当前位置:网站首页>Paper reading [open book video captioning with retrieve copy generate network]
Paper reading [open book video captioning with retrieve copy generate network]
2022-07-07 05:34:00 【hei_ hei_ hei_】
Open-book Video Captioning with Retrieve-Copy-Generate Network
Summary
- publish :CVPR 2021
- idea: The author believes that the previous method is due to generation caption Lack of guidance when , So generated caption It's monotonous , And because the training data set is fixed , Therefore, the knowledge learned after model training is not scalable . The author thought of passing video-to-text Search task , Retrieve sentences from the corpus as caption Guidance of . Similar to open book examination (open-domain mechanism)
Detailed design
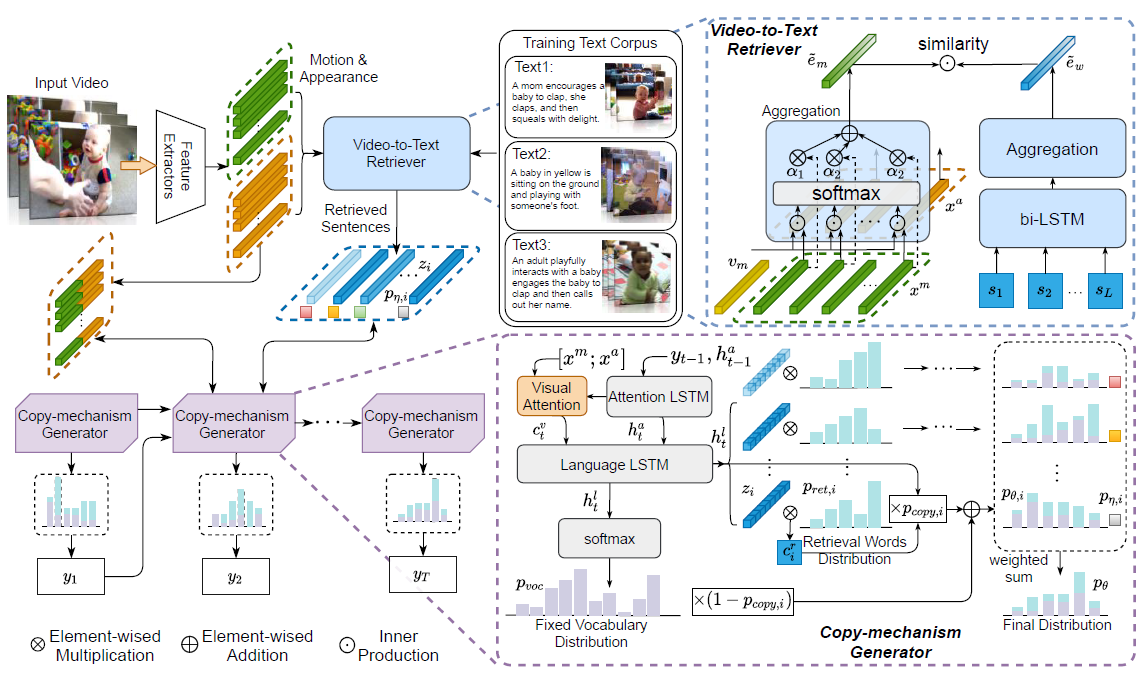
1. Effective Video-to-Text Retriever
Put all in the corpus sentences Through one textual encoder Mapping to d dimension ,videos adopt visual encoder Mapping to d dimension , Find the similarity as the selection standard

Textual Encoder:bi-LSTM
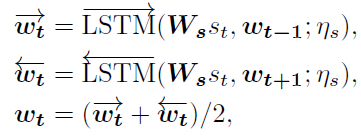
ps: L L L Indicates the length of the sentence , W s W_s Ws It's learnable embedding matrix , η s \eta _s ηs by LSTM Parameters of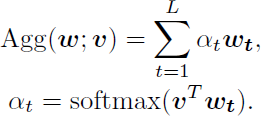
Will the length L Of sentence Aggregate into one d Dimensional vector: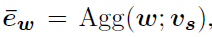
v s v_s vs Is the aggregation parameterVisual Encoder:appearance features && motion features

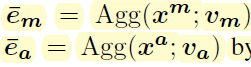
v a , v m v_a,v_m va,vm Is the aggregation parametervideo-to-text similarity:
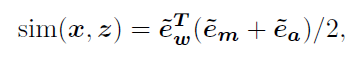
The resulting k Search out the guiding sentences
2. Copy-mechanism Caption Generator
adopt Hierarchical Caption Decoder To generate caption, Just in every step adopt Dynamic Multi-pointers Module Decide whether to copy Guided word
2.1 Hierarchical Caption Decoder
By a attention-LSTM And a language-LSTM form .attention-LSTM For attention visual features The probability distribution used to aggregate the current state and visual context to generate a vocabulary p v o c p_{voc} pvoc
- attention-LSTM
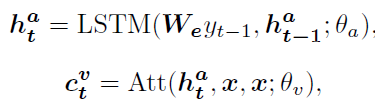
x = [ x m ; x a ] x = [x^m;x^a] x=[xm;xa], y t − 1 y_{t-1} yt−1 Indicates the last step Generated words - language-LSTM
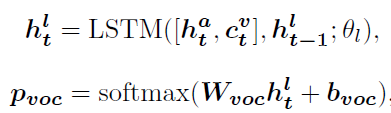
W b o c , b b o c W_{boc},b_{boc} Wboc,bboc Are learnable parameters
2.2 Dynamic Multi-pointers Module
Premise : Already got K Candidates sentences Every sentence Yes L Word
Every sentence Yes L Word 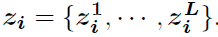
Deal with each sentence separately . take decoder Medium hidden state h t l h^l_t htl As Q In the sentence L Words do attention, obtain L Attention probability distribution of words
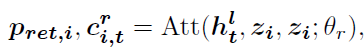
p r e t , i p_{ret,i} pret,i It means the first one i The weight of attention distribution of each word in a sentence ; c i , t r c_{i,t}^r ci,tr Represents the weighted result .Decide whether to copy The selected word
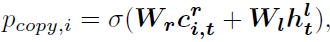
Get the probability distribution of all the final words ( p r e t p_{ret} pret Be extended , p c o p y p_{copy} pcopy Be broadcast )
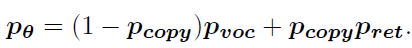
3. Training
- Strategy 1: In order to expand the corpus , It can be fixed retriever,fine-tuning generator.
- Strategy 2: You can also train together , But if you update directly retriever It can lead to generator Poor training from the beginning , So for Loss Added restrictions
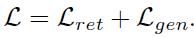
experimental result
- Ablation Experiment
different K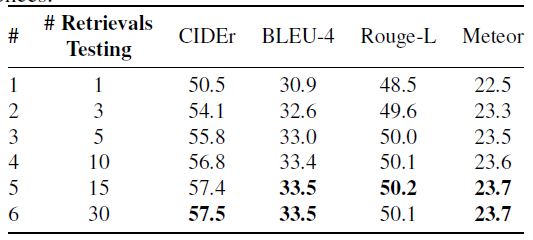
different corpus size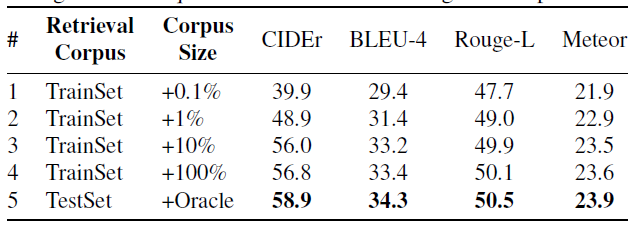
- Comparison Performance
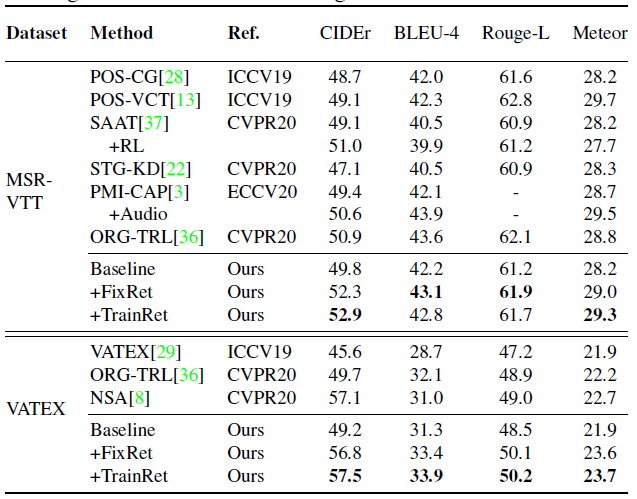
The result is actually average , No more than 20 Some experiments in
边栏推荐
- If you want to choose some departments to give priority to OKR, how should you choose pilot departments?
- Life experience of an update statement
- Most commonly used high number formula
- Creation and use of thread pool
- Pinduoduo product details interface, pinduoduo product basic information, pinduoduo product attribute interface
- 痛心啊 收到教训了
- Initial experience of annotation
- Preliminary practice of niuke.com (9)
- Summary of the mean value theorem of higher numbers
- 高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
猜你喜欢
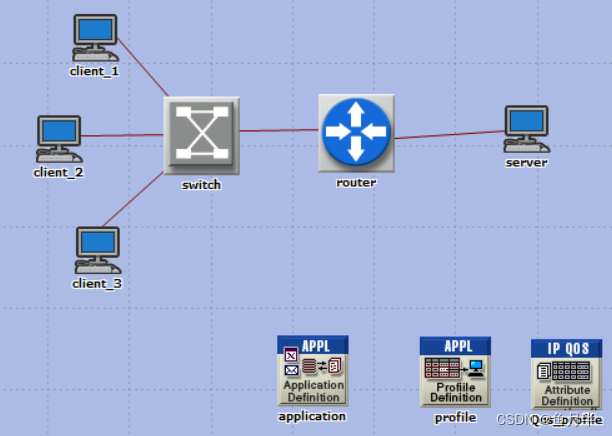
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
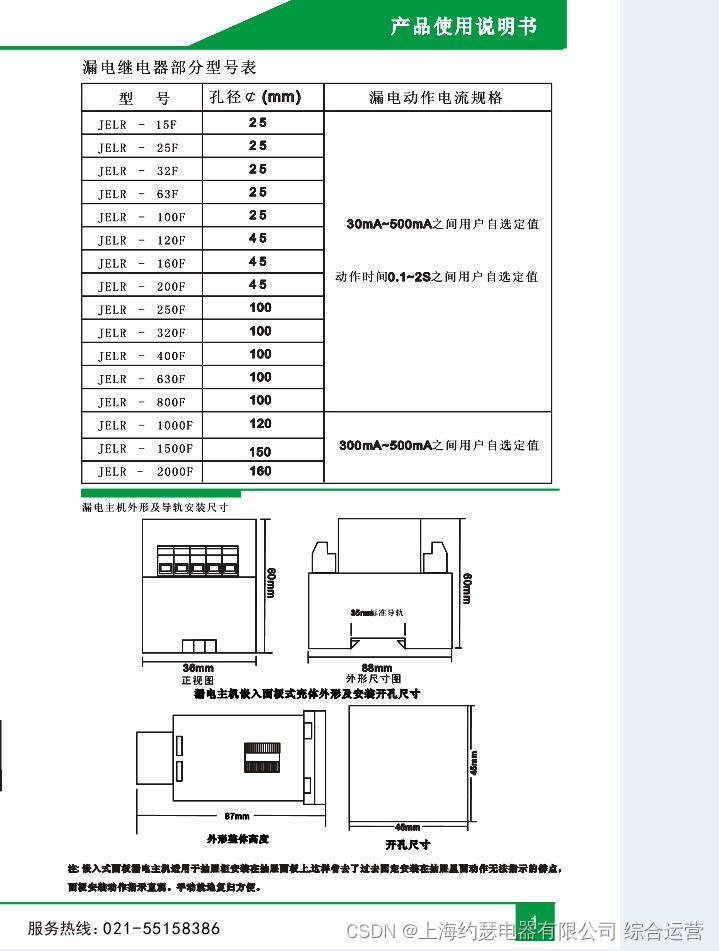
K6el-100 leakage relay

漏电继电器JOLX-GS62零序孔径Φ100

How digitalization affects workflow automation
Zero sequence aperture of leakage relay jolx-gs62 Φ one hundred
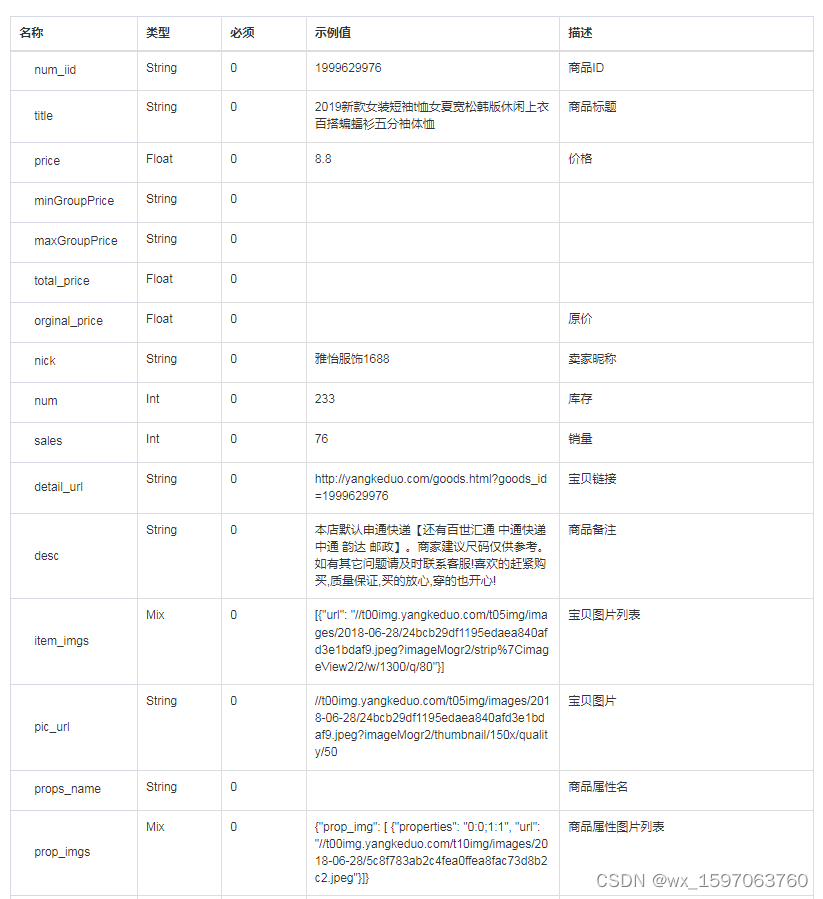
Pinduoduo product details interface, pinduoduo product basic information, pinduoduo product attribute interface
Annotation初体验
漏电继电器JELR-250FG

4. Object mapping Mapster
不同网段之间实现GDB远程调试功能
随机推荐
np. random. Shuffle and np Use swapaxis or transfer with caution
Intelligent annotation scheme of entity recognition based on hugging Face Pre training model: generate doccano request JSON format
《4》 Form
分布式事务解决方案之2PC
Linkedblockingqueue source code analysis - initialization
Preliminary practice of niuke.com (9)
淘宝商品详情页API接口、淘宝商品列表API接口,淘宝商品销量API接口,淘宝APP详情API接口,淘宝详情API接口
Two person game based on bevy game engine and FPGA
JD commodity details page API interface, JD commodity sales API interface, JD commodity list API interface, JD app details API interface, JD details API interface, JD SKU information interface
How can professional people find background music materials when doing we media video clips?
漏电继电器LLJ-100FS
[binary tree] binary tree path finding
人体传感器好不好用?怎么用?Aqara绿米、小米之间到底买哪个
How digitalization affects workflow automation
K6EL-100漏电继电器
漏电继电器JELR-250FG
Mysql database learning (8) -- MySQL content supplement
Torch optimizer small parsing
Zero sequence aperture of leakage relay jolx-gs62 Φ one hundred
Leakage relay jd1-100