128 when ,
And the parameter value turns to 4 Times :

When the number of input parameters increases , Single forward reasoning floating point operation increase , Functions take up more memory , The direct impact is that the overclocking function of the board is unstable , Maybe friends who have played board know , Memory frequency directly affects the bandwidth of the computing platform , The function / The efficiency of the model is limited by the bandwidth resources of the board or computing platform , This may also be the reason why the operation efficiency of exponential operation is slightly affected after the input parameters are greatly increased .
The following figure shows the memory occupied by different activation functions :

about ReLU and LeakyReLU Wait for the activation function , It is the most common deployment in lightweight networks and mobile terminals ( I haven't seen it yet Mish Function's lightweight network ), One side , As a constant order operator , Low time delay , Fast calculation ; On the other hand , It does not involve a large number of complex operation instructions such as exponential operation , Operator for dealing with parameter inflation , Also able to deal with , It is very suitable for the board with extremely scarce computing resources .
边栏推荐
- leetcode 873. Length of Longest Fibonacci Subsequence | 873. 最长的斐波那契子序列的长度
- 云原生应用开发之 gRPC 入门
- XXL job of distributed timed tasks
- 科普 | 什么是灵魂绑定代币SBT?有何价值?
- metasploit
- Ncnn+int8+yolov4 quantitative model and real-time reasoning
- [knowledge atlas paper] minerva: use reinforcement learning to infer paths in the knowledge base
- Literature reading and writing
- Deep understanding of softmax
- Mqtt x newsletter 2022-06 | v1.8.0 release, new mqtt CLI and mqtt websocket tools
猜你喜欢

mysql报错ORDER BY clause is not in SELECT list, references column ‘‘which is not in SELECT list解决方案

"Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.2 data preprocessing_ Learning thinking and exercise answers

力争做到国内赛事应办尽办,国家体育总局明确安全有序恢复线下体育赛事

Many friends don't know the underlying principle of ORM framework very well. No, glacier will take you 10 minutes to hand roll a minimalist ORM framework (collect it quickly)
![[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview](/img/45/5f14454267318bb404732c2df5e03c.jpg)
[reinforcement learning medical] deep reinforcement learning for clinical decision support: a brief overview

Deep understanding of softmax
JVM memory and garbage collection-3-object instantiation and memory layout
![[knowledge map] interpretable recommendation based on knowledge map through deep reinforcement learning](/img/62/70741e5f289fcbd9a71d1aab189be1.jpg)
[knowledge map] interpretable recommendation based on knowledge map through deep reinforcement learning
A comprehensive and detailed explanation of static routing configuration, a quick start guide to static routing

metasploit
随机推荐
力扣6_1342. 将数字变成 0 的操作次数
Alo who likes TestMan
实现前缀树
Thread deadlock -- conditions for deadlock generation
From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
"Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.2 data preprocessing_ Learning thinking and exercise answers
Dnn+yolo+flask reasoning (raspberry pie real-time streaming - including Yolo family bucket Series)
【每日一题】736. Lisp 语法解析
Semantic segmentation | learning record (5) FCN network structure officially implemented by pytoch
In the digital transformation of the financial industry, the integration of business and technology needs to go through three stages
Semantic segmentation | learning record (3) FCN
CV2 read video - and save image or video
Relationship between bizdevops and Devops
Emqx 5.0 release: open source Internet of things message server with single cluster supporting 100million mqtt connections
Principle of least square method and matlab code implementation
分布式定时任务之XXL-JOB
PHP calculates personal income tax
idea窗口不折叠
Learn face detection from scratch: retinaface (including magic modified ghostnet+mbv2)
MQTT X Newsletter 2022-06 | v1.8.0 发布,新增 MQTT CLI 和 MQTT WebSocket 工具