当前位置:网站首页>How does apscheduler set tasks not to be concurrent (that is, execute the next task after the first one)?
How does apscheduler set tasks not to be concurrent (that is, execute the next task after the first one)?
2022-07-04 05:54:00 【Jayce~】
APScheduler How to set tasks not to be concurrent ( That is, execute the next task after the first task )?
1. Software environment
Windows10 Education 64 position
Python 3.6.3
APScheduler 3.6.3
2. Problem description
Python A solution to timed tasks in , Generally speaking, there are four kinds of , Namely :crontab、 scheduler、 Celery、APScheduler, among :
crontabyesLinuxA timed task management tool for , stayWindowsThere are substitutes on itpycron, butWindowsUnlikeLinuxThere are many powerful command programs ,pycronUsefullimitations,CustomizationNot good. ;SchedulerToo simple 、 A more complex scheduled task is too difficult , Especially withmonthScheduled tasks in the above time units ;CeleryThere are more dependent software , Comparative resource consumption ;APScheduler(Advanced Python Scheduler)be based onQuartz, It can be cross platform and easy to configure , Providesdate、interval、cron3 Different triggers , AndLinuxUpper nativecrontabFormat compatible , You can set any highly complex scheduled task , Flexible to death .
I will not introduce APScheduler The basic characteristics of , If you need it, you can see it directly APScheduler Official documents , Let's go straight to the subject :
APScheduler How to set tasks not to be concurrent ( That is, execute the next task after the first task )?
APScheduler When multiple tasks are triggered at the same time , Multiple tasks will be executed simultaneously , For example, use the sample code below :
''' =========================================== @author: jayce @file: apscheduler Set tasks not to be concurrent .py @time: 2022/7/1/001 19:38 =========================================== '''
from apscheduler.schedulers.blocking import BlockingScheduler
import time
def job_printer(text):
''' Dead cycle , Used to simulate long-time tasks :param text: :return: '''
while True:
time.sleep(2)
print("job text:{}".format(text))
if __name__ == '__main__':
schedule = BlockingScheduler()
schedule.add_job(job_printer, "cron", second='*/10', args=[' Every time 10 Once per second !'])
schedule.add_job(job_printer, "cron", second='*/20', args=[' Every time 20 Once per second !'])
schedule.print_jobs()
schedule.start()
You can see , function job_printer It's a dead cycle , Used to simulate long-time tasks , We use add_job towards APScheduler Add 2 individual job_printer, The difference is that 2 The time interval between tasks is : Every time 10 Once per second and Every time 20 Once per second .
because job_printer It's a dead cycle , amount to job_printer Has not been implemented , But in fact APScheduler When the task is not completed , Execute multiple different job_printer:
job text: Every time 10 Once per second !
job text: Every time 20 Once per second !
job text: Every time 10 Once per second !
job text: Every time 20 Once per second !
job text: Every time 10 Once per second !
job text: Every time 20 Once per second !
job text: Every time 10 Once per second !
job text: Every time 20 Once per second !
job text: Every time 10 Once per second !
Execution of job "job_printer (trigger: cron[second='*/10'], next run at: 2022-07-01 20:47:50 CST)" skipped: maximum number of running instances reached (1)
namely :
You can see 10 Of a second job_printer and 20 Of a second job_printer Alternately executed , And in fact 10 Of a second job_printer In fact, it has not been implemented at all . This is in CPU perhaps GPU When the hardware equipment can bear the load , Of course it's a good thing , But if your hardware is not enough , happen OOM Such as insufficient resources , The program was interrupted , Cause your model training or business logic to fail ! Concrete :
I use APScheduler and Tensorflow Learning online (online learning) when , Different retraining methods will be used for the model at different time nodes , if there be 2 Scheduled tasks (A: Every time 10 Once per second ,B: Every time 20 Once per second ) and 2 A heavy training method (X and Y), When your video memory has the following conditions :
Video memory is rarely enough to train a program , You cannot run multiple programs at the same time , Otherwise
OOM;
Then you can only guide the program to execute in turn , Instead of executing concurrently , At the same time X and Y When triggered simultaneously , Only execute 1 individual , in addition 1 One does not execute .
What should we do at this time ?
3. resolvent
By consulting official documents , It is found that the number of threads that can execute tasks can be set , To control only 1 An actuator performs the task , So as to complete the task X Then carry out the task Y, As follows :
''' =========================================== @author: jayce @file: apscheduler Set tasks not to be concurrent .py @time: 2022/7/1/001 19:38 =========================================== '''
from apscheduler.executors.pool import ThreadPoolExecutor
if __name__ == '__main__':
# To prevent video memory overflow caused by full and incremental concurrency , And then the training failed , Set that only one task can run at a time
schedule = BlockingScheduler(executors={
'default': ThreadPoolExecutor(1)})
Through to the BlockingScheduler Set the maximum ThreadPoolExecutor=1, That's what we want !
4. Results Preview
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
Execution of job "job_printer (trigger: cron[second='*/10'], next run at: 2022-07-01 21:17:50 CST)" skipped: maximum number of running instances reached (1)
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
Execution of job "job_printer (trigger: cron[second='*/10'], next run at: 2022-07-01 21:18:00 CST)" skipped: maximum number of running instances reached (1)
Execution of job "job_printer (trigger: cron[second='*/20'], next run at: 2022-07-01 21:18:00 CST)" skipped: maximum number of running instances reached (1)
namely :
You can see , I've been implementing section 1 A triggered task , Tasks triggered at the same time are skipped 了 ~~
Of course , If you want the 1 When a task is completed , Perform the skipped task , It can be done by add_job Set in misfire_grace_time Realization !
FAQ
1.APScheduler If a task fails , Will the whole scheduled task program be interrupted ? Or do you want to continue the task next time ?
The answer is : The program will not break , It's time for the next task , And re execute .
Concrete , Use the following test code :
''' =========================================== @author: jayce @file: apscheduler Set tasks not to be concurrent .py @time: 2022/7/1/001 19:38 =========================================== '''
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ThreadPoolExecutor
import time
def exception_maker():
''' Exception maker , Used to simulate that task execution is interrupted :return: '''
return 1 / 0
def job_printer(text):
''' Dead cycle , Used to simulate long-time tasks :param text: :return: '''
while True:
time.sleep(2)
print("job text:{}".format(text))
if __name__ == '__main__':
schedule = BlockingScheduler()
schedule.add_job(job_printer, "cron", second='*/10', args=[' Every time 10 Once per second !'])
schedule.add_job(exception_maker, "cron", second='*/5')
schedule.print_jobs()
schedule.start()
You can see exception_maker Has failed many times , But it does not affect the next execution of other tasks and itself :
Job "exception_maker (trigger: cron[second='*/5'], next run at: 2022-07-01 19:53:30 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\Jayce\Anaconda3\envs\tf2.3\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "E:/Code/Python/demo Code /apscheduler Set tasks not to be concurrent .py", line 14, in exception_maker
return 1 / 0
ZeroDivisionError: division by zero
Job "exception_maker (trigger: cron[second='*/5'], next run at: 2022-07-01 19:53:35 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\Jayce\Anaconda3\envs\tf2.3\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "E:/Code/Python/demo Code /apscheduler Set tasks not to be concurrent .py", line 14, in exception_maker
return 1 / 0
ZeroDivisionError: division by zero
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
Job "exception_maker (trigger: cron[second='*/5'], next run at: 2022-07-01 19:53:40 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\Jayce\Anaconda3\envs\tf2.3\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "E:/Code/Python/demo Code /apscheduler Set tasks not to be concurrent .py", line 14, in exception_maker
return 1 / 0
ZeroDivisionError: division by zero
job text: Every time 10 Once per second !
job text: Every time 10 Once per second !
Execution of job "job_printer (trigger: cron[second='*/10'], next run at: 2022-07-01 19:53:40 CST)" skipped: maximum number of running instances reached (1)
Job "exception_maker (trigger: cron[second='*/5'], next run at: 2022-07-01 19:53:45 CST)" raised an exception
Traceback (most recent call last):
File "C:\Users\Jayce\Anaconda3\envs\tf2.3\lib\site-packages\apscheduler\executors\base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "E:/Code/Python/demo Code /apscheduler Set tasks not to be concurrent .py", line 14, in exception_maker
return 1 / 0
ZeroDivisionError: division by zero
job text: Every time 10 Once per second !
namely :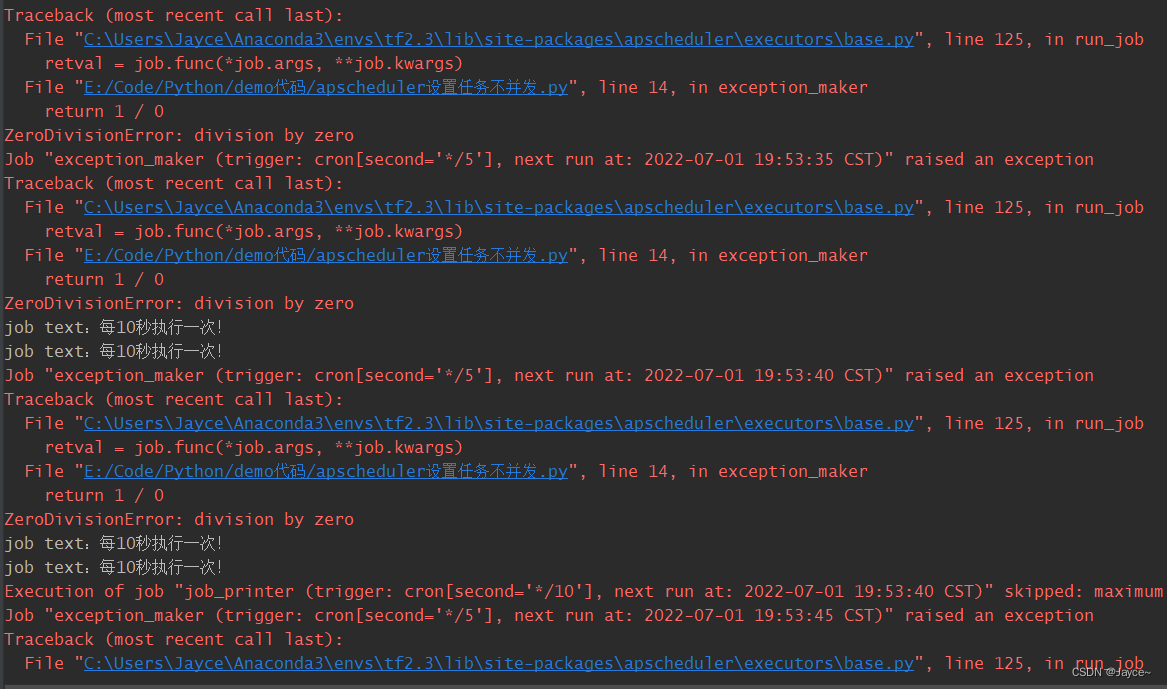
You can see it here , Not in a hurry give the thumbs-up , Comment on , Collection Take a walk ?
边栏推荐
- fastjson
- Leetcode question brushing record | 206_ Reverse linked list
- Canoe panel learning video
- 剑指 Offer II 038. 每日温度
- 测试岗的中年危机该如何选择?是坚守还是另寻出路?且看下文
- AWT常用组件、FileDialog文件选择框
- Overview of relevant subclasses of beanfactorypostprocessor and beanpostprocessor
- 注释与注解
- Actual cases and optimization solutions of cloud native architecture
- Qt发布多语言国际化翻译
猜你喜欢

input显示当前选择的图片
ansys命令
How to get the parent node of all nodes in El tree
![BUU-Crypto-[HDCTF2019]basic rsa](/img/d0/8e451dabb2a6897f6680220d16d04d.jpg)
BUU-Crypto-[HDCTF2019]basic rsa

Introduction To AMBA 简单理解
Actual cases and optimization solutions of cloud native architecture
Experience weekly report no. 102 (July 4, 2022)
Kubernets first meeting

剑指 Offer II 038. 每日温度

每周小结(*63):关于正能量
随机推荐
Impact relay jc-7/11/dc110v
AWT介绍
BUU-Pwn-test_ your_ nc
配置交叉编译工具链和环境变量
VB. Net simple processing pictures, black and white (class library - 7)
剑指 Offer II 038. 每日温度
[Chongqing Guangdong education] electronic circuit homework question bank of RTVU secondary school
复合非线性反馈控制(二)
MySQL information_ Schema database
XII Golang others
How to configure static IP for Kali virtual machine
[QT] create mycombobox click event
LC weekly 300
如何获取el-tree中所有节点的父节点
What are the reasons for the frequent high CPU of ECS?
安装 Pytorch geometric
LayoutManager布局管理器:FlowLayout、BorderLayout、GridLayout、GridBagLayout、CardLayout、BoxLayout
How to determine whether an array contains an element
如何判断数组中是否含有某个元素
Tutle clock improved version