当前位置:网站首页>自然语言处理系列(一)入门概述
自然语言处理系列(一)入门概述
2022-07-05 12:38:00 【Yunlord】

目录
4.命名实体识别 Named Entity Recognition
引言
自然语言处理正处于高速发展时期。
随着传感器、通信、芯片以及AI算法的共同进步,物联网的时代即将到来。届时,几乎所有事物都可以通过传感器技术收集全面的信息,通过5G高速传输海量信息。在云服务上通过AI算法实现数据分析,大大提升社会生产效率。
人工智能技术主要分为两大领域,计算机视觉(computer vision),自然语言处理(natural language processing),而且影响着人们生活的方方面面。计算机视觉专注于对于图像的理解与处理,而自然语言处理则广泛应用于各种与语音或文本有关的场景。在这当中,自然也存在两种技术应用场景的重叠区域,即需要同时对图像与文本进行综合地理解与处理。
从这个角度,只要有文本数据的地方就有NLP技术的需求。目前,即便在金融科技领域也有着大量对文本分析的需求,比如通过阅读新闻和研报来分析市场舆情,或者做证券市场数据分析。
过去几年,可以看到一个明显的趋势那就是文本数据在呈指数级的增长。这其实离不开移动互联网所带来的数据暴增。可以想象一下,我们每天使用的社交软件,如微信、抖音,所承载的文本数据量有多大。文本数据的剧增必然会伴随着行业对文本分析需求的急速增加,随着而来的是对于NLP人才的需求。
虽然目前这个赛道貌似已经很卷了,但是我相信,这是一个会被拓宽的赛道,在自然语言处理领域里面是能够有所作为的。
一、NLP系列专栏介绍
(一)设计初衷
书写本系列的初衷有以下几点:
- 培养吸引新的NLP/AI人才。在系列文章中会由浅入深的讲解自然语言相关知识和案例。
- NLP是目前AI领域中最为火热的方向。自然语言处理近几年变得异常火爆,虽然起步相比计算机视觉晚了几年,但它的势头非常强劲,而且预计在未来5年内仍然保持这种势头。
- 当前还没有特别体系化、细节的NLP系列教程,特别是中文。
- 深度学习之前的技术
- 基于深度学习的方法论
- NLP近几年发展特别快,知识迭代更新迅速。所以近几年AI领域轰动性的成功很多来自于自然语言处理,包括前几年的bert。
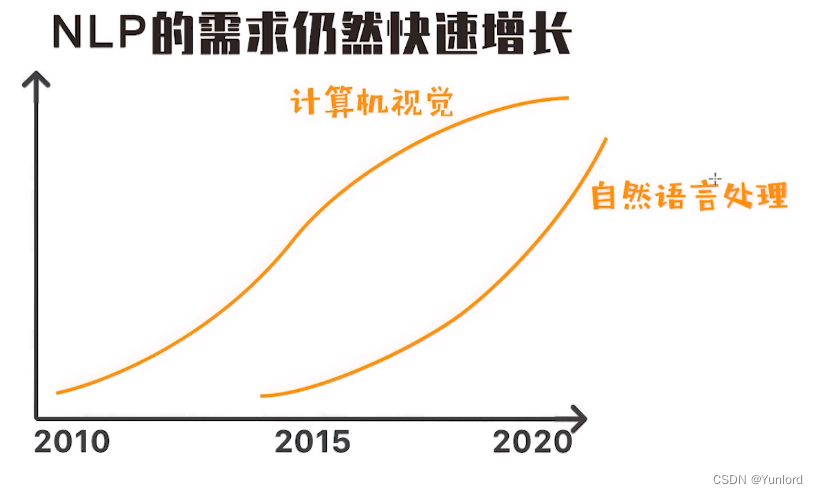
同时对于初学者来说,NLP是一个较快的AI的入门选择和发展方向,门槛比CV更低。
(二)NLP岗位待遇
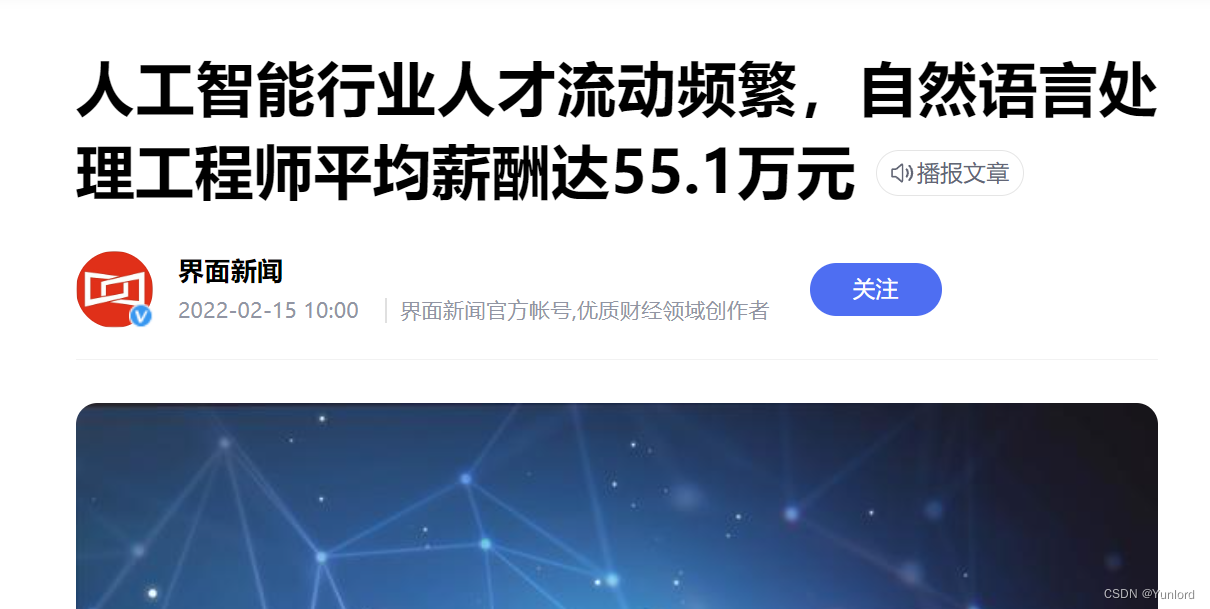
随着人工智能产业的飞速发展,人工智能人才抢夺日趋白热化。近日,发布的《人工智能行业人才管理研究报告》显示,人工智能行业流动率同比增加,科技类岗位人员供应吃紧,算法设计岗和应用开发岗人员供需比均在 0.2以下。
据工信部数据,预计我国人工智能产业内有效人才缺口达 30 万,其中技术人才缺口较大。报告指出,人工智能行业算法研究岗、应用开发岗人才供应极度紧张,人才供需比仅为 0.13 和 0.17;实用技能岗人才供应基本满足需求,人才供需比为 0.98,仍有轻度的供应不足。在不同技术方向上,计算机视觉人才极度稀缺,供需比仅为 0.09,自然语言处理、机器学习和人工智能芯片人才也处于紧缺状态,人才供需比分别为 0.2、0.23 和 0.37。
总而言之,目前进入NLP的行列是没有错的,至少在未来5年内这个行业的机会仍然会存在,只不过市场对人才的要求也会变得越来越高。 所以,越早进入这个行业,优势越大。
(三)如何学习NLP
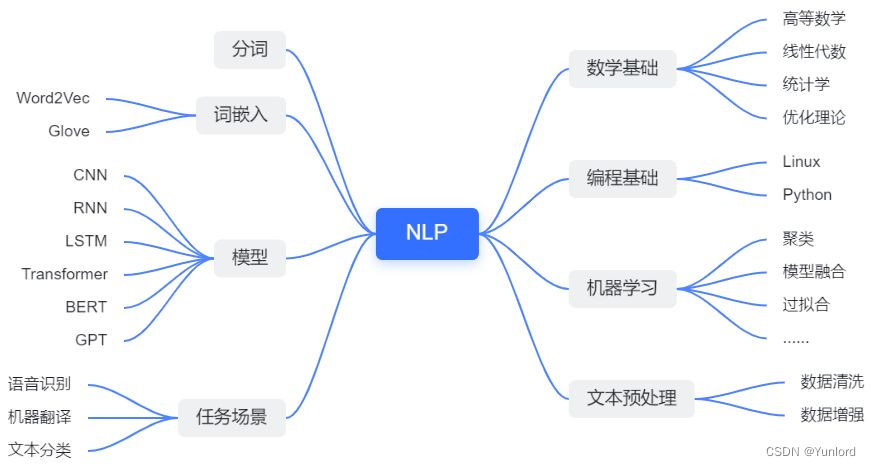 、
、
自然语言处理小白入门知识体系如上图所示。下面我会进行简单的介绍,而且在后续的系列文章中会依次介绍相关的知识及文章,并且会通过案例及代码讲解帮助大家更好的理解。
- 数学基础
- 编程基础
- 机器学习
- 文本预处理
- 分词和词嵌入
- 模型
- 应用场景
数学知识:
首先需要一定的数学知识。只需要了解基础的高等数学、线性代数、统计学和优化理论就行。具体的理论等深入学习再慢慢了解也行。
编程基础:
主要是通过python实现深度学习代码,而且现在已经有大量好用的深度学习框架,包括pytorch、tensorflow2等等,简单易学好上手。而操作系统其实linux和windows都行,不过真正工业部署的时候linux适用性更广。
机器学习:
需要学习一些机器学习的基本概念,虽然现在基本都是用深度学习去解决自然语言处理上复杂的应用问题,相对与传统的机器学习方法,性能会比较优秀。但是深度学习与机器学习一脉相承,很多机器学习的概念在深度学习中是通用的,比如数据集,损失函数,过拟合等。
文本预处理:
自然语言处理任务的首个流程也是关键性流程——文本预处理。当得到文本数据集后,需要经过分词、停用词过滤、文本向量的转化等一系列文本预处理步骤,这样才能在后续的任务中取得较好的效果。而同时如果数据集较小,可以通过数据增强等操作进行数据集的扩充。
分词与词嵌入
对于自然语言处理各类应用,最基础的任务就是文本表示。因为我们知道一个文本是不能直接作为模型的输入的,所以我们必须要先把文本转换成向量的形式之后,再导入到模型中训练。所谓文本的表示,其实就是研究如何把文本表示成向量或者矩阵的形式。基本操作就是把文本分为词的组合,然后对于每一个词,用一个特征向量来表示它。
模型
当我们将用特征向量去表示文本后,就可以将向量输入到模型中去进行下游任务,比如分类或者翻译。接下来我们会介绍各种模型结果并且讲解代码。
应用场景
NLP的应用场景有很多,比如语音识别、机器翻译、文本分类以及摘要生成等等。我们会用工业化的工程实践来逐一讲解。
二、什么是NLP
(一)NLP概述
自然语言处理的三个概念:
- 自然语言处理(Natural Language Processing, NLP)
- 自然语言理解(Natural Language Understanding, NLU),理解文本中的意思
- 自然语言生成(Natural Language Generation, NLG),根据意思生成文本
人们通过语音、图像和文本的方式来传递信息交流。那么最核心的问题就是如何理解这些信息?而NLP的主要任务就是理解文本和生成文本信息,所以有一个公式:
NLP=NLU+NLG
从NLU到NLG的图示如下:
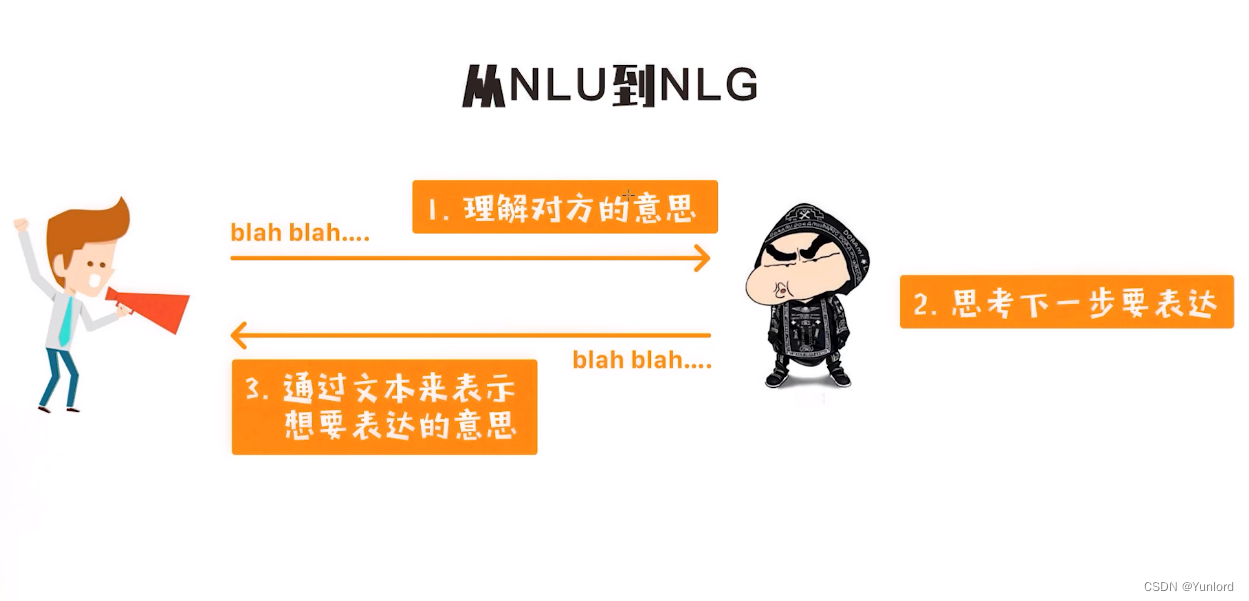
所以总体来讲,NLP主要分两个方面,一方面是研究如何更好地理解文本传递的意思(NLU),另外一方面则研究如何根据所表达的意思来生成文本(NLG)。
(二)NLP的难点
为什么理解文本比理解图像更难?
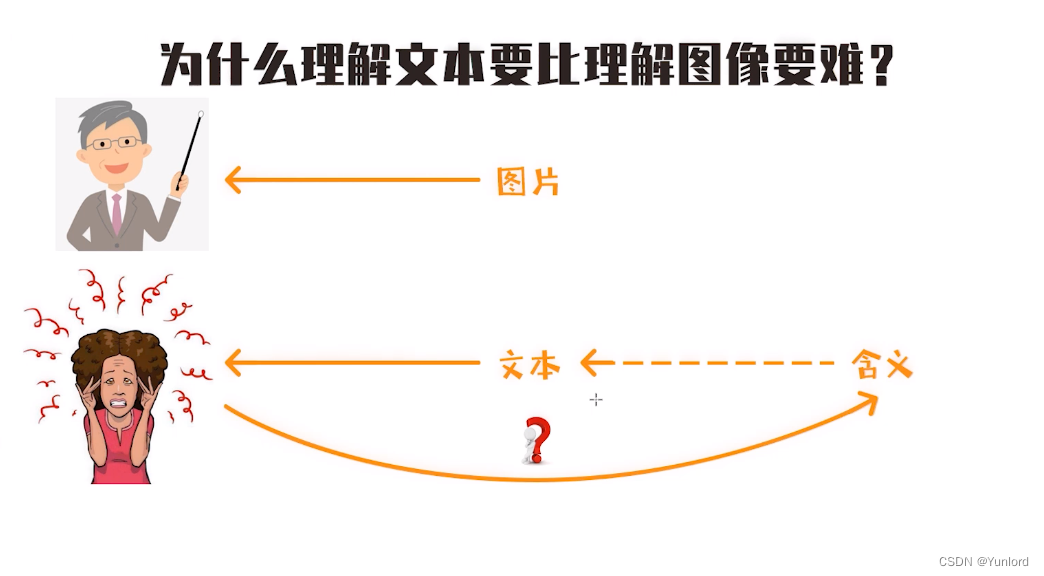
因为图片一般都是所见即所得,没有背后深层的含义,而且基本不会存在在不同场景有不同意义的情况。
而文本就不是这样了,我们直接看到的只是文本,还需要理解其背后深层含义,具体的说有以下几点:
- 一义多表,一种含义多种表示。
- 一词多义,一个词语在上下文中表达不同的含义。
除了技术本身之外,自然语言处理工业流程通常也会涉及到很多的模块,基本的包括文本清洗、分词、特征工程、命名实体识别、分类等一系列步骤,实际上每一次操作都会不断累积误差,最终影响实际系统的性能。 所以在设计NLP系统时,每一个环节至关重要,不能有任何的忽视。
三、NLP应用
自然语言处理有很多应用场景,包括智能问答系统、文本生成、机器翻译等。
(一)智能问答系统
随着互联网的快速发展,网络信息量不断增加,人们需要获取更加精确的信息。传统的搜索引擎技术已经不能满足人们越来越高的需求,而自动问答技术成为了解决这一问题的有效手段。自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务,在回答用户问题时,首先要正确理解用户所提出的问题,抽取其中关键的信息,在已有的语料库或者知识库中进行检索、匹配,将获取的答案反馈给用户。
(二)文本生成
文本生成技术是自然语言处理领域的另一重要技术。应用者可以利用既定信息与文本生成模型生成满足特定目标的文本序列。文本生成模型的应用场景丰富如生成式阅读理解、人机对话或者智能写作等。当前深度学习的发展也推动了该项技术的进步,越来越多高可用的文本生成模型诞生,促进行业效率,服务智能化社会。
(三)机器翻译
随着通信技术与互联网技术的飞速发展、信息的急剧增加以及国际联系愈加紧密,让世界上所有人都能跨越语言障碍获取信息的挑战已经超出了人类翻译的能力范围。
机器翻译因其效率高、成本低满足了全球各国多语言信息快速翻译的需求。机器翻译属于自然语言信息处理的一个分支,能够将一种自然语言自动生成另一种自然语言又无需人类帮助的计算机系统。目前,谷歌翻译、百度翻译、搜狗翻译等人工智能行业巨头推出的翻译平台逐渐凭借其翻译过程的高效性和准确性占据了翻译行业的主导地位。
(四)情感分析
在数字时代,信息过载是一个真实的现象,我们获取知识和信息的能力已经远远超过了我们理解它的能力。并且,这一趋势丝毫没有放缓的迹象,因此总结文档和信息含义的能力变得越来越重要。情感分析作为一种常见的自然语言处理方法的应用,可以让我们能够从大量数据中识别和吸收相关信息,而且还可以理解更深层次的含义。比如,企业分析消费者对产品的反馈信息,或者检测在线评论中的差评信息等。
(五)聊天机器人
聊天机器人可以实现无人下单等功能。
分为闲聊型和任务导向型机器人:闲聊型用到的是生成式方法,包括seq2seq、Transformer等模型;任务型,偏向使用填槽的方式。
搭建聊天机器人也可以使用类似于问答系统的方式,即检索式。
(六)垃圾邮件过滤
当前,垃圾邮件过滤器已成为抵御垃圾邮件问题的第一道防线。不过,有许多人在使用电子邮件时遇到过这些问题:不需要的电子邮件仍然被接收,或者重要的电子邮件被过滤掉。
而自然语言处理通过分析邮件中的文本内容,能够相对准确地判断邮件是否为垃圾邮件。目前,贝叶斯(Bayesian)垃圾邮件过滤是备受关注的技术之一,它通过学习大量的垃圾邮件和非垃圾邮件,收集邮件中的特征词生成垃圾词库和非垃圾词库,然后根据这些词库的统计频数计算邮件属于垃圾邮件的概率,以此来进行判定。
(七)个性化推荐
自然语言处理可以依据大数据和历史行为记录,学习出用户的兴趣爱好,预测出用户对给定物品的评分或偏好,实现对用户意图的精准理解,同时对语言进行匹配计算,实现精准匹配。例如,在新闻服务领域,通过用户阅读的内容、时长、评论等偏好,以及社交网络甚至是所使用的移动设备型号等,综合分析用户所关注的信息源及核心词汇,进行专业的细化分析,从而进行新闻推送,实现新闻的个人定制服务,最终提升用户粘性。
(八)信息抽取
金融市场中的许多重要决策正日益脱离人类的监督和控制。算法交易正变得越来越流行,这是一种完全由技术控制的金融投资形式。但是,这些财务决策中的许多都受到新闻的影响。因此,自然语言处理的一个主要任务是获取这些明文公告,并以一种可被纳入算法交易决策的格式提取相关信息。例如,公司之间合并的消息可能会对交易决策产生重大影响,将合并细节(包括参与者、收购价格)纳入到交易算法中,这或将带来数百万美元的利润影响。
除了以上应用之外,其实还有非常多的应用场景。即便针对于其中一个应用,我们也可以衍生出很多不一样的任务。大家可以挑选一个自己最感兴趣的主题去系统性地了解这个领域的知识,或者去调研相关的所有的文章。希望在系列教程结束之际,大家能够对某一个领域有自己较深的认知。
所以接下来的教程将会依次对这些应用场景从算法理论、代码实操和项目落地这三个角度进行讲解,使大家能够具备独立开发模型以及服务化部署的能力。
四、NLP核心技术
(一)NLP技术的三个维度
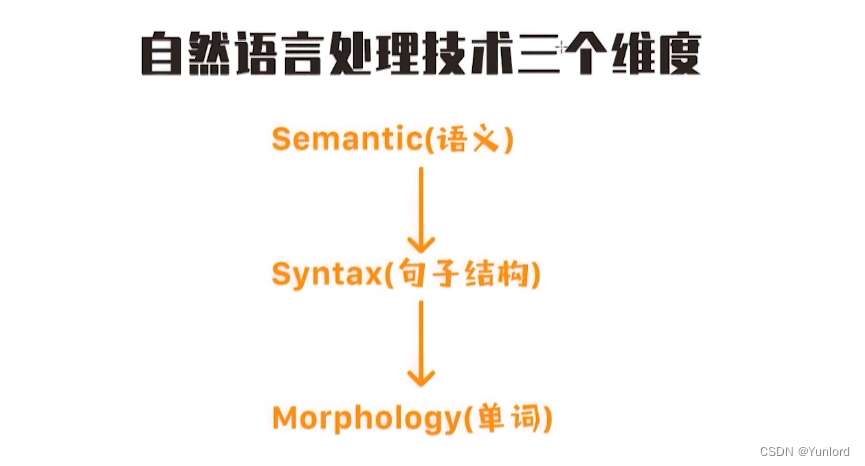
三个维度分别是:
- 单词Morphology ,单词的含义、词性等。
- 句子结构Syntax, 基于语言语法剖析句子成分,得到语法树,从而得出句子不同模块之间的关系。
- 语义Semantic ,理解句子背后的含义。
这些属于上游任务,因为起到了最为基础性的作用。如果在这些没有做好,那无法对句子层面上的,或者对于整篇文本层面上的分析。只有把底层基础技术做好,才能更好地去服务下游任务。
打个比方,对于一个文本分类任务来说,它非常依赖于文本的表示,而且文本的表示又非常依赖于单词的表示。那这里的一个核心是如何更好的表示单词,回归到了上游任务。
(二)NLP的关键技术
1.分词 Word Segmentaition
分词就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作。显然,中文的分词比英文分词更复杂,但同时分词可以通过jieba等工具直接调用,作为已经完成的任务。
2.词性标注 Part-of-Speech Tagging
词性标注即在给定的句子中判定每个词最合适的词性标记。词性标注的正确与否将会直接影响到后续的句法分析、语义分析,是中文信息处理的基础性课题之一。
3.语义理解 Semantic Understanding
语义理解指的是解释自然语言句子或篇章各部分(词、词组、句子、段落、篇章)的含义。
4.命名实体识别 Named Entity Recognition
命名实体识别就是从实际的文本数据集(语料库)中分析,判断,标记出具体的命名实体,通常会涉及到两个关键点:(1)命名实体的边界识别;(2)命名实体所属的类别(比如人名、地名、组织机构名等等)。
5.句法分析 Parsing
句法分析是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。
(三)NLP技术概览
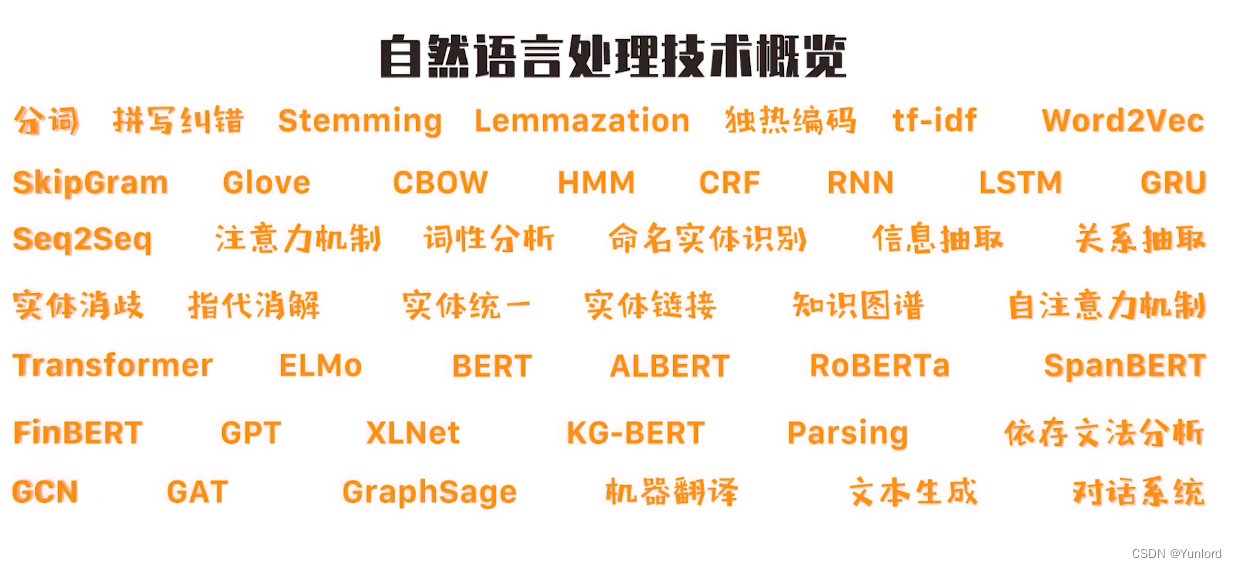
以上就是涉及自然语言处理的一些技术名词,而后续的教程也会逐步介绍。
总结
NLP 在过去十年间已经取得了出乎人类意料的发展,而随着大规模语言模型的发展,计算机将突破语言的界限并可以掌握越来越多的感官信息。正如曼宁所说,可以理解更多种感官信息的模型也意味着它们将更广泛地使用,而正因为此,人们将可能在未来十年内就看到一种普遍适用的更基础的人工智能形式。
因此,NLP未来可期,也希望能有更多的大家一起加入到这个领域。
想要一起从小白到大神,学习自然语言处理的朋友们可以点击下方链接或者订阅我的自然语言处理从小白到精通专栏,里面涉及到的工程部署以及完整代码实践全部免费赠送。
参考:
人工智能行业人才流动频繁,自然语言处理工程师平均薪酬达55.1万元
贪心学院NLP课程
边栏推荐
- 【Nacos云原生】阅读源码第一步,本地启动Nacos
- Reshape the power of multi cloud products with VMware innovation
- 滴滴开源DELTA:AI开发者可轻松训练自然语言模型
- ZABBIX agent2 monitors mongodb nodes, clusters and templates (official blog)
- Kotlin流程控制、循环
- SAP 自开发记录用户登录日志等信息
- 非技术部门,如何参与 DevOps?
- Constructing expression binary tree with prefix expression
- Experimental design - using stack to realize calculator
- Sqoop import and export operation
猜你喜欢
OPPO小布推出预训练大模型OBERT,晋升KgCLUE榜首
CVPR 2022 | single step 3D target recognizer based on sparse transformer

前几年外包干了四年,秋招感觉人生就这样了..
【Nacos云原生】阅读源码第一步,本地启动Nacos
Constructing expression binary tree with prefix expression
SAP 自开发记录用户登录日志等信息
What if wechat is mistakenly sealed? Explain the underlying logic of wechat seal in detail
Ecplise development environment configuration and simple web project construction
Iterator details in list... Interview pits

从39个kaggle竞赛中总结出来的图像分割的Tips和Tricks
随机推荐
Transactions on December 23, 2021
Yum only downloads the RPM package of the software to the specified directory without installing it
2021-12-21 transaction record
Master-slave mode of redis cluster
【云原生】Nacos中的事件发布与订阅--观察者模式
Kotlin函数
Kotlin process control and circulation
Hexadecimal conversion summary
以VMware创新之道,重塑多云产品力
Taobao, pinduoduo, jd.com, Doudian order & Flag insertion remarks API solution
NFT: how to make money with unique assets?
Distributed cache architecture - cache avalanche & penetration & hit rate
从39个kaggle竞赛中总结出来的图像分割的Tips和Tricks
ZABBIX agent2 monitors mongodb nodes, clusters and templates (official blog)
Docker configures redis and redis clusters
Language model
Ecplise development environment configuration and simple web project construction
NLP engineer learning summary and index
Detailed structure and code of inception V3
Alipay transfer system background or API interface to avoid pitfalls