当前位置:网站首页>A detailed explanation of ASCII code, Unicode and UTF-8
A detailed explanation of ASCII code, Unicode and UTF-8
2022-07-05 13:12:00 【UPythonFish】
List of articles
One ASCII code
Inside the computer , All information is ultimately a binary value . Every binary bit (bit) Yes 0 and 1 Two kinds of state , So eight binary bits can be combined 256 States , This is called a byte (byte). in other words , A byte can be used to represent 256 Different states , Each state corresponds to a symbol , Namely 256 Symbols , from 00000000 To 11111111.
Last century 60 years , The United States has developed a set of character codes , The relationship between English characters and binary bits , Made a unified regulation . This is known as ASCII code , It has been used up to now .
ASCII The code is specified 128 Character encoding , Such as the blank space SPACE yes 32( Binary system 00100000), Capital letters A yes 65( Binary system 01000001). this 128 Symbols ( Include 32 A control symbol that can't be printed ), It only takes up the end of one byte 7 position , The first one is uniformly defined as 0.
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
|---|---|---|---|---|---|---|---|
| The unified stipulation is 0 | 0 or 1 | 0 or 1 | 0 or 1 | 0 or 1 | 0 or 1 | 0 or 1 | 0 or 1 |
Two Not ASCII code
If only English , use 128 A symbol code is enough , But for other languages ,128 A symbol is not enough .
such as , In French , There are phonetic symbols above the letters , It won't work ASCII Code said .
therefore , Some European countries decided to , Use the highest bit of the byte to program the new symbol .
such as , In French é The code of is 130( Binary system 10000010).
thus , The coding system used by these European countries , Can mean at most 256 Symbols .
however , There are new problems .
Different countries have different letters , therefore , Even if they all use 256 The encoding of symbols , The letters are different .
such as ,130 In French coding, it stands for é, In Hebrew code, it stands for the letters Gimel (ג), In Russian code, it will represent another symbol .
But anyway , Of all these coding methods ,0–127 The symbols are the same , It's just that 128–255 This part of .
As for the words of Asian countries , More symbols are used , There are as many Chinese characters as 10 All around .
A byte can only represent 256 Symbols , It must not be enough , You have to use more than one byte to express a symbol .
such as , The common encoding method of simplified Chinese is GB2312, Use two bytes to represent a Chinese character , So in theory, it can at most express 256 x 256 = 65536 Symbols
3、 ... and Unicode
There are many ways of coding in the world , The same binary number can be interpreted as different symbols .
therefore , To open a text file , You have to know how it's encoded , Otherwise, read it in the wrong way , There will be chaos .
This is why files are often garbled , Because the encoding method used for encoding and decoding is different
As you can imagine , If there's a code , Include all the symbols in the world . Each symbol is given a unique code , Then the confusion will disappear .
This is it. Unicode, It's like its name means , It's a code for all the symbols .
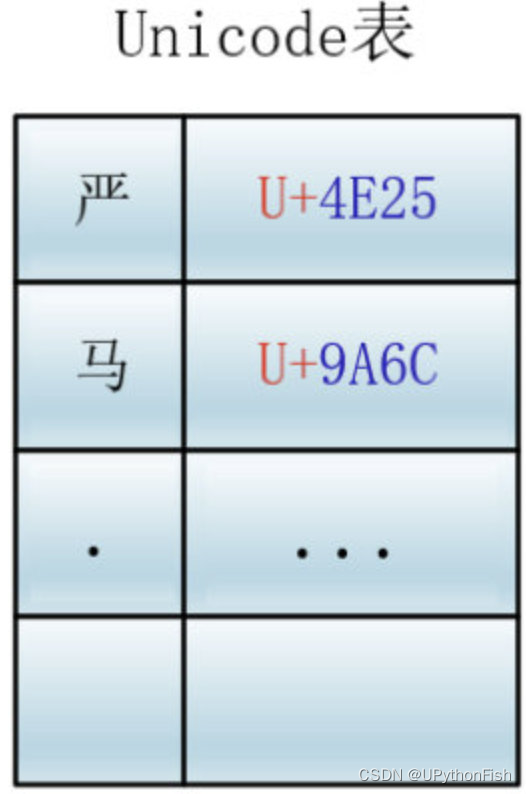
Unicode All characters in the world are assigned a unique numeric number , This number ranges from 0x000000 To 0x10FFFF ( Hexadecimal ), Yes 110 More than ten thousand , Each character has a unique Unicode Number , This number is usually written as 16 Base number , Add in front U+. for example :
U+9A6C Representing Chinese character horse ,
U+4E25 It means Chinese characters are strict
U+0639 For Arabic letters Ain,
U+0041 A capital letter for English A,
Unicode It's like a table , The connection between characters and numbers is established
3.1 Unicode The problem is
Unicode It's just a set of symbols , It only specifies the binary code of the symbol , It doesn't specify how the binary code should be stored .
such as , The Chinese characters are strict Unicode It's a hexadecimal number 4E25, Conversion to binary is enough 15 position (100111000100101), in other words , The representation of this symbol requires at least 2 Bytes . Other larger symbols , You may need to 3 Bytes or 4 Bytes , Even more .
There are two serious problems :
** Question 1 :** How to distinguish Unicode and ASCII ? How do computers know that three bytes represent a symbol , Instead of three symbols ?
** Question two :** Only one byte is enough for English letters , If Unicode Uniform rules , Each symbol is represented by three or four bytes , Then every letter must be preceded by two or three bytes 0, It's a huge waste of storage , The size of the text file will therefore be two or three times larger
3.2 The result is
** Results a :** There is Unicode A variety of storage methods , That is to say, there are many different binary formats , It can be used to express Unicode, There are mainly UTF-8,UTF-16,UTF-32.
Result two : Unicode Can't promote... For a long time , Until the advent of the Internet
Four UTF-8
The popularity of the Internet , A unified coding method is strongly demanded .
UTF-8 It's the most widely used on the Internet Unicode How to implement .
Other implementations include UTF-16( Characters are represented by two or four bytes ) and UTF-32( Characters are represented in four bytes ), But not on the Internet .
Be careful :UTF-8 yes Unicode One of the ways to realize .
###4.1 UTF-8 characteristic
UTF-8 The biggest one , It's a variable length encoding . It can be used 1~4 Bytes represent a symbol , The length of the bytes varies according to the symbol .
###4.2 UTF-8 The coding rules of
UTF-8 There are two coding rules :
** Rule one :** For single byte symbols , The first bit of the byte is set to 0, Back 7 Bit by bit Unicode code . So for English letters ,UTF-8 Coding and ASCII The code is the same .
** Rule 2 :** about n Symbol of byte (n > 1), Before the first byte n All places are set as 1, The first n + 1 Set as 0, The first two bits of the next byte are all set to 10. The remaining bits not mentioned , All for this symbol Unicode code .
The following table summarizes the coding rules , Letter x The bits that can be encoded .
| Serial number range ( Number corresponds to decimal number ) | Binary format |
|---|---|
| Hexadecimal range :(0x00—0x7f) Decimal range :(0—127) | 0XXXXXXX |
| Hexadecimal range :(0x80—0x7ff) Decimal range :(128—2047) | 110XXXXX 10XXXXXX |
| Hexadecimal range :(0x800—0xffff) Decimal range :(2048—65535) | 1110XXXX 10XXXXXX 10XXXXXX |
| Hexadecimal range :(0x10000—0x10ffff) Decimal range :(65536 above ) | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX |
5、 ... and Unicode and UTF-8 Conversion between
According to the above table , Reading UTF-8 Coding is very simple . If the first bit of a byte is 0, Then this byte is just a character ; If the first one is 1, How many in a row 1, It means how many bytes the current character occupies .
below , Take the strictness of Chinese characters as an example , Demonstrate how to achieve UTF-8 code .
Yan's Unicode yes 4E25(100111000100101), According to the table , You can find 4E25 In the third line (0000 0800 - 0000 FFFF), So strict UTF-8 Encoding takes three bytes , The format is 1110xxxx 10xxxxxx 10xxxxxx. then , Start with the strict last binary bit , Fill in... In the format from the back to the front x, The extra complement 0. So you get , Yan's UTF-8 Encoding is 11100100 10111000 10100101, Convert it to hexadecimal E4B8A5
边栏推荐
- 155. 最小栈
- Datapipeline was selected into the 2022 digital intelligence atlas and database development report of China Academy of communications and communications
- 手把手带你入门Apache伪静态的配置
- leetcode:221. 最大正方形【dp状态转移的精髓】
- Natural language processing series (I) introduction overview
- 爱可生SQLe审核工具顺利完成信通院‘SQL质量管理平台分级能力’评测
- The Research Report "2022 RPA supplier strength matrix analysis of China's banking industry" was officially launched
- 逆波兰表达式
- I'm doing open source in Didi
- 百日完成国产数据库opengausss的开源任务--openGuass极简版3.0.0安装教程
猜你喜欢
Simple page request and parsing cases

Cf:a. the third three number problem
SAP SEGW 事物码里的 ABAP 类型和 EDM 类型映射的一个具体例子
SAP UI5 视图里的 OverflowToolbar 控件
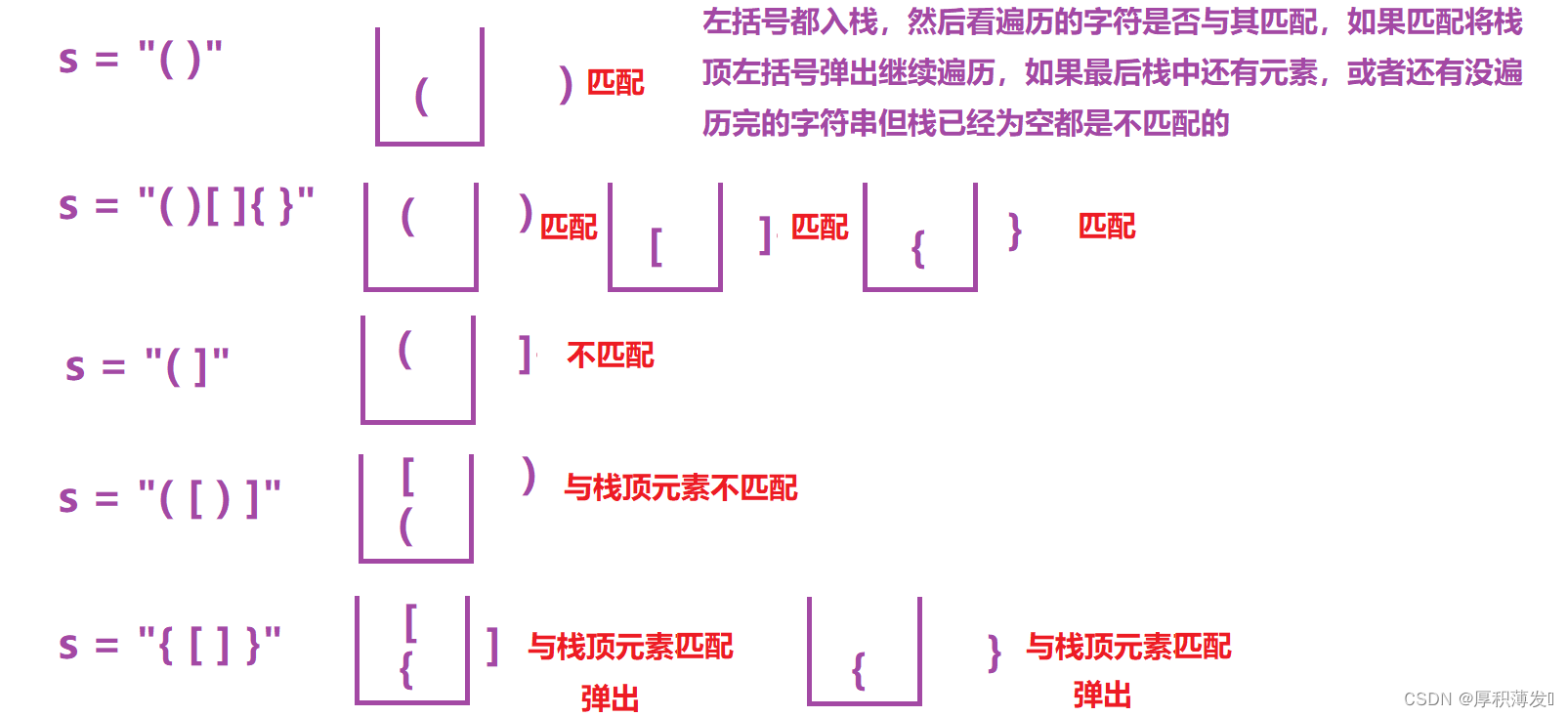
LeetCode20.有效的括号
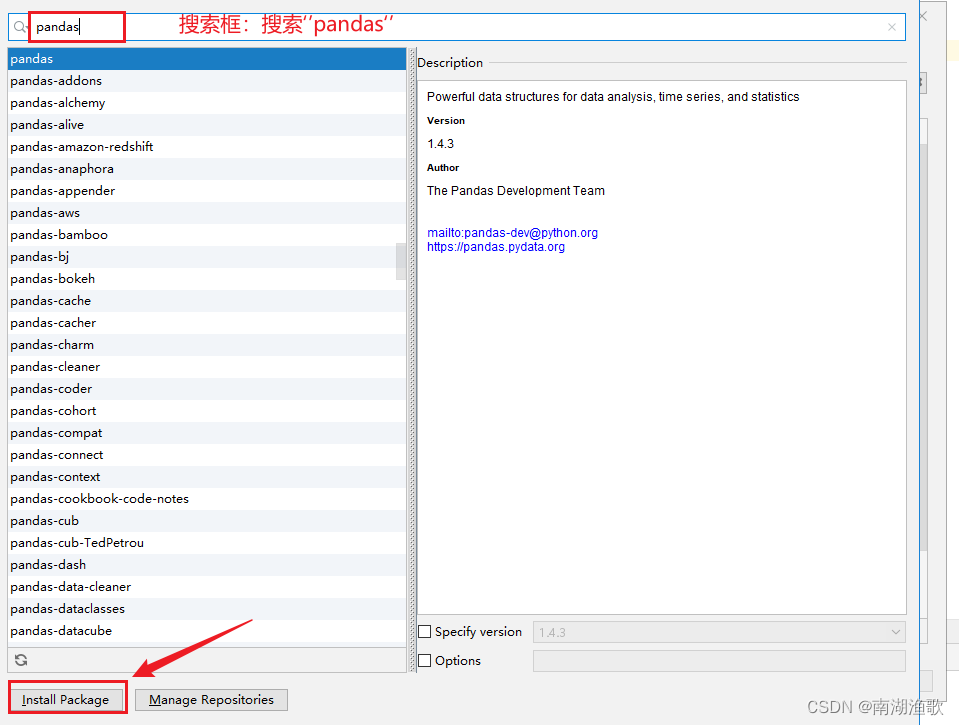
Pycharm installation third party library diagram

Shi Zhenzhen's 2021 summary and 2022 outlook | colorful eggs at the end of the article
How to realize batch sending when fishing
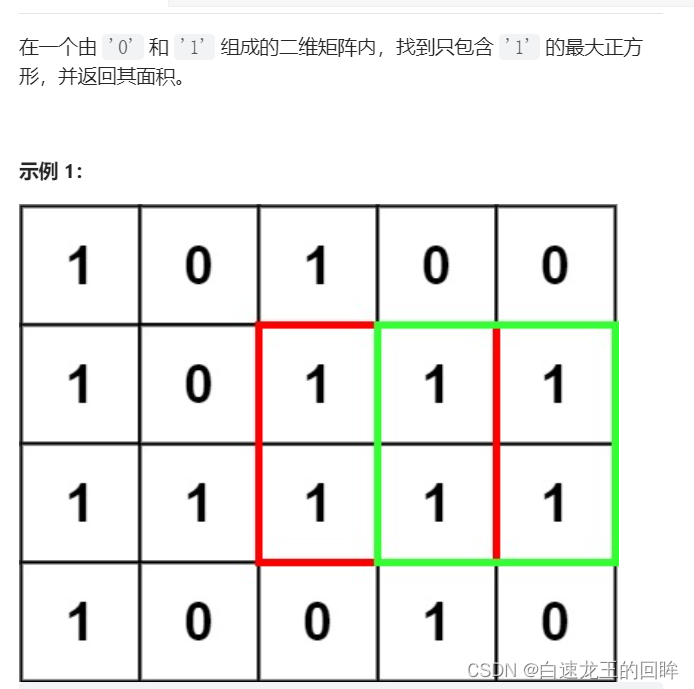
leetcode:221. 最大正方形【dp状态转移的精髓】
SAP SEGW 事物码里的导航属性(Navigation Property) 和 EntitySet 使用方法
随机推荐
Introduction to sap ui5 dynamicpage control
[cloud native] event publishing and subscription in Nacos -- observer mode
LeetCode20.有效的括号
Natural language processing from Xiaobai to proficient (4): using machine learning to classify Chinese email content
A deep long article on the simplification and acceleration of join operation
Hundred days to complete the open source task of the domestic database opengauss -- openguass minimalist version 3.0.0 installation tutorial
[cloud native] use of Nacos taskmanager task management
Changing JS code has no effect
leetcode:221. 最大正方形【dp状态转移的精髓】
uni-app开发语音识别app,讲究的就是简单快速。
Apicloud studio3 API management and debugging tutorial
阿里云SLB负载均衡产品基本概念与购买流程
Flutter draws animation effects of wave movement, curves and line graphs
Reverse Polish notation
STM32 and motor development (from architecture diagram to documentation)
A small talk caused by the increase of sweeping
SAP SEGW 事物码里的 ABAP 类型和 EDM 类型映射的一个具体例子
RHCSA10
Natural language processing series (I) introduction overview
初次使用腾讯云,解决只能使用webshell连接,不能使用ssh连接。