当前位置:网站首页>【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
2022-07-02 07:44:00 【bryant_ meng】


ICRA-2019
List of articles
1 Background and Motivation
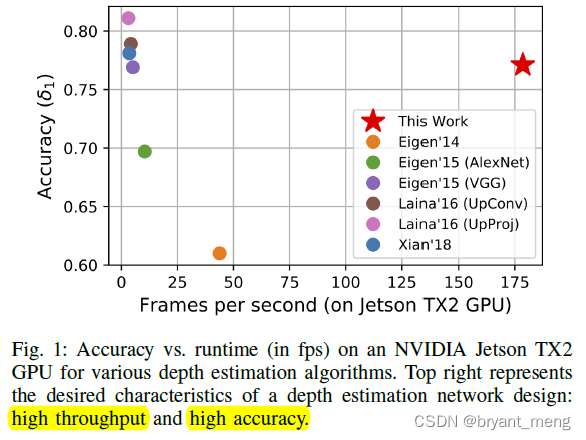
Accelerate the existing monocular depth estimation model , It has low delay while not losing accuracy , Can be in micro aerial vehicle Deployment run , auxiliary mapping, localization, and obstacle avoidance etc. robotic tasks
2 Related Work
- Monocular Depth Estimation
- Efficient Neural Networks
- Network Pruning
3 Advantages / Contributions
Accelerated monocular depth estimation model :
- a low-complexity and low-latency decoder design
- a state-of-the-art pruning algorithm(NetAdapt prune )
- Hardware-specific compilation(TVM Deploy DWConv Optimize )
4 Method
1) The overall structure 
Unsophisticated U-Net structure ,skip connection With add( useless concat,avoid increasing the number of feature map channels)
upsample layer The details are as follows

conv5( Depth separates the convolution ) + linear interpolation( Compared with bilinear , The underlying implementation is simple and general )
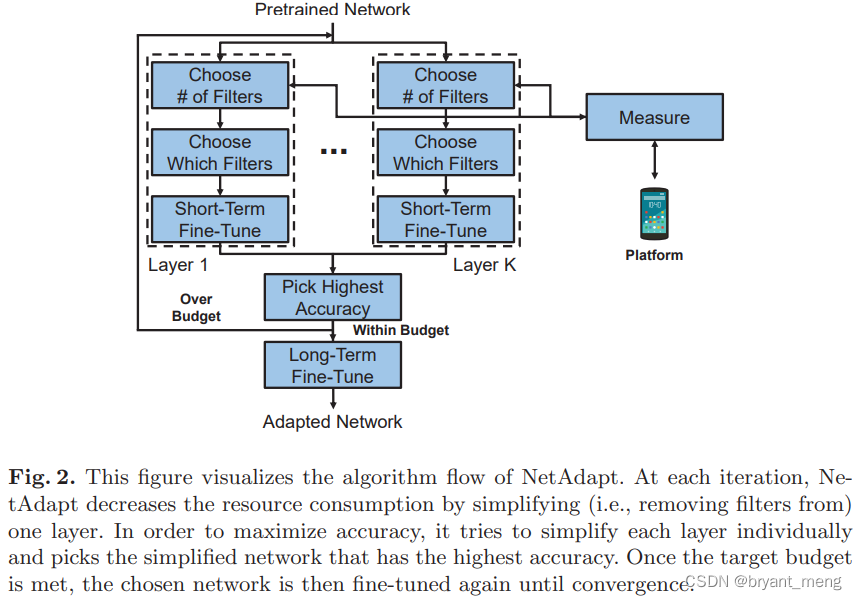
2)Network Pruning
With NetAdapt Methods to prune
《NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications》

It's more violent and direct , The following figure is more intuitive
3)Network Compilation
use TVM To speed up DWConv
Reference resources :
TVM It's a support GPU、CPU、FPGA Open source compiler framework for instruction generation
TVM The biggest feature is to optimize instruction generation based on graph and operator structure , Maximize hardware execution efficiency , It butts up Tensorflow、Pytorch Equal depth learning framework , Backwards compatible GPU、CPU、ARM、TPU Etc
TVM Is an end-to-end instruction generator . It receives model input from the deep learning framework , Then transform the graph and optimize it basically , Finally, generate instructions to complete the deployment of hardware .
TVM There are two main features :
- Support will Keras、MxNet、PyTorch、Tensorflow、CoreML、DarkNet The deep learning model of the framework is compiled into the minimum deployable model of a variety of hardware backend .
- It can automatically generate and optimize multiple back-end tensor operations and achieve better performance .
Now feel the overall framework

Feel it again 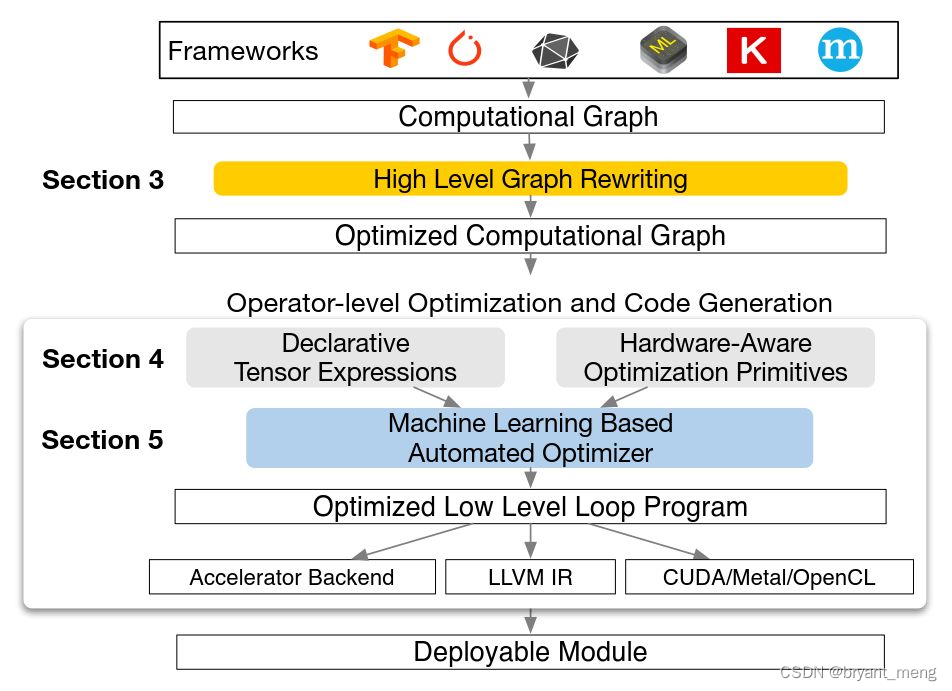
Feel it again 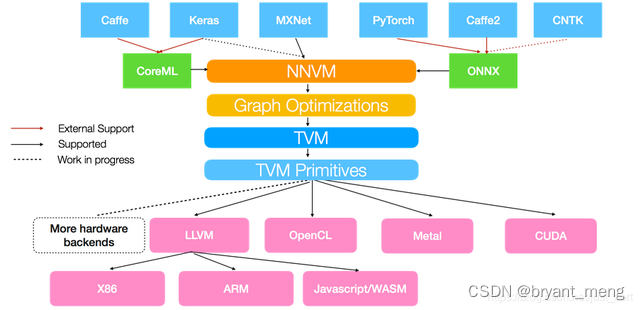
5 Experiments
5.1 Datasets

The evaluation index
δ 1 \delta1 δ1 (the percentage of predicted pixels where the relative error is within 25%), The bigger the better
RMSE (root mean squared error), The smaller the better.
5.2 Final Results and Comparison With Prior Work
The experiment platform

NVIDIA Jetson TX2 Series modules can be embedded AI Computing devices provide excellent speed and energy efficiency . Equipped with NVIDIA Pascal GPU、 the height is 8 GB Memory 、59.7 GB/s Video memory bandwidth and various standard hardware interfaces , Every supercomputer module will really AI The calculation is brought to the edge .
comparison encoder,decoder Occupy more runtime, Need to focus on Optimization 
Jetson TX2 in high performance (max-N) In mode , Compare with other methods 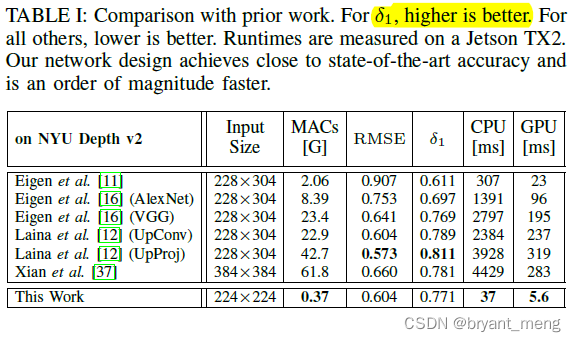
Jetson TX2 in high energy-efficiency (max-Q) Results in mode 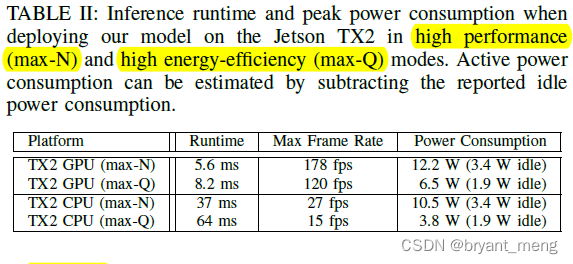
The visualization results are as follows ,the error is highest at boundaries and at distant objects.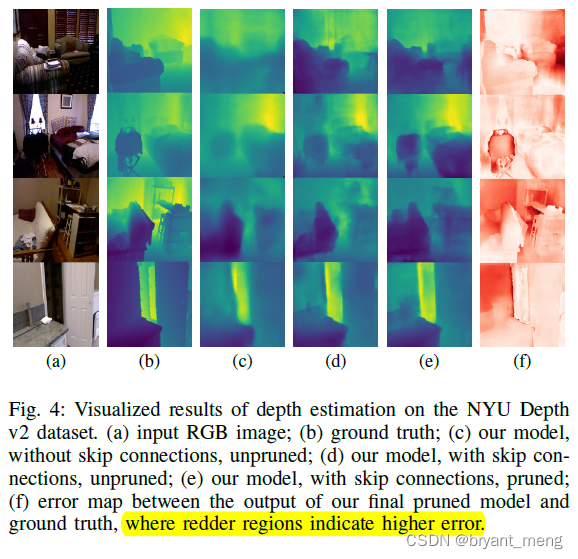
(c) and (d) The difference is that skip connection,(d) Refined a lot
5.3 Ablation Study
1)Encoder Design Space
The choice is MobileNet, The best trade-off between speed and accuracy 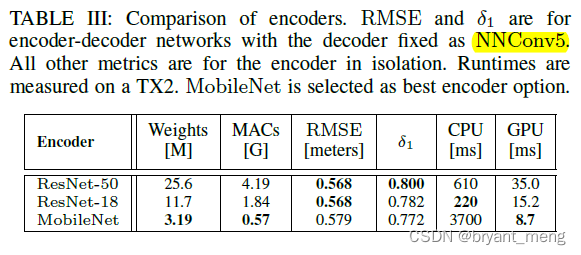
2)Decoder Design Space
Upsample Operation, That is, figure 2 Medium upsample layer

(a) and (b) The up sampling operation in is zero filling zero-insertion,(d) yes nearest neighbor interpolation

Depthwise Separable Convolution and Skip Connections

3)Hardware-Specific Optimization
hold DWConv To the extent that it further approximates the theoretical compressibility 
4)Network Pruning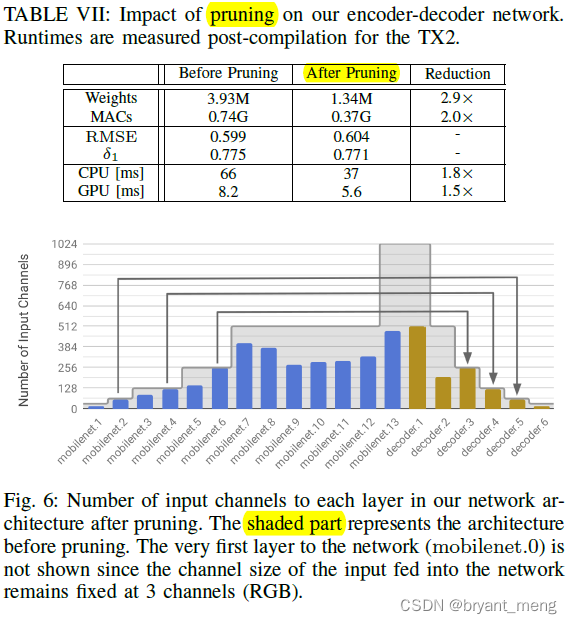
6 Conclusion(own) / Future work
It's more like a technical report of a competition !!!
code:https://github.com/dwofk/fast-depth
边栏推荐
- [tricks] whiteningbert: an easy unsupervised sentence embedding approach
- PointNet原理证明与理解
- How to efficiently develop a wechat applet
- [introduction to information retrieval] Chapter 3 fault tolerant retrieval
- SSM laboratory equipment management
- Use Baidu network disk to upload data to the server
- Drawing mechanism of view (3)
- [paper introduction] r-drop: regulated dropout for neural networks
- Semi supervised mixpatch
- Find in laravel8_ in_ Usage of set and upsert
猜你喜欢

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》

基于pytorch的YOLOv5单张图片检测实现
![[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization](/img/24/09ae6baee12edaea806962fc5b9a1e.png)
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization
使用百度网盘上传数据到服务器上

The difference and understanding between generative model and discriminant model

What if the laptop task manager is gray and unavailable
生成模型与判别模型的区别与理解

Label propagation
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization

Classloader and parental delegation mechanism
随机推荐
How to efficiently develop a wechat applet
Thesis writing tip2
Traditional target detection notes 1__ Viola Jones
自然辩证辨析题整理
Calculate the difference in days, months, and years between two dates in PHP
Record of problems in the construction process of IOD and detectron2
【Random Erasing】《Random Erasing Data Augmentation》
Open failed: enoent (no such file or directory) / (operation not permitted)
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
Solve the problem of latex picture floating
[introduction to information retrieval] Chapter 3 fault tolerant retrieval
PPT的技巧
ModuleNotFoundError: No module named ‘pytest‘
PHP returns the corresponding key value according to the value in the two-dimensional array
Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
Execution of procedures
ABM thesis translation
论文tips
What if a new window always pops up when opening a folder on a laptop
The difference and understanding between generative model and discriminant model