当前位置:网站首页>《ClickHouse原理解析与应用实践》读书笔记(4)
《ClickHouse原理解析与应用实践》读书笔记(4)
2022-07-04 06:05:00 【Aiky哇】
开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第五章:
第6章 MergeTree原理解析
MergeTree作为ck最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,家族中其他的表引擎则在MergeTree的基础之上各有所长。

6.1 MergeTree的创建方式与存储结构
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁 盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。
6.1.1 MergeTree的创建方式
声明Engine=MergeTree()
MergeTree表引擎几个重要参数:
- PARTITION BY [选填]:分区键。可以多个列字段,支持使用列表达式。不声明分区键,则 ClickHouse会生成一个名为all的分区。
- ORDER BY [必填]:排序键。默认情况下主键(PRIMARY KEY)与排序键相同。可以多个列字段,此时按字段依次排序。
- PRIMARY KEY [选填]:主键。会依照主键字段生成一级索引,默认与排序键相同。MergeTree 主键允许存在重复数据(ReplacingMergeTree可以去重)。【当指定的主键和排序键不同时:】
- 此时排序键用于在数据片段中进行排序,主键用于在索引文件中进行标记的写入。
- 主键表达式元组必须是排序键表达式元组的前缀,即主键为(a,b),排序列必须为(a,b,******)。
- SAMPLE BY [选填]:抽样表达式。声明数据以何种标准进行采样。抽样表达式需要配合SAMPLE子查询使用,这项功能对于选取抽样 数据十分有用,更多关于抽样查询的使用方法会在第9章介绍。
【另外书中还写了settings,但是这个现在的版本已经不再适用。另外新版本还增加了ttl】
- TTL [选填]:指定行的存储持续时间并定义磁盘和卷之间自动部件移动的逻辑。表达式必须有一个Date或者DateTime作为结果,例如`TTL date + INTERVAL 1 DAY`,规则类型 `DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'|GROUP BY`
- SETTINGS[选填]:控制 MergeTree 行为的附加参数,具体的可以参考官网介绍。
6.1.2 MergeTree的存储结构
MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上。

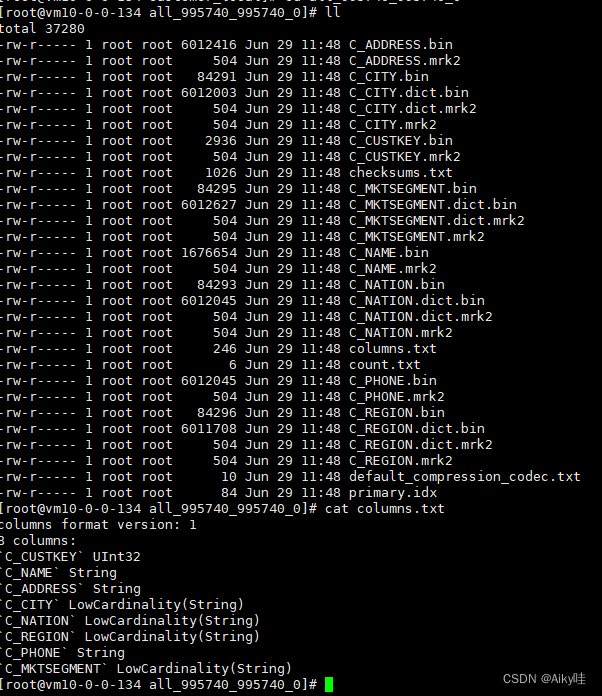
一张表文件夹下的存储说明:
partition:分区目录
各类数据文件(primary.idx、 [Column].mrk、[Column].bin等)都是以分区目录的形式被组织存放 的。
相同分区的数据,最终会被合并到同一个分区目录。
checksums.txt:校验文件
使用二进制格式存储。
保存了余下各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
columns.txt:列信息文件
明文格式存储。用于保存此数据分区下的列字段信息。
count.txt:计数文件
使用明文格式存储。用于记录当前数据分区目录下数据的总行数。
primary.idx:一级索引文件
二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY或者PRIMARY KEY)。
[Column].bin:数据文件
使用压缩格式存储,默认为LZ4 压缩格式。每一个列字段都拥有独立的.bin数据文件
[Column].mrk/[Column].mrk2:列字段标记文件
二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息。每个列字段都会拥有与其对应的.mrk标记文件。
标记文件与稀疏索引对齐,又与.bin文件一一对应。
MergeTree通过标记文件建立了 primary.idx 稀疏索引与.bin数据文件之间的映射关系。首先通过稀 疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据。
如果使用了自适应大小的索引间隔(参数控制),则标记文件会以.mrk2命名。它的工作原理和作用与.mrk标记文件相同。
partition.dat与minmax_[Column].idx:
使用了分区键,则会额外生成partition.dat与 minmax索引文件,它们均使用二进制格式存储。
partition.dat用于保存当前分区下分区表达式最终生成的值。
minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。
例如,EventTime字段对应的原始数据为2019-05-01、2019-05-05,分区表达式为PARTITION BY toYYYYMM(EventTime)。partition.dat中保存的值将会是2019- 05,而minmax索引中保存的值将会是2019-05-012019-05-05。
可以在进行数据查询时快速跳过不必要的数据分区目录。
skp_idx_[Column].idx与skp_idx_[Column].mrk:
若声明了二级索引,额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。
二级索引在ClickHouse中又称跳数 索引,目前拥有minmax、set、ngrambf_v1和tokenbf_v1四种类型。细节会在 6.4节阐述。
6.2 数据分区
6.2.1 数据的分区规则
分区ID的生成逻辑目前拥有四种规则:
- 不指定分区键:即不使用PARTITION BY,则分区ID默认取名为all。
- 使用整型:如果分区键取值属于整型且无法转换为日期类型YYYYMMDD格式,则直接按照该整型的字符形式输出,作为分区ID的取值。
- 使用日期类型:日期类型或能转为YYYYMMDD格式的整型,则使用按照YYYYMMDD作为分区ID的取值。
- 其他类型:例如String、Float等,则通过128位Hash算法取其Hash值作为分区ID的取值。

若使用多个分区键,则按照上面规则后,使用 - 连接。
PARTITION BY (length(Code),EventTime)
分区为:
2-20190501
2-201906116.2.2 分区目录的命名规则
MergeTree分区目录的完整物理名称 ,在ID之后还跟着一串奇怪的数字,例如 201905_1_1_0。

一个完整分区目录的命名公式如下所示:
PartitionID_MinBlockNum_MaxBlockNum_Level
- PartitionID:分区ID
- MinBlockNum和MaxBlockNum:最小数据块编号与最大数据块编号。这里的BlockNum是一个整型的自增长编号。计数n在单张MergeTree数据表内全局累加,n从1开始,每次创建一个新的分区目录,计数加1。所以新建目录最小最大数据块编号相等为n。
- Level:合并的层级,某个分区被合并过的次数。每一个新创建的分区目录初始值为0,若相同分区发生合并动作,则在相应分区内计数累积加1。
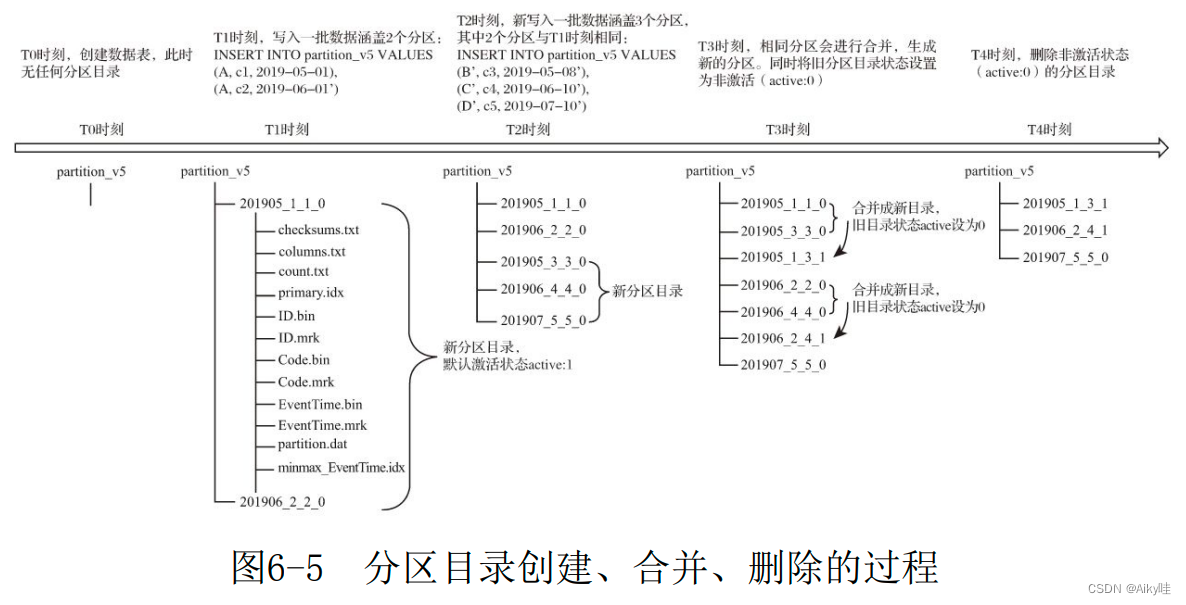
6.2.3 分区目录的合并过程
MergeTree每一批数据的写入(一次INSERT语句), MergeTree都会生成一批新的分区目录。
即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。
在之后ck后台将属于相同分区的多个目录合并成一个新的目录。
旧分区目录并不会立即被删除,而是之后后台任务删除。
合并后目录中的索引和数据文件也会相应地进行合并。
- PartitionID:不变
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum 值。
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum 值。
- Level:取同一分区内最大Level值并加1。
6.3 一级索引
MergeTree的主键使用PRIMARY KEY定义,更为常见的是通过 ORDER BY指代主键。
MergeTree会依据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内。
PRIMARY KEY与ORDER BY定义有差异的应用场景在 SummingMergeTree引擎章节部分会有介绍。
6.3.1 稀疏索引
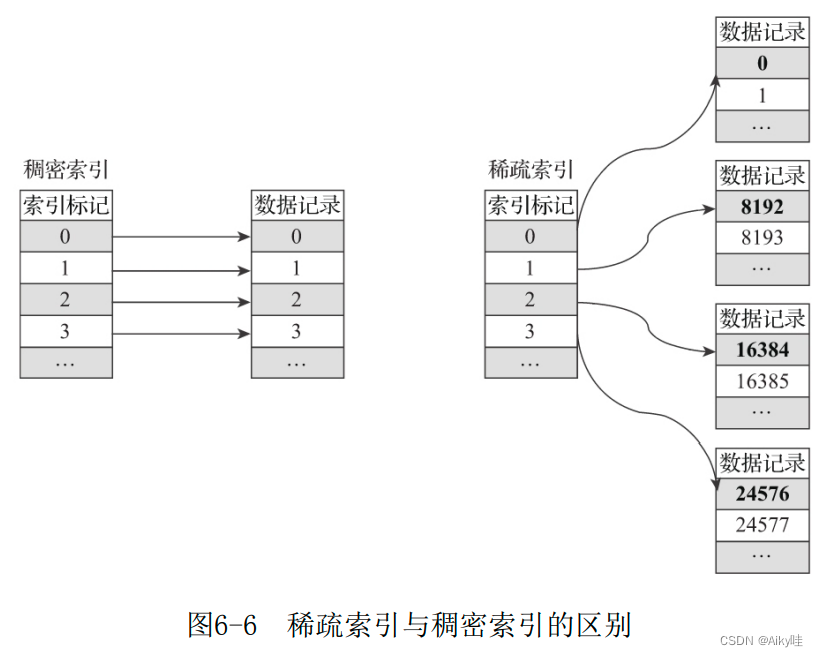
稀疏索引占用空间小,所以 primary.idx内的索引数据常驻内存,取用速度自然极快。
6.3.2 索引粒度
索引粒度对MergeTree而言是一个非常重要的概念。
由参数index_granularity定义 。
MergeTree使用MarkRange表示 一个具体的区间,并通过start和end表示其具体的范围。
index_granularity同时也会影响数据标记(.mrk)和数据文件 (.bin)。
6.3.3 索引数据的生成规则
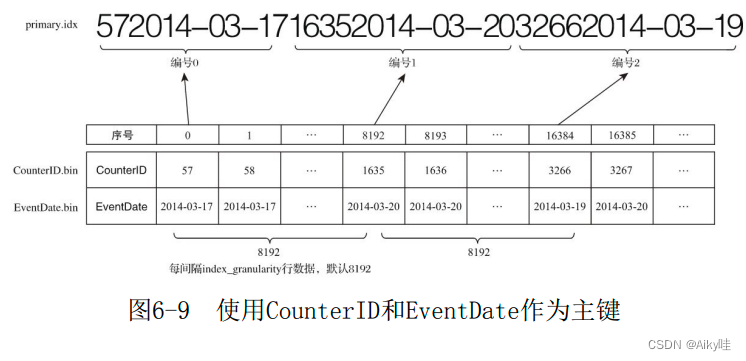
MergeTree需要间隔index_granularity数据才会生成一条索引记录 。
如果使用 CounterID作为主键(ORDER BY CounterID),则每间隔8192行数据就会取一次CounterID的值作为索引值,索引数据最终会被写入 primary.idx文件进行保存。
例如。第0(8192*0)行CounterID取值57,第8192(8192*1)行 CounterID取值1635,而第16384(8192*2)行CounterID取值3266,最终索引数据将会是5716353266。

看的出MergeTree对于稀疏索引的存储是非常紧凑的。
如果使用多个主键,例如ORDER BY(CounterID,EventDate),则每间隔8192行可以同时取CounterID与EventDate两列的值作为索引值。
6.3.4 索引的查询过程
一个具体的数据段是一个MarkRange 。与索引编号对应,使用start和end两个属性表示其区间范 围。
整个索引查询过程可以大致分为3个步骤。
- 生成查询条件区间:将查询条件转换为条件区间。
WHERE ID = 'A003' ['A003', 'A003'] WHERE ID > 'A000' ('A000', +inf) WHERE ID < 'A188' (-inf, 'A188') WHERE ID LIKE 'A006%' ['A006', 'A007') - 递归交集判断:从最大的区间开始:
- 如果不存在交集,则直接通过剪枝算法优化此整段MarkRange。
- 如果存在交集,且MarkRange不可再分解,则记录MarkRange并返回。
- 如果存在交集,且MarkRange可再分解,继续做递归。
- 合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
6.4 二级索引
目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
需要在CREATE语句内定义:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity会额外生成相应的索引与标记文件(skp_idx_[Column].idx与 skp_idx_[Column].mrk)。
6.4.1 granularity与index_granularity的关系
不同二级索引共同拥有granularity参数。
index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度。granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。

6.4.2 跳数索引的类型
MergeTree共支持4种跳数索引,分别是minmax、set、 ngrambf_v1和tokenbf_v1。
CREATE TABLE skip_test (
ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b(length(ID) * 8) TYPE set(2) GRANULARITY 5,
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree()
省略...minmax:
minmax索引记录了一段数据内的最小和最大极值.
类似分区目录的minmax索引,能够快速跳过无用的数据区间 。
set:
set索引直接记录了声明字段或表达式的取值(唯一 值,无重复)。
其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。
如果max_rows=0,则表示无限制 。
ngrambf_v1:
数据短语的布隆表过滤器,只支持String和FixedString数据类型。
只能够提升 in、notIn、like、equals和notEquals查询的性能。
完整形式为 ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_fun ctions,random_seed)。
- n:token长度,依据n的长度将数据切割为token短语。
- size_of_bloom_filter_in_bytes:布隆过滤器的大小。
- number_of_hash_functions:布隆过滤器中使用Hash函数的个 数。
- random_seed:Hash函数的随机种子。
tokenbf_v1:
是ngrambf_v1的变种,同样是一种布隆过滤器索引。
和ngrambf_v1的区别是不需要指定token长度。
tokenbf_v1会自动按照非字符的、数字的字符串分割token。
6.5 数据存储
6.5.1 各列独立存储
每个列字段都拥有一个与之对应的.bin数据文件。
列式存储更好地进行数据压缩,最小化数据扫描的范围。
MergeTree的设计:
- 数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用 LZ4算法;
- 数据会事先依照ORDER BY的声明排序;
- 数据是 以压缩数据块的形式被组织并写入.bin文件中的。
6.5.2 压缩数据块
由头信息和压缩数据两部分组成。
头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小

通过ClickHouse提供的clickhouse-compressor工具,能够查询某个.bin文件中压缩数据的统计信息。
clickhouse-compressor --stat bin文件路径
每一行数据代表着一个压缩数据块的头信息,其分别表示该压缩块中未压缩数据大小和压缩后数据大小。
每个压缩数据块上下限分别由min_compress_block_size(默认65536)与 max_compress_block_size(默认1048576)参数指定。
一个压缩数据块最终的大小和一个间隔(index_granularity)内数据的实际大小相关。
MergeTree在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取 8192行),按批次获取数据并进行处理。如果把一批数据的未压缩大小设为size,则整个写入过程遵循以下规则:
- size<64KB:单个批次数据小于64KB,则继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块。
- 64KB<=size<=1MB :如果单个批次数据大小恰好在64KB与1MB 之间,则直接生成下一个压缩数据块。
- size>1MB :如果单个批次数据直接超过1MB,则首先按照1MB 大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时一个批次数据生成多个压缩数据块。
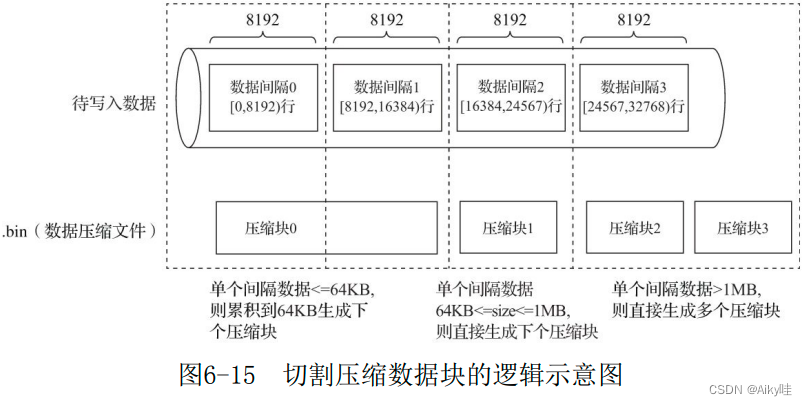
多个压缩数据块之间,按照写入顺序首尾相接.
.bin文件中引入压缩数据块的目的:
- 性能损耗和压缩率之间寻求一种平衡
- 将读取粒度降低到压缩数据块级别
6.6 数据标记
如果把MergeTree比作一本书,primary.idx一级索引好比这本书的一级章节目录,.bin文件中的数据好比这本书中的文字,那么数据标记(.mrk)会为一级章节目录和具体的文字之间建立关联。对于数据标记而言,它记录了两点重要信息:其一,是一级章节对应的页码信息;其二,是一段文字在某一页中的起始位置信息。
【索引中没有记录偏移位置,就记录了值,跳转需要用数据标记。】
6.6.1 数据标记的生成规则
数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔。 数据标记文件也与.bin文件一一对应。
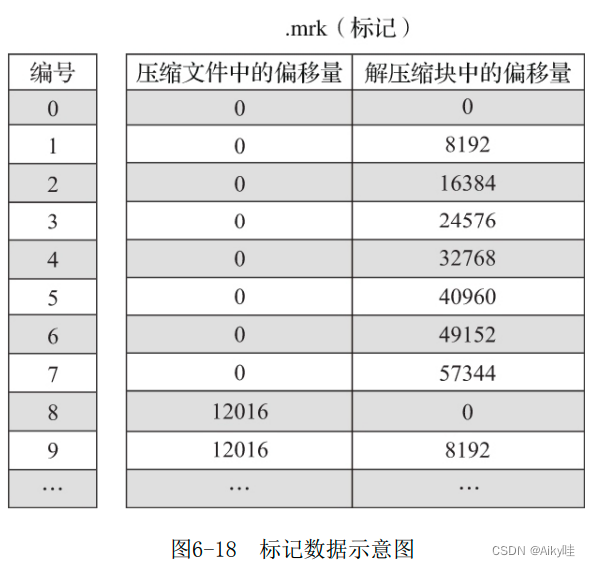
每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。
一行标记数据使用一个两个整数的元组表示,分别表示压缩数据块的起始偏移量;以及解压后未压 缩数据的起始偏移量。
标记数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取用速度。
6.6.2 数据标记的工作方式
Mergetree读取数据的步骤可以分为读取压缩数据块和读取数据两个步骤。
以hits_v1测试表的JavaEnable字段为例。JavaEnable字段的数据类型为UInt8,所以每行数值占用1字节。index_granularity粒度为8192,一个索引片段的数据大小恰好是8192B。根据数据压缩块生成规则,JavaEnable标记文件中,每8行标记数据对应1个压缩数据块。
其标记数据与压缩数据的对应关系:

读取压缩数据块
MergeTree只加载特定的压缩数据块到内存中即可,无须一次性加载整个.bin文件。
标记数据中,两个压缩文件的偏移量就是第一个压缩快的偏移量区间。
在.mrk文件中,第0个压缩数据块的截止偏移量是12016。而在.bin数据文件中,第0个压缩数据块的压缩大小是12000。为什么两个数值不同呢?
其实原因很简单,12000只是数据压缩后的字节数,并没有包含头信息部分。而一个完整的压缩数据块是由头信息加上压缩数据组成的,它的头信息固定由9个字节组成,压缩后大小为8个字节。所以,12016=8+12000+8
压缩数据块被整个加载到内存之后,会进行解压,在这之后就进入具体数据的读取环节了。
读取数据
在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要,以index_granularity的粒度加载特定的一小段。 为了实现这项特性,需要借助标记文件中保存的解压数据块中的偏移量。
例如在图6-19所示中,通过[0,8192]能够读取压缩数据块 0 中的第一个数据片段。
6.7 对于分区、索引、标记和压缩数据的协同总结
分别从写入过程、查 询过程,以及数据标记与压缩数据块的三种对应关系的角度展开介绍。
6.7.1 写入过程
第一步,随着每一批写入数据,生成一个新的分区目录。这些新的分区目录之后会后台合并。
第二步,按照index_granularity索引粒度, 会分别生成primary.idx一级索引(如果声明了二级索引,还会创建二索引文件)、每一个列字段的.mrk数据标记和.bin压缩数据文件。
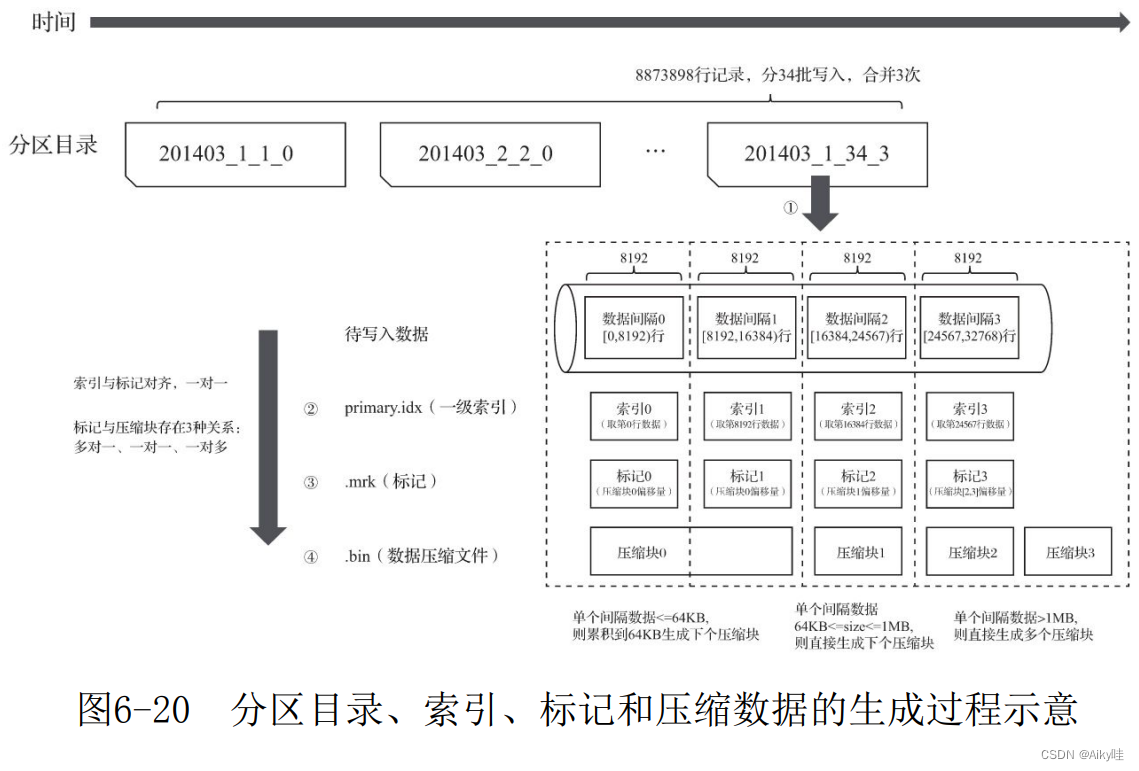
其中,索引和标记区间是对齐的,而标记与压缩块则根据区间数据大小的不同,会生成多对一、一对一和一对多三种关系。
6.7.2 查询过程
查询本质是不断的减小数据的范围。
在最理想的情况下,MergeTree首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小。
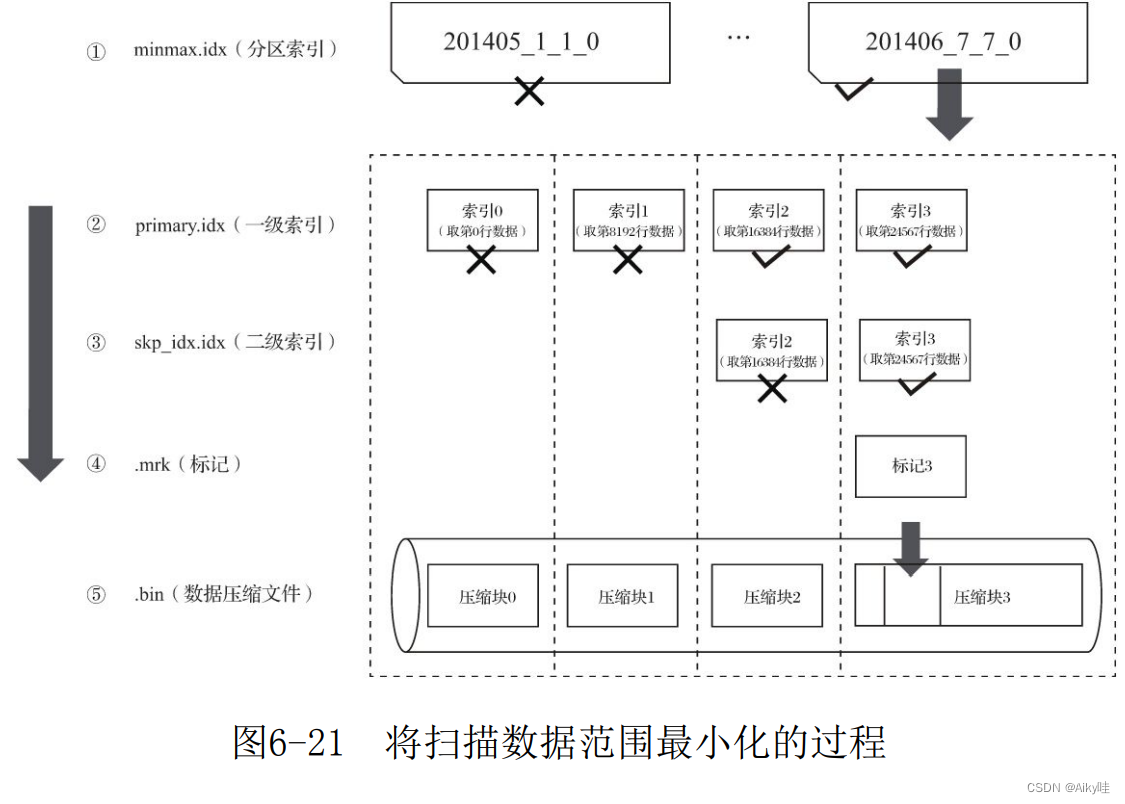
如果一条查询语句没有指定任何WHERE条件,或是指定了WHERE条件,但条件没有匹配到任何索引(分区索引、一级索引和二级索引),那么MergeTree就不能预先减小数据范围。
在后续进行数据查询时,它会扫描所有分区目录,以及目录内索引段的最大区间。
虽然不能减少数据范围,但是MergeTree仍然能够借助数据标记,以多线程的形式同时读取多个压缩数据块,以提升性能。
6.7.3 数据标记与压缩数据块的对应关系
【min_compress_block_size(默认65536)与 max_compress_block_size(默认1048576)指定压缩快大小上下限】
1.多对一
多个数据标记对应一个压缩数据块,当一个间隔 (index_granularity)内的数据未压缩大小size小于64KB时,会出现这种对应关系。
2.一对一
一个数据标记对应一个压缩数据块,当一个间隔 (index_granularity)内的数据未压缩大小size大于等于64KB且小于等于1MB时,会出现这种对应关系。
3.一对多
一个数据标记对应多个压缩数据块,当一个间隔 (index_granularity)内的数据未压缩大小size直接大于1MB时,会出现这种对应关系。
6.8 本章小结
解释了MergeTree的基础属性和物理存储结构。
介绍了数据分区、一级索引、二级索引、数据存储和数据标记的重要特性。
总结了MergeTree上述特性在一起协同 时的工作过程。
下一章将进一步介绍MergeTree家族中其他常见表引擎的具体使用方法。
【下一章主要就开始看工作环境中最常用的ReplicatedMergeTree了】
边栏推荐
- Overview of relevant subclasses of beanfactorypostprocessor and beanpostprocessor
- FRP intranet penetration, reverse proxy
- 509. Fibonacci number, all paths of climbing stairs, minimum cost of climbing stairs
- 接地继电器DD-1/60
- webrtc 快速搭建 视频通话 视频会议
- 19. Framebuffer application programming
- High performance parallel programming and optimization | lesson 02 homework at home
- Configure cross compilation tool chain and environment variables
- MySQL的information_schema数据库
- HMS v1.0 appointment.php editid参数 SQL注入漏洞(CVE-2022-25491)
猜你喜欢
Canoe panel learning video
Win10 clear quick access - leave no trace

Input displays the currently selected picture
JS flattened array of number shape structure
![[untitled]](/img/32/cfd45bb5e8555ea2ad344161370dbe.png)
[untitled]
![[openvino+paddle] paddle detection / OCR / SEG export based on paddle2onnx](/img/a9/72791cbcc6c9da45e89450ab2820c1.jpg)
[openvino+paddle] paddle detection / OCR / SEG export based on paddle2onnx
Kubernets first meeting
Kubernets first meeting

Programmers don't talk about morality, and use multithreading for Heisi's girlfriend
JSON Web Token----JWT和传统session登录认证对比
随机推荐
MySQL information_ Schema database
px em rem的区别
APScheduler如何设置任务不并发(即第一个任务执行完再执行下一个)?
Average two numbers
How to determine whether an array contains an element
JSON Web Token----JWT和傳統session登錄認證對比
Experience weekly report no. 102 (July 4, 2022)
JS flattened array of number shape structure
webrtc 快速搭建 视频通话 视频会议
ABAP:OOALV实现增删改查功能
配置交叉编译工具链和环境变量
注释与注解
How to expand all collapse panels
Kubernets first meeting
C语言练习题(递归)
2022.7.2-----leetcode.871
Grounding relay dd-1/60
Qt发布多语言国际化翻译
Layoutmanager layout manager: flowlayout, borderlayout, GridLayout, gridbaglayout, CardLayout, BoxLayout
js如何将秒转换成时分秒显示